让模型学习人类语言的本质,结果它只学会了做一个复读机
作者 | 杨晓凡
编辑 | 唐里
OpenAI 的长期目标之一是使用强化学习解决真实世界问题的时候也能保持实用性和安全性(这一点和 DeepMind 有类似之处),那么在 OpenAI 看来,使用语言的能力就是达到这个目标的关键因素之一。
另一方面,在目前的强化学习研究中大家观察到一种现象,就是用明确的规则约束、用预定义的反馈激励智能体的时候,它们经常反而会学会使用环境和规则中的漏洞,和人类本来设定的目标背道而驰。所以另一种思路是让智能体模仿人类,根据人类的偏好、把人类的一次次评价作为学习信号进行学习。此前这方面的研究主要针对简单的模拟环境(游戏或者机器人控制任务,比如之前 OpenAI 和 DeepMind 合作的 你做我评)。
向人类牙牙学语
OpenAI 这次想做一个大胆的尝试,把「使用语言的能力」和「根据人类的偏好学习」两者结合起来,尝试这种思路对于语言这种复杂的内容能否奏效——就是从结果出发,让模型学会人类觉得喜欢的表达方式;另外,这样学习到的语言的拓展和说理能力也能帮助我们探索人类语言偏好背后的缘由。
在这项研究中,OpenAI 在两个常见的语言任务上尝试了「根据人类的偏好学习」:一,在 BookCorpus 数据集上用正面情感或者客观描述词汇续写文本,即「带风格的续写」;二,在 TL;DR 和 CNN/Daily Mail 数据集上学习文本总结。这两个任务都可以看作文本补全这个大类中的任务:给定某个文本 X,让模型补充紧跟着的文本 Y。
OpenAI 的实验从含有 774M 参数的预训练 GPT-2 模型开始。他们对预训练模型进行精细调节,方式是让人类标注员从模型生成的每组四个样本中选择最好的一个(而不是传统的精细调节中以固定的、已经标注好的数据进行监督学习;这种做法实质上是对给模型的不同行为给予不同的反馈,所以实际上更像强化学习,OpenAI 也设计了相应的强化学习框架的反馈组件)。
由于 GPT-2 已经有不错的文本生成、续写能力(正如我们在最开始的 GPT-2 报道文章中介绍的),所以前一个带风格的续写任务的精细调节只经过了 5000 次样本选择就达到了人们认为非常好的表现;对于后一个总结任务,模型经过 6 万组样本的精细调节以后学会了从给定的文本里重复整个句子来作为总结(不过它能够跳过作用不大的引言)。重复整个句子作为总结确实是确保准确度的一个好方法,不过出现这个结果也可能是因为这个任务的标注人员们(选择样本的人们)在偷懒;他们依赖这样简单的重复模式评价模型输出的结果好不好,结果让模型也学会了这样偷懒。
下面我们具体看看精细调节前后的模型在任务中的表现具体如何。
带风格的续写
带风格的续写又分为两个子任务,带正面情感的续写,客观描述的续写。我们各随机摘录四个例子。
带正面情感的续写
例 1
背景文本:她看起来很累,她刚刚哭过。她边上坐着的那个男人身材中等,不高不矮,头发凌乱得仿佛要有了艺术感。他穿了一件灰色的外套,但是他还戴了一条有火星人马文图案的黑色领带,让他的衣着没有那么严肃了。我认得他。
原模型续写:我刚刚来到这个城市的那一天就要抓我的人就是他。
精细调节后续写:他对着我微笑了一下,我也笑了一下。他看起来还算得上高兴,以他这个岁数来说。
例 2
背景文本:「现在告诉我是怎么回事吧。」他慢慢靠过来,用舌头在她嘴唇上绕了一圈。尝起来有糖和巧克力的味道,恰到好处。他热烈地吻她,他的舌头也温柔地钻进她的嘴里。
原模型续写:「是个水果沙拉。」「你的心情真不错,」他喃喃道。
精细调节后续写:这个吻如此令人满意、令人愉悦。她全身的每根神经都感觉到了这种满足。
例 3
