三万字整理深度匹配模型
❝知乎:辛俊波 腾讯高级研究员
编辑:阿泽的学习笔记
❞
本文主要启发来源SIGIR2018的这篇综述性slides《Deep Learning for Matching in Search and Recommendation》,重点阐述搜索和推荐中的深度匹配问题,非常solid的综述,针对里面的一些方法,尤其是feature-based的深度学习方法增加了近期一些相关paper。推荐系统和搜索应该是机器学习乃至深度学习在工业界落地应用最多也最容易变现的场景。而无论是搜索还是推荐,本质其实都是匹配,搜索的本质是给定query,匹配doc;推荐的本质是给定user,推荐item。本文主要讲推荐系统里的匹配问题,包括传统匹配模型和深度学习模型。
深度学习之风虽然愈演愈烈,但背后体现的矩阵分解思想、协同过滤思想等其实一直都是贯穿其中,如svd++体现的userCF和itemCF的思想,FM模型本质上可以退化成以上大多数模型等。多对这些方法做总结,有助于更深刻理解不同模型之间的关联。

整个目录大纲如下所示:
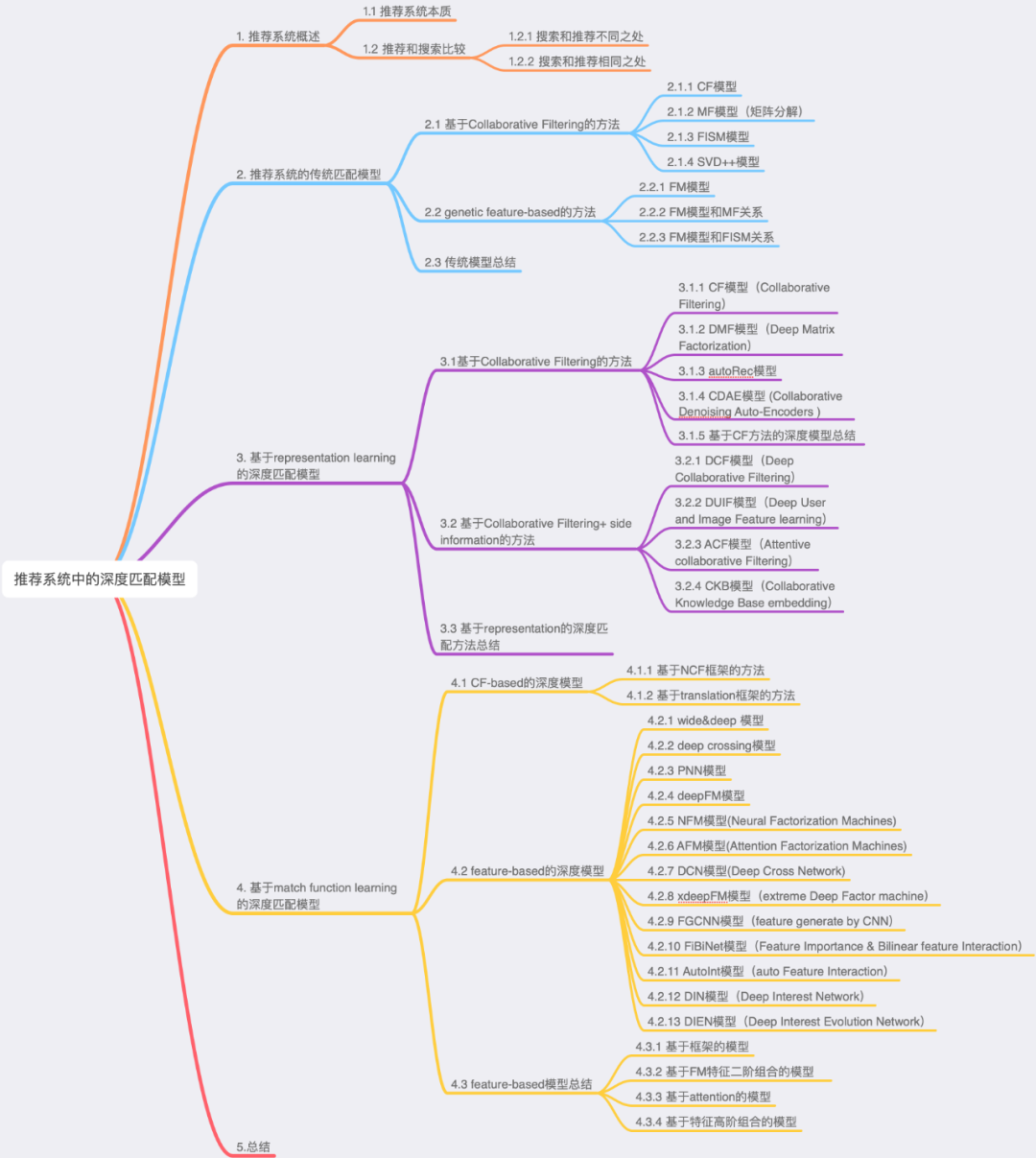
1.推荐系统概述
1.1 推荐系统本质
推荐系统就是系统根据用户的属性(如性别、年龄、学历、地域、职业),用户在系统里过去的行为(例如浏览、点击、搜索、购买、收藏等),以及当前上下文环境(如网络、手机设备、时间等),从而给用户推荐用户可能感兴趣的物品(如电商的商品、feeds推荐的新闻、应用商店推荐的app等),从这个过程来看,推荐系统就是一个给user匹配(match)感兴趣的item的过程。
1.2 推荐和搜索比较
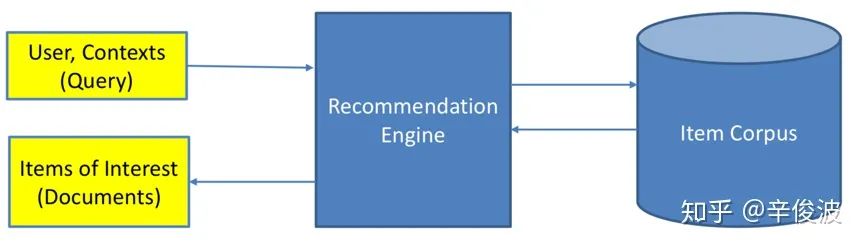
推荐和搜索有很多相同又有很多不同的地方,放到一起的原因是两者其实都是一个match的过程,图1.1展示的是一个搜索引擎的架构,需要match的是query和相关的doc;图1.2展示的是一个推荐系统的架构,需要match的是user(可能会带有主动意图的query)和相关的item。

1.2.1 搜索和推荐不同之处
(1) 意图不同
搜索是用户带着明确的目的,通过给系统输入query来主动触发的,搜索过程用户带着明确的搜索意图。而推荐是系统被动触发,用户是以一种闲逛的姿态过来的,系统是带着一种“猜”的状态给用户推送物品。
简单来说,搜索是一次主动pull的过程,用户用query告诉系统,我需要什么,你给我相关的结果就行;而推荐是一次push的过程,用户没有明显意图,系统给用户被动push认为用户可能会喜欢的东西吧。
(2) 时效不同
搜索需要尽快满足用户此次请求query,如果搜索引擎无法满足用户当下的需求,例如给出的搜索结果和用户输入的query完全不相关,尽是瞎猜的结果,用户体验会变得很差。
推荐更希望能增加用户的时长和留存从而提升整体LTV(long time value,衡量用户对系统的长期价值),例如视频推荐系统希望用户能够持续的沉浸在观看系统推荐的视频流中;电商推荐系统希望用户能够多逛多点击推荐的商品从而提高GMV。
(3) 相关性要求不同
搜索有严格的query限制,搜索结果需要保证相关性,搜索结果量化评估标准也相对容易。给定一个query,系统给出不同结果,在上线前就可以通过相关性对结果进行判定相关性好坏。例如下图中搜索query为“pool schedule”,搜索结果“swimming pool schedule”认为是相关的、而最后一个case,用户搜索“why are windows so expensive”想问的是窗户为什么那么贵,而如果搜索引擎将这里的windows理解成微软的windows系统从而给出结果是苹果公司的mac,一字之差意思完全不同了,典型的bad case。

而推荐没有明确的相关性要求。一个电商系统,用户过去买了足球鞋,下次过来推荐电子类产品也无法说明是bad case,因为用户行为少,推完全不相关的物品是系统的一次探索过程。推荐很难在离线阶段从相关性角度结果评定是否好坏,只能从线上效果看用户是否买单做评估。
(4) 实体不同
搜索中的两大实体是query和doc,本质上都是文本信息。这就是上文说到的为什么搜索可以通过query和doc的文本相关性判断是否相关。Query和doc的匹配过程就是在语法层面理解query和doc之间gap的过程。
推荐中的两大实体是user和item,两者的表征体系可能完全没有重叠。例如电影推荐系统里,用户的特征描述是:用户id,用户评分历史、用户性别、年龄;而电影的特征描述是:电影id,电影描述,电影分类,电影票房等。这就决定了推荐中,user和item的匹配是无法从表面的特征解决两者gap的。

