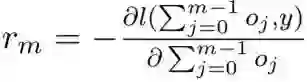作者:Ji Feng、Yi-Xuan Xu、Yuan Jiang、Zhi-Hua Zhou
机器之心编译
参与:Panda
梯度提升机(GBM)的重要性无需多言,但传统的 GBM 仍存在一些固有缺点。近日,南京大学周志华, 创新工场冯霁等人提出了一种新型的软梯度提升机(sGBM),并基于此构建了新型的软梯度提升决策树(sGBDT),作为XGBoost的替代性模型。相比于传统的「硬」GBM,sGBM 在准确度、训练时间和增量学习,多维度回归等多方面都有更优的表现。
![]()
论文链接:https://arxiv.org/pdf/2006.04059.pdf
梯度提升机(GBM)已被证明是一种成功的函数近似器并已在多种不同的领域得到了广泛应用。GBM 的基本思想很简单,即训练一系列基学习器(base learner)并且这些学习器的目标是按顺序最小化某个预定义的可微分损失函数。
在构建这些学习系统时,通常的做法是用不可微分的决策树充当基学习器。梯度提升决策树(GBDT)及 XGBoost、LightGBM 和 CatBoost 等变体,是最常见也是最广泛使用的具体模型实现。
现阶段,对于表格式数据而言,GBDT 模型仍旧是最佳选择,其应用领域也很广泛,从协同过滤到信息检索再到粒子发现均有其身影。但是,此类模型较难用于在线学习,因为流数据的环境是会变化的,而基模型在训练完成后难以随环境而变化。
另一方面,同 GBM 不同,可微分编程不仅需要损失函数是可微分的,学习模块也需要可微分。具体来说,通过将多个可微分学习模块构建为任意有向无环图(DAG)形式,就可通过随机梯度下降或其变体优化方法来联合优化其整个结构。这样的系统有一些出色的特性,包括强大的表征学习能力、可扩展性以及可在线使用。
2018 年,周志华和冯霁等人发表的一篇 NeurIPS 论文提出了一种用于表征学习的多层梯度提升决策树(mGBDT),这项研究开创性地融合了上述两个研究方向的优势。具体来说,mGBDT 具有和可微分编程模型一样的分层表征能力,同时又具备非可微分模型的一些优良特性,因此能以更好的方式处理表格式数据。这项开创性研究带来了新的挑战和机遇,但也存在很大的进一步探索空间。
