AI Time | 你负责人工智能哪部分?人工那部分;知识图谱的构建主要靠人工还是机器?


大家都知道当前知识图谱是在当前人工智能领域一个备受关注的分支中有一个分类叫做“知识图谱”。,简单来说,它就是知识图谱以结构化的形式描述客观世界中概念、实体及其之间的关系,将互联网的信息表达成更接近人类认知世界的形式。
这也是AI Time第3期主题:“论道知识图谱:知识赋能智能与智能产生知识”,加州大学洛杉矶分校(UCLA)副教授孙怡舟、加拿大蒙特利尔学习算法研究所 (MILA)研究员唐建和中科院自动化所副研究员刘康共同参与了此次论道。

现在请大家思考一个场景,假想你是一个医疗创业公司的负责人,目前想启动一个健康问答的项目,现在你是选择集中资金和人力构建丰富的医疗知识图谱,还是集中资金与人力去研发高效的问答算法?你会怎么选择?
知识工程的前世今生
在进入知识图谱领域之前,我们不妨先来回顾一下知识工程四十年多来发展历程。对知识工程的演进过程和技术进展记性总结后,我们可以将知识工程分成五个标志性的阶段:图灵测试时期、专家系统时期、Web1.0 万维网时期、Web2.0 群体智能时期以及Web 3.0 知识图谱时期,如下图所示:

知识工程发展历程
1950-1970时期:图灵测试—知识工程诞生前期
人工智能旨在让机器能够像人一样解决复杂问题,图灵测试是评测智能的是手段。这一阶段主要有两个方法:符号主义和连结主义。符号主义认为物理符号系统是智能行为的充要条件,连结主义则认为大脑(神经元及其连接机制)是一切智能活动的基础。
这一阶段具有代表性的工作是通用问题求解程序(GPS):将问题进行形式化表达,通过搜索,从问题初始状态,结合规则或表示得到目标状态。其中最成功应用是博弈论和机器定理证明等。
这一时期的知识表示方法主要有:数理逻辑、基于逻辑的知识表示、产生式规则和语义网络等。
这一时代人工智能和知识工程的先驱Minsky,Mccarthy和Newell以Simon四位学者因为他们在感知机、人工智能语言和通用问题求解和形式化语言方面的杰出工作分别获得了1969年、1971年、1975年的图灵奖。
1970-1990时期:专家系统—知识工程蓬勃发展期
70年开始,人工智能开始转向建立基于知识的系统,通过“知识库+推理机”实现机器智能,这一时期涌现出很多成功的限定领域专家系统,如MYCIN医疗诊断专家系统、识别分子结构的DENRAL专家系统以及计算机故障诊断XCON专家系统等。
斯坦福人工智能实验室的奠基人Feigenbaum教授在1980年的一个项目报告《Knowledge Engineering:The Applied Side of Artificial Intelligence》中提出知识工程的概念,从此确立了知识工程在人工智能中的核心地位。
这一时期知识表示方法有新的演进,包括框架和脚本等。80年代后期出现了很多专家系统的开发平台,可以帮助将专家的领域知识转变成计算机可以处理的知识。
1990-2000时期:Web1.0 万维网
在1990年到2000年,出现了很多人工构建大规模知识库,包括广泛应用的英文WordNet,采用一阶谓词逻辑知识表示的Cyc常识知识库,以及中文的HowNet。
Web 1.0万维网的产生为人们提供了一个开放平台,使用HTML定义文本的内容,通过超链接把文本连接起来,使得大众可以共享信息。
W3C提出的可扩展标记语言XML,实现对互联网文档内容的结构通过定义标签进行标记,为互联网环境下大规模知识表示和共享奠定了基础。这一时期在知识表示研究中还提出了本体的知识表示方法。
2000-2006时期:Web2.0 群体智能
在2001年,万维网发明人、2016年图灵奖获得者Tim Berners-Lee在科学美国人杂志中发表的论文《The Semantic Web》正式提出语义Web的概念,旨在对互联网内容进行结构化语义表示,利用本体描述互联网内容的语义结构,通过对网页进行语义标识得到网页语义信息,从而获得网页内容的语义信息,使人和机器能够更好地协同工作。W3C进一步提出万维网上语义标识语言RDF(资源描述框架)和OWL(万维网本体表述语言)等描述万维网内容语义的知识描述规范。
万维网的出现使得知识从封闭知识走向开放知识,从集中构建知识成为分布群体智能知识。原来专家系统是系统内部定义的知识,现在可以实现知识源之间相互链接,可以通过关联来产生更多的知识而非完全由固定人生产。这个过程中出现了群体智能,最典型的代表就是维基百科,实际上是用户去建立知识,体现了互联网大众用户对知识的贡献,成为今天大规模结构化知识图谱的重要基础。
2006年至今:Web 3.0 知识图谱时期
将万维网内容转化为能够为智能应用提供动力的机器可理解和计算的知识是这一时期的目标。从2006年开始,大规模维基百科类富结构知识资源的出现和网络规模信息提取方法的进步,使得大规模知识获取方法取得了巨大进展。与Cyc、WordNet和HowNet等手工研制的知识库和本体的开创性项目不同,这一时期知识获取是自动化的,并且在网络规模下运行。
当前知识图谱自动构建的知识库已成为语义搜索、大数据分析、智能推荐和数据集成的强大资产,在大型行业和领域中正在得到广泛使用。典型的例子是谷歌收购Freebase后在2012年推出的知识图谱(Knowledge Graph),Facebook的图谱搜索,Microsoft Satori以及商业、金融、生命科学等领域特定的知识库。最具代表性大规模网络知识获取的工作包括DBpedia、Freebase、KnowItAll、WikiTaxonomy和YAGO,以及BabelNet、ConceptNet、DeepDive、NELL、Probase、Wikidata、XLORE、Zhishi.me、CNDBpedia等。这些知识图谱遵循图RDF数据模型,包含数以千万级或者亿级规模的实体,以及数十亿或百亿事实(即属性值和与其他实体的关系),并且这些实体被组织在成千上万的由语义体现的客观世界的概念结构中。
在我国知识工程领域研究中,中科院系统所陆汝钤院士、计算所史忠植研究员等老一代知识工程研究学者为中国的知识工程研究和人才培养做出了突出贡献,陆汝钤院士因在知识工程和基于知识的软件工程方面作出的系统和创造性工作,以及在大知识领域的开创性贡献,荣获首届“吴文俊人工智能最高成就奖”。

