深度强化学习领域(2)之大牛云集

来源:公众号原创
作者:DeepRL
一个大师级的人物可以推动一个领域的发展,深度强化学习的发展得益于强化学习在深度学习和神经网络的推动作用下的快速进步,在整个深度强化学习的发展过程中,有那么一群顶尖学者起到了推动作用,下文将对每一位前沿学者进行介绍。


Richard S. Sutton
--Google科学家
Richard S. Sutton,是加拿大计算机科学家。目前他是阿尔伯塔大学计算机科学教授 和iCORE主席。萨顿被认为是现代计算强化学习的创始人之一,对该领域有几项重要贡献,包括时间差异学习和策略梯度方法,这两种方法为后来的强化学习发展起到了推动作用。
Sutton于1978年获得斯坦福大学心理学学士学位,硕士学位。分别于1980年和1984年在马萨诸塞大学阿默斯特分校获得计算机科学博士学位,并在Andrew Barto的监督下。他的博士论文“ 强化学习中的时间信用分配” 引入了行为者- 批评体系结构和“时间信用分配”两种方法。

老爷子目前为强化学习的发展贡献了圣经级别的书籍:
《Reinforcement Learning: An Introduction 》

《书籍pdf链接》
http://incompleteideas.net/book/RLbook2018.pdf
《书籍代码链接》
http://incompleteideas.net/book/first/code/code.html
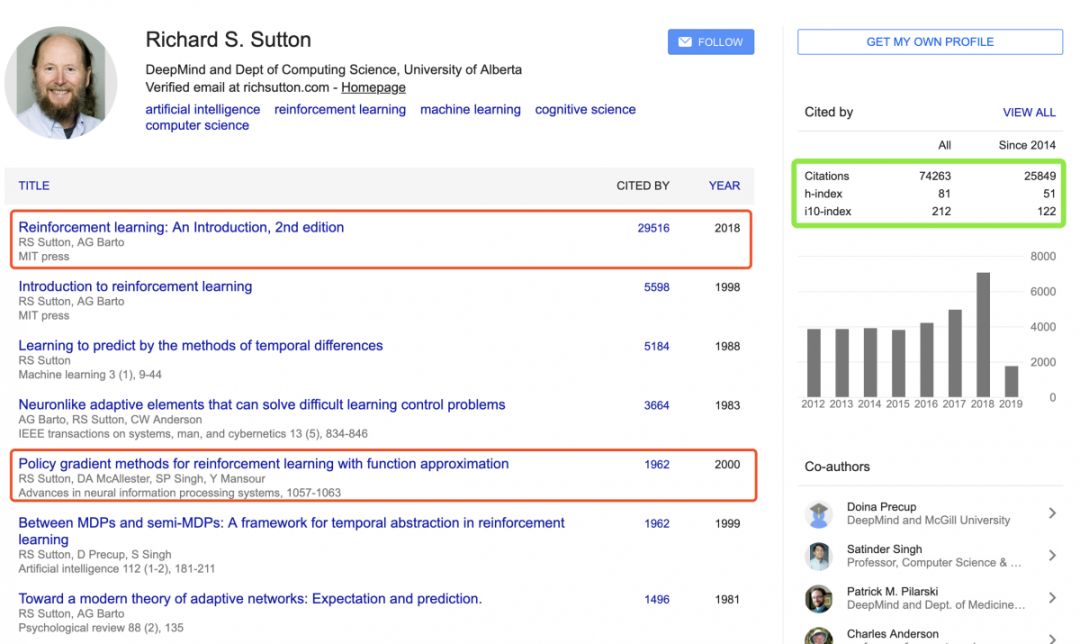
《GoogleScholar地址》
https://scholar.google.ca/citations?user=6m4wv6gAAAAJ&hl=en