今天要介绍的这项研究是周志华,冯霁等人在相关问题上的又一种开创性思考。这一次,
他们研究的不是如何构建一个能像可微分程序一样工作的 GBM,而是探索了如何构建能像不可微分的 GBM 一样工作的可微分系统
。软梯度提升机(Soft Gradient Boosting Machine)就是他们的探索成果。
这种「软」版本的 GBM 是将多个可微分的基学习器连接在一起,受 GBM 启发,同时引入了局部损失与全局损失,使其整体结构可以得到联合优化。
在此基础上,他们还提出使用软决策树(soft decision tree)来充当基学习器,在硬决策树不是最合适的选择时,软决策树对应的软梯度提升决策树就可被视为 XGBoost 的替代选择。
据介绍,这种设计具有如下优势:
首先,相比于传统的(硬)梯度提升机,
软梯度提升机的训练速度更快
。软 GBM 不是一次一个地训练基学习器,而是能同时训练所有基学习器。该团队也对该设计进行了实验实测,结果表明在使用同样的基学习器时,软 GBM 在多个基准数据集上能带来超过 10 倍的速度提升,同时还有更胜一筹的准确度。此外,在拟合传统 GBM 模型时,一个基学习器必须在「看」完所有训练数据之后才能转向下一个学习器;这样的系统不适合增量学习或在线学习。而软 GBM 天生就具备这样的能力。
其次,
XGBoost 等当前的 GBDT 实现使用了 CART 作为基学习器,因此不能很直接地用于多维回归任务。但 sGBDT 可使用软决策树作为基学习器来自然地处理这些任务
。这样的特性也使得 sGBDT 更适用于知识蒸馏或二次学习,因为蒸馏过程会将分类的 one hot 标签转换为一个在训练集上的稠密向量。
最后,
由于局部和全局的损失注入,软 GBM 会让基学习器之间的交互呈指数增长,使得该系统能比对多个基学习器使用软平均 (soft averaging, 可微加权平均集成) 的方法更有效和更高效。
在详细介绍新提出的方法之前,先来看看梯度提升机(GBM)的工作方式。具体来说,对于给定的数据集
![]() ,GBM 的目标是获得函数 F*(x) 的一个优良近似,而评估标准是看其能否在实验中最小化损失
,GBM 的目标是获得函数 F*(x) 的一个优良近似,而评估标准是看其能否在实验中最小化损失
![]() 。
。
![]() ,
,