2011年2月14日,IBM的“Waltson”超级计算机登上了美国最受欢迎的智力问答节目《危险边缘》(Jeopardy),挑战该节目的两名总冠军肯-詹宁斯和布 拉德-鲁特尔,实现有史以来首次人机智力问答对决,并赢取高达100万美元的奖金。
“Waltson”由10台IBM服务器组成。这些服务器采用Linux操作系统,虽然没有联网,但沃森存储了大量图书、新闻和电影剧本资料、辞海、文选和《世界图书百科全书》等数百万份资料,每当读完问题的提示后,“Waltson”就在不到三秒钟的时间里对自己的数据库"挖地三尺",在长达2亿页的漫漫资料里展开搜索。
那他究竟是如何能从这些浩瀚的数据中得到答案的呢?实际过程当然很复杂,需要从杂乱无章的原始数据中提取有用的数据,即信息,在此基础上理解它的含义,即知识,最后这些知识才能拿来为我们所用产生智能。
知识图谱究竟主要是靠人工来构建,还是靠机器自动来构建?
网络上曾流行这样一段打趣的对话。
A:“你是做什么的的?”
B:“做人工智能的。”
A: “你负责人工智能的哪部分呢?”
B:“我负责人工那部分。”
虽然这是玩笑话,但实际上在构建知识图谱的过程中,不可或缺地需要很多人工智慧的参与。在某些垂直领域知识图谱的构建上,甚至需要非常多专家智慧的参与。尽管学术界与工业界都在努力尝试自动抽取实体与发现实体之间的关系,但是其精准度的局限性导致在某些对错误容忍性很低的领域,比如医疗领域,可能并不能很好的应用。
三位老师大体上都认为半自动结合人工是目前构建知识图谱的理想方式。刘老师表示知识表示的手段对于我们要表现的知识还存在局限性,构建某个领域的知识图谱也是很困难的,需要根据需求不断更新数据。总的来说,构建和维护知识图谱都是一件很费时费力的事,人工的参与提高了精准性,不可能完全摒弃掉人工智慧。孙老师告诉大家,她的老师韩家炜教授近期的工作重点就在于知识图谱的构建自动化。