(5) 个性化要求不同
虽然现在但凡是一个推荐系统都在各种标榜如何做好个性化,“千人千面”,但搜索和推荐天然对个性化需求不同。搜索有用户的主动query,本质上这个query已经在告诉系统这个“用户”是谁了,query本身代表的就是一类用户,例如搜索引擎里搜索“深度学习综述”的本质上就代表了机器学习相关从业者或者对其感兴趣的这类人。在一些垂直行业,有时候query本身就够了,甚至不需要其他用户属性画像。例如在app推荐系统里,不同的用户搜索“京东”,并不会因为用户过去行为、本身画像属性不同而有所不同。
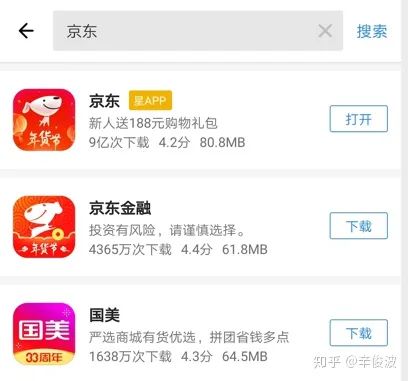
而推荐没有用户主动的query输入,如果没有用户画像属性和过去行为的刻画,系统基本上就等于瞎猜。
1.2.2 搜索和推荐相同之处
(1)本质是都是match过程
如果把user比作query,把item比作doc,那么推荐和搜索在这个层面又是相同的,都是针对一个query(一个user),从海量的候选物品库中,根据query和doc的相关性(user过去的历史、画像等和item的匹配程度),去推荐匹配的doc(item)
(2)目标相同
搜索和推荐的目标都是针对一次context(或者有明确意图,或者没有),从候选池选出尽可能满足需求的物品。两者区别只是挑选过程使用的信息特征不同。
(3)语义鸿沟(semantic gap)都是两者最大的挑战
在搜索里表现是query和doc的语义理解,推荐里则是user和item的理解。例如,搜索里多个不同的query可能表示同一个意图;而推荐里用来表示user和item的特征体系可能完全不是一个层面的意思。
2.推荐系统的传统匹配模型
2.1 基于Collaborative Filtering的方法
2.1.1 CF模型
说到推荐系统里最经典的模型,莫过于大名鼎鼎的协同过滤了。协同过滤基于一个最基本的假设:一个用户的行为,可以由和他行为相似的用户进行预测。
协同过滤的基本思想是基于<user, item>的所有交互行为,利用集体智慧进行推荐。CF按照类型可以分为3种,user-based CF、item-based CF和model-based CF。
(1)User-base CF:通过对用户喜欢的item 进行分析,如果用户a和用户b喜欢过的item差不多,那么用户a和b是相似的。类似朋友推荐一样,可以将b喜欢过但是a没有看过的item推荐给a
(2)Item-base CF: item A和item B如果被差不多的人喜欢,认为item A和item B是相似的。用户如果喜欢item A, 那么给用户推荐item B大概率也是喜欢的。比如用户浏览过这篇介绍推荐系统的文章,也很有可能会喜欢和推荐系统类似的其他机器学习相关文章。
(3)model-base CF: 也叫基于学习的方法,通过定义一个参数模型来描述用户和物品、用户和用户、物品和物品之间的关系,然后通过已有的用户-物品评分矩阵来优化求解得到参数。例如矩阵分解、隐语义模型LFM等。
CF协同过滤的思路要解决的问题用数据形式表达就是:矩阵的未知部分如何填充问题(Matrix Completion)。如图2.1所示,已知的值是用户已经交互过的item,如何基于这些已知值填充矩阵剩下的未知值,也就是去预测用户没有交互过的item是矩阵填充要解决的问题。
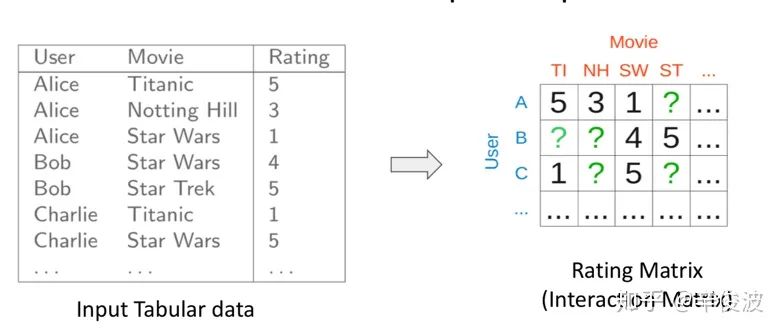
矩阵填充可以用经典的SVD(Singular Value Decomposition )解决,如图2.1所示

其中左侧M=m*n表示用户评分矩阵,m矩阵的行表示用户数,n矩阵的列表示item数,在大多数推荐系统中m和n规模都比较大,因此希望通过将M分解成右侧低秩的形式。一般来说SVD求解可以分为三步:
(1) 对M矩阵的missing data填充为0
(2) 求解SVD问题,得到U矩阵和V矩阵
(3) 利用U和V矩阵的低秩k维矩阵来估计
对于第二步种的SVD求解问题,等价于以下的最优化问题:

其中yij为用户i对物品j的真实评分,也就是label, U和V为模型预估值,求解矩阵U和V的过程就是最小化用户真实评分矩阵和预测矩阵误差的过程。
这种SVD求解方法存在以下问题:
(1) missing data(在数据集占比超过99%)和observe data权重一样
(2) 最小化过程没有正则化(只有最小方差),容易产生过拟合
因此,一般来说针对原始的SVD方法会有很多改进方法。
2.1.2 MF模型(矩阵分解)
为解决上述过拟合情况,矩阵分解模型(matrix factorization)提出的模型如下

MF模型的核心思想可以分成两步
(1)将用户u对物品i的打分分解成用户的隐向量vu,以及物品的隐向量vi
(2)用户u和物品i的向量点积(inner product)得到的value,可以用来代表用户u对物品i的喜好程度,分数越高代表该item推荐给用户的概率就越大
同时,MF模型引入了l2正则来解决过拟合问题

当然,这里除了用l2 正则,其他正则手段例如l1正则,cross-entropy正则也都是可以的。
2.1.3 FISM模型
上述提到的两种模型CF方法和MF方法都只是简单利用了user-item的交互信息,对于用户本身的表达是userid也就是用户本身。2014年KDD上提出了一种更加能够表达用户信息的方法,Factored Item Similarity Model,简称FISM,顾名思义,就是将用户喜欢过的item作为用户的表达来刻画用户,用数据公式表示如下:

注意到用户表达不再是独立的隐向量,而是用用户喜欢过的所有item的累加求和得到作为user的表达;而item本身的隐向量vi是另一套表示,两者最终同样用向量内积表示。
2.1.4 SVD++模型
MF模型可以看成是user-based的CF模型,直接将用户id映射成隐向量,而FISM模型可以看成是item-based的CF模型,将用户交户过的item的集合映射成隐向量。一个是userid本身的信息,一个是user过去交互过的item的信息,如何结合user-base和item-base这两者本身的优势呢?
SVD++方法正是这两者的结合,数学表达如下

其中,每个用户表达分成两个部分,左边vu表示用户id映射的隐向量(user-based CF思想),右边是用户交互过的item集合的求和(item-based CF思想)。User和item的相似度还是用向量点击来表达。
这种融合方法可以看成早期的模型融合方法,在连续3年的Netflix百万美金推荐比赛中可是表现最好的模型。
2.2 Generic feature-based的方法
上述的方法中,无论是CF, MF, SVD, SVD++,还是FISM,都只是利用了user和item的交互信息(ratin g data),而对于大量的side information信息没有利用到。例如user本身的信息,如年龄,性别、职业;item本身的side information,如分类,描述,图文信息;以及context上下文信息,如位置,时间,天气等。因此,传统模型要讲的第二部分,是如何利用这些特征,去构造feature-based的model.

2.2.1 FM模型
首先要介绍的是大名鼎鼎的FM模型。FM模型可以看成由两部分组成,如图2.4所示,蓝色的LR线性模型,以及红色部分的二阶特征组合。对于每个输入特征,模型都需要学习一个低维的隐向量表达v,也就是在各种NN网络里所谓的embedding 表示。

FM模型的数学表达如图2.5所示
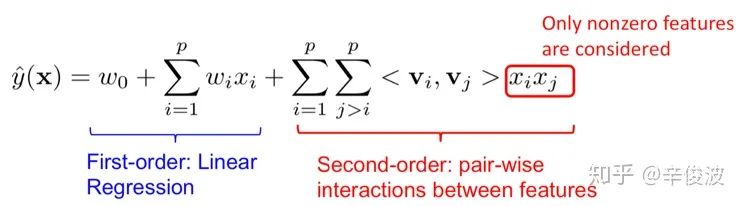
注意红色部分表示的是二阶特征的两两组合(特征自己和自己不做交叉),向量之间的交叉还是用向量内积表示。FM模型是feature-based模型的一个范式表达,接下来介绍的几个模型都可以看成是FM模型的特殊范例。
2.2.2 FM模型和MF关系
假如只使用userid和itemid,我们可以发现其实FM退化成加了bias的MF模型,如图2.6所示

数学表达式如下:

2.2.3 FM模型和FISM关系
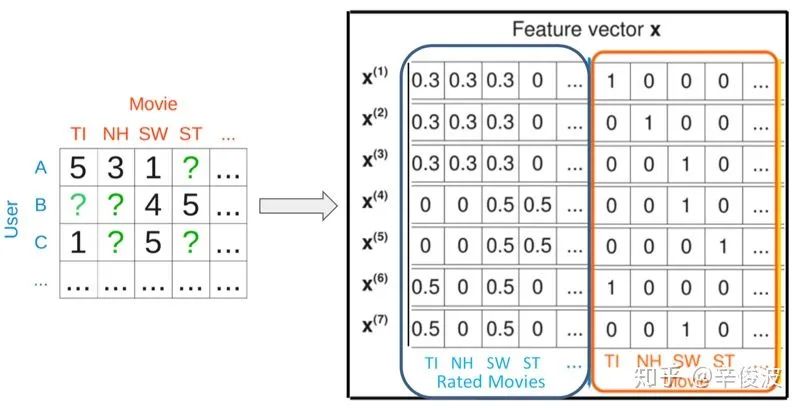
如果输入包含两个变量,1)用户交互过的item集合;2)itemid本身,那么,此时的FM又将退化成带bias的FISM模型,如图2.7所示,蓝色方框表示的是用户历史交互过的item(rated movies),右边橙色方框表示的是itemid本身的one-hot特征
此时的FM模型数学表达如下:
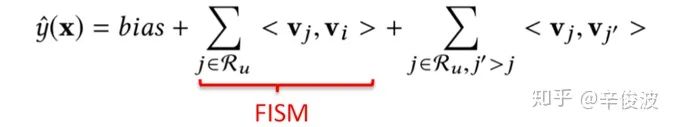
同样道理,如果再加上userid的隐向量表达,那么FM模型将退化成SVD++模型。可见,MF, FISM, SVD++其实都是FM的特例。
2.3 传统模型总结
上面介绍的模型都是通过打分预测来解决推荐系统的排序问题,这在很多时候一般都不是最优的,原因有如下几个方面:
(1)预测打分用的RMSE指标和实际的推荐系统排序指标的gap
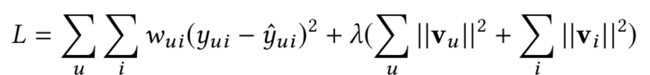
预测打分用的RMSE拟合的是最小方差(带正则),而实际面临的是个排序问题
(2) 观察数据天然存在bias
用户一般倾向于给自己喜欢的item打分,而用户没有打分过的item未必就真的是不喜欢。针对推荐系统的排序问题,一般可以用pairwise 的ranking来替代RMSE

