AI Challenger开赛,千万量级数据开放,AI高手将上演巅峰对决

2017年9月4日,“AI challenger全球AI挑战赛”正式开赛,来自世界各地的AI高手,将展开为期三个多月的比拼,获胜团队将分享总额超过200万人民币的奖金,并获得顶级AI专家的指导。
大赛官网(challenger.ai)同步上线了训练数据集以及验证数据集,供参赛选手下载,进行算法设计、模型训练及评估。

参赛团队来自世界各地,包含多位国际顶级AI赛事冠军
“AI Challenger全球AI挑战赛”是由创新工场、搜狗和今日头条三家国内人工智能领域领军企业共同发起的竞赛活动,面向人工智能领域科研人才,致力于打造大型、全面的科研数据集与世界级竞赛平台。

自8月14日开放报名以来,AI Challenger平台已经汇聚了来自世界各地的参赛者。
来自高校的包括中国清华大学、北京大学、中科院、上海交通大学、复旦大学、中科大、香港科技大学、香港中文大学、台湾大学,美国康奈尔大学、佐治亚理工、纽约大学,英国剑桥大学、帝国理工学院,德国卡尔斯鲁厄大学,法国国立路桥学校,澳洲卧龙岗大学,日本早稻田大学。
来自公司机构的包括百度、蚂蚁金服、小米、搜狐、奇虎360、众安保险、平安科技、同花顺、陌陌、迅雷、中兴通讯、中国移动、中国电信、格灵深瞳、驭势科技、摩拜,微软、通用电气、英特尔、eBay、Micron、法国巴黎银行,还有神秘的公安部院所。
参赛者中也不乏曾经在各种大赛上叱咤风云的牛人,比如天池阿里移动推荐算法大赛冠军、滴滴DI-tech算法大赛冠军、ImageNet目标分类任务和定位任务双料冠军、中兴算法精英挑战赛冠军,IBM-滴滴编程马拉松大赛冠军,以及Kaggle大赛的众多优胜者。
开放千万量级科研数据集
本次大赛提供了百万量级的计算机视觉数据集、千万量级的机器翻译数据集,包括:超过1000万条中英文翻译数据、70万个人体骨骼关键点标注数据、30万张图片场景标注和语义描述数据。这是国内迄今公开的规模最大的科研数据集,已经在大赛官网(challenger.ai)上线,供参赛选手下载,进行算法设计、模型训练及评估。
(1)人体骨骼关键点数据集:此数据集是目前规模最大,场景、人物动作及身体遮挡情况最复杂的数据集。它使用含有人物的图片,对人体14个骨骼关键点分别作出标注,共有30万张图片,包含了超过100种复杂生活场景内的实际人物动作与姿态,标注人物个数达到70万量级,远超过MSCOCO的10万人、以及MPII的4万人量级。该数据集将挑战现有主流算法的鲁棒性。
基于此数据集的研究成果可以被直接应用于动作分类和识别,动作捕捉,图像和视频内容理解,人机交互,自动驾驶(行人动作和意图识别),安防(异常行为检测),无人零售(消费者行为理解)等领域。
(2)图像中文描述数据集:此数据集是目前规模最大、场景和语言使用最丰富的图片中文描述数据集,共有30万张图片,150万句中文描述,使用了超过100种复杂生活场景的含有人物的图片,而且此数据集的语言描述标注更符合中文语言使用习惯。相对于MSCOCO和Flickr8k-CN,在完整描述图片主体事件的基础之上,该数据集创新性的引入了形容词和中文成语,用以修饰图片中的主要人物及背景事件,大大提升了描述语句的丰富度。本数据集的标注量远大于Flickr8k-CN(8000张图),巨大的数据量和复杂的图片场景将直接挑战现有算法的可用性。
基于此数据集的研究成果可以被直接应用于图像与视频语义理解、图像与视频自动标注、图像与视频内容检索、人工智能辅助教育、机器人视觉、盲人辅助等人工智能相关领域。
(3)英中翻译数据集:此数据集的训练数据量达到1000万句对,每一条数据由一句英文和对照的中文构成,是最大规模的口语领域英中比赛数据集。训练数据全部经过译员检查和矫正,句正确率在97%以上,英中双语句对对照工整、质量高、噪音低。
基于此数据集的研究成果可以被直接应用于机器翻译,尤其是口语机器翻译、同声传译应用。
开放数据集能给AI人才带来什么帮助?
在人工智能领域,数据的质和量是科学研究与产品技术研发的核心。高质量训练数据对机器学习模型的建立和优化有关键性的作用。建立大规模、高水准的标注数据集,是推动AI科研和技术前进的驱动力。
创新工场、搜狗、今日头条三方在“AI Challenger 全球AI挑战赛”发布会上共同宣布社会责任宣言说:“数据、算法、计算能力是人工智能的三大基石,其中,数据更是人工智能科研最宝贵的资产。没有足够好的数据,就无法取得世界顶级的科研成果。在此方面,学术界和创业团队所能获得的数据资源通常远少于产业界中的顶级企业。因此,将高质量的数据集建设与科学研究、技术产品研发、人才培养有效结合,对人工智能发展具有重大意义,也是身为产业先驱应尽的一份社会责任。”

