案例分享 | 轻量而高效,12 周落地一个趣味音乐交互!

文 / TFX 产品经理 Anusha Ramesh、TFX 软件工程师 David Zats、TensorFlow.js 软件工程师 Ping Yu 以及 Magenta 团队 AI 定向实习生 Lamtharn (Hanoi) Hantrakul
简介
Sounds of India 是一款独特而有趣的交互式音乐体验应用,以印度传统为灵感,并由机器学习提供支持。当用户在演唱印度歌曲时,浏览器中的机器学习模型会实时将他们通过移动设备上输入的声音转换为各种印度古典乐器的声音。
Sounds of India
https://soundsofindia.withgoogle.com/
完成整个体验的开发过程仅需 12 周,您可了解开发者在使用 TensorFlow 生态系统时,如何快速地将模型从研究阶段推进到规模化生产。
研究:Magenta 的微分数字信号处理
Magenta 是 Google AI 中的一个开源研究项目,旨在探索机器学习可以有哪些创新使用。微分数字信号处理 (Digital Signal Processing,DDSP) 是一个全新的开源库,融合了现代机器学习与可解释信号处理技术。
Magenta
https://magenta.tensorflow.org/DDSP
https://magenta.tensorflow.org/ddsp
不同于训练纯深度学习模型(如 WaveNet)去逐个渲染样本的波形,我们改为训练轻量级模型,这些模型能够向这些可微的 DSP 模块中输出随时间变化的控制信号(因此,DDSP 中有一个额外的“D”),从而合成最终声音。我们在 TensorFlow Keras 层的递归和卷积模型中整合了 DDSP,其有效生成音频的速度为更大型自回归模型的 1000 倍,而对模型参数和训练数据的需求仅为后者的百分之一。
WaveNet
https://deepmind.com/blog/article/wavenet-generative-model-raw-audio
DDSP 中一个有趣的应用是音色转换,即将用户输入的声音转换为乐器声。先用目标萨克斯对 DDSP 模型开展 15 分钟的训练。然后,你可以演唱一段旋律,经过训练的 DDSP 模型会将其重新渲染成萨克斯的声音。我们已在 Sounds of India 中将这项技术应用于三种印度古典乐器:Bansuri、Shehnai 和 Sarangi。
音色转换
https://colab.sandbox.google.com/github/magenta/ddsp/blob/master/ddsp/colab/demos/timbre_transfer.ipynb#scrollTo=Go36QW9AS_CD
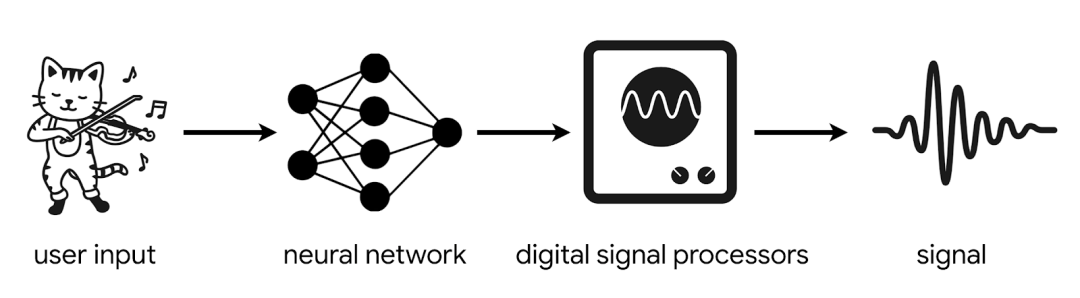
使用 TFX,TFJS 训练并部署到浏览器中
TensorFlow Extended (TFX) 是用于生产机器学习 (ML) 的端到端平台,包括准备数据、训练、验证和在生产环境中部署模型。使用 TFX 训练模型(将用户的声音转换为上述某种乐器声),然后将这些模型转换为 TensorFlow.js 格式,以部署在标准网络浏览器中。
TensorFlow Extended (TFX)
https://tensorflow.google.cn/tfx/TensorFlow.js
https://tensorflow.google.cn/js
通过部署到浏览器中,为用户带来与机器学习模型交互的无缝体验:仅需点击超链接,加载网站页面。而无需安装工作。在浏览器中运行客户端,我们能够直接在传感器数据源处执行推理,从而最大程度地减少延迟,降低与大型显卡、CPU 和内存相关的服务器成本。此外,应用会将您的声音用作输入,因此用户隐私十分重要。由于整个端到端的体验都发生在客户端和浏览器当中,因此传感器或麦克风收集到的数据保留在用户的设备上。
基于浏览器的机器学习模型需要进行优化以尽可能缩减其大小,从而降低所用带宽。在这种情况下,每种乐器的理想超参数也大有不同。我们利用 TFX 对数百个模型进行大规模训练和调试,确定每个乐器可用的最小模型尺寸。因此,我们能够大幅降低其内存占用。例如,在未对音质产生明显影响的情况下,Bansuri 乐器模型的磁盘占用量约降低至以前的二十分之一。
我们还可借助 TFX 在不同的模型架构(GRU、CNN)、不同类型的输入(响度、RMS 能量)和不同的乐器数据源上执行快速迭代。我们每次都能够快速有效地运行 TFX 流水线,生成具有所需特性的新模型。
