微软在计算芯片界的“至尊魔戒”终浮现!破天荒披露与高通联手打造的全新处理器架构
“至尊魔戒统领众戒”(One ring to rule them all)是经典魔幻电影《指环王》里最出名的一句台词。蛰伏的“至尊魔戒”横空出世,便引来中土世界的一场腥风血雨。
其实电影中的故事放在当前架构频出、方案各异的计算芯片领域也不失为一个贴切的比喻。但是否最终会出现一种统领性的架构来解决所有的计算问题?不论是运行操作系统,还是进行AI运算。其实微软早有布局......
在最近 ISCA 2018 大会(2018 International Symposium on Computer Architecture)上,微软破天荒披露了秘密与高通合作开发新架构处理器的计划,而且已经长达 8 年之久,根据微软研发人员表示,其基于全新 EDGE 架构的 E2 架构已经达到最终阶段,已经可以运行包含 Linux 以及 Windows 10 等主要操作系统,同时又具备不逊于 GPU 的多工计算能力。
微软的研发人员也表示,E2 不只要支持主流操作系统,Busybox 的和 FreeRTOS 等嵌入式系统也在支持之列。除了操作系统的支持以外,开发人员也移植了一系列的开发和建构处理器应用程序的工具包,内容包含了标准的 C/C++、.NET Core 运行库,Windows 内核调试器、Visual C++ 2017 的命令行工具,以及.NET 的实时编译器 RyuJIT 等。

另外,广泛被使用的 LLVM C/C++编译程序和调试器,及相关的运行库也在移植之列。该研发团队的终极目标,是要证明即便是在这款全新的处理器架构上,开发者也不用重写他们的软件,而只需要重新编译过就可顺利运行。
E2 架构与目前基于 X86 的英特尔、AMD 处理器,以及 ARM 架构处理器是完全不同的架构,它也不是目前市面上可见的开源处理器的变体,而是完全由微软主导开发出来的全新架构。该架构是基于被称为显式数据图执行 (Explicit Data Graph Execution) 的指令集体系结构,这个架构也被称为 EDGE 架构。
由美国国防部提出的概念性架构,主打超强多任务能力
该架构是一种尚未被实现过的全新指令集,它可将许多单独的指令组合成一个更大的群组,称为 hyperblock,其中包含数百或数千个单独的指令。这些 hyperblock 然后由 CPU 动态调度。EDGE 因此结合了在编译时查找独立数据的 VLIW 概念的优点,以及在数据可用时执行指令的超标量 RISC 概念。
现代 CPU 设计的并行性通常稳定在大约 8 个内部单元和 1 到 8 个”内核”,EDGE 原始设计可支持达数百个内部单元,并提供比现有处理器设计高数百倍的处理速度。
此架构最早是由根据美国国防部高级研究计划局 (DARPA) 的 Polymorphous Computing Architectures 提出,并由得克萨斯大学奥斯汀分校主导 EDGE 概念的发展,其最初目标是到 2012 年实现 1 TFLOPS 性能的单芯片 CPU 设计,不过直到微软公开 E2 处理器计划为止,从未被真正实现过。