未来三年,主办方将投入数千万基金,解决数据集缺失的问题,为人工智能科研提供海量数据及算法竞赛、人才交流平台,辅以强大的学术界和产业界专家指导,全力支持与帮助国内外的高校、研究机构、产业界的研发团队。
三家主办方将持续投入,建设和发布更大规模的AI前沿领域高质量数据集,涵盖自动驾驶、智慧医疗、智慧金融、机器人等行业应用中的核心AI需求,主办世界级的年度AI竞赛,吸引世界范围内的高端AI人才,促进人工智能科研生态的持续健康发展。
大赛奖金超200万,还有顶级专家评委助阵
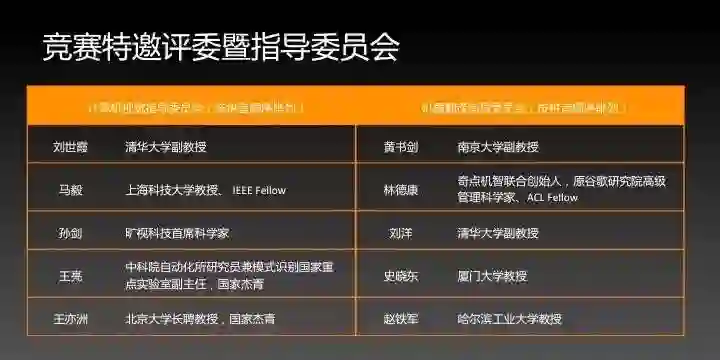
主办方为首届竞赛准备了超过200万元人民币的奖金,供参赛优秀选手分享。参赛选手还有机会进入三家主办方工作、实习或获得投资,并有机会在国际顶级学术会议上分享获奖心得,还将获得包括上海科技大学教授马毅、旷视科技首席科学家孙剑、前Google研究院高级管理科学家林德康等十余位国内外人工智能领域顶级专家评委的指导和评价。
本届AI Challenger大赛的主赛道竞赛分别是:人体骨骼关键点检测竞赛、图像中文描述竞赛、场景分类竞赛、英中机器文本翻译竞赛、英中机器同声传译竞赛。大赛还在持续推出更丰富的实验赛道、实验数据集,敬请关注大赛官网(challenger.ai)
赛程安排如下:
9月4日10:00,开放训练数据集以及验证数据集。
10月31日23:59:59,大赛报名截止。
12月3日23:59:59,各项竞赛的排名将决定最终的成绩排名。
12月中旬,大赛主赛道各项竞赛的最终榜单排名前五的团队将受邀到现场答辩并参加颁奖典礼。
大赛期间,主赛道及实验赛道还将有双周赛或单周赛并有奖金。
推出首个实验赛道:虚拟股票趋势预测
为了让大赛有更高的参与度,同时探索更前沿的AI科技,本次大赛将持续推出更丰富的实验赛道和实验数据集。AI Challenger 的首个实验赛道,是虚拟股票趋势预测,通过对大规模历史数据建模,预测虚拟股票未来趋势,这个实验赛道适合有大数据背景、深度学习的初中级人士参与。
发起这个实验赛道的创新工场表示,金融市场是由大数据驱动的行业,也是最快速被AI冲击的行业之一。金融及相关数据可以说是目前最容易获得、最海量公开、也是非常适合用于机器学习的数据来源。此次以“虚拟股票趋势预测”为题,通过开放数据集和竞赛的形式帮助广大兴趣爱好者入手机器学习,作为AI Challenger第一届大赛中相对低门槛的入门实验赛道。同时,金融AI应用对于科研来说有一定的指导意义。例如,虽然机器学习是目前金融趋势预测、量化投顾的趋势,但基于传统运筹学、统计学思路的方法也有其发展空间,创新工场成立人工智能工程院以来接触到的很多高校中,均有针对这个领域开展研究的老师。接下来三个月,实验赛道在赛题中将公开的脱敏数据,将有助于这些研究者判别科研成果的价值,这个实验赛道便是将大众熟悉的真实场景和前沿科研技术相结合的一个重点尝试。