David Sliver
--Google DeepMind科学家
David Silver, 曾领导DeepMind的强化学习研究小组,并担任AlphaGo的首席研究员和AlphaStar的联合负责人。他于1997年毕业于剑桥大学,获得Addison-Wesley奖,并在那里与Demis Hassabis【DeepMind创始人】结识。随后,Silver共同创办了视频游戏公司Elixir Studios,在那里他担任CTO和首席程序员,获得了多项技术和创新奖。2004年,他在阿尔伯塔大学回到学术界攻读博士学位,主要研究强化学习,他介绍了第一个主级9x9 Go程序中使用的算法。他的MoGo程序版本(与Sylvain Gelly共同撰写)是截至2009年最强大的Go计划之一。Silver于2011年被授予皇家学会大学研究奖学金,随后成为伦敦大学学院的讲师,现任教授。他的强化学习讲座可在YouTube上找到。Silver 从一开始就为DeepMind提供咨询,并于2013年全职加入。他最近的工作重点是将强化学习与深度学习相结合,包括一个学习直接从像素中学习Atari游戏的程序。Silver领导了AlphaGo项目,最终推出了第一个在Go全尺寸游戏中击败顶级职业玩家的计划。AlphaGo随后获得了荣誉9段专业认证; 并因创新而获得戛纳狮子奖。然后他领导了AlphaZero的开发,在学习以同样的方式下棋和棋子之前,使用相同的AI来学习玩游戏(从头开始学习而不是从人类游戏中学习),达到比任何其他计算机程序更高的水平。
目前他为强化学习发展贡献了经典课程《UCL强化学习课程》,这门课程主要根据sutton老爷子的书为基础进行讲解,是目前强化学习原理与基础方面最经典的课程之一

《链接》
http://www0.cs.ucl.ac.uk/staff/d.silver/web/Teaching.html
他在围棋领域最为经典代表是AlphaGo、AlphaZero等

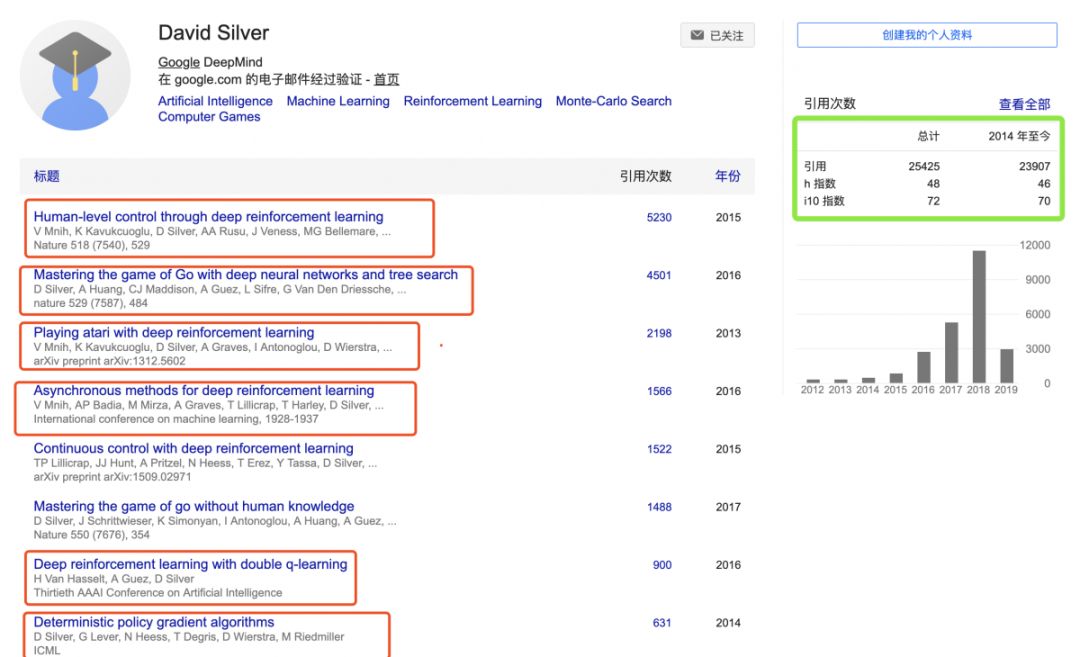
《GoogleScholar地址》
https://scholar.google.com.sg/citations?user=-8DNE4UAAAAJ&hl=zh-CN&oi=sra