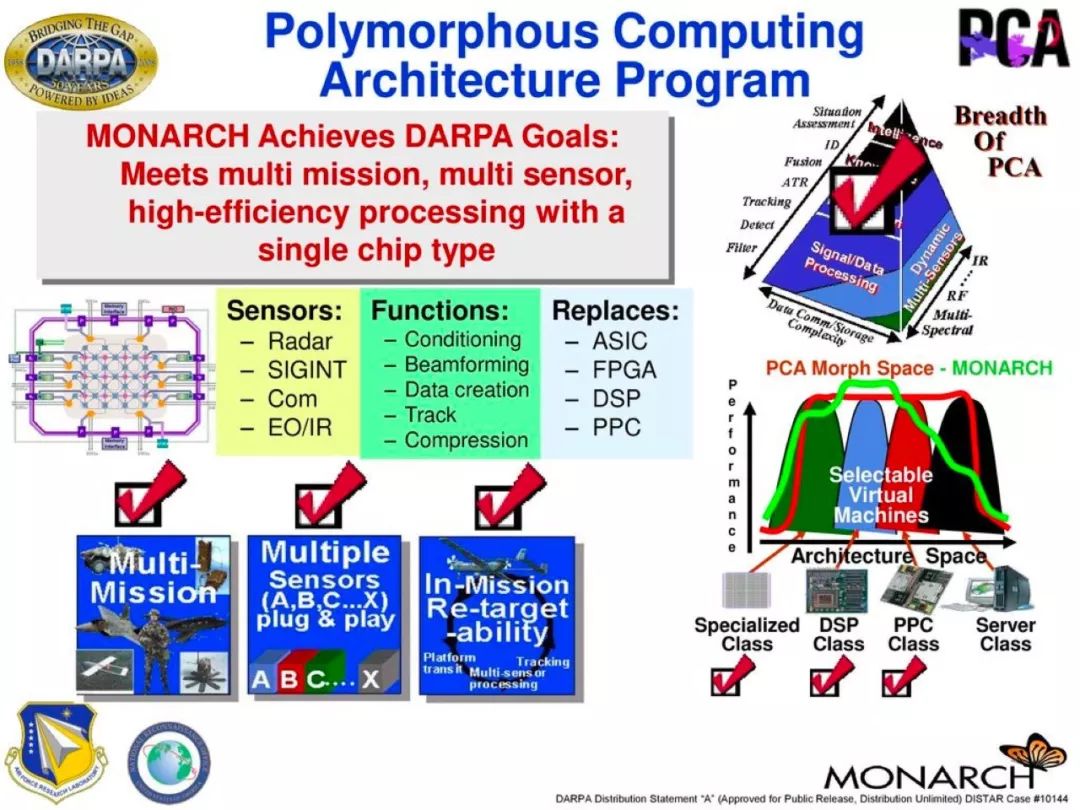
根据开发人员的描述,以 Xilinx FPGA 为基础设计的原型 E2 处理器主频为 50MHz,开发团队还设计了一个可以同时启动并运行 Windows 和 Linux 系统应用程序的周期精确仿真器 (cycle-accurate simulator)。
而参与开发的高通研究人员正在评估两种基于 EDGE 指令集的芯片设计,一种是小型的内核,代号为 R0,另一个是运行频率高达 2GHz,基于 10nm 工艺制造的 R1 内核,都是基于非循序处理 (Out of Order) 的架构。DT 君认为,前者可能是要针对 IoT 或比较单纯的网络通信应用,后者则是要负责主流系统运行,甚至是流行的 AI 模型计算,包含训练与推理等工作。
由于 EDGE 架构非常擅长多任务运行,同时又能运行操作系统与一般通用计算,若以 EDGE 设计之初的目标,恐怕连英伟达的 GPU 架构也会受到严苛的挑战。
EDGE 架构让目前的主流处理器相形见拙
传统处理器的运作模式就像个垃圾回收机,垃圾循序进入回收机、消化后,里面有个机器人可以把消化后的废物分组,然后再各自送到独立的输送带上,再由机器的不同部分来进行最终处理。不同的流水线处理不同的工作。
目前,包括英特尔、AMD 以及 Arm 在内的主流处理器都是基于这样的处理概念,这些处理器其实非常不擅长多任务处理,也因此,在今日的 AI 时代,传统处理器只能当配角,但 EDGE 架构改变了这个状况。
该核心内拥有许多小执行单元来执行这些区块,最多可达数百个计算单元,而流水线数量更可超过32 条。作为比较,Arm 最近才推出的 Cortex-A76 同时只能有 8 条流水线运行,其中 4 个用于整数数学计算,2 个用于浮点计算,2 个用在访问存储器中的数据。因此 EDGE 的理论执行效率可以达到远高于类似 Arm 之类的传统 RISC 架构。

传统架构上,核心的前端会试图在流水线上安排指令,即便是采用较先进的非循序处理架构,指令集还是必须沿着流水线处理事先被安排好的工作内容,这种乱中有序,就导致了效率的低落。就概念上,EDGE 要避免的就是流水线上的指令有排队等待被执行的状况,排队的时间等于就是被浪费掉。如果流水线上的指令集都要等待前面的指令集被完成之后才能接续执行,就会有很多处理时间被浪费掉。
EDGE 架构可以把程序打散成由简单指令组成的不同区块,并且在代码各自的寄存器中执行,而不会进入通用寄存器之中,通过这种切碎程序的执行方式,来达成多任务效率的提升,并同时维持相关数据的不可分割以及安全性需求。编译程序还会对代码进行注释以描述数据在程序中的流向,从而允许 CPU 相应地调度指令块。