如上述公式所示,不直接拟合用户对item的单个打分,而是以pair的形式进行拟合;一般来说,用户打分高的item>用户打分低的item;用户用过交互的item>用户未交互过的item(不一定真的不喜欢)
3.基于representation learning的深度匹配模型
终于要讲到激动人心的深度学习部分了。深度学习匹配模型从大致方向上可以分为两大类,分别是基于representation learning的模型以及match function learning的模型。
本章主要讲述第一种方法,representation learning,也就是基于表示学习的方法。这种方法会分别学习用户的representation以及item的representation,也就是user和item各自的embedding向量(或者也叫做隐向量),然后通过定义matching score的函数,一般是简单的向量点击、或者cosine距离来得到两者的匹配分数。整个representation learning的框架如图3.1所示,是个典型的user和item的双塔结构

基于representation learning的深度学习方法,又可以分为两大类,基于CF以及CF + side info的方法。下面的介绍将分别从input 、representation function和matching function三个角度分别看不同的模型有什么不同
3.1 基于Collaborative Filtering的方法
3.1.1 CF模型(collaborative filtering)
重新回顾下传统方法里的协同过滤方法,如果从表示学习的角度来看,就是个经典的representation learning的模型,分别学习user和item的隐向量。
(1) Input layer
只有两个,分别是userid(one-hot),itemid(one-hot)
(2) representation function
线性embedding layer
(3) matching function
向量内积(inner product)

3.1.2 模型(Deep Matrix Factorization)
DMF模型也就是深度矩阵分解模型,在传统的MF中增加了MLP网络,整个网络框架如图3.3所示。
(1)input layer
由两部分组组成,其中user由user交互过的item集合来表示,是个multi-hot的打分表示,如[0 0 4 0 0 … 1 5 …],在矩阵中用行表示;item也由交互过的user集合来表示,也是个multi-hot的表示,如[5 0 0 3 … 1 3],在矩阵中用列表示
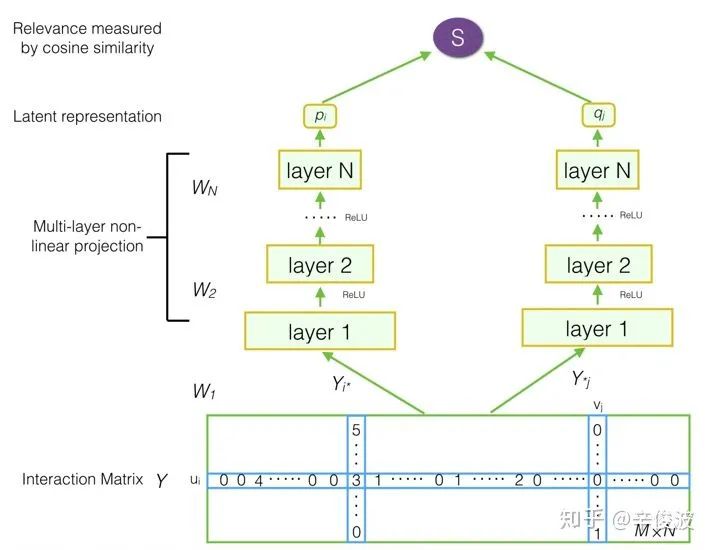
可以发现这里的输入都是one-hot的,一般来说M用户数比较大,N作为item数量假设是百万级别的。
(2)representation function
Multi-Layer-Perceptron,也就是经典的全连接网络
(3)matching function
用cosine点击表示两个向量的匹配分数

对比普通的CF模型,最大的特点是在representation function中,增加了非线性的MLP,但是由于输入是one-hot的,假设用户规模是100万,MLP的第一层隐层是100,整个网络光user侧的第一层参数将达到1亿,参数空间将变得非常大
3.1.3 AutoRec模型
借鉴auto-encoder的思路,AutoRec模型对输入做重建,来建立user和item的representation,和CF一样,也可以分为user-based和item-based的模型。对于item-based AutoRec,input为R里的每列,即每个item用各个user对它的打分作为其向量描述;对于user-based AutoRec则是用R里的每行来表示,即每个user用他打分过的item的向量来表达。
用ru表示用户向量,ri表示item向量,通过autoencoder将ru或者ri投射到低维向量空间(encode过程),然后再将其投射到正常空间(decode过程),利用autoencoder中目标值和输入值相近的特性,从而重建(reconstruct)出用户对于未交互过的item的打分。
(1) input layer
和DMF一样,user用user作用过的item集合表示,item则用itemid本身表示,图中在原slides是说user-autoencoder,但个人在看原始autoRec论文时,这块应该有误,应该是item-based的,因为m表示的是用户数,n表示item数,下方的输入表示所有user(1,2,3,…m)对item i的交互输入

(2)representation function
通过auto-encoder的结构表示,其中,h(r; theta)表示的是输入层到隐层的重建;由于输入的是用户交互过的item(multi-hot),所以在隐层中的蓝色节点表示的就是user representation;而输出的节点表示的是item的representation,这样就可以得到user和item各自representation,如下面公式所示

损失函数为最小化预测的平方差以及W和V矩阵的L2正则
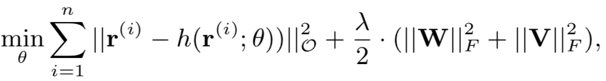
(3)matching function
有了user和item的representation,就可以用向量点击得到两者的匹配分数
3.1.4 模型 (Collaborative Denoising Auto-Encoders )
CDAE模型类似SVD++的思想,除了userid本身表达用户,也将用户交互过的item作为user的表达。
(1) input layer
用户id,用户历史交互过的item;以及itemid。可以发现对比上述基础的autoRec,用户侧输入同时使用了用户历史交互过的item以及userid本身这个bias,思想很类似SVD++。如图3所示的input layer节点,绿色节点表示每个用户交互过的item,最下面的红色节点user node表示用户本身的偏好,可以认为是userid的表达
(2) representation function
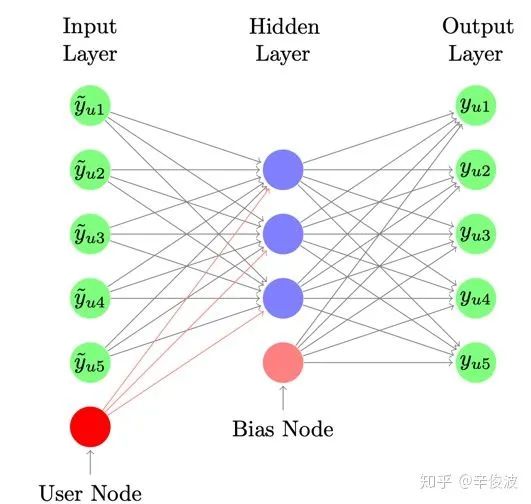
其中,中间蓝色的隐层节点作为用户表示,其中Vu为input layer中的user node的representation,针对所有用户id会学习一个和item无关的vu向量表达,可以认为是用户本身的bias,例如有些用户打分本身比较严格,再好的item打分也不会太高;有些用户打分很宽松,只要item别太差都会给高分,加上Vu可以更好的刻画用户之间天然的bias。

而对于输出层的节点,可以认为是用户u对物品i的打分预测

(3) matching function
使用向量点积作为匹配分数
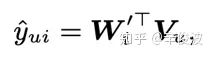
3.1.5 基于CF方法的深度模型总结
总结下以上基于CF的方法,有以下几个特点
(1)user或者item要么由本身id表达,要么由其历史交互过的行为来表达
(2)用历史交互过的行为来作为user或者item的表达,比用id本身表达效果更好,但模型也变得更复杂
(3) Auto-encoder本质上等同于MLP+MF,MLP用全连接网络做user和item的representation表达

(4) 所有训练数据仅用到user-item的交互信息,完全没有引入user和item的side info信息
3.2 基于Collaborative Filtering+ side information的方法
基于CF的方法没有引入side information,因此,对于representation learning的第二种方法,是基于CF + side info,也就是在CF的方法上额外引入了side info。
3.2.1 DCF模型(Deep Collaborative Filtering)
(1) input layer
除了用户和物品的交互矩阵,还有用户特征X和物品特征Y
(2) representation function
和传统的CF表示学习不同,这里引入了用户侧特征X例如年龄、性别等;物品侧特征Y例如文本、标题、类目等;user和item侧的特征各自通过一个auto-encoder来学习,而交互信息R矩阵依然做矩阵分解U,V。整个模型框架如图3.6所示。
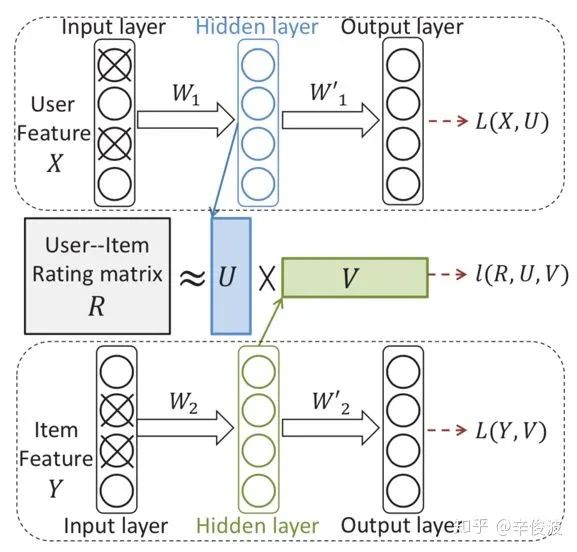
其中W1, 表示的用户侧特征X在auto-encoder过程中的encode部分,也就是输入到隐层的重建,P1表示的是用户特征到交互矩阵R的映射;而W2表示物品侧特征Y在auto-encoder过程中的encode部分。P2表示的是物品特征到交互矩阵R的映射。
损失函数优化,需要最小化用户侧特征的reconstruction和item侧的encoder部分,以及交互矩阵和预测矩阵的平方差,还有加上L2正则。如图3.7第一个公式


图3.7下面两组公式中,可以看出用户侧和物品侧特征都由两项error组成,第一项衡量的是input和corrupted input构建的预估误差,需要保证W1和W2对于corrupted 后的input x 和y不能拟合太差;第二项表达的是映射后的隐层特征空间W1X和投射到U矩阵的误差不能太大。
简单理解,整个模型的学习,既需要保证用户特征X和物品特征Y本身encode尽可能准确(auto-encoder的reconstruction误差),又需要保证用户对物品的预估和实际观测的尽可能接近(矩阵分解误差),同时正则化也约束了模型的复杂度不能太高
3.2.2 DUIF模型(Deep User and Image Feature Learning)
(1) input layer
除了用户和物品的交互矩阵,还有用户特征X和物品特征Y
(2) representation function
整个match score可以用下图表示:fi表示原始图片特征,通过CNN网络提取的图片特征作为item的表达,然后用一个线性映射可以得到item的embedding表达

