论文浅尝 - ISWC2020 | KnowlyBERT: 知识图谱结合语言模型补全图谱查询
论文笔记整理:胡楠,东南大学博士。

来源:ISWC 2020
动机
像Wikidata这样的现代知识图已经捕获了数十亿个RDF三元组,但是它们仍然缺乏对大多数关系的良好覆盖。同时在NLP研究的最新进展表明,可以轻松地查询神经语言模型以获得相关知识而无需大量的训练数据。这项论文工作综合这些进展通过在知识图谱的顶部创建一个结合BERT的混合查询应答系统来改善补全查询结果,将知识图谱中的有价值的结构和语义信息与语言模型中的文本知识相结合,以达到高精度查询结果。当前处理不完整知识图谱的标准技术是(1)需要大量训练数据的关系提取,或者(2)知识图谱嵌入,这些知识在简单的基准数据集之外就难以成功。论文为此提出的混合系统KnowlyBERT仅需要少量的训练数据,并且在Wikidata上进行实验,结果表明优于最新技术。
模型
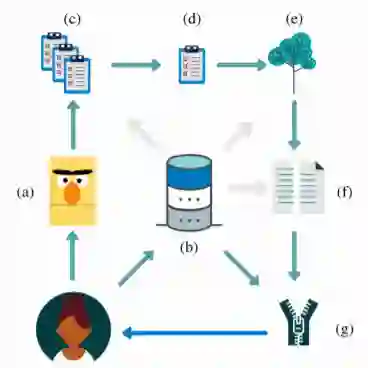
系统概述图如上所示。作为KnowlyBERT的输入,用户可以向系统提出以实体为中心的SPARQL查询。首先,查询语言模型(a);然后,对不完整的知识图谱进行查询,并获得结果(b);另外SPARQL查询被翻译成多种自然语言语句,这些语言语句在“关系模板生成”步骤中由语言模型完成;语言模型返回多个单词列表以及每个单词(c)的置信度值;然后将这些列表合并为一个列表(d),并根据知识图谱类型信息(e)使用我们的语义过滤步骤进行过滤。此外,执行阈值处理,削减不相关的结果(f);最后,将语言模型和知识图谱的结果合并(g)并返回给用户。
关系模板生成
作为查询语言模型以获取相关知识的第一步,需要将SPARQL查询转换为带有[MASK]标记的自然语言语句。在这项工作中采用自动生成的句子思想,并在预处理步骤中针对知识图谱的每个关系自动提取候选句子并对其进行评分,以生成相关句子模板。这样的模板可以具有以下格式:“[S]出生于[O]”,用于出生地关系,而[S]被查询的主题实体替换,或[O]被对象替换。生成句子模板不是在查询时执行,而是一个预处理步骤。
附加上下文段落。通过向查询语句提供额外的上下文信息,可以进一步提高语言模型的预测质量。对于查询中的每个实体,文章已经从相应的Wikipedia摘要中提取了前五个句子,并使用BERT的[SEP]令牌将其添加到了生成模板中。与现有工作相比,文章将自动模板生成和上下文段落检索结合在一起,从而提高了结果质量。
查询语言模型并组合结果
现在使用多个句子模板以及相应的上下文段落,以从语言模型中获得对应查询的可能答案。由于可能的答案实体标签可能包含多个单词,因此文章使用单个[MASK]标记构成查询以返回可能的单个单词实体,还要使用多个[MASK]标记进行查询。文中将结果列表中所有可能的单词组合连接起来,并检查是否已创建知识图谱中的有效实体标签,这一步能够过滤掉大部分无法映射到任何实体的预测单词。