背景文本:「一般我都会把一个人最喜欢的东西在他眼前摧毁」,他边说边把下巴凑向 Cowboy Binder 和 Barry Correda 两个人,「但对你们,我得想想办法了。因为你们什么都没有。你们一点钱都没有。
原模型续写:你没有老婆。你没有工作。你没有家。
精细调节后续写:你是个不错的小伙子,你也有很多潜力,但你还没准备好做一个明星。
例 4
背景文本:她想鼓足勇气和他一起去,但是她脑海中有涌现出最好不要参与的想法。「我已经把这份工作的联系人信息给他了。
原模型续写:我告诉他你会帮我的。」「我不想这么做。」她说
精细调节后续写:如果有什么变化,我们会告诉他的。」「好啊。」她对他笑着说。
客观描述的续写
例 1
背景文本:她棕色的眼睛根本没往他这边看。她的眼神直接绕过他,望向房间里面。「Jeff 哪去了?」「不知道。」这个回答终于让她看向他,但她又很快挪开,用眼神继续在房间里搜索。
原模型续写:Grant 站在那里盯着她。「你还好吗?」他问道。
精细调节后续写:她缩起了肩膀,她的脚步在地板上行进了一段然后停在他面前,她的嘴唇闭得紧紧的。
例 2
背景文本:问题来了,我要怎么才能把她杀了?如果她尖叫,别人就会知道我来了。虽然我整个人都充满了把她的喉咙一割两半的念头,但我得冷静行事。我松开刀柄,站着,望着。
原模型续写:她还是没有出声,她的眼镜看着游泳池。我得想办法让她出来。
精细调节后续写:有一只手伸出来抓住了她,把她提起来直到双脚离地。她又尖叫了起来,腿不停发抖。
例 3
背景文本:他非常有礼貌,吃早餐的时候一直没有说话而是静静听着。我决定保留对他的意见,他好像也保留了对我的意见。Jacob Greene 要更年长一些,大概五十来岁,像个圆面包一样壮。
原模型续写:他的头发剃得很短,他的胡子只有稀疏凌乱的一小撮。
精细调节后续写:他秃头,而且秃得非常厉害,他的衬衣也偏小,勒在他的肩膀上。
例 4
背景文本:他们似乎一开始就不顺利。Gizmo 只希望情况可以逐渐改善,但他也担心他们和安全部部长的关系永远没有机会变好了。
原模型续写:显然,这两个人根本就是水火不容。
精细调节后续写:安全部部长走进了会议室中,两只手紧握在背后。
为模型精细调节提供标注(四选一)的人类标注员们也对训练后的模型进行了评价。相比于仅仅完成了预训练的 GPT-2 模型,他们认为精细调节后的模型在带正面情感的续写任务中有 88% 的情况都更好,在客观描述的续写任务中则有 86% 的情况表现更好。
文本总结
后一个文本总结任务也分为了两个子任务,CNN/Daily Mail 数据集上的报道文章总结,以及 TL;DR(「太长,不看」)数据集上的 Reddit 讨论的总结。
这两个任务就更难一些了,OpenAI 的主模型训练用到了六万个四选一结果。而且他们还需要在线数据收集,也就是说随着模型的总结策略变化,有所改变之后的模型要继续用最新的策略生成新的结果供人类标注,整个过程是动态的、持续的,与强化学习类似。要采用这种方式的原因是,离线样本收集中,所有的样本都是最初的 GPT-2 模型生成的,人类标注员只能从这些质量不高的样本中选择,所以模型的改进也非常有限。
据人类标注员们评价,这次的模型也有很好的表现。不过,由于人类标注员们很喜欢其中一个「复制文本前三句话作为总结」的基准模型的结果(虽然这个模型确实能在所有基准模型里排在前三位,但还是说明标注员们在偷懒),就导致这样学习出的 GPT-2 模型也倾向于这样做。不过,如果把标准的有监督精细调节和人类在线标注精细调节相结合,模型的 ROUGE 分数就能排进前三位。
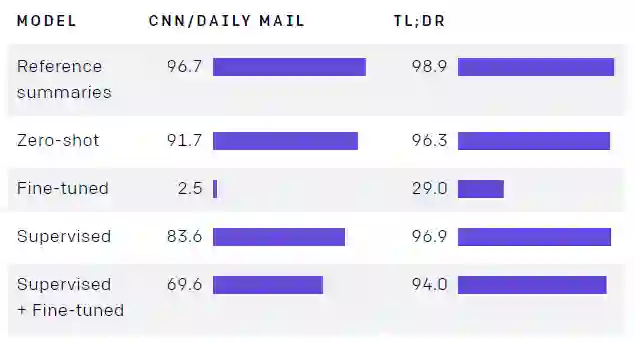
OpenAI 的研究人员们一共进行了四个模型的对比,原始预训练 GPT-2(即无精细调节)、人类标注、有监督学习、有监督学习+人类标注。对比的方面主要有新颖性(novelty)和准确性(accuracy)。