(3) match function
通过模型学到的pu作为用户的representation,以及通过CNN提取的图片特征作为item的 representation, 两者通过向量点积得到两者的匹配分数
3.2.3 ACF模型(Attentive Collaborative Filtering)
Sigir2017提出的Attention CF方法,在传统的CF里引入了attention机制。这里的attention有两层意思,第一层attention,认为用户历史交互过的item的权重是不一样的;另一个attention意思是,用户同一个item里到的视觉特征的权重也是不一样的,如图3.8所示。

(1) input layer
a) 用户侧:userid;用户历史交互过的item
b) Item侧:itemid; item相关的视觉相关特征
(2) representation function
可以分为两个attention,一个是component 层级的attention,主要是提取视觉特征;第二层是item层级的attention,主要提取用户对物品的喜好程度权重。
a) component-attention
在该paper里的推荐系统针对的是multi-media的,有很多图文和视频的特征信息提取,所以引入的第一层attention指的是component attention,认为对于不同的components 对item representation的贡献程度是不同的,如图3.9所示

对第l个item,输入为不同region本身的特征xl1, xl2, xlm,表示的是m个不同的item feature, 以及用户输入ui,最终item的表达为不同的region的加权embedding。
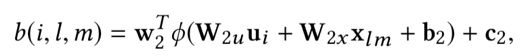

其中第一个公式表示用户i对物品l第m个component(例如图片特征中的局部区域特征,或者视频中不同帧的特征)的权重;第二个公式softmax对attention权重归一化
b) item attention
第二层attention,认为用户作用过的item历史中,权重应该是不同的。这里文章使用了SVD++的方式,用户本身的表达引入了a(i, l),代表的是用户i对其历史交互过的物品l的权重.
用户i对第l个item的权重表达可以用如下的数据表示:

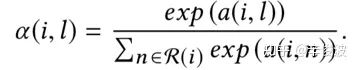
其中ui是用户本身的latent vector, vl是物品l的latent vector,pl是物品l的辅助latent vector; xl是表示前面提到的从图文信息提取的特征latent vector。用户最终的表达是自身ui的latent vector,以及历史行为的attention加权的representation表示。
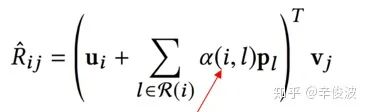
模型使用的是pairwise loss进行优化
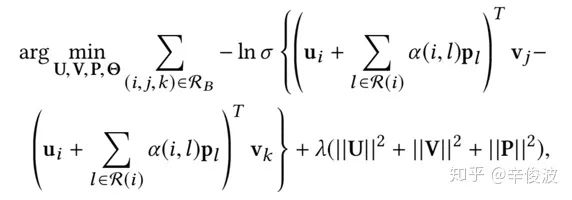
(3) representation function
使用user和item的向量点击作为匹配分数
3.2.4 CKB模型(Collaborative Knowledge Base Embedding)
CKB模型是在2016年KDD提出的,利用知识图谱做representation learning,模型框架如图3.10所示。整个CKB模型框架其实思想比较简单,分别在结构化信息、文本信息和视觉信息中提取item侧特征作为item的representation

(1) input layer
a) user侧:userid
b) item侧:itemid; 基于知识图谱的item特征(structural, textual, visual )
(2) representation function
主要是从知识图谱的角度,从结构化信息,文本信息以及图文信息分别提取item侧的表达,最终作为item的embedding
a) 结构化特征struct embedding: transR, transE

b) 文本特征Textual embedding: stacked denoising auto-encoders (S-DAE)
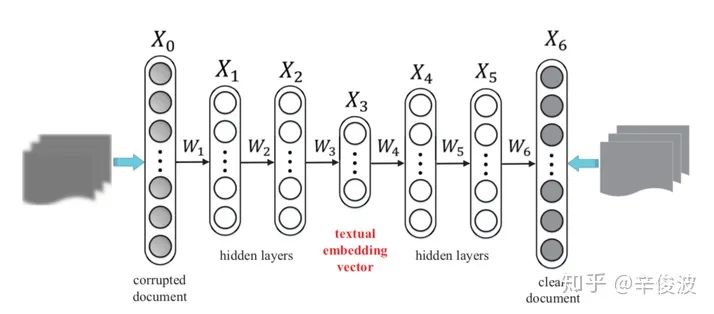
c) 视觉特征Visual embedding: stacked convolutional auto-encoders (SCAE)

(3) matching function
得到用户向量和item向量后,用向量点击表示user和item的匹配分数;损失函数则用如下的pair-wise loss表示
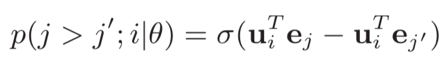
3.3 基于representation的深度匹配方法总结
总结上述基于CF的方法,可以用如下的范式作为表达

(1)representation learning: 目的是学习到user和item各自的representation(也叫latent vector, 或者embedding)
(2) 特征表达:user侧特征除了用户id本身userid,可以加上其他side info;item侧特征除了物品id本身itemid, 还有其他文本特征、图文特征、视频帧特征等信息
(3) 模型表达:除了传统的DNN,其他结构如Auto-Encoder(AE), Denoise-Auto-Encoder(DAE),CNN,RNN等。
基于representation learning的深度匹配模型不是一个end-2-end模型,通过user和item各自的representation作为中间产物,解释性较好,而且可以用在出了排序阶段以外的其他环节,例如求物品最相似的item集合,召回环节等。
4.基于match function learning 的深度匹配模型
对比representation learning的方法,基于match function learning最大的特点是,不直接学习user和item的embedding,而是通过已有的各种输入,通过一个neural network框架,来直接拟合user和item的匹配分数

简单来说,第一种方法representation learning不是一种end-2-end的方法,通过学习user和item的embedding作为中间产物,然后可以方便的计算两者的匹配分数;而第二种方法matching function learning是一种end2end的方法,直接拟合得到最终的匹配分数。本章主要介绍基于match function learning的深度学习匹配方法。
4.1 CF-based的深度模型
前面传统匹配模型以及基于表示学习的模型,其base模型都离不开协同过滤,也可以称为基于矩阵分解的模型。基于match function learning的模型也不例外。
4.1.1 基于NCF框架的方法
基于神经网络的学习方法(NCF)为何向南博士在2017年提出,对比传统的CF网络,在得到user vector和item vector后,连接了MLP网络后,最终拟合输出,得到一个end-2-end的model。这套框架好处就是足够灵活,user和item侧的双塔设计可以加入任意side info的特征,而MLP网络也可以灵活的设计,如图4.2所示。
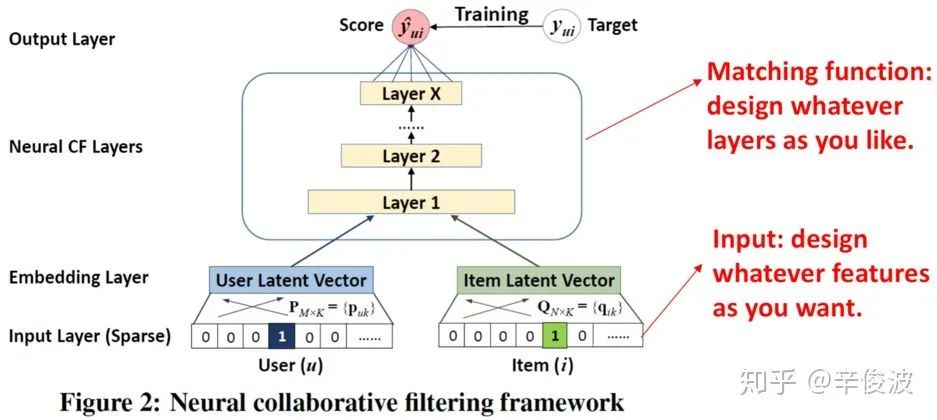
NCF框架对比第三章所说的CF方法最主要引入了MLP去拟合user和item的非线性关系,而不是直接通过inner product或者cosine去计算两者关系,提升了网络的拟合能力。然而MLP对于直接学习和捕获从mf提取的user和item vector能力其实并不强。在wsdm2018的一篇文章质疑的就是MLP对特征组合的拟合能力
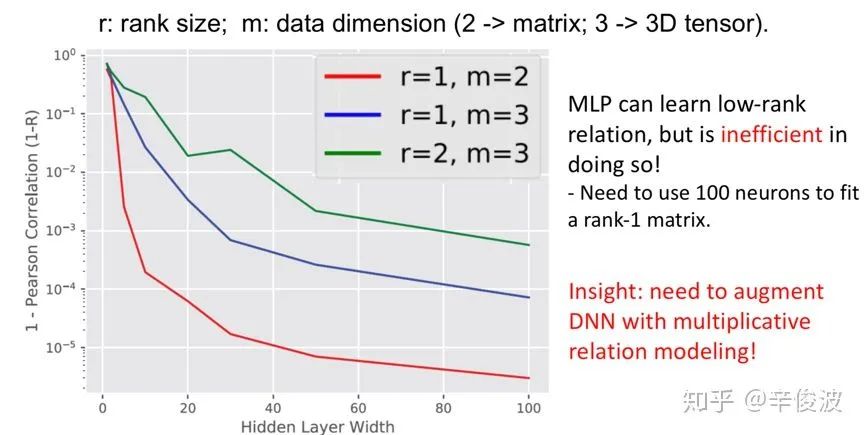
该paper做了一组实验,使用1层的MLP网络去拟合数据;实验证明对于二维一阶的数据,也需要100个节点才能拟合;如果超过2阶,整个MLP的表现将会非常差。文章因此说明了DNN对于高阶信息的捕捉能力并不强,只能捕捉低阶信息。
下文要讲的模型,也是在模型结构或者特征层面做的各种变化。
4.1.1.1 NeuMF模型(Neural Matrix Factorization)
Neural MF,顾名思义,同时利用了MF和神经网络MLP的能力来拟合matching score;MF利用向量内积学习user和item的关联,同时MLP部分捕捉两者的其他高阶信息。这篇paper其实和NCF框架是出自同一篇paper的。模型可以分为GMF和MLP两个部分来看,如图4.4所示。

(1) GMF(General Matrix Factorization)部分
user和item都通过one-hot编码得到稀疏的输入向量,然后通过一个embedding层映射为user vector和item vector。这样就获得了user和item的隐向量,一般可以通过向量点积或者哈达马积(element-wide product)得到交互,不过在NeuMF中多连接了一个连接层,也就是GMF layer
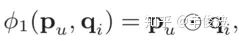