对股票价格趋势的预测是金融领域极为复杂和极为关键的问题。有效市场假说认为股票价格趋势不可能被预测,然而真实市场由于各种因素的存在并不完全有效,这对于股票市场而言相当于一种“错误”。AI Challenger的虚拟股票趋势预测实验赛道,为参赛者提供了大规模的股票历史数据,从而可以通过集合大家的智慧来纠正股票市场的这些“错误”。
本竞赛数据来源主要以股票及新闻数据为主。竞赛每周一轮。选手通过训练模型,对虚拟股票走势进行预测。每轮结束时统计该轮队伍排名。最终累计每周积分决出最终的大奖。冠军将获得5万元人民币的奖励。同时,每周都会对该轮排名前三的队伍颁发奖金。该实验赛道由创新工场发起、管理和运营,奖励由创新工场提供。
另外,大赛主办方还将努力为条件有限的参赛选手提供免费GPU资源的支持,帮助他们圆梦AI,选手可在各赛道相关数据集下载的页面进行申请。此次同步上线的还有汇集了全球优秀AI技术学习资源的“教程”栏目,并将持续更新,帮助AI人才更好学习成长。
在此特别感谢大赛AI GPU云合作方UCloud专门为AI Challenger大赛组织资源、技术开发和服务团队,帮助更多的AI人才能够实际动手利用大数据集进行实践。特别感谢在线教育合作方Udacity为大赛提供优质学习资源,并向全球AI人才推荐AI Challenger大赛。还有更多高校、机构、公司、个人为大赛提供了各种各样的帮助,让AI Challenger获得了大量的资源和支持,从而能更好的帮助更多的AI人才。深深地感谢这些贡献者们!
科研大数据,智慧竞技场!快来challenger.ai学习、参赛吧!
小提示:比赛组队、参加每周AI技术大神分享会,请加大赛微信小助手 aiczhuhou ,或扫码加入大赛官方微信群!

关于创新工场

创新工场是由李开复博士于2009年9月创办的创业投资机构,旨在用全方位的创业服务帮助中国年轻创业者打造世界级企业。创新工场首创“投资+孵化”模式,凭借专业化、国际化的特色和优势,已经迅速成长为国内最具影响力的科技型创业投资机构之一,目前管理超过80亿的双币基金。从2013年起,创新工场所投AI公司超过30家,累计投资金额超过1亿美金。2016年9月成立创新工场人工智能工程院,李开复博士亲任院长,全面推进人工智能领域的人才培养、创业项目孵化、开放生态系共建、科研与产业对接等系列工作。
关于搜狗

搜狗成立于2004年,是中国互联网行业的创新标杆性企业。目前搜狗月活跃用户数仅次于BAT,是中国用户规模第四大互联网公司。在“自然交互+知识计算”的人工智能战略引领下,搜狗以“让表达和获取信息更简单”为使命,在语音、图像识别,翻译等领域取得了诸多突破性进展。 2016年搜狗捐赠清华大学1.8亿元成立“天工智能计算研究院”,共同致力于人工智能前沿技术的研究。作为中国领先的人工智能企业,搜狗希望以创新的技术型产品为用户不断创造价值。
关于今日头条

北京字节跳动科技有限公司成立于2012年3月,是一家技术驱动的移动互联网公司,公司的主要产品“今日头条”资讯客户端,是一款基于数据挖掘技术的个性化推荐引擎产品。“今日头条”致力于帮助用户在移动互联网上方便快捷地获取最有价值的信息,它会根据用户的兴趣为其推荐内容,这是对传统信息分发方式的一次巨大颠覆。 “今日头条”面市后,迅速获得市场认可,长期占据苹果应用商店新闻类榜首。目前已有超过80万个个人、组织开设头条号。
合作伙伴
选手社区


在线教育平台

云计算平台

智慧校园平台


● Facebook AI“失控”事件,一个瑕疵引发的妖魔化闹剧
● 李开复的美国来信





