资讯 | 总奖金 200 万的 AI Challenger 开赛,可申请免费 GPU 资源

记者 | 周翔
8 月 14 日,创新工场、搜狗和今日头条联合宣布共同发起“AI Challenger 全球 AI 挑战赛”。其中,CSDN 作为选手社区,为大赛提供支持。(点击查看《奖金200万,千万数据规模,创新工场搜狗今日头条联合发起迄今国内最大AI挑战赛》)
昨日( 9 月 4 日),首届“AI Challenger 全球 AI 挑战赛”于正式拉开帷幕,各路高手将展开为期三个月的比拼,并于 12 月中旬进行总决赛巅峰对决。获奖团队将分享合计超过 200 万人民币的奖金。
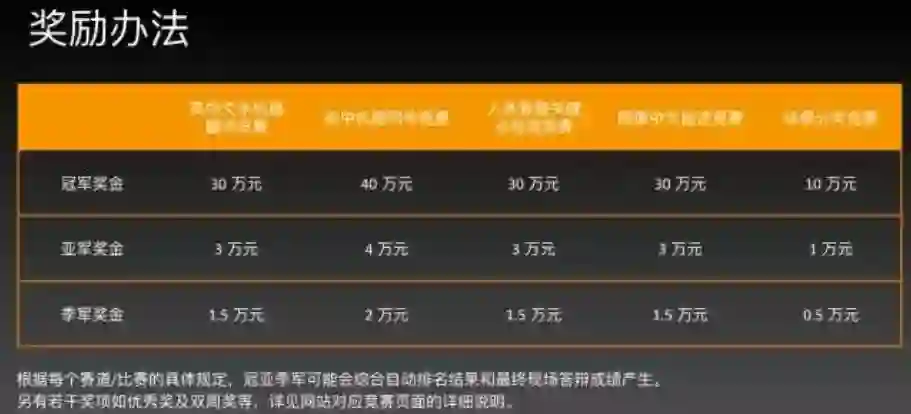
除了奖金之外,参赛选手还有机会进入三家主办方工作、实习或获得投资,并有机会在国际顶级学术会议上分享获奖心得,还将获得包括上海科技大学教授马毅、旷视科技首席科学家孙剑、前 Google 研究院高级管理科学家林德康等十余位国内外人工智能领域顶级专家评委的指导和评价。
另外,大赛主办方表示,将努力为条件有限的参赛选手提供免费 GPU 资源的支持,帮助他们圆梦AI,选手可在各赛道相关数据集下载的页面进行申请。
9月4日10:00,开放训练数据集以及验证数据集。
据AI科技大本营了解,AI Challenger 的首个实验赛道,是虚拟股票趋势预测,通过对大规模历史数据建模,预测虚拟股票未来趋势,这个实验赛道适合有大数据背景、深度学习的初中级人士参与。
发起这个实验赛道的创新工场表示,金融市场是由大数据驱动的行业,也是最快速被AI冲击的行业之一。金融及相关数据可以说是目前最容易获得、最海量公开、也是非常适合用于机器学习的数据来源。
作为 AI Challenger 第一届大赛中相对低门槛的入门实验赛道,金融AI应用对于科研来说有一定的指导意义。例如,虽然机器学习是目前金融趋势预测、量化投顾的趋势,但基于传统运筹学、统计学思路的方法也有其发展空间,创新工场成立人工智能工程院以来接触到的很多高校中,均有针对这个领域开展研究的老师。接下来三个月,实验赛道在赛题中将公开的脱敏数据,将有助于这些研究者判别科研成果的价值,这个实验赛道便是将大众熟悉的真实场景和前沿科研技术相结合的一个重点尝试。
对股票价格趋势的预测是金融领域极为复杂和极为关键的问题。有效市场假说认为股票价格趋势不可能被预测,然而真实市场由于各种因素的存在并不完全有效,这对于股票市场而言相当于一种“错误”。AI Challenger的虚拟股票趋势预测实验赛道,为参赛者提供了大规模的股票历史数据,从而可以通过集合大家的智慧来纠正股票市场的这些“错误”。
本竞赛数据来源主要以股票及新闻数据为主。竞赛每周一轮。选手通过训练模型,对虚拟股票走势进行预测。每轮结束时统计该轮队伍排名。最终累计每周积分决出最终的大奖。冠军将获得5万元人民币的奖励。同时,每周都会对该轮排名前三的队伍颁发奖金。该实验赛道由创新工场单独发起、管理和运营,奖励由创新工场提供。
创新工场方面表示,自 8 月 14 日开放报名以来,AI Challenger 平台已经汇聚了来自世界各地的参赛者。
来自高校的包括中国清华大学、北京大学、中科院、上海交通大学、复旦大学、中科大、香港科技大学、香港中文大学、台湾大学,美国康奈尔大学、佐治亚理工、纽约大学、英国剑桥大学、帝国理工学院,德国卡尔斯鲁厄大学,法国国立路桥学校,澳洲卧龙岗大学以及日本早稻田大学。