(2) MLP部分
输入和GMF部分一样,都是one-hot的稀疏编码,然后通过embedding层映射为user vector和item vector。注意到这里user和item的vector 和GMF部分是不一样的,原因是GMF和MLP两个网络结构对隐层维度要求不同,MLP部分会高一些(个人感觉share embedding能更充分训练embedding)
embedding层之后就是几层常规的MLP,这块没什么好说的,最后一层输出作为MLP的output。
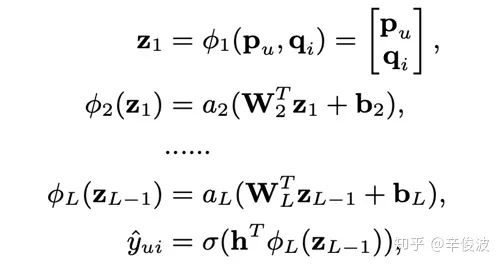
4.1.1.2 NNCF模型(Neighbor-based NCF)
CIKM2017提出的一种基于neighbor的NCF方法,最大的不同在于输入除了user和item的信息,还各自引入了user和item各自的neighbor信息。

图4.5所示的输入由两部分组成,中间xu和yi为原始的user和item的one-hot输入,通过embedding层后映射为pu和qi的embedding向量,然后通过哈达马积作为MLP的输入。而输入层两侧的nu和ni是user和item各自的neighbor信息的输入,这里nu和ni息如何提取可以采用多种手段,如二部图挖掘,user-CF或者item-CF等。
对于neighbor信息,由于每个用户和item的neighbor数不一致,输入是不定长的,通过卷积和pooling后提取得到定长的embedding,然后和user以及item本身的向量concat后输入到模型中
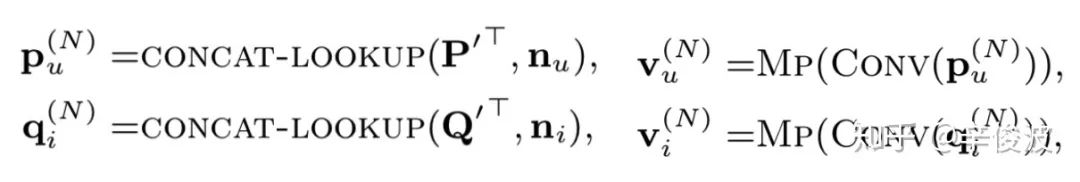
4.1.1.3 ONCF模型(Outer-Product based NCF)
何向南博士2018年在NCF模型框架上提出了outer-product based NCF,在原有的NCF框架上,引入了outer product的概念,如图4.6所示。

在embedding layer之后,O-NCF模型引入了interaction map也就是特征交叉层,对于用户u的向量pu和物品i的向量qi,引入两者的outer-product

E是一个k*k维的矩阵,其中的每个element两两相乘,得到2维的矩阵。到这,可以通过把二维矩阵展开变成一个k2维度的向量,作为MLP的输入。假设k=64,那么E就是个4096的向量,每一层隐层单元个数设置为上一层的一半,那么第一层的维度为4096*2048约需要840万的网络参数需要训练,参数量非常巨大。
因此,文章提出了一种利用CNN局部连接共享参数的方法来减少embedding layer到hidden layer之间的参数,如图4.7所示。
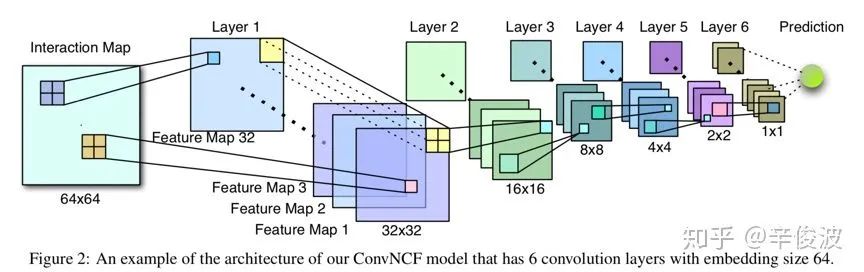
假设隐层维度K=64,有6层hidden layer,每一层有32个卷积核(feature map),步长stride=2,那么经过每个卷积核后的feature map大小为原来的1/4(长和宽各少了一半)。以第一层卷积为例。

那么第一层卷积后得到的网络是个323232的3维vector,其中最后一个32代表feature map个数。这里如何体现特征交叉的思想呢?ei,j,c代表的就是在前一层的feature map中,第i个单元和第j个element的二阶交叉。第一层feature map中,每个单元提取的是上一层22区域的local连接信息,第三层提取的就是第一层44的信息,那么在网络的最后一层就能提取到原始feature map里的global 连接信息,从而达到高阶特征提取的目的。
总结来说,使用原始的outer-product思想,在第一层网络处有近千万的参数需要学习,而使用CNN网络一方面能够减少参数量,另一方面又同时提取了低阶和高阶特征的组合。个人觉得引入CNN固然能节省内存,但也同时会带来训练和推理时间的增加,是一种时间换空间的思想。另外用CNN是否能够比原始MLP更有效拟合特征组合也需要结合数据分布去看。
4.1.1.4 小结
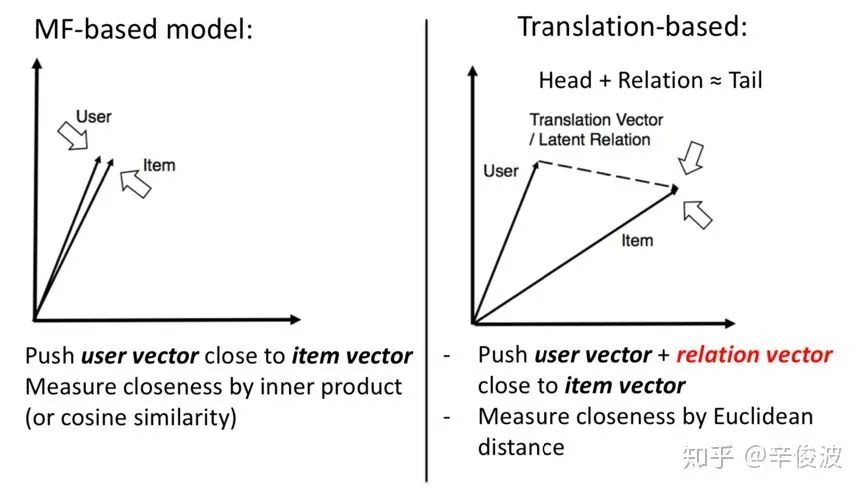
基于NCF框架的方法基础原理是基于协同过滤,而协同过滤本质上又是在做user和item的矩阵分解,所以,基于NCF框架的方法本质上也是基于MF的方法。矩阵分解本质是尽可能将user和item的vector,通过各种方法去让user和item在映射后的空间中的向量尽可能接近(用向量点击或者向量的cosine距离直接衡量是否接近)。
而另外一种思路,基于翻译的方法,也叫translation based model,认为user和item在新的空间中映射的vector可以有gap,这个gap用relation vector来表达,也就是让用户的向量加上relation vector的向量,尽可能和item vector接近。两种方法的区别可以用图4.8形象的表示。
4.1.2 基于translation框架的方法
4.1.2.1 transRec模型
2017年的recsys会议上提出的一种基于“translate”的推荐方法,要解决的是next item的推荐问题。基本思想是说用户本身的向量,加上用户上一个交互的item的向量,应该接近于用户下一个交互的item的向量,输入是(user, prev item, next item),预测下个item被推荐的概率

用户向量表达如下:
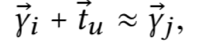
这里ri和rj表示的是用户上一个交互的item i和下一个交互的item j,tu为用户本身的向量表达。而在实际的推荐系统中,往往存在数据稀疏和用户冷启动问题,因此,作者将用户向量tu分解成了两个向量。
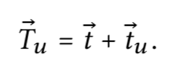
这里t可以认为是全局向量,表示的是所有用户的平均行为,tu表示用户u本身的bias,例如对于冷启动用户,tu可以设置为0,用全局用户的表达t作为冷启动。
对于热门item由于出现次数非常多,会导致最终热门item的向量和绝大多数用户向量加上item向量很接近,因此文章对热门item做了惩罚,最终,已知上一个item i,用户和下一个item j的匹配score表达为:
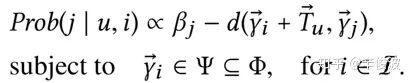
其中, 第一项beta_j表示的是物品j的全局热度;第二项d表示的是用户向量加上物品i的向量与物品j向量的距离;距离越小表示i和j距离越接近,被推荐的可能性就越大
4.1.2.2 LRML模型(Latent Relational Metric Learning)
前面讲到,基于translation框架的方法对比基于CF框架方法最大的不同,在于找到一个relation vector,使得user vector + relation vector尽可能接近item vector。WWW2018提出的LRML模型通过引入memory network来学习度量距离。可以分为三层layer,分别是embedding layer, memory layer和relation layer。
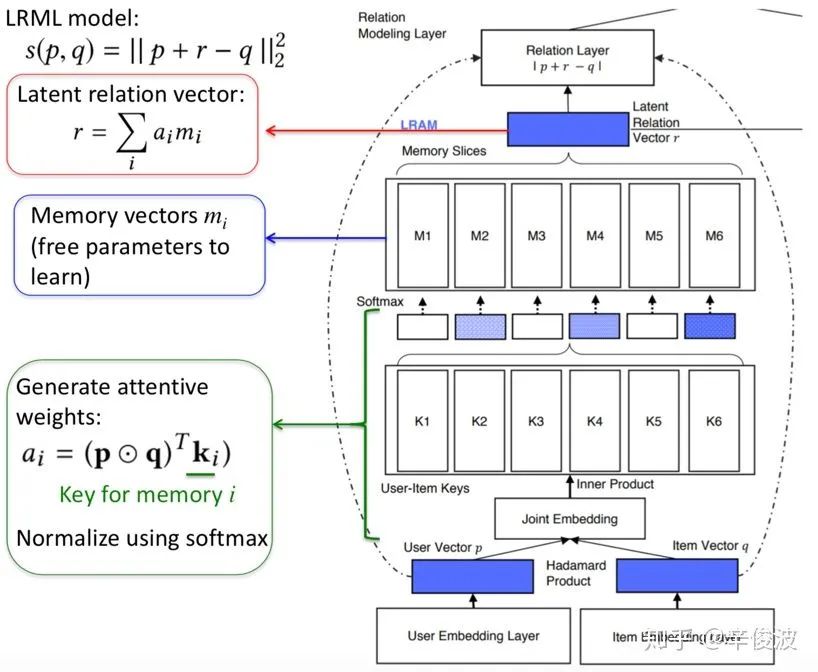
(1) embedding layer
底层是常规的双塔embedding,分别是用户embedding矩阵和物品的embedding矩阵,用户one-hot输入和item的one-hot输入通过embedding后得到用户向量p和物品向量q
(2) memory layer
记忆网络层是文章的核心模块,作者通过引入memory layer作为先验模块。这个模块可以分为三个步骤进行计算:
a)用户和物品embedding融合
embedding层得到的user和item向量p和q需要先经过交叉合成一个向量后输入到下一层,作者提到使用哈达码积效果优于MLP效果,也更简单

b)用户-物品key addressing
从第一步得到的向量s中,去和memory记忆网络模块中的各个memory vector挨个计算相似度,相似度可以用内积表达并做归一化