Pieter Abbeel
--OpenAI, UC Berceley科学家
Pieter Abbeel 教授是加州大学伯克利分校机器人与强化学习范畴的教授。他于比利时 KU Leuven 获电子工程学士、硕士学位,之后在斯坦福大学师从吴恩达,并于 2008 年取得博士学位。Pieter Abbeel 教授自 2008 年起在加州大学伯克利分校担任 教职。在攻读博士期间,Pieter Abbeel 教授发表了多篇重要的学术论文,并与导师《吴恩达》提出了学徒学习(Apprenticeship learning)这一强化学习的全新概念,2011 年,Pieter Abbeel 教授通过深度神经网络应用策略搜寻所,实现了机器 人叠毛巾的演示,他也因而被MITTechnologyReview 评比为当年的“TR35”获奖者。Pieter Abbeel 教授同时担任创业公司 Embodied Intelligence 的董事长兼首 席科学家。其研究领域为:机器学习和机器人技术领域,他的研究集中让机器人从人身上 学习(学徒学习),通过自己的尝试和错误学习(强化学习),以及通过学习-学习 (元学习)加速技能的获取。"
他为强化学习的发展贡献了课程:
CS 188 | Fall 2018
《pdf链接》
https://inst.eecs.berkeley.edu/~cs188/fa18/index.html
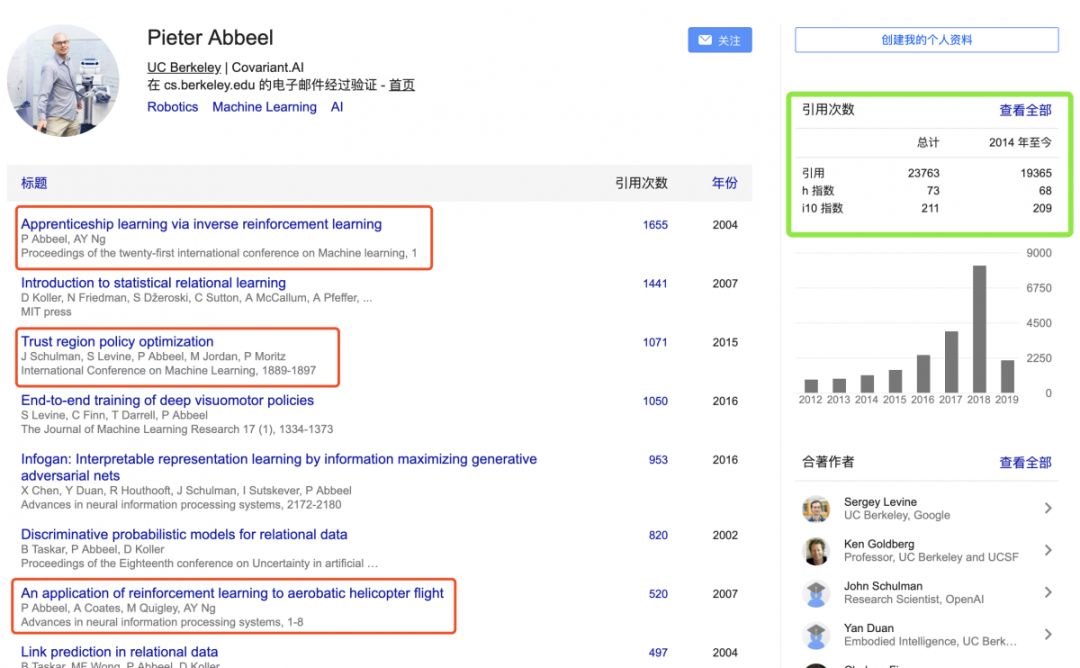
《GoogleScholar》
https://scholar.google.com.sg/citations?hl=zh-CN&user=vtwH6GkAAAAJ