有必要融合知识图谱吗?
知识图谱可以由任何机构和个人自由构建,其背后的数据来源广泛、质量参差不齐,导致它们之间存在多样性和异构性。语义集成的提出就是为了能够将不同的知识图谱融合为一个统一、一致、简洁的形式,为使用不同知识图谱的应用程序间的交互建立操作性。
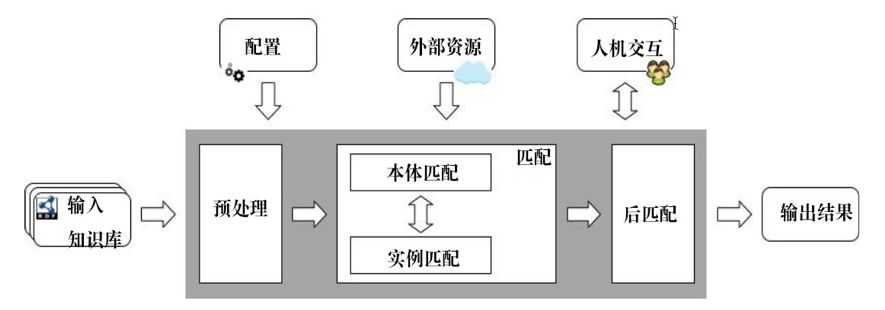
语义集成的常见流程
常用的技术包括本体匹配(也称为本体映射)、实例力匹配(也称为实体对齐、对象公共指消解)以及知识融合等。
对此,三位老师均认为知识图谱的融合是有必要的。因为有些问题需综合多个领域的图谱才能回答,不同知识图谱覆盖的信息不同,融合可构建更全面的知识图谱。孙老师强调不同语言之间的知识图谱融合是最有意义的,对图谱的要求自然是越全越好,垂直融合尽可能获取更多知识的话,对推理的帮助更大。刘老师则表示融合时面临着两个问题:一个是不同图谱之间的关键词和字符不同,另一个是不同图谱之间的实例能否关联。

“人工智能历史上最有争议的项目”之一Cyc
曾经在美国盛极一时的Cyc项目代表了Web1.0 万维网时期典型的人工智能技术与思考,更神奇的是这个1984年启动的项目,直到今天还在继续,并且始终处于建设中,它称为是“人工智能历史上最有争议的项目”之一,因此难免对它有批评的意见,主要概括如下:
• 系统的复杂度:该系统具有创建百科全书式知识库的野心,却由特定知识工程师手动添加所有的知识到系统中
• 知识表示广泛的具体化引发的可扩展性问题,特别是以常量的形式进行
• 对物质概念的解释难以令人满意,对内在属性和外在属性区分不清晰
刘老师直言这是一个失败的项目,孙老师也同样表示人的速度赶不上知识增长的速度,这是不可行的。
除了“搜一搜,看一看”,知识图谱更深入的应用场景有哪些?
知识应用能够将知识图谱特有的应用形态与领域数据与业务场景相结合并助力领域业务转型。知识图谱的典型应用包括智能推荐、语义搜索、智能问答以及可视化决策支持等三种。如何针对业务需求设计实现知识图谱应用,并基于数据特点进行优化调整,是知识图谱应用的关键研究内容。
刘老师表示除了大众看到的“搜一搜,看一看”之外,还有很多知识图谱在背后发挥作用的场景,例如金融领域的风险评估、银行领域的征信、电商领域的推荐场景和教育领域的APP;唐老师表示除此之外医疗领域也有很多场景有知识图谱的应用。

知识图谱应当如何更加智能地应用到这些场景中?
现在有很多人研究将知识图谱应用到智能问答、机器翻译和推荐等场景中。但是,实际在很多场景下,用了知识图谱效果也不会提升多少,甚至有可能会下降。这里面可能存在的难点有两个,一是知识图谱本身的不完整性导致其效果有限,二是将知识图谱链入到各个具体任务时,可能会引入大量的错误。
刘老师对此表示在场景下应用知识图谱效果反而下降的原因在于两点,第一也是认为知识图谱的覆盖度过低,第二是已有的知识和表达无法对应上。如果能提前预知用户需求和图谱应用场合,对数据进行精细化后,就能更好地应用到场景中去。
未来之路
如果未来的智能机器拥有一个大脑,知识图谱就是这个大脑中的知识库,对于大数据智能具有重要意义,将对自然语言处理、信息检索和人工智能等领域产生深远影响。
现在以商业搜索引擎公司为首的互联网巨头已经意识到知识图谱的战略意义,纷纷投入重兵布局知识图谱,并对搜索引擎形态日益产生重要的影响。同时,我们也强烈地感受到,知识图谱还处于发展初期,大多数商业知识图谱的应用场景非常有限。可以看到,在未来的一段时间内,知识图谱将是大数据智能的前沿研究问题,有很多重要的开放性问题亟待学术界和产业界协力解决。

观看本期 AITime 回放视频,请登录 AI研习社 观看。
↓ 传送门 ↓

2019 年 7 月 12 日至 14 日,由中国计算机学会(CCF)主办、雷锋网和香港中文大学(深圳)联合承办,深圳市人工智能与机器人研究院协办的 2019 全球人工智能与机器人峰会(简称 CCF-GAIR 2019)将于深圳正式启幕。
届时,诺贝尔奖得主JamesJ. Heckman、中外院士、世界顶会主席、知名Fellow,多位重磅嘉宾将亲自坐阵,一起探讨人工智能和机器人领域学、产、投等复杂的生存态势。