其中![]() 由 θ_m 参数化,而 β_m 是第 m 个基学习器的系数。
由 θ_m 参数化,而 β_m 是第 m 个基学习器的系数。
GBM 的训练过程是基于训练数据学习参数
![]() 。
GBM 首先假设
。
GBM 首先假设
![]() ,
然后就能按顺序决
定
,
然后就能按顺序决
定
![]() 和 β_m。
首先,给定 y^i 和 GBM 前一轮获得的预测结果,
和 β_m。
首先,给定 y^i 和 GBM 前一轮获得的预测结果,
![]()
![]()
其次,下一个基学习器 h_m 会与该残差进行拟合。系数 β_m 则通过最小二乘法确定或设定为常数。最后,完成对学习器 h_m 和系数 β_m 的参数更新之后,就可以将其用作条件来更新 GBM 的预测结果:
![]()
![]()
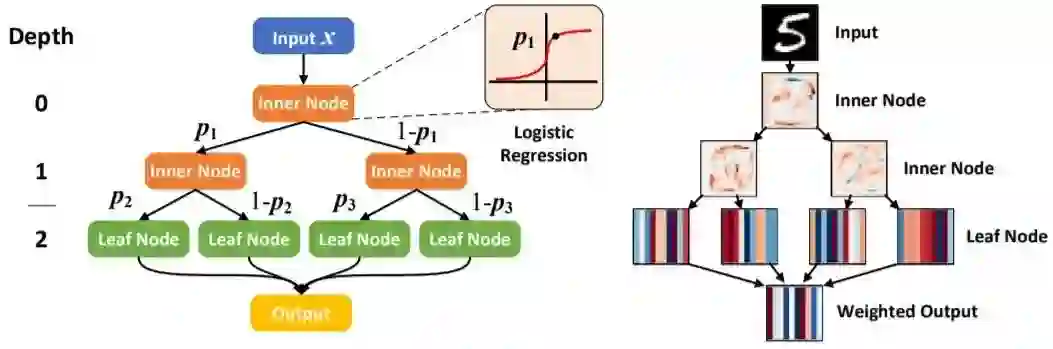
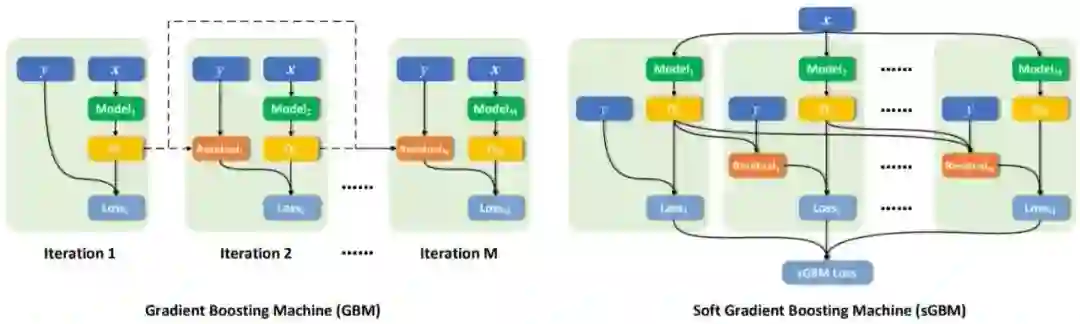
然后进入下一轮训练流程。算法 1 总结了这个训练过程,图 1 左图也给出了其示意图。
![]()
可以看出,GBM 的训练过程难以并行化,因为只有在一个基学习器拟合之后才能转向下一个基学习器。也因为这个原因,这类算法也难以在线应用。
软梯度提升机(sGBM)就是针对这些问题而提出的。该研究团队首先假设所有基学习器都是可微分的。然后,他们没有选择为相连的基学习器执行软平均,而是提出使用两种类型的损失函数——全局损失和局部损失;将这两种损失函数注入训练过程之后,可使得基学习器之间的交互成指数增长,进而实现梯度提升效果(而非所有基学习器的直接加权平均)。
具体来说,令 M 为可微分基学习器的数量,其中每个基学习器的参数为 θ_m。这里 M 是预先确定的,指定了训练之前所使用的基学习器的数量。和硬 GBM 一样,sGBM 的输出为所有基学习器的输出之和:
![]() 。
训练中整个结
构的最终损失定义为
。
训练中整个结
构的最终损失定义为
![]() 。
其中,l_m 是基学习器的损失:
。
其中,l_m 是基学习器的损失:
![]() ,而 o_m 则是当前学习器 h_m 的输出,r_m 是对应的残差
,而 o_m 则是当前学习器 h_m 的输出,r_m 是对应的残差
![]()