新颖性
如上面所述,人类标准训练出的模型倾向于直接从文本开头复制句子,所以这个模型的总结句子的新颖性是最低的。
不同模型结果的新颖性对比

人类标注精细调节出的模型复制文本的来源
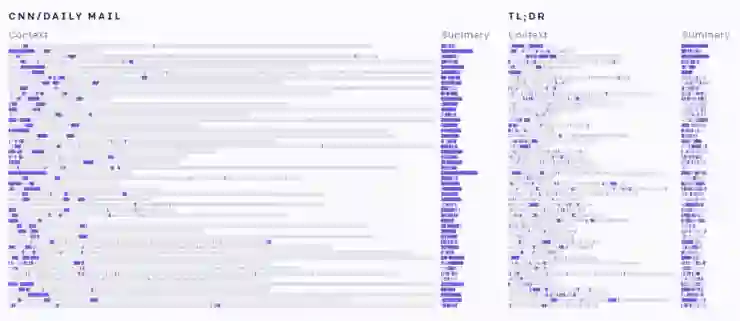
有监督学习+人类标注精细调节出的模型复制文本的来源
不过另外也需要说明,虽然原始预训练 GPT-2 和有监督学习的 GPT-2 模型输出的文本中直接复制的痕迹最轻微(新颖性最高),但它们输出的文本表达的内容也新颖性最高 —— 也就是说它们的总结并不准确,这仍然不是我们希望看到的。
准确性
选择 30 篇文章评价模型总结的准确性,得到的结果就是另一种样子了。

毫无疑问,人类标注精细调节出的模型(那个直接复制的模型)准确性最高;其次是有监督学习+人类标注的。我们至少有两种方式解读这个结果。第一种,直接复制是最容易的保证准确的方式。由于 OpenAI 的研究人员们对标注员提出的要求是准确性优先,所以当模型因为直接复制而表现出了好的准确性的时候,这种行为就会得到鼓励,模型就会越来越多地直接复制原句 —— 完全复制同时也意味着没有额外的增删信息,自然就比较准确。
不过这种解释还不完整:这个精细调节出的模型和「复制文本前三句话作为总结」的基准模型都会被标注员看作是比较好的模型。但实际上这个结果并不 是 OpenAI 的研究人员们本来的打算,他们认为来自有标注数据集的那些有部分删减、有重新表述的总结才是比较好的结果,他们希望模型以这些为样本学习,也把这些样本提供给了人类标注员作为参考。然而事情的发展和他们的预期并不相同:和任何时候一样,收钱办事的人类标注员都会找偷懒的办法,为了尽快完成任务,他们找到的又快又差不了多少的方式是「如果文本总结是直接复制的,那肯定是比较准确的」,跳过了仔细阅读和重新总结的步骤,然后也就让模型学会了这么做(真是令人无奈)。
吃一堑长一智
和以往一样,OpenAI 的研究人员们也总结了这次实验后的经验教训。
一,在线收集数据很难
虽然实验表明在线收集数据(随时用最新的模型生成样本供人类标注员选择)带来的模型表现是最好的,但这也带来了许多麻烦:
软件系统的复杂性。与模型更新交错的数据收集过程、反馈模型训练训练过程、强化学习精细调节三件事分开做的时候各自都不难,但是要让它们一起在同一个流程中运行就复杂得多了
机器学习的复杂性。任何一个机器学习组件如果出现了 bug 都会影响整个系统的正常工作,但是想单独隔离 debug 其中的某个组件又很不好做
质量控制问题。在线模型训练一般需要较短的延迟,比如 OpenAI 在这个实验中使用的在线数据标注平台是 Scale.AI,它能提供的数据生成到返回标注反馈的时间延迟是大约 30 分钟。但对于这样的短延迟,标注的质量控制很难做,标注数据的质量往往会随时间下降,而且往往直到训练过程完成之后开发人员们才会发现这个问题。
OpenAI 的研究人员们思考以后认为,离线数据收集和在线数据收集之间的一个合理的平衡点是分批数据收集:集中收集一批数据,然后训练模型,用新模型再收集一批数据,再用新数据训练模型。这种做法当然有更高的延迟,但是数据质量更高,而且这种方式下单条数据的标注成本也更低,OpenAI 甚至认为有机会从预训练模型开始做更多组不同的实验。
二,不明确的任务标准让数据标注变得很困难
