企业到底需要怎样的湖仓一体架构?| Q推荐

在愈发复杂的大数据场景下,数据仓库与数据湖各自的弊端开始显现,湖仓一体架构走向舞台中央。此前,InfoQ 也曾在 《湖仓一体会成为企业的必选项吗?》 一文中提到,对于高速增长的企业来说,选择湖仓一体架构来替代传统的独立仓和独立湖,将成为不可逆转的趋势。
虽然业界对于湖仓一体的价值是高度认同的,但作为一种新兴的架构,大多数公司对于湖仓一体仍处在初期的探索阶段,有些企业甚至对于要选择怎样的湖仓一体架构仍旧是云里雾里。本文,我们希望从技术选型的角度出发,让你重新理解湖仓一体的本质与要求,扫除技术选型过程中的迷雾。
若想真正理解湖仓一体的真正内涵,这需要我们回溯到企业的数据使用场景:我们发现,它早已悄无声息地完成了从离线场景到实时数据分析场景的转变。
在以往,企业主要是利用离线场景对历史数据进行分析,而随着业务发展到一定规模以后,离线数据的缺点就愈发凸显,公司的业务方、决策方对实时化数据提出了更高的诉求,希望从业务端获取到数据以后,便能够立即被清洗处理,从而满足基于数据的事前预测、事中判断和事后分析。在 《ANCHOR 区分湖仓一体和湖仓分体的锚》 研究报告中,还分别从四个层面指出了实时数据分析的需求场景:
运营层面:实时业务变化、实时营销效果、当日业务趋势分析;
用户层面:搜索推荐排序、实时行为等特征变量的生产,为用户推荐更精准的内容;
风控层面:实时风险识别、反欺诈、异常交易等;
生产层面:实时监控系统的稳定性和健康状况等。
不难发现,无论是互联网企业还是传统企业,数据的时效性都被摆在了重要位置,甚至有些企业已经从 PV、UV 指标等单点实时化进阶到了全面实时化的阶段。也正于因此,数据的时效性也就成为了企业判断自身架构设计是否满足真正湖仓一体的关键因素。
总体来看,企业到底需要怎样的湖仓一体架构?除了要满足实时化数据需求这一关键要素以外,数据一致性、超高并发、云原生、支持多类型数据以及一份数据也被列入了湖仓一体的 ANCHOR 六大特征。
如前文所言,随着市场竞争和用户需求的不断变幻,企业对于数据的时效性需求不断攀升,但实时数据的分析场景出现以后,也给数据技术的实现带来了很大的挑战。目前,无论是擅长事务型工作的数据仓库,还是数据类型更为丰富的数据湖,亦或是 Hadoop+MPP 模式下的湖仓分体,其都是基于 T+1 设计的,即便引入了流处理引擎实现了部分固定模式的实时分析,仍无法达到 T+0 全实时的水平。
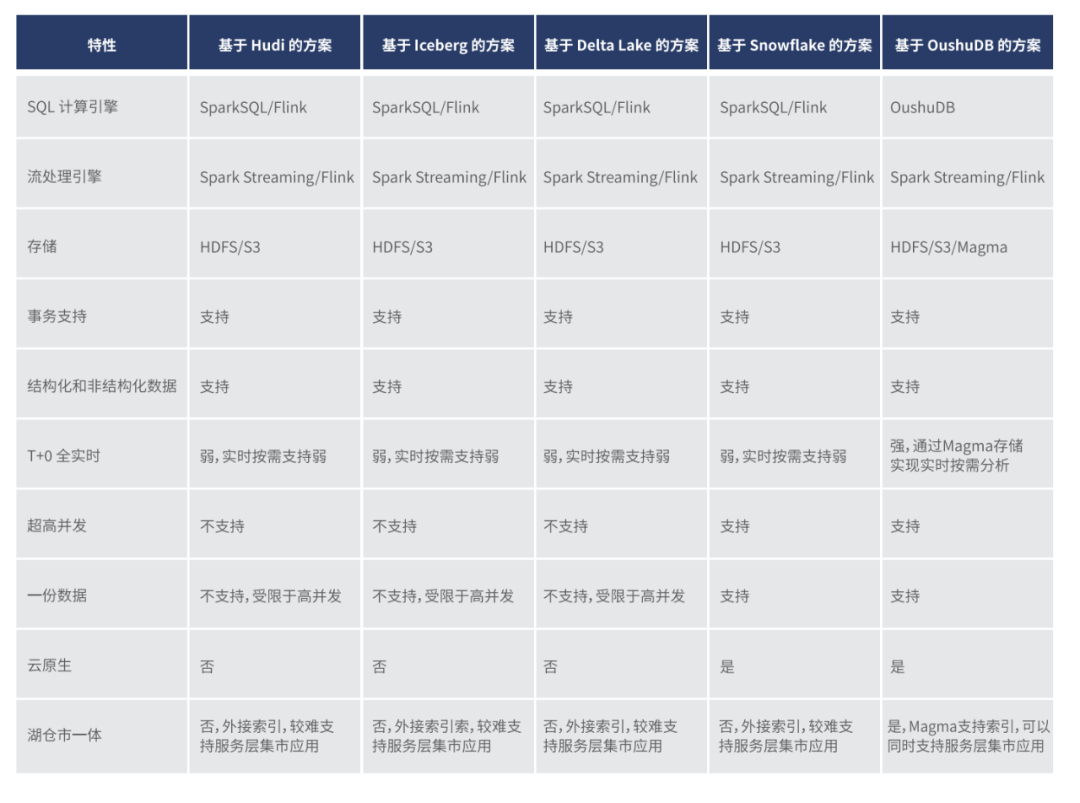
为了让数据实现全面实时化,行业内也衍生出了不同的湖仓一体方案,可以将其大致分为两类:一类是基于 Hadoop 的改造方案,拿 Hudi、Iceberg 两款开源数据湖项目为例,结构化、半结构化及非结构化的数据通过 SparkSQL/Flink 引擎不断流转与计算,再基于 HDFS/S3 实现事务存储,但此类方案在性能支持上与 Hadoop 的区别并不大;