图 1 右图为新提出的 sGBM 的示意图。可以看到,输入数据的流动过程是一个有向无环图(DAG),因此其整个结果都可通过 SGD 或其变体进行训练,即最小化局部和全局损失目标。算法 2 阐释了这一过程。
![]()
下面来看看适合 sGBM 的基学习器。研究者在论文中探讨了基学习器是决策树的具体情况。
梯度提升决策树(GBDT)是 GBM 应用最广的实例之一,其使用了硬(而且通常较浅)的二叉决策树作为基学习器。具体来说,这个硬决策树内每个无叶的节点会形成一个轴平行的决策平面,每个输入样本都会根据对应的决策平面被引导至左侧或右侧的子节点。这样的流程是按递归方式定义的,直到输入数据抵达叶节点。最终的预测结果是输入样本所在的叶节点内的类分布。
XGboost、LightGBM 和 CatBoost 等 GBDT 的成功实现已经证明 GBDT 是一种绝佳的数据建模工具,尤其是对于表格式数据而言。
另一方面,软决策树使用了 logistic 单元作为内部非叶节点的路由门,而输入样本的最终预测结果是所有叶节点之间的类别分布的加权和,其中权重是由在内部节点上沿决策路径的 logit 积确定。这样的结构可通过随机梯度下降进行训练,图 2 给出了示意图。
![]()
当使用软决策树作为基学习器时,对应的软 GBDT 相较于硬 GBDT 有多项优势。第一,硬 GBDT 并非处理流数据的最佳选择;而 sGBDT 是参数化的,因此整个系统可以根据环境更快地进行调整。第二,在面对多输出回归任务时,硬 GBDT 必须为每个树设置一个维度,这会导致训练效率低下;相较而言,由于 sGBDT 会同时训练所有树,因此速度会快得多。
sGBM 的有效性也在实验之中得到了验证。具体来说,研究者基于同样的基学习器比较了传统硬 GBM 和新提出的软 GBM 在准确度、训练时间、多输出回归、增量学习任务和知识蒸馏能力上的表现。
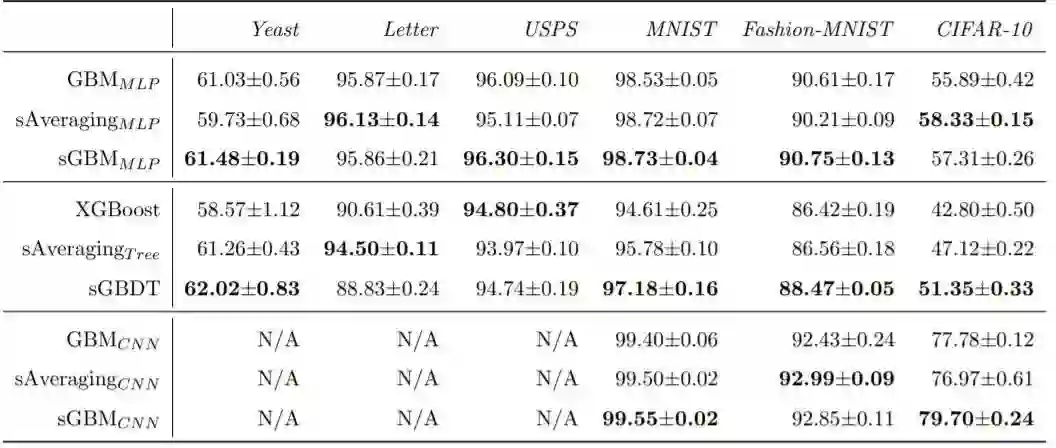
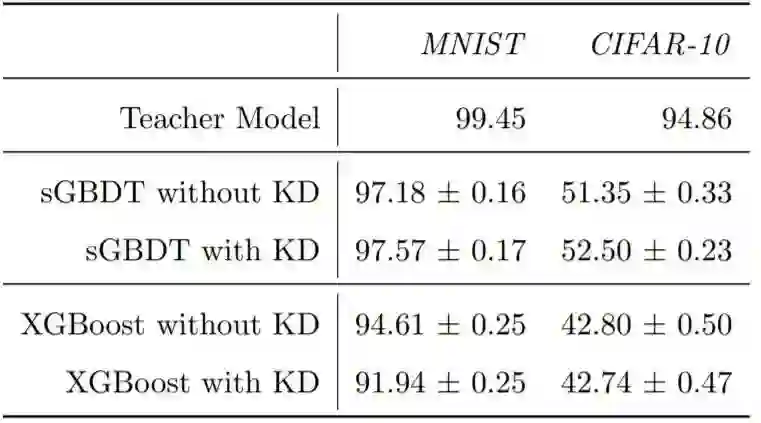
准确度方面的表现比较如表 2 所示。可以看到,sGBM_CNN 在图像分类任务上的表现优于 GBM_CNN,而 sGBM_MLP 在除 Letter 数据集之外的几乎所有数据集上都有优于 GBM_MLP 的表现。在使用树方法时,相较于经典的 XGBoost 模型,sGBDT 仅在 Letter 和 USPS 数据集上得到了较差的结果。