来自公司机构的包括百度、蚂蚁金服、小米、搜狐、奇虎360、众安保险、平安科技、同花顺、陌陌、迅雷、中兴通讯、中国移动、中国电信、格灵深瞳、驭势科技、摩拜,微软、通用电气、英特尔、eBay、Micron、法国巴黎银行,还有神秘的公安部院所。
参赛者中也不乏曾经在各种大赛上叱咤风云的牛人,比如天池阿里移动推荐算法大赛冠军、滴滴DI-tech算法大赛冠军、ImageNet 目标分类任务和定位任务双料冠军、中兴算法精英挑战赛冠军,IBM-滴滴编程马拉松大赛冠军,以及 Kaggle 大赛的众多优胜者。
本次大赛提供了百万量级的计算机视觉数据集、千万量级的机器翻译数据集,包括:超过1000万条中英文翻译数据、70万个人体骨骼关键点标注数据、30万张图片场景标注和语义描述数据。这是国内迄今公开的规模最大的科研数据集,已经在大赛官网(challenger.ai)上线,供参赛选手下载,进行算法设计、模型训练及评估。
1. 人体骨骼关键点数据集:此数据集是目前规模最大,场景、人物动作及身体遮挡情况最复杂的数据集。它使用含有人物的图片,对人体14个骨骼关键点分别作出标注,共有30万张图片,包含了超过100种复杂生活场景内的实际人物动作与姿态,标注人物个数达到70万量级,远超过MSCOCO的10万人、以及MPII的4万人量级。该数据集将挑战现有主流算法的鲁棒性。
基于此数据集的研究成果可以被直接应用于动作分类和识别,动作捕捉,图像和视频内容理解,人机交互,自动驾驶(行人动作和意图识别),安防(异常行为检测),无人零售(消费者行为理解)等领域。
2. 图像中文描述数据集:此数据集是目前规模最大、场景和语言使用最丰富的图片中文描述数据集,共有30万张图片,150万句中文描述,使用了超过100种复杂生活场景的含有人物的图片,而且此数据集的语言描述标注更符合中文语言使用习惯。相对于MSCOCO和Flickr8k-CN,在完整描述图片主体事件的基础之上,该数据集创新性的引入了形容词和中文成语,用以修饰图片中的主要人物及背景事件,大大提升了描述语句的丰富度。本数据集的标注量远大于Flickr8k-CN(8000张图),巨大的数据量和复杂的图片场景将直接挑战现有算法的可用性。
基于此数据集的研究成果可以被直接应用于图像与视频语义理解、图像与视频自动标注、图像与视频内容检索、人工智能辅助教育、机器人视觉、盲人辅助等人工智能相关领域。
3. 英中翻译数据集:此数据集的训练数据量达到1000万句对,每一条数据由一句英文和对照的中文构成,是最大规模的口语领域英中比赛数据集。训练数据全部经过译员检查和矫正,句正确率在97%以上,英中双语句对对照工整、质量高、噪音低。
基于此数据集的研究成果可以被直接应用于机器翻译,尤其是口语机器翻译、同声传译应用。

精选福利
关注AI科技大本营,进入公众号,回复对应关键词查看分类专题;回复“入群”,加入AI科技大本营学习群。
回复“深度学习”,一文囊括30篇深度学习精华文章。
回复“机器学习”,一文推荐30篇机器学习优质文章。
回复“访谈”,查看吴喜之、周志华、杨强、蚂蚁金服漆远、今日头条李磊的重磅独家访谈实录。
回复“资源”,一文梳理机器学习,深度学习,神经网络等各方面的资源。
回复“视频”,5分钟的视频带你轻松入门人工智能。
回复“程序员”,带你了解别人家的程序员如何学好AI。
回复“数据”,帮你弄清楚人工智能与数据科学之前的关系。
回复“课程”,跟我一起免费学习:谷歌大脑深度学习&Fast.ai最实战深度学习&David Silver深度强化学习。