而最重要的是,在核心处理这些模块的许多小型执行单元中,可以一次大量执行许多在流水线上的指令,指令集需要被排队执行的等待时间被降到最低。
E2 基本上是把 RISC 的概念做到极致化的架构,与目前市场上所有的处理架构完全不同,微软之所以开发这样的架构其实隐含极为庞大的野心,若利用指令集与架构的改变能带来革命性的效能演进,那么在量子计算普及之前的半导体计算领域,就有机会以单一架构来一统目前的传统通用与 AI 计算加速架构。
未来微软若在自己的软硬件生态中引入这样的计算架构,不论要采用开源或者是自行推出处理芯片,都将对包含英特尔、AMD、Arm,甚至英伟达和 FPGA 厂商造成极大的威胁。
最高机密的研发过程
大约从 2010 年开始,微软就一直在研发实验室秘密研发 EDGE 处理器。不过,这项技术是在21 世纪初美国得克萨斯大学奥斯汀分校作为 TRIPS(Tera-Op Reliable Intelligently Adaptive Processing System)——一种可靠、智能、自适应的 Tera-Op 处理系统开始为世人所知。

Tera-Op 指的是生成一个TFLOPS 处理器,它可以实现每秒万亿次浮点运算。在当时,这是一个很惊人的速度,当然,今天的 GPU 和专业的硬件加速器可以运行得更快些,但它们并不能运行操作系统。
目前只有计算机的顶级通用 CPU 才有机会接近或超越 TFLOPS 屏障。
研究工作进行十年并结束后,TRIPS 项目成功地生产并演示了一种雄心勃勃的原型芯片。微软的研发实验室引进了来自 TRIPS 的知识、经验和架构理念,并融入到现在的 E2 项目中,计划利用其新颖设计超越目前英特尔和 Arm 的芯片。
EDGE 指令如何实作芯片及目标应用都还相当神秘
E2 已经持续开发了好几年,但本月发生的三件至关重要的事情。首先,该团队透露,Windows 10 已经被移植到该架构中,并为应用程序开发人员提供了大量支持材料,使他们能够为该平台构建应用程序。2017 年 10 月,研究人员说他们能够得到 Linux 的权限。
其次,有消息称,美国芯片设计巨头高通 (Qualcomm) 正与微软 (Microsoft) 合作。第三,微软的网站上没有很多关于 E2 项目的信息。上周,微软诡异地删除了这个项目的相关网页,将 URL 指向一个不相关的项目。
今年计算机架构国际研讨会在本月于加州举行,会上微软研究人员 Doug Burger 和 Aaron Smith 以及高通处理器研究部门工程高级主管 Greg Wright 走上舞台,讨论他们的前沿工作,并演示了在 E2 模拟器上运行的 Windows 操作系统。

图|运行在 EDGE 试作芯片上的 Windows 10 操作系统
Burger 是 TRIPS 项目的共同负责人,他曾在奥斯汀德克萨斯大学指导 Smith 博士研究 CPU 软件设计。现在他俩都在微软研究院工作。