Oriol Vinyals
--Google DeepMind科学家
Oriol Vinyals,目前正在研究跨学科主题,包括Nelson Morgan监督下的语音识别和信号处理,Ruzena Bajcsy的TeleImmersive技术,以及Trevor Darrell的计算机视觉和机器学习。他是2011年微软研究博士奖学金的获得者。其从西班牙的加泰隆尼亚理工大学(University of Catalonia)完成电信工程及数学双学位之后,前往美国进修,在卡内基梅隆大学机器人学院完成了机器学习和电脑视觉的学位论文(undergrad thesis),接着又到加州大学圣地牙哥分校,取得计算机科学及工程(Computer Science and Engineering)硕士学位,2009年则进入加州大学伯克利分校(UC Berkeley)攻读电机及电脑科学(Electrical Engineering & Computer Science)博士,他也参与了伯克利的Overmind 计划。2015 年, Google 研究团队发表了一篇论文,他们透过电影对白来训练的聊天机器人(chatbot)居然能跟人类谈论抽象的人生议题。一开始研究人员问了一些简单的问题,例如我的 VPN 连不上等IT问题,机器就像是一个专业的 IT 人员,工作得恰如其分,但接着问它“生命的意义是什么”、“活着的目的是什么”等形而上的问题,机器分别说:“追求最大的美好”、“为了永生”……等。对话让人从感觉从有趣变成了有点恐惧。而这个 chatbot的开发者就是 Oriol Vinyals 和他的同事 Quoc V.Le 。

他为深度强化学习的贡献主要是星际争霸游戏的智能体AlphaStar
【GoogleScholar】
https://scholar.google.com.sg/citations?hl=zh-CN&user=NkzyCvUAAAAJ

Volodymyr Mnih
--Google DeepMind科学家
Volodymyr Mnih,谷歌(Google DeepMind)的一位加拿大研究科学家,拥有深入学习方面的专业知识,领导团队致力于深入Q-Networks(DQN),掌握Atari游戏[2]。DQN通过pong、space in侵略者、breakout和seaquest等游戏进行测试,只接收像素和游戏分数作为输入,以超越所有先前算法的性能,并在一组49个游戏中达到与专业的人类游戏测试人员相当的水平,使用相同的算法、网络架构和超级参数。Volodymyr mnih在 Geoffrey E. Hinton《2019年图灵奖获得者,反向传播、胶囊网络的提出者》的教导下在多伦多大学获得了机器学习博士学位,并在阿尔伯塔大学获得了计算机科学硕士学位,他的导师是csaba szepesv_ri。
《GoogleScholar》
https://scholar.google.com/citations?user=rLdfJ1gAAAAJ&hl=zh-CN