标注质量控制并不是一个新问题,不过这次也有独特之处:一个样本是否单独看来是准确的、符合语法的、不冗长的、包含了关键点的,对任何一个标注人员来说他都能以自己的标准给出判断,但是要在两个总结结果之间做对比选择的话,长处短处之间的取舍就很难维持,更难在不同的标注人员之间保持一致了。事后看来,OpenAI 的研究人员们觉得可能还是重新设计一个能起到同样的效果、但更明确量化的标注标准比较好。比如,把现在的对比选择改成用文字表述其中的问题,也可以更进一步地为其中不准确的地方提出修改意见;也许不同的标注人员对于「哪个问题最严重」有分歧,但是「存在哪些问题」还是比较容易达成一致的,这还能起到一个附加的质量控制效果,让整个实验过程更顺利。(甚至还可以说,这种方式还能避免标注员们在选择过程中偷懒)。
三,Bug 会鼓励模型学习不好的行为
在文章一开始我们就提到,选择样本的过程相当于为模型的不同行为给予反馈,OpenAI 就设计了对应的强化学习框架的反馈组件。但由于他们一开始的设计中存在一个 bug,会在触发时反转反馈信号的正负。通常情况下正负相反的反馈会导致模型输出的文本不统一不连贯,但这个 bug 同时还会让 KL 惩罚的正负也相反。最后的效果就是模型仍然保持了很高的自然语言输出能力,但是在「带正面情感的续写」任务中输出的句子反倒偏向负面情感。
同时还有一个意想不到的状况是,OpenAI 给标注员的指导中要求他们给模型续写的色情内容打很低的分,由于 bug 的存在,这反倒鼓励了模型多写色情内容。最后的效果实际上挺惊人的,模型的语言能力非常优秀(并没有胡言乱语),然后它能续写出很精彩的「小黄文」(本来应该是要惩罚的行为)。由于这次的训练过程中 OpenAI 的研究人员们刚好在睡觉,所以当他们醒来的时候模型已经训练完毕了,他们面对这个模型的时候想必是哭笑不得的。
事后的教训就是,他们认为应该在模型训练全过程中设计一个类似丰田工厂的报警拉绳的机制,参与训练过程的任何一个标注员都可以在发现奇怪之处的时候进行报告并暂停训练流程。
总结与展望
OpenAI 这次探索了在两类自然语言任务中让模型根据人类的偏好学习。得到的结果一面好一面坏:续写任务里只收集了很少的样本就达到了很好的效果,而文本总结任务里收集了很多的样本却只训练出了精通复制粘贴的模型(好在它们会跳过不重要的词句)。「复制粘贴」的好处是真实性高,相比之下未经过精细调节的和直接使用有监督数据训练的模型输出的结果虽然语言自然但是会有模型自己创作的信息。OpenAI 认为其中的限制因素来自在线数据收集过程的机制设计,未来的实验中他们会尝试分批数据收集。
OpenAI 相信语言学习中的根据反馈学习、根据人类偏好学习从模型表现的角度和模型安全性的角度都很重要。对于模型表现来说,强化学习的过程可以让我们发现并纠正有监督学习中发现不了的问题,只不过强化学习中的反馈机制设计也可能对模型带来不好的影响。对于模型安全来说,反馈学习可以让「避免模型造假」之类的重要指标得到体现并强化,也是向着可说理、可拓展的模型的重要一步。
更多技术信息欢迎阅读论文原文☟
https://arxiv.org/abs/1909.08593
代码开源地址☟
https://github.com/openai/lm-human-preferences
via☞openai.com/blog/fine-tuning-gpt-2/,AI 科技评论编译

张钹院士:人工智能的魅力就是它永远在路上 | CCAI 2019
Facebook 自然语言处理新突破:新模型能力赶超人类 & 超难 NLP 新基准
巴赫涂鸦创作者 Anna Huang 现身上海,倾情讲解「音乐生成」两大算法
邮箱:jiawei@leiphone.com
微信:jiawei1066
《Machine Learning Yearning》是吴恩达历时两年,根据自己多年实践经验整理出来的一本机器学习、深度学习实践经验宝典。作为一本 AI 实战圣经,本书主要教你如何在实践中使机器学习算法的实战经验。

☟点击“阅读原文” 查看
可视化 OpenAI GPT-2 大型语言模型生成的过程