Smith 在 LinkedIn 主页上指出,他正作为一名主要的研究经理,以及他在 E2 项目上的角色:”我开始并领导微软研究院的 E2 项目,该项目正在研究下一代 EDGE 架构。我把这个项目从一个人团队发展到有几十名工程师,他们来自不同的部门、公司和国家。”
外界知道的是,E2 的指令集是几年前完成的,现在大部分是保密的。但是,我们知道,每个代码块都是从全局寄存器到临时专用寄存器的数据读入开始,然后处理这些数据,最后将结果写回全局寄存器。
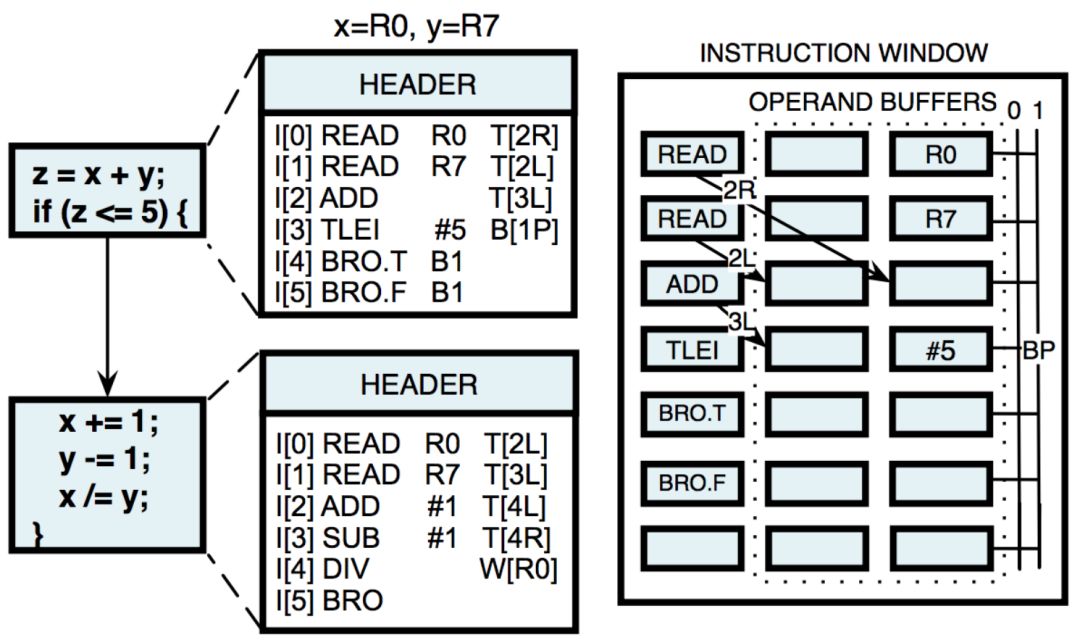
图|编译成 EDGE 指令的 C 语言代码示例
微软在设计芯片方面有自己的优势。例如,HoloLens 虚拟现实眼镜上的数学加速器。微软还进行了大量的私人研究,有些项目已经进入了商业产品,比如在 Linux 系统 SQL Server 上的 Drawbridge;而有些则永远停留在实验阶段。
但微软和高通的发言人均拒绝对此架构置评。
可能成为除量子计算外半导体产业最引人注目的架构革新
E2 公开后,微软的一位发言人回复了一些额外细节。她说:”E2 目前是一个研究项目,目前还没有生产计划。”
“E2 是一个研究项目,我们做了很多工程来了解这种类型的架构是否能运行真正的堆栈,我们结束了与高通的合作关系,因为研究问题已经得到解答。”
至于删除的网页,她补充说:”鉴于大部分研究工作已经结束,我们决定将网页的内容降至最低,以减少该研究对现有合作伙伴有冲突的外界猜想。”
“我们希望能够将工作中所学到的知识融入到正在进行的研究中。”

图丨被微软移除的 E2 项目页面
目前此架构已经步入开发的最终阶段,可运行主流操作系统,又有不逊于 GPU 与 AI 加速芯片的性能表现是其最大特色,在单一计算架构中能兼顾通用性与多工性能表现,是目前所有计算架构单难以达到的目标。即便是量子计算,目前也多半是用来进行特殊计算的加速,而无法运行操作系统或其他通用计算工作。
微软在研发过程中与高通的合作也相当值得玩味,这代表了 2 个可能性:
高通是否可能使用该架构来进军终端以及服务器等云端计算市场,如果是,那么该架构对外授权甚至开源的机会就很大;但如果微软希望打造封闭系统,那么所需要的 EDGE 架构芯片将可能由高通来设计提供,毕竟终端脱离不了无线网络技术,未来 5G 网络的支持会是终端计算架构的主要发展方向,通过与高通的合作来取得第一手无线技术也是可能的选项,而高通也可能借此架构成为独家供货商。
当然,目前英特尔也在推动 CPU 与FPGA 的异构结合,理论上也可以同时运行操作系统与 AI 加速计算,但此架构属于异构设计,不同计算架构之间的沟通仍需要进行转换,在某些混合应用上,可能性能就不会那么突出。
但不论未来如何发展,微软在操作系统与云端服务等应用生态的布局与影响力非常重大,如果真的推出完全针对自己操作系统优化的计算架构,且在单一架构上完成过去必须异构结合才有办法处理的工作,那么这件事将对整个半导体产业以及软件平台生态的意义将不亚于当初 CUDA 以及量子计算产品推出的影响。
-End-