得到的ai代表的是当前用户-物品输入对(p, q)与memory-network中的第i个向量的相似度.
c)最终加权表达
最终得到的relation vector是第二步得到的memory记忆网络中不同vector的加权表达,如下所示
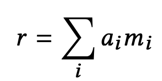
(3) relation layer
从memory layer得到的r向量可以认为是用户向量p与物品向量q的relation vector,最终的距离用平方损失衡量,如图4.11所示。
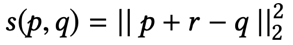
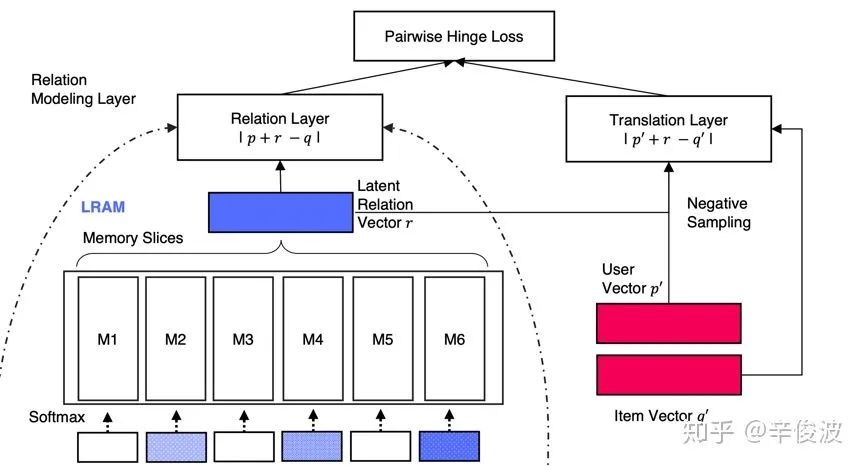
由于解决的是推荐物品的排序问题,文章使用的是pairwise loss,因此在网络的最后一层,对user和item分别进行负样本采样得到p’和q’,然后使用pairwise hinge loss进行优化
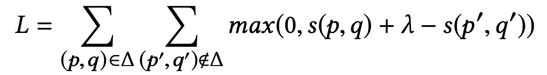
4.2 feature-based的深度模型
4.1介绍的基于CF的方法,对大多数推荐系统来说,输入的特征向量往往都是非常高维而且稀疏的,而特征之间的交叉关系对模型来说往往都是非常重要的。例如,用户一般会在一天快吃三餐的时候,打开和订餐相关的app,这样,用户使用订餐app和时间存在着二阶交叉关系;又比如说,男性的青年群体,往往更喜欢射击类的游戏,性别、年龄以及类目之间存在着三阶的交叉关系。因此,如何捕捉特征之间的交叉关系,衍生了众多基于特征的模型,在这里将这些捕捉特征交叉关系的模型称为feature-based model。
4.2.1 wide&deep 模型
提到深度学习模型,最经典的莫过于2016年google提出的wide and deep模型。说是模型,不如说是通用的一套范式框架,在整个工业界一举奠定了风靡至今的模型框架,如图4.12所示。
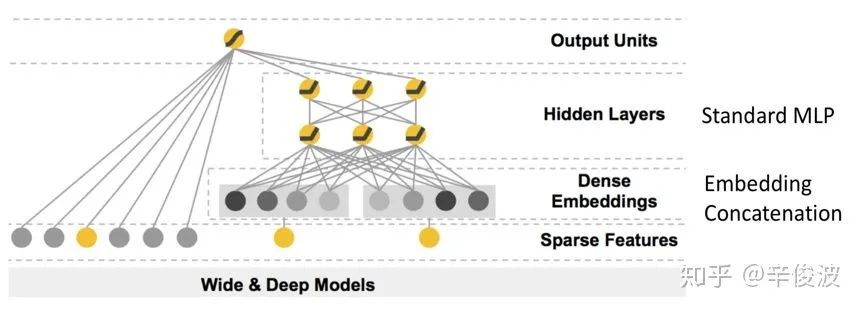
在这个经典的wide&deep模型中,google提出了两个概念,generalization(泛化性)和memory(记忆性)。
(1) 记忆性:wide部分长处在于学习样本中的高频部分,优点是模型的记忆性好,对于样本中出现过的高频低阶特征能够用少量参数学习;缺点是模型的泛化能力差,例如对于没有见过的ID类特征,模型学习能力较差。
(2) 泛化性:deep部分长处在于学习样本中的长尾部分,优点是泛化能力强,对于少量出现过的样本甚至没有出现过的样本都能做出预测(非零的embedding向量),容易带来惊喜。缺点是模型对于低阶特征的学习需要用较多参数才能等同wide部分效果,而且泛化能力强某种程度上也可能导致过拟合出现bad case。尤其对于冷启动的一些item,也有可能用用户带来惊吓。
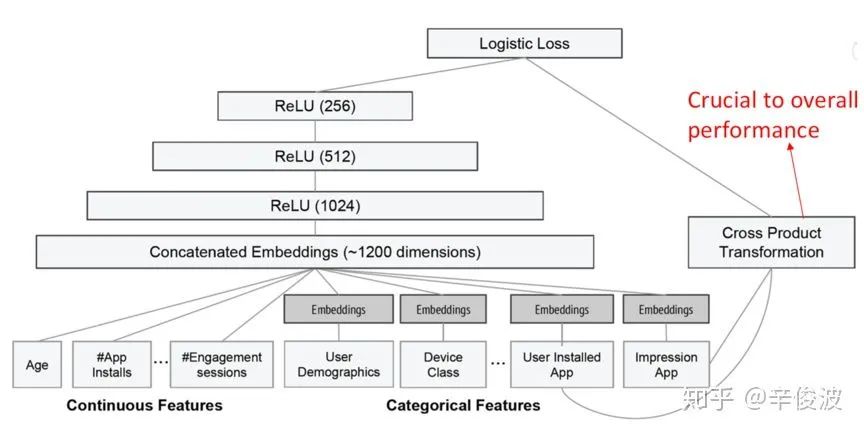
值得注意的是,虽然模型的deep部分拟合和泛化能力很强,但绝对不意味着把特征交叉都交给MLP就够了。实际证明,对于重要的一些人工经验的特征,对于提升整体效果还是非常重要的,如图4.13所示。这个人工特征的所谓缺点,也是后续各种模型结构想对其进行“自动化”的优化点。
4.2.2 deep crossing模型
微软在2016年提出了一套框架deep crossing,这篇文章在输入到embedding这里到是和wide&deep 没有太多不同,主要区别在于MLP部分。
google的wide&deep模型里深度网络的MLP部分是全连接网络,每一层的网络输入都是前一层的输入出,受限于模型结构,越往后越难学习到原始输入的表达,一般深度不会太深,超过5层的网络在工业界已经算很少见了。为了解决这个问题,deep crossing网络引入了resnet残差网络的概念,通过short-cut,在MLP的深层网络,也能接收来自第一层的输入,这样可以使得模型的深度达到10层之多,如图4.14所示。

上述提到的wide&deep以及deep crossing框架更像是在模型结构做的改进,一个引入了wide&deep,一个引入了resnet,特征层面并没有做太多改造,如何体现feature-base呢?sigIR2017就有一篇文章做了个实验,对wide&deep以及Deep&Cross实验按照embedding是否做初始化分别做了实验。实验发现,如果embedding是随机初始化的,两个深度模型连基础的FM模型都打不过;哪怕经过FM初始化了embedding,wide&deep模型效果也仅仅略好于FM模型,而deep crossing模型依然比不过FM模型,实验结果如图4.15所示