![]()
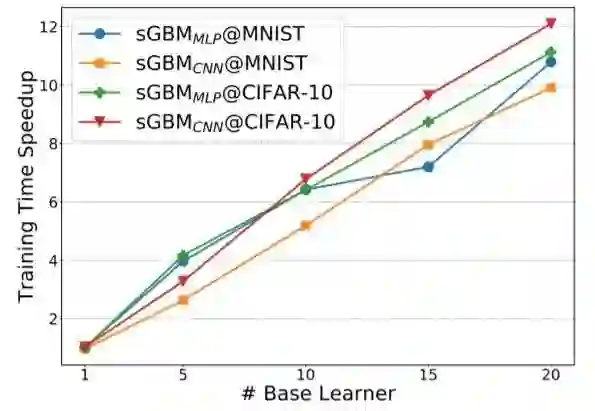
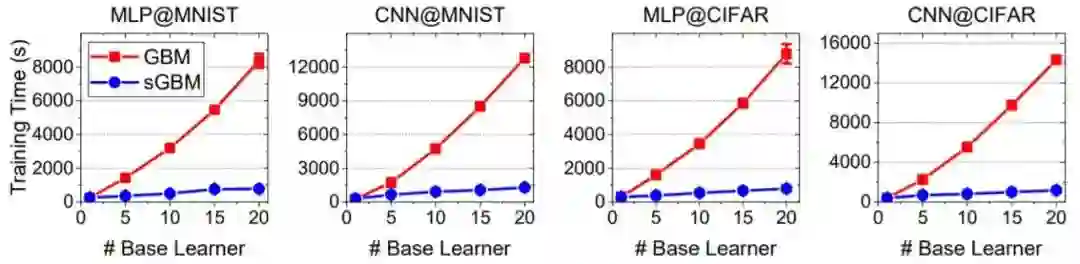
图 3 和图 4 则展示了 sGBM 相较于传统 GBM 的速度提升效果。可以看出,效果极其显著,这主要得益于 sGBM 能自然地同时训练所有基学习器。
![]()
图 3:sGBM 对训练的加速效果。很显然,基学习器越多,加速效果越显著。
![]()
图 4:使用 MLP 和 CNN 作为基学习器时的训练时间(秒)。
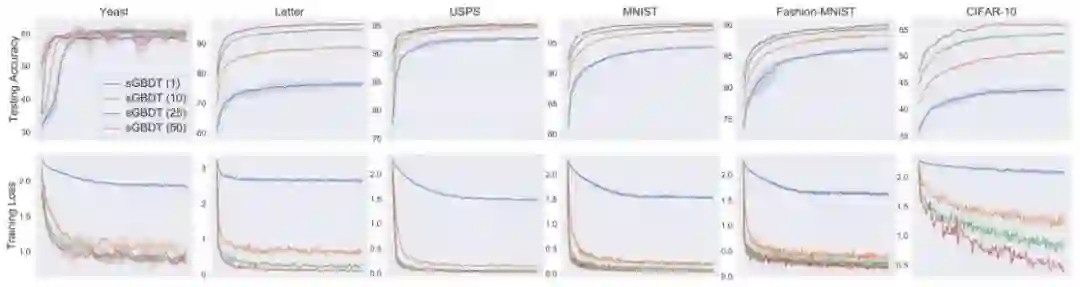
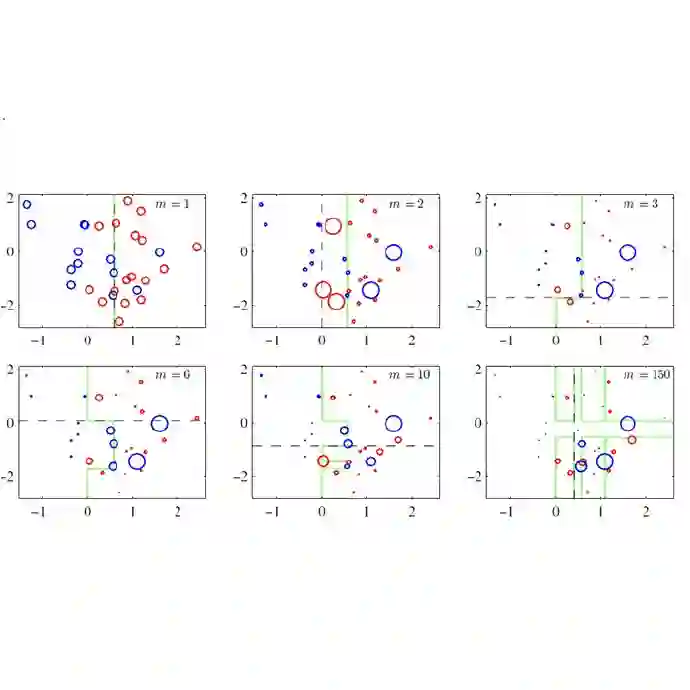
研究者也探索了添加更多基学习器能否有助于提升准确度表现。结果见图 5,可以看出,答案是肯定的,可以认为主要原因是在 sGBM 的架构设计中基学习器之间有更多的交互。
![]()
图 5:具有不同数量的基决策树的 sGBDT 的学习曲线
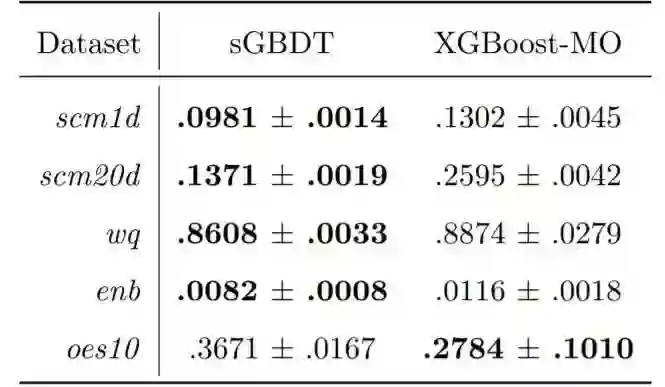
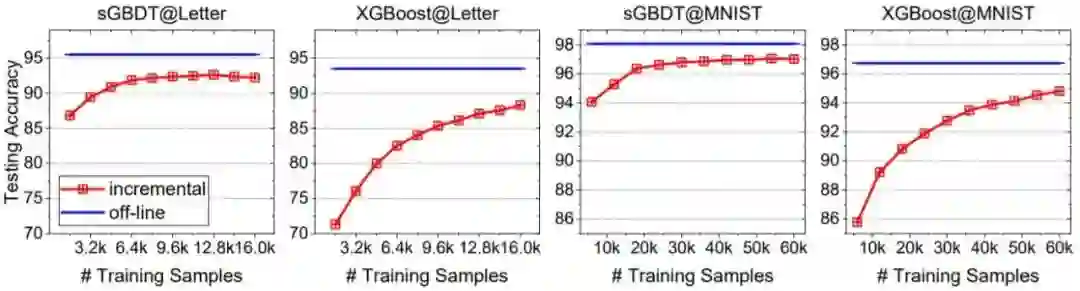
下表 3、图 6 和表 4 则分别给出了 sGBDT 在多输出回归任务、增量学习设置及知识蒸馏上的表现。总体而言,sGBDT 相较于传统 GBDT 基本都有更优的表现。
![]()
表 3:使用 10 个基学习器的均方误差(均值 ± 标准差)。可以看到 sGBDT 在大多数数据集上表现更优,另需注意 sGBDT 可轻松自然地插入其它任务,而硬 GBDT 需要一些额外的修改才行。
![]()
图 6:在增量学习设置下的表现比较。相比于 XGBoost,sGBDT 在收敛速度方面优势明显。此外,sGBDT 相比于离线设置的准确度下降也更低。
![]()
表 4:sGBDT 和 XGBoost 的知识蒸馏能力对比。sGBDT 同样表现更佳,作者认为原因是 XGBoost 及其它使用硬 CART 树作为基模型的 GBDT 实现在执行多维回归任务时,负责目标维度的树之间交互更少,使得模型难以蒸馏存在于标签分布向量之中的信息。