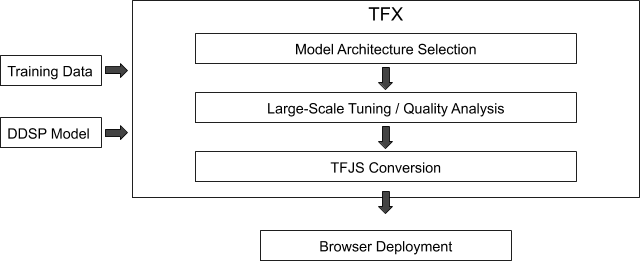
构建 TensorFlow.js DDSP 模型需要达到严格的性能和模型质量目标,所以具有独特的挑战性。模型需要高效执行音色转换,以便在移动设备上有效运行。同时,一旦模型质量出现任何下降,便会导致音频失真,进而破坏用户体验。
我们首先探索了众多的 TensorFlow.js 后端和模型架构。WebGL 后端的优化程度最高,而 WebAssembly 后端则可在低端手机上运行良好。我们采用了基于 Convnet 的 DDSP 模型,并利用 WebGL 后端,以满足 DDSP 的计算需求。
WebGL 后端
https://github.com/tensorflow/tfjs/tree/master/tfjs-backend-webglWebAssembly 后端
https://github.com/tensorflow/tfjs/tree/master/tfjs-backend-wasm
为缩短模型下载时间。我们研究了模型的拓扑结构,并使用 Fill/ZeroLike 算子压缩了大量常数张量,从而将模型大小从 10MB 缩减到 300KB。
为使 TensorFlow.js 模型准备就绪,以便在生产环境中将其大规模部署在设备上,我们还重点关注了以下三个主要领域:推理性能、内存占用和数值稳定性。
DDSP 模型中包括神经网络和信号合成器。合成器部分包含许多需要大量算力的信号处理算子。为提升模型在移动设备上的性能,我们使用特殊的 WebGL Shader 重新编写了内核,以便充分利用 GPU。例如,通过并行累积求和算子,推理时间可缩短 90%。
我们的目标是尽可能在更多种类型的移动设备上运行模型。由于许多手机的 GPU 显存有限,我们需要确保尽可能降低模型的内存占用。通过处理中间张量并添加新标记,我们能够提早处理 GPU 纹理,从而实现这一目标。通过这些方法,我们可以将显存占用减少 60%。
DDSP 模型需要达到非常高的数值精度,才能生成动听的音乐。这一点与常见的分类模型截然不同:在分类模型中,一定范围内的精度降低并不会影响最终的分类结果。我们在此体验中使用的 DDSP 模型为生成模型。任何精度较低和不连续的音频输出都可轻易被我们敏感的耳朵发觉。使用 float16 WebGL 纹理时,我们遇到了数值稳定性问题。因此,我们重新编写了一些主要算子,以减少输出结果的上溢和下溢。例如,在累积求和算子中,我们会确保在 Shader 内以全浮点精度完成累积,并在将输出结果写入 float16 纹理前,运用模数计算来避免结果溢出。
动手尝试!
您可使用手机访问 g.co/SoundsofIndia,尝试此体验。如您愿意,请与我们分享您的结果。我们十分期待看到您用自己的声音所创作的音乐。
如果您有兴趣了解机器学习如何增强创造力与创新性,可浏览 Magenta 团队的博客,详细了解该项目,并为他们的开源 GitHub 贡献力量,也可查看 #MadeWithTFJS,从 TensorFlow.js 社区获得更多浏览器端机器学习示例。如果您对使用 ML 最佳做法在生产环境中大规模训练并部署模型比较感兴趣,请查看 Tensorflow Extended。
博客
https://magenta.tensorflow.org/blogGitHub
https://github.com/magenta/magenta#MadeWithTFJS
https://twitter.com/search?q=%23madewithtfjs&src=typed_query
致谢
本项目的实现离不开 Miguel de Andrés-Clavera、Yiling Liu、Aditya Mirchandani、KC Chung、Alap Bharadwaj、Kiattiyot (Boon) Panichprecha、Pittayathorn (Kim) Nomrak、Phatchara (Lek) Pongsakorntorn、Nattadet Chinthanathatset、Hieu Dang、Ann Yuan、Sandeep Gupta、Chong Li、Edwin Toh、Jesse Engel 的巨大努力,以及 Michelle Carney、Nida Zada、Doug Eck、Hannes Widsomer 和 Greg Mikels 提供的其他帮助。非常感谢 Tris Warkentin 和 Mitch Trott 的大力支持。


加入案例分享,请点击 “阅读原文” 填写您的用例与相关信息,我们会尽快与你联系。