另一类则是从新的基础架构发展出的云原生数据仓库,其中比较典型的代表有 Snowflake、OushuDB 方案,二者均突破了传统 MPP 和 Hadoop 的局限性,实现了存储和计算的完全分离,并且通过虚拟计算集群技术,其单个集群可以达到数万节点,同时在复杂查询性能和 SQL 兼容性上也非常完善。在国外,Snowflake 可以算作落地湖仓一体的成功先例之一,而偶数科技围绕 OushuDB 提出的湖仓一体解决方案,也成为国内该赛道中的一颗耀眼的新星。
若想了解 OushuDB 性能的强大之处,我们大抵可以从以下这组公开数据中窥知一二:由于 OushuDB 使用了 SIMD(单指令多数据流)的执行器优化策略,其全面性能超过 Spark 性能相差 8 倍以上,最大相差 55 倍。通过横向对比几类湖仓一体解决方案,我们发现,在 T+0
全实时方面,基于 OushuDB 的方案也展现出了较大的优势。
那么问题来了,偶数科技是如何实现具备实时能力的湖仓一体架构?我们可以先从 Lambda 以及 Kappa 这两种典型架构的优劣说起。
为了能够让流处理与批处理配合使用,Lambda 架构应运而生,基于这套架构,任务可以根据是否需要被实时处理进行分离,然而,这套架构背后也隐藏了很多问题。首先,离线和实时两套方案会产生不同的计算结果,当发生数据产生不一致问题时,对比排查需要花费较长时间。此外,由于 Lambda 架构由多个引擎和系统组成,其学习成本、运维成本也相对较高。
可见,Lambda 架构在开发割裂感、资源重复、集群维护成本以及数据一致性等问题上存在较大的问题。为了解决 Lambda 架构需要维护两套代码的难题,Kappa 架构又出现了,即在 Lambda 架构的基础上移除了批处理层,利用流计算的分布式特征,加大流数据的时间窗口,统一批处理和流处理,最终处理后的数据可以直接给业务层使用。相比之下,虽然 Kappa 架构的优点显而易见,但其也存在以下两方面的缺点:
依赖 Kafka 等消息队列来保存所有历史,而 Kafka 难以实现数据的更新和纠错,发生故障或者升级时需要重做所有历史,周期较长;
Kappa 依然是针对不可变更数据,无法实时汇集多个可变数据源形成的数据集快照,不适合即席查询。
面对 Lambda 架构与 Kappa 架构的局限性,业内也亟需一种新型技术架构来满足企业的实时分析需求。为此,偶数科技在 2021 年初提出了同时满足实时流处理、实时按需分析以及离线分析的 Omega 架构,其是根据流数据处理系统和实时数仓构成的。
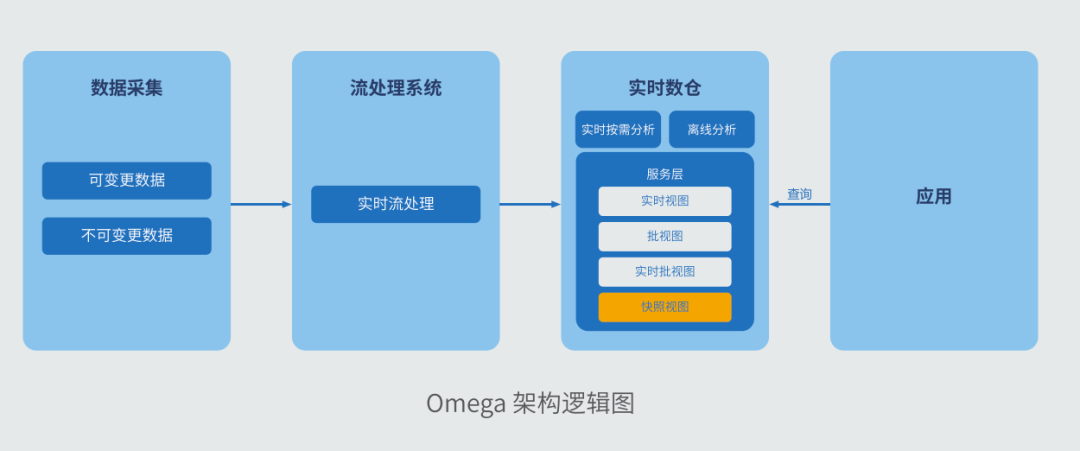
需要强调的一点是,在 Omega 架构中需要变更流处理版本时,不再需要流处理引擎访问 Kafka,直接访问 OushuDB 即可获得所有历史数据,这样一来,便规避了 Kafka 难以实现数据更新和纠错的问题,大大提升了数据处理的效率。在 Omega 全实时架构的加持下,偶数科技实现了具备实时能力的湖仓一体,即实时湖仓。
深入剖析了数据使用场景,我们发现大数据平台不仅需要适配复杂的数据生产环境,还需要同时满足业务对于时效性的追求。可见,离线分析场景的数据诉求已经与企业渐行渐远,抓住实时业务场景的数据需求才能让企业在数字化转型的大潮中站稳脚跟。
而在全面实时化的进程中,相信具备实时能力的湖仓一体方案将发挥其独特的优势,从而切实助力企业提升数据的价值。