这个结论也引出了关于MLP的一些思考,全连接网络表面上看对所有节点都进行了连接,理论上应该学习到了各个节点的交叉特征,但是从结果上来看,MLP对这些特征交叉的学习能力确实非常差的。纠其原因,还是在模型结构的设计上。
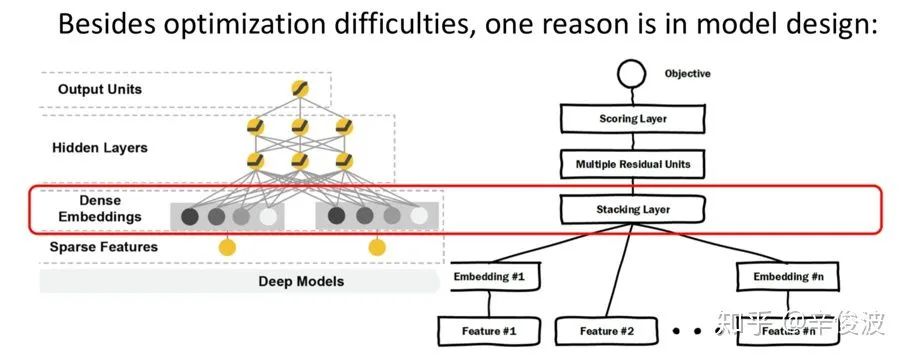
图4.16里无论是wide&deep还是deep crossing network,embedding层之后到MLP之间,都是将embedding做concat的。这些concat后的信息其实能够表达的特征交叉信息其实是非常有限的,仅靠MLP想完全捕捉到特征的有效交叉其实是非常困难的。因此,有大量工作关于在embedding这里如何捕捉特征交叉,其实就是在MLP网络之前,利用更多的数学先验范式做特征交叉去提取特征,这也是本节提到的方法叫做feature-based的原因。
4.2.3 PNN模型
embedding layer进入MLP之前,引入了product layer 来显式的学习每个field的embedding向量之间的两两交叉,如图4.17所示。
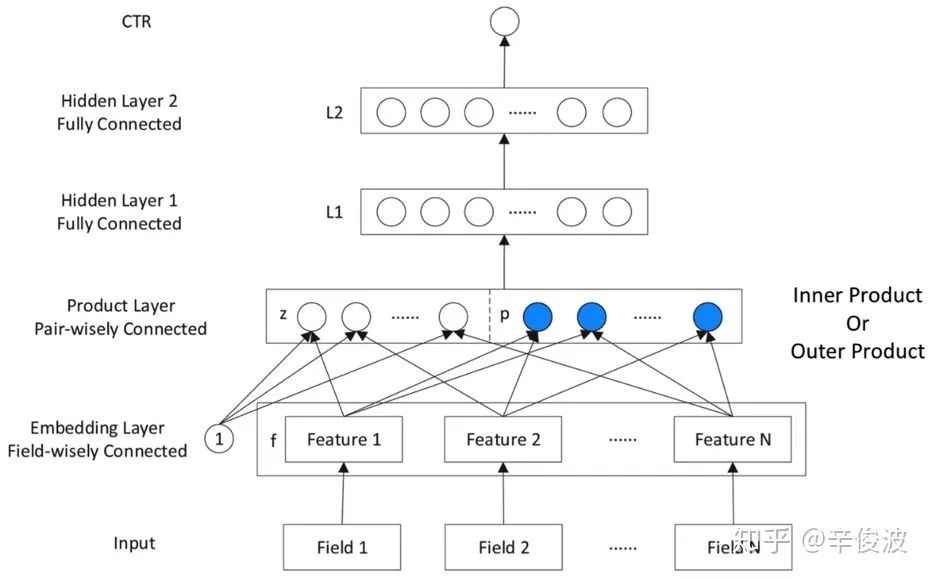
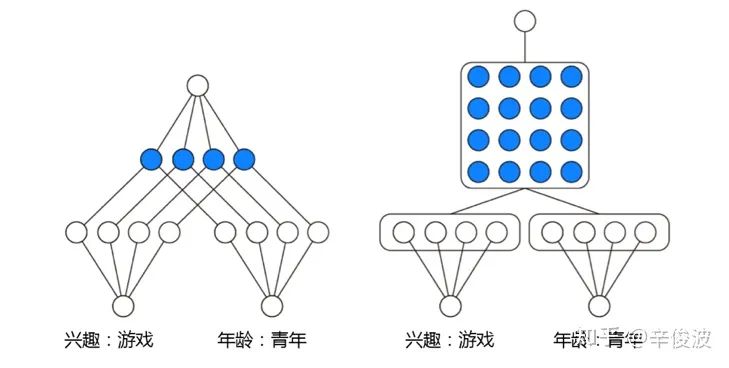
左边z为embedding层的线性部分,右边为embedding层的特征交叉部分。这种product思想来源于,推荐系统中的特征之间的交叉关系更多是一种and“且”的关系,而非add"加”的关系。例如,性别为男且喜欢游戏的人群,比起性别男和喜欢游戏的人群,前者的组合比后者更能体现特征交叉的意义。根据product的方式不同,可以分为inner product(IPNN)和outer product(OPNN),如图4.18所示。
其中,IPNN模型每个特征是个inner product, f个field两两交叉,得到的新的特征组合有f*(f-1)/2个;outer product是两个向量的乘积,得到的新的特征组合有 个。
4.2.4 deepFM模型
google的wide&deep框架固然强大,但由于wide部分是个LR模型,仍然需要人工特征工程。华为诺亚方舟团队结合FM相比LR的特征交叉的功能,在2017年提出了deepFM,将wide&deep部分的LR部分替换成FM来避免人工特征工程,如图4.19所示。
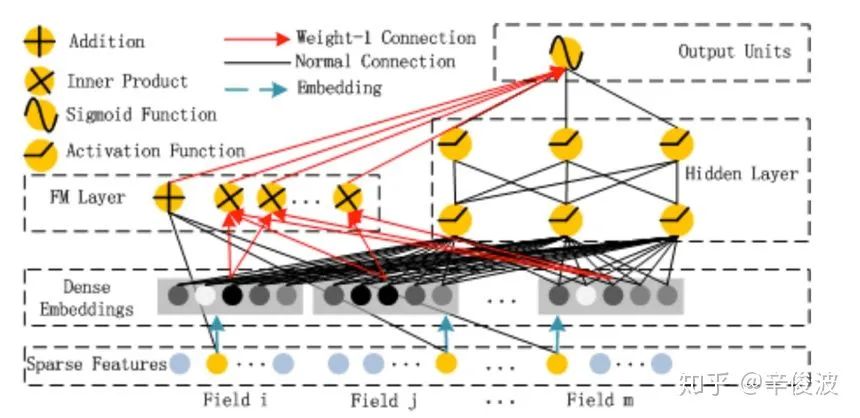
比起wide&deep的LR部分,deeFM采用FM作为wide部分的输出,FM部分如图4.20所示。
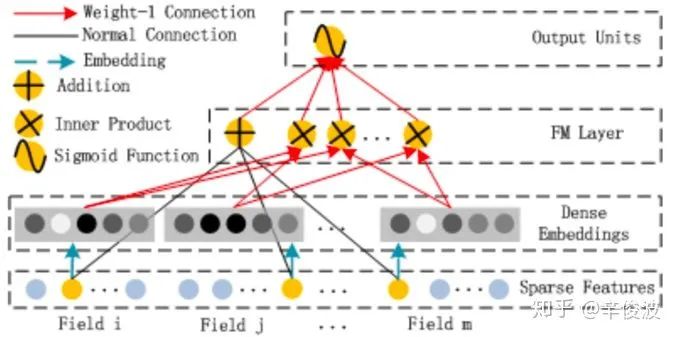
除此之外,deepFM还有如下特点:
(1) 更强的低阶特征表达
wide部分取代WDL的LR,与4.2.1和4.2.2提到的wide&deep模型以及deep crossing模型相比更能捕捉低阶特征信息
(2)embedding层共享
wide&deep部分的embedding层得需要针对deep部分单独设计;而在deepFM中,FM和DEEP部分共享embedding层,FM训练得到的参数既作为wide部分的输出,也作为DNN部分的输入。
(3)end-end训练
embedding和网络权重联合训练,无需预训练和单独训练
4.2.5 NFM模型(Neural Factorization Machines)
deepFM在embedding层后把FM部分直接concat起来(f*k维,f个field,每个filed是k维向量)作为DNN的输入。Neural Factorization Machines,简称NFM,提出了一种更加简单粗暴的方法,在embedding层后,做了一个叫做Bi-interaction的操作,让各个field做element-wise后sum起来去做特征交叉,MLP的输入规模直接压缩到k维,和特征的原始维度n和特征field维度f没有任何关系,如图4.21所示。

这里论文只画出了其中的deep部分, wide部分在这里省略没有画出来。Bi-interaction所做的操作很简单:让f个field两两element-wise相乘后,得到f*(f-1)/2个维度为k的向量,然后直接sum起来,最后得到一个k维的向量。所以该层没有任何参数需要学习,同时也降低了网络复杂度,能够加速网络的训练;但同时这种方法也可能带来较大的信息损失。
4.2.6 AFM模型(Attention Factorization Machines)
前面提到的各种网络结构中的FM在做特征交叉时,让不同特征的向量直接做交叉,基于的假设是各个特征交叉对结果的贡献度是一样的。这种假设往往不太合理,原因是不同特征对最终结果的贡献程度一般是不一样的。Attention Neural Factorization Machines,简称AFM模型,利用了近年来在图像、NLP、语音等领域大获成功的attention机制,在前面讲到的NFM基础上,引入了attention机制来解决这个问题,如图4.22所示。

AFM的embedding层后和NFM一样,先让f个field的特征做了element-wise product后,得到f*(f-1)/2个交叉向量。和NFM直接把这些交叉项sum起来不同,AFM引入了一个Attention Net,认为这些交叉特征项每个对结果的贡献是不同的,例如xi和xj的权重重要度,用aij来表示。从这个角度来看,其实AFM其实就是个加权累加的过程。Attention Net部分的权重aij不是直接学习,而是通过如下公式表示

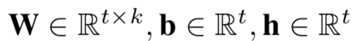
这里t表示attention net中的隐层维度,k和前面一样,为embedding层的维度。所以这里需要学习的参数有3个,W, b, h,参数个数共tk+2t个。得到aij权重后,对各个特征两两点积加权累加后,得到一个k维的向量,引入一个简单的参数向量pT,维度为k进行学习,和wide部分一起得到最终的AFM输出。

关于AFM还有个好处,通过attention-base pooling计算的score值aij体现的是特征vi和vj之间的权重,能够选择有用的二阶特征,如图4.23所示。
4.2.7 DCN模型(Deep Cross Network)
前面提到的几种FM-based的方法都是做的二阶特征交叉,如PNN用product方式做二阶交叉,NFM和AFM也都采用了Bi-interaction的方式学习特征的二阶交叉。对于更高阶的特征交叉,只有让deep去学习了。为解决这个问题,google在2017年提出了Deep&Cross Network,简称DCN的模型,可以任意组合特征,而且不增加网络参数。图4.24为DCN的结构。

整个网络分4部分组成:
(1)Embedding and stacking layer
之所以不把embedding和stacking分开来看,是因为很多时候,embedding和stacking过程是分不开的。前面讲到的各种 XX-based FM 网络结构,利用FM学到的v向量可以很好的作为embedding。而在很多实际的业务结构,可能已经有了提取到的embedding特征信息,例如图像的特征embedding,text的特征embedding,item的embedding等,还有其他连续值信息,例如年龄,收入水平等,这些embedding向量stack在一起后,一起作为后续网络结构的输入。当然,这部分也可以用前面讲到的FM来做embedding。为了和原始论文保持一致,这里我们假设X0向量维度为d(上文的网络结构中为k),这一层的做法就是简答的把各种embedding向量concat起来。

2)deep layer network
在embedding and stacking layer之后,网络分成了两路,一路是传统的DNN结构。表示如下
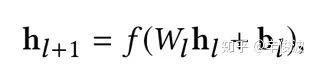
为简化理解,假设每一层网络的参数有m个,一共有Ld层,输入层由于和上一层连接,有dm个参数(d为X0向量维度),后续的Ld-1层,每层需要m(m+1)个参数,所以一共需要学习的参数有 dm+m(m+1)*(Ld-1)。最后的输出也是个m维向量
3)cross layer network
embedding and stacking layer输入后的另一路就是DCN的重点工作了。每一层l+1和前一层l的关系可以用如下关系表示