Koray Kavukcuoglu
--Google DeepMind科学家
Koray Kavukcuoglu,谷歌 DeepMind的计算机科学家和研究员,参与WaveNet语音合成系统,以及AlphaGo项目。他从Middle East Technical University大学获得航天工程学位,在纽约大学分别于2005年和2010年获得硕士和博士学位。他的研究兴趣集中在机器学习,包括神经网络和深度学习。与Ronan Collobert和ClémentFarabet,他是机器学习库Torch5 版本的开发者,也为后续版本做出了贡献。
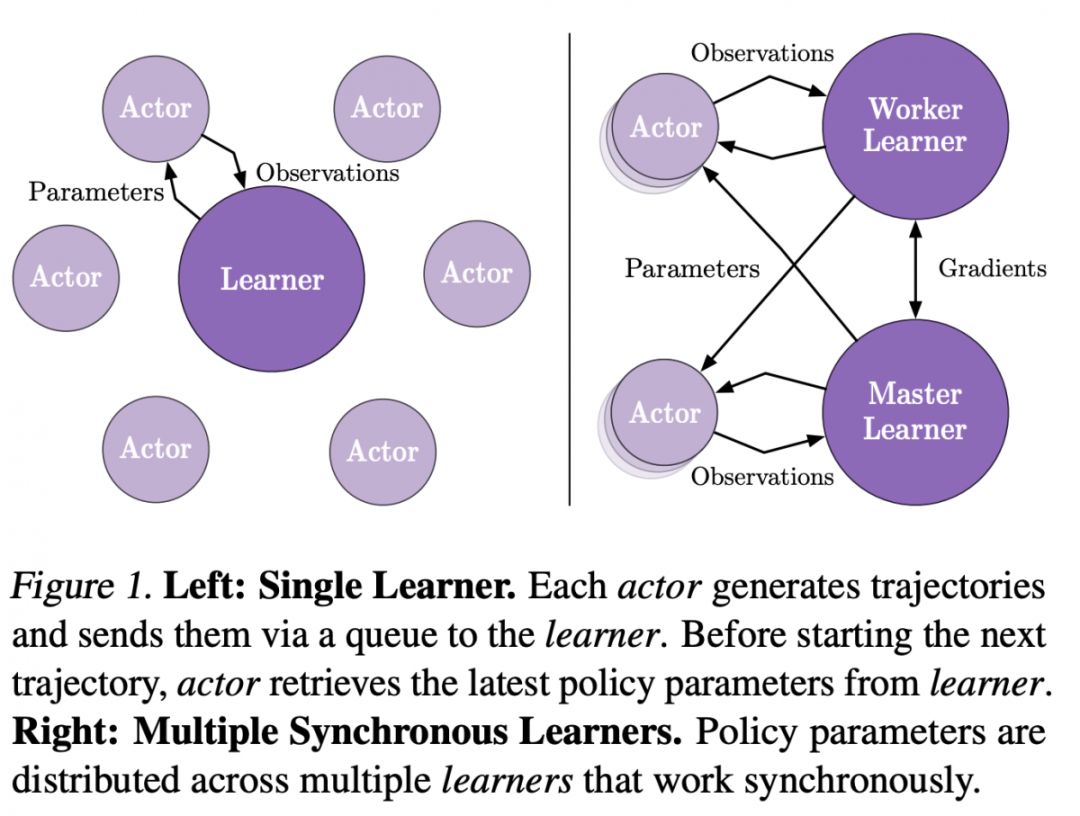
他为强化学习的主要贡献除了论文之外,和前面几位科学家共同提出了强化学习框架《IMPALA: Scalable Distributed Deep-RL with Importance Weighted Actor-Learner Architectures》
《GoogleScholar》
https://scholar.google.com/citations?hl=zh-CN&user=sGFyDIUAAAAJ
《Github》
https://github.com/koraykv

