半监督深度学习训练和实现小Tricks
加入极市专业CV交流群,与 10000+来自港科大、北大、清华、中科院、CMU、腾讯、百度 等名校名企视觉开发者互动交流!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。关注 极市平台 公众号 ,回复 加群,立刻申请入群~
临近毕业,忽然想实现一下一些比较经典的半监督深度学习算法。恰逢一周前有个师妹问我有没有关于半监督深度学习训练技巧的文章,我一想,好像没有,便想自己写一篇。
Talk is cheap, show you my code:
https://github.com/iBelieveCJM/Tricks-of-Semi-supervisedDeepLeanring-Pytorchgithub.com
实现了几个比较经典的半监督深度学习算法,包括 PseudoLabel 2013[1], PI model[2], Tempens[2], MeanTeacher[3], ICT[4] 和 MixMatch[5]。代码刚整理完,可能还有些小问题,请多见谅~(没想到整理代码比写代码还累...orz)
言归正传,本文旨在分享一些我在训练和实现半监督深度学习模型时所发现的一些小Tricks,并没有什么太多理论,只是一些经验,也没有太多实验去支持(毕竟也就写了一周,repo上的一些代码我自己都没完整跑过...orz),大家就看看,希望能对大家有所启发。
注:下面给出的所有模型的实验结果,几乎都在同一实验参数下得出,以方便公平比较,并不是按照论文给出的最佳参数进行训练的。若想复现论文结果,请自行调参。
1. 默认优化参数
第一个我想分享的是,默认优化参数,如下:
-
优化器: SGD + lr =0.1+ momentum =0.9;或 Adam+ lr =1e-3 -
学习率策略: Cosine 学习率退火;或 学习率 warmup -
Batch中有标签和无标签数据比例:1:1,即在一个batch中,无标签样本量和有标签样本量相等
没有太多的惊喜成分,就是常用的优化配置,但在初始构建一个半监督深度学习模型的时候,也够用了。想要更多的提升,也可以从这个默认的配置进行寻参。
我通常直接使用 SGD+Cosine退火,使用Cosine退火而不是多步衰减是因为懒得调参,效果也相差不大。
当你的半监督模型需要稀疏地更新样本的时候,例如CCL[6],可以尝试 Adam 优化器,或许会有更好的效果。
很多情况下,例如样本量比较少(250个有标签样本的Cifar10实验时),我都建议尝试学习率warmup策略,可能会有奇效(e.g. PI model)。学习率warmup策略会使得模型稳定收敛到不错的性能。
2.两种数据输入方式
讲这个内容前,请容我介绍一些半监督深度学习代价的基本形式:
其中, 为有监督代价函数,通常为交叉熵代价。 为无监督代价函数,也是不同半监督深度学习模型的区别所在。
由于 是无监督代价函数,可以作用于有标签数据和无标签数据,因此无监督代价函数的输入出现了两种不同实现方法。在一个batch中,令 为输入 的数据。
-
方式v1:
中有标签数据和无标签数据按固定比例混合输入。即 ,其中 为batch中的有标签数据和无标签数据。
-
方式v2:
,即 为整个数据集的随机采样,因此不能保证有标签数据和无标签数据的比例,甚至会出现没有有标签数据的情况。
从目前CIFAR-10实验情况来看,方式v2更好(并不保证orz):
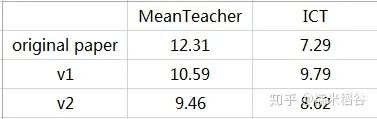
Test error of CIFAR-10 with 4000 labeled samples
3.使用 epoch pseudo labels
Pseudo-Label 2013 提出,使用网络的预测最大概率的类别,作为无标签数据的伪标签。具体解释参考我前面的文章《半监督深度学习小结》,https://zhuanlan.zhihu.com/p/33196506)。
此前我理解为,使用当前的预测类别,作为当前无标签数据的伪标签,我称为 iteration pseudo labels,但效果不太理想。
后来,Tempens[2]源码的实现,是使用上一个 epoch的预测类别,作为当前epoch中无标签数据的伪标签,即 epoch pseudo labels。
CIFAR-10的实验结果对比如下:
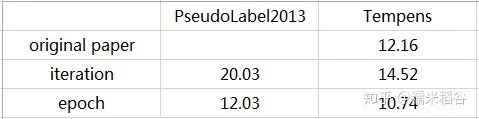
Test error of CIFAR-10 with 4000 labeled samples
可以看到,使用 epoch pseudo labels 有非常明显的提升。因此建议大家实现基于伪标签的半监督深度模型时使用 epoch pseudo labels 而不是 iteration pseudo labels。
4. 使用 MixUp loss
最近,使用 MixUp[7]+consistency regularization 成为了新的 SOTA 方法,代表有 ICT和MixMatch。半监督中使用的 Mixup 数据增强形式如下:
即通过线性插值的方式产生新的数据。但是如何利用插值数据有4种方式,令模型为 :
其中,CE为交叉熵代价函数,MSE为均方误差代价函数。
CIFAR-10的实验结果对比如下:
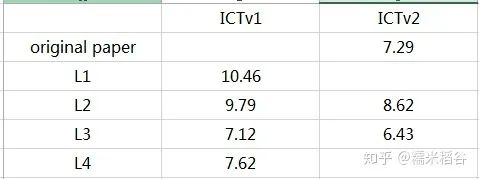
Test error of CIFAR-10 with 4000 labeled samples
其中,ICTv1表示使用第一种数据输入方式,ICTv2表示使用第二种数据输入方式。
从实验结果上看到,L3代价项的效果是最好的,而且对代价进行插值的 L3 和 L4 明显比 L1 和L2 的效果好。
半监督深度学习从入门到放弃之路,我终于快走到结束了,希望此文能对想入门的同学有所帮助。
参考
1.Pseudo-Label : The Simple and Efficient Semi-Supervised Learning Method for Deep Neural Networks
2.Temporal Ensembling for Semi-Supervised Learning https://arxiv.org/pdf/1610.02242v1.pdf
3.Mean teachers are better role models https://arxiv.org/pdf/1703.01780.pdf
4.Interpolation Consistency Training for Semi-supervised Learning https://arxiv.org/pdf/1903.03825.pdf
5.MixMatch: A Holistic Approach to Semi-Supervised Learning https://arxiv.org/pdf/1905.02249v2.pdf
6.Certainty-Driven Consistency Loss for Semi-supervised Learning
7.MixUp: Beyond Empirical Risk Minimization https://arxiv.org/pdf/1710.09412.pdf
推荐阅读:


△长按添加极市小助手

△长按关注极市平台,获取最新CV干货
觉得有用麻烦给个在看啦~