部署枯燥?困难?无趣?NO NO NO~~ 来AI快车道,马上传授你两个法宝!一个等外卖的时间就能轻易、快速开发检测模型的小秘密!一个让前端开发工程师拥有金饭碗的速成秘籍!还等什么?快扫描下方二维码报名吧~
![]()

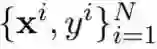 ,GBM 的目标是获得函数 F*(x) 的一个优良近似,而评估标准是看其能否在实验中最小化损失
,GBM 的目标是获得函数 F*(x) 的一个优良近似,而评估标准是看其能否在实验中最小化损失
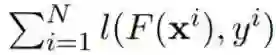 。
。
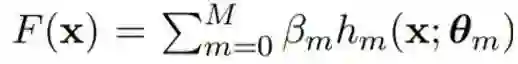
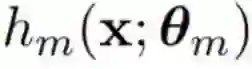
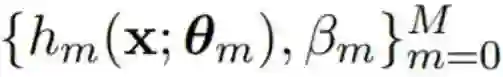 。
GBM 首先假设
。
GBM 首先假设
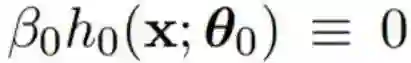 ,
然后就能按顺序决
定
,
然后就能按顺序决
定
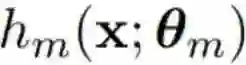 和 β_m。
首先,给定 y^i 和 GBM 前一轮获得的预测结果,
和 β_m。
首先,给定 y^i 和 GBM 前一轮获得的预测结果,
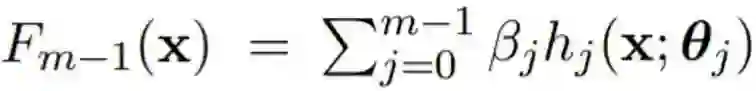
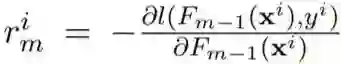
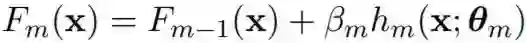

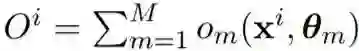 。
训练中整个结
构的最终损失定义为
。
训练中整个结
构的最终损失定义为
 。
其中,l_m 是基学习器的损失:
。
其中,l_m 是基学习器的损失:
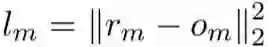 ,而 o_m 则是当前学习器 h_m 的输出,r_m 是对应的残差
,而 o_m 则是当前学习器 h_m 的输出,r_m 是对应的残差