John Schulman
--OpenAI 科学家
John Schulman,是Openai的一名研究科学家,其致力于强化学习(RL),特别是与转移学习和元学习有关的。他在加州大学伯克利分校获得了计算机科学博士学位,并研究机器人,使机器人能够打结和缝合,并利用轨迹优化来计划运动。
他为强化学习所做的贡献在于提出了置信域策略梯度优化算法(Trust Region Policy Optimization),并发表于顶会上,这篇论文是与大神Pieter Abbeel共同完成,他在其个人博士论文第三章作为单独章节进行了解释描述,该算法成功的解决了策略梯度更新过程中的更新步长问题。
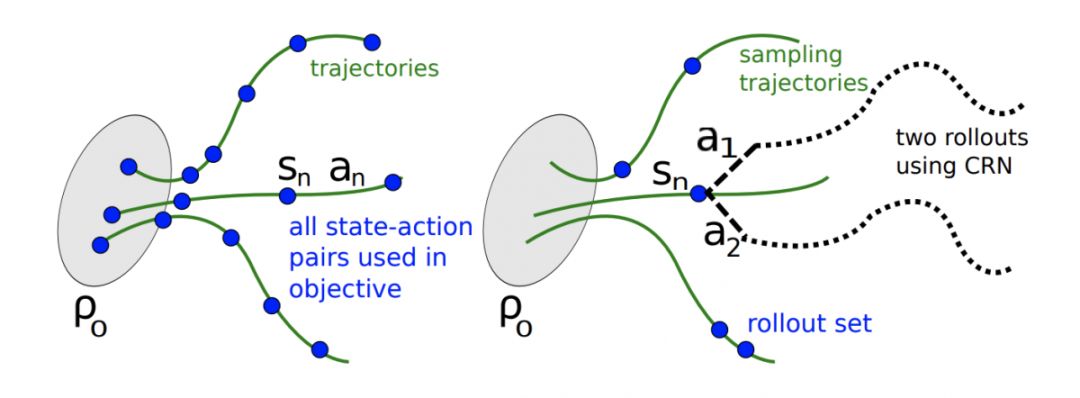
《GoogleScholar》
https://scholar.google.com/citations?user=itSa94cAAAAJ&hl=zh-CN
《Github》
https://github.com/joschu

Sergey Levine
--UC Berkeley、Google科学家
Sergey Levine,是加州大学伯克利分校电气工程和计算机科学系的助理教授。其关注控制和机器学习之间的交叉点,目的是开发算法和技术,使机器能够自主地获得执行复杂任务的技能。特别是对如何利用学习来获得复杂的行为技能感兴趣,以便赋予机器更大的自主性和智能性方面的研究。
他于2009年获得斯坦福大学计算机科学学士和硕士学位,2014年获得斯坦福大学计算机科学博士学位。他于2016年秋季加入加州大学伯克利分校电气工程和计算机科学系。他的工作重点是决策和控制的机器学习,重点是深入学习和强化学习算法。他的作品的应用包括自动机器人和车辆,以及计算机视觉和图形。他的研究包括开发感知和控制相结合的深层神经网络策略的端到端训练算法、逆强化学习的可扩展算法、深层强化学习算法等。他的作品曾在许多流行的媒体上发表,包括《纽约时报》、《英国广播公司》、《麻省理工学院技术评论》和《彭博商业》。
他为强化学习所做贡献主要集中在机器人控制领域,并在伯克利大学开设了经典的强化学习课程《CS294》
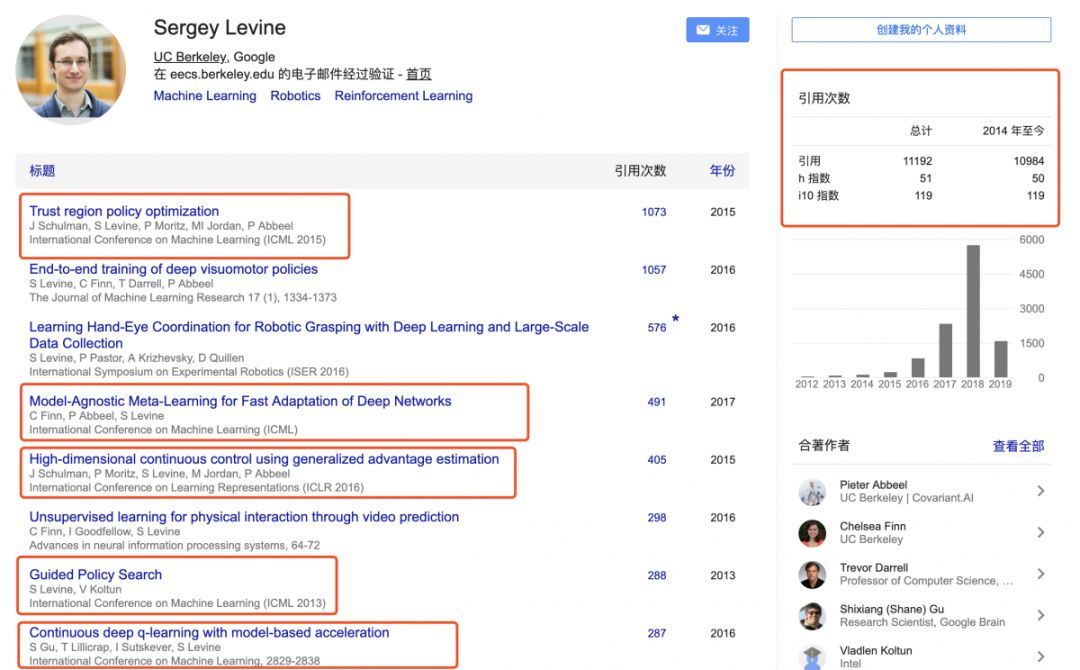
《GoogleScholar》
https://scholar.google.com/citations?hl=zh-CN&user=8R35rCwAAAAJ
《更多论文》
https://dblp.uni-trier.de/pers/hd/l/Levine:Sergey