汇总来自多个模板的结果。单个查询的不同句子模板导致每个结果实体具有不同概率值的独立结果列表。文中首先简单地合并列表,如果一个实体出现在多个列表中,则选择最大概率。此外,还比较在多个列表中出现的每个实体的最大概率和最小概率,如果它们的差值超过设定的阈值,则该实体不会进入最终结果列表。
语义类型过滤
大多数知识图谱为实体提供了非常详细的类型层次结构,文章将其用于进一步过滤语言模型结果。在语义类型过滤步骤之后,仍然可以得到具有相同实体标签的多个可能的答案实体,对于此类罕见情况,文中执行了额外的实体消歧步骤,使用流行度过滤器排除了极为罕见的实体。具体为,当实体在整个知识图中从不出现为对象实体时,将其排除;如果存在多个同音异义词,则返回最流行的实体作为答案。
阈值设定与结果返回
作为返回结果列表之前的最后一步,文中执行阈值确定过程以确保仅将高质量结果返回给用户。文中执行了两种不同的阈值机制,通过预测值之间的统计异常值分析为每个查询动态选择第一阈值,如果语言模型未返回正确答案,则动态阈值方法将不起作用。因此还选择了一个对所有查询均有效的附加静态阈值,该阈值是通过对不完整知识图中已经存在的已知结果的概率求平均,也可以对语言模型结果列表中的已知结果概率求平均值。最后,文中将不完整知识图谱的结果列表与基于语言模型的管道的结果列表结合在一起,并消除重复项。
实验
数据集基于2020年2月6日的Wikidata Truthy dump,实验仅对三元组进行评估,其中主语和宾语是具有rdf : label关系的实体。实验通过查询语言模型并删除不完整的KG中已经存在的答案三元组来分别评估每个查询,对于其余的其他结果计算精度和召回率值。报告的结果是返回其他结果的所有查询的平均精度和召回值。
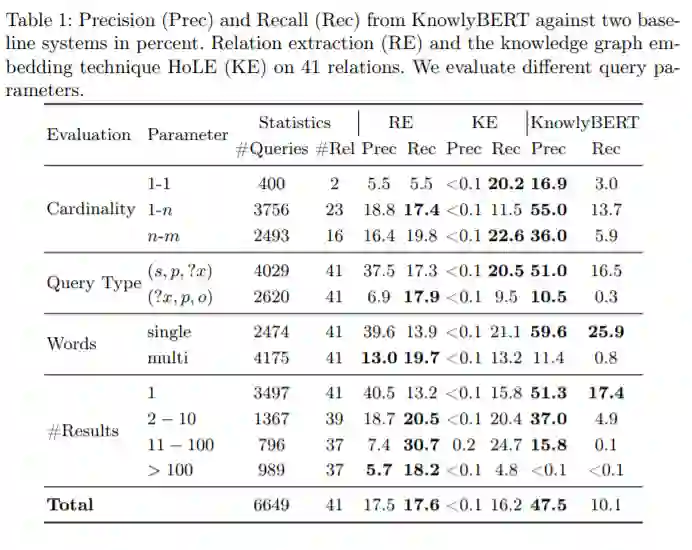
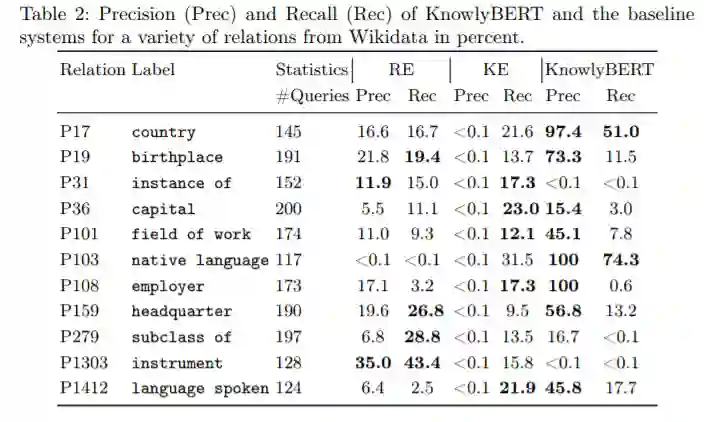
表1概述了KnowlyBERT和两个基线系统的精度和召回率。最后一行中描述了的总精度和召回率值,KnowlyBERT的平均精度达到47.5%,比其他两种方法的精度高出30%以上。与关系提取基准(RE)相比,该方法极大地提高了精度,但是与RE基准的17.6%相比,方法的召回率略低,为10.1%。在表2中给出了各种关系比较的实验结果。
总结
这项工作中提出了一种混合的语言知识模型查询系统,该系统使用语言模型来应对现实世界中知识图谱的不完整性问题。该工作不会像以前的工作那样污染知识图谱的质量,并且在必要时仍可以帮助提供完整的结果。在现实知识图谱上的查询实验表明,语言模型是减少不完整知识图谱和完整结果集之间差距的一种很有前途的方法。
OpenKG
开放知识图谱(简称 OpenKG)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenKG 网站。