Hado van Hasselt
--OpenAI 科学家
Hado van Hasselt,是谷歌DeepMind的研究科学家。其研究兴趣包括人工智能、机器学习、深度学习,尤其是强化学习。此前,曾在阿尔伯塔大学与RichSutton合作。
他为强化学习所做的贡献是开设了UCL(2016)强化学习课程

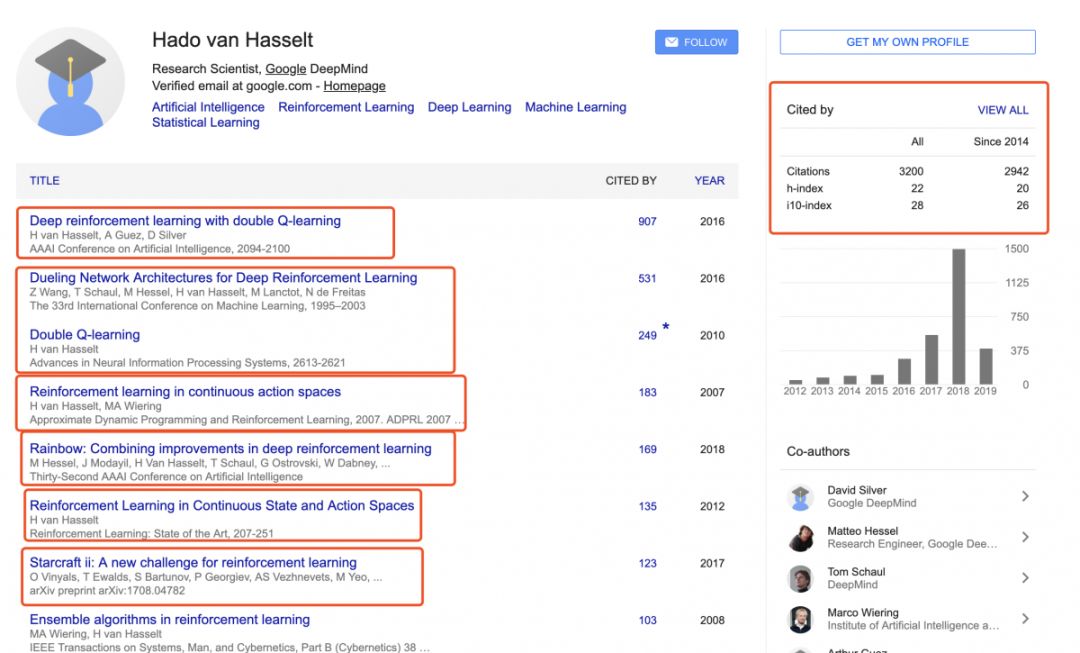
《GoogleScholar》
https://scholar.google.ch/citations?user=W80oBMkAAAAJ&hl=en

俞扬
--南京大学
俞扬博士,南京大学人工智能学院教授 ,分别于 2004 年和 2011 年获得南京大学计算机科学与技术系学士学位和博士学位 。
2011 年 8 月加入南京大学计算机科学与技术系、机器学习与数据挖掘研究所(LAMDA)从事教学与科研工作。曾获 2013 年全国优秀博士学位论文奖、2011 年中国计算机学会优秀博士学位论文奖。发表论文 40 余篇,包括多篇 Artificial Intelligence、IJCAI、AAAI、NIPS、KDD 等国际一流期刊和会议上,研究成果获得 IDEAL'16、GECCO'11、PAKDD'08 最佳论文奖,以及 PAKDD』06 数据挖掘竞赛冠军等。《Frontiers of Computer Science》青年副编辑,任人工智能领域国际顶级会议 IJCAI』15/17 高级程序委员、IJCAI'16/17 Publicity Chair、ICDM'16 Publicity Chair、ACML'16 Workshop Chair。指导的学生获天猫「双十一」推荐大赛百万大奖、Google 奖学金等
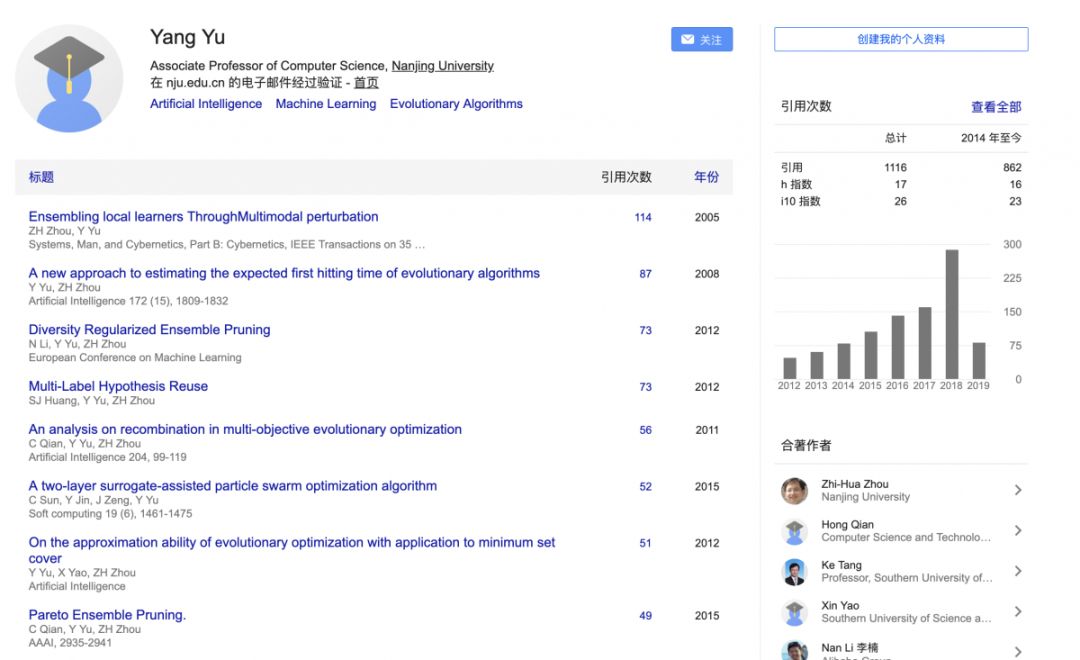
《GoogleScholar》
https://scholar.google.com/citations?user=PG2lDSwAAAAJ&hl=zh-CN
注:部分图片引用版权仅学习使用,请勿商业用途。
以上是目前在强化学习领域具有代表性的学者,其中国内比较少,部分国外还没有收集完整,受篇幅限制仅介绍了10位,后续持续更新最新最前沿的大牛。

深度强化学习算法
算法、框架、资料、前沿信息等
长按二维码关注我们吧