可以看到f是待拟合的函数,xl即为上一层的网络输入。需要学习的参数为wl和bl,因为xl维度为d,当前层网络输入xl+1也为d维,待学习的参数wl和bl也都是d维向量。因此,每一层都有2*d的参数(w和b)需要学习,网络结构如下。

经过Lc层的cross layer network后,在该layer最后一层Lc层的输出为Lc2的d维向量
(4)combination output layer
经过cross network的输出XL1(d维)和deep network之后的向量输入(m维)直接做concat,变为一个d+m的向量,最后套一个LR模型,需要学习参数为1+d+m。
总结起来,DCN引入的cross network理论上可以表达任意高阶组合,同时每一层保留低阶组合,参数的向量化也控制了模型的复杂度。cross网络部分的交叉学习的是特征向量中每一个element的交叉,本质上是bit-wise的。
4.2.8 xdeepFM模型(extreme Deep Factor Machine)
xDeepFM模型从名字上听好像是deepFM模型的升级,但其实更应该拿来和DCN模型做对比。DCN模型引入了高阶特征交叉,但是特征的交叉本质上是在bit-wise的。而xDeepFM模型认为特征向量i和特征向量j的交叉过程中,i本身的元素交叉没有意义,提取i和j的向量交叉才是更有效捕捉特征的方式,也就是vector-wise的交叉,整个模型的框架如图4.26所示,最核心的模块在于特征交叉的CIN模块。
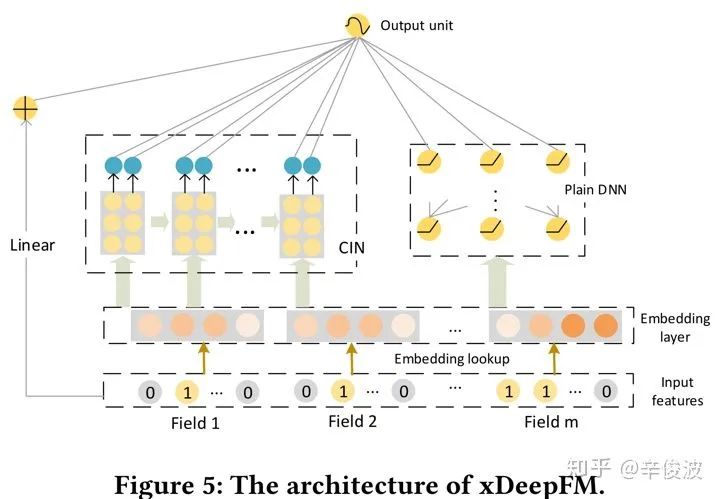
首先我们来看下整个CIN的整体框架图,如图4.27所示,假设特征field个数是m,每个field的隐层维度为d,那么原始embedding层的大小为m*d,而cross network有Hk层,提取的是特征的交叉。每一层网络在做什么事情呢?就是和第一层x0做特征交叉得到新的特征向量后,然后这Hk层cross net得到的特征向量concat到一起,作为MLP的输入。那么,这里面,每一层的特征xk到底是如何输入层x0发生交互的?

以cross net的第k层和原始输入x0为例,我们看下如何提取得到新的特征,图4.28是其特征交叉的过程。其中xk的维度为HkD,表示的是第k层有Hk个vector,而原始输入x0的维度为mD,表示输入层有m个D维的vector。

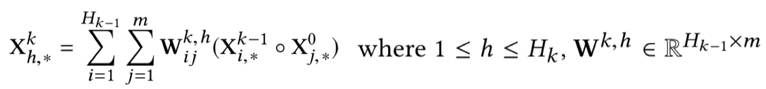
这里Wk,h表示的是第k层的第h个vector的权重,是模型需要学习的参数。整个公式的理解是整个xdeepFM理解的关键,我们具体看下发生了什么
(1) 首先,从前一层的输入Xk-1(一共有Hk-1个vector),取出任意一个vector;从原始输入x0(一共有m个vector),取出任意一个vector,两者两两做哈达码积,可以得到Hk-1*m个vector
(2) 这Hk-1*m个交叉得到的vector,每个vector维度都是D,我们通过一个W矩阵做乘积进行加权求和,相当于是个带权重的pooling, 最终得到加权求和后的vector Xh,k,表示的是第h层第k个vector。这里的W矩阵就是模型要学习的
(3) 为什么说是压缩,压缩体现在哪里?还是用图说话,这里我们看下原始论文给出的图示,有助于整个过程的理解。
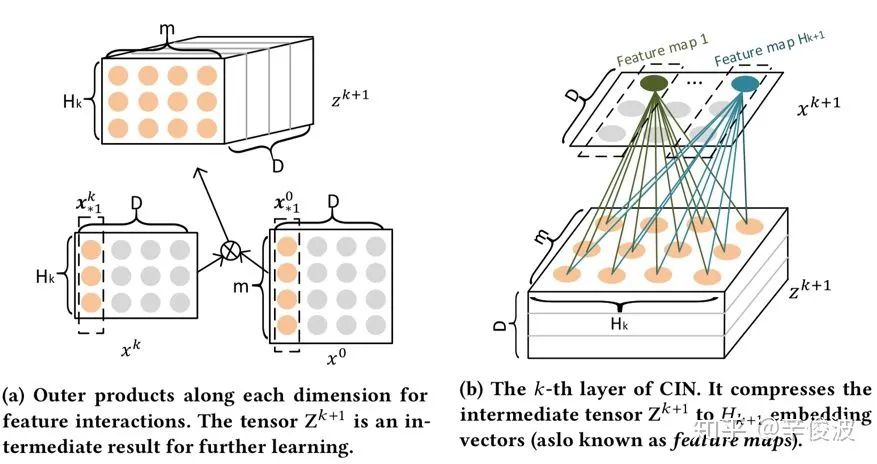
在图4.29左图中,我们把D看成是原始二维平面的宽度,我们沿着D的方向挨个进行计算。先看xk向量中D的第一维,有Hk个数;x0向量中D的第一维,有m个数,让Hk和m两两计算,就可以得到Hkm的一个平面。一直沿着D方向,2,3,4,…D,我们就可以得到一个Hkm*D的三维矩阵,暂且叫做zk+1,注意这个过程只是简单的矩阵计算,没有参数需要学习。
在4.29右边的图中,我们开始提取前面zk+1的信息,还是以D方向的第一维为例,一个mHk的平面,乘以一个大小一样的mHk矩阵W,然后加权求和,就可以得到这个平面最后压缩的一个实数。整个平面被“压缩“成为了一个一维的数。一直沿着D方向求解每个平面压缩后的数,就可以得到一个D维的向量。
这就是整个“压缩”的取名原因。整个过程非常类似CNN的filter卷积思想,W就是卷积核,得到的每个特征映射的值就是feature map。
4.2.9 FGCNN模型(Feature Generate by CNN)
CNN模型在图像,语音,NLP领域都是非常重要的特征提取器,原因是对图像、视频、语言来说,存在着很强的local connection信息。而在推荐系统中由于特征输入都是稀疏无序的,很难直接利用CNN作为特征提取。华为诺亚方舟在2019年的WWW会议上提出了一种巧妙的利用CNN提取特征的方法FGCNN,整个模型框架如图4.30所示。
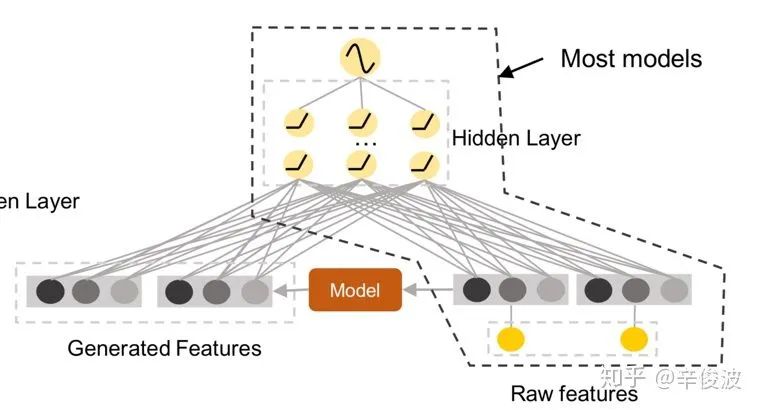
其中利用CNN提取新特征是整个paper的核心模块,具体框架如图4.31所示,可以分为4个层,卷积层、池化层、重组层以及特征输出层。下面分别介绍这4个不同的层,分别看下各自的输入,输出以及具体的网络结构。

(1) 卷积层Convolution Layer
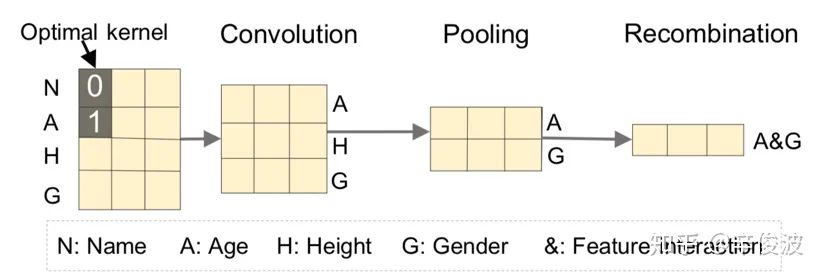
原始one-hot特征经过embedding后,进入的是卷积层。卷积的思想和TextCNN类似,通过一个高度为hp,宽度为d的卷积核进行卷积;其中高度hp代表的是每次卷积连接的邻域的个数,以图4.32为例,hp=2,表示二维特征的交叉,从上到下卷积,表示的是N&A, A&H, H&G卷积,分别表示名字和年龄、年龄和身高、身高和性别的交叉;而宽度方向d需要和embedding的维度d保持一致,这和TextCNN的思想是一致的,只在高度方向上进行卷积。
1)Convolutional layer 输入
特征one-hot之后经过embedding层后的输出作为卷积层的输入,输入维度为nf*k。nf为field个数,k为隐层维度
2)Convolutional layer 输出
经过二维平面大小不变,增加第三维卷积核大小,第一层卷积层的输出大小为nfkmc1,mc1为第1个卷积层的卷积个数,以l=1为例,C:,:,i表示的是第一层卷积层第i个feature-map,每个feature map的大小为nf*k,Cp,q,i表示的是第一层第i个feature map的坐标为(p, q)的元素

(2) 池化层Pooling Layer
特征经过第一层卷积层之后,从nfk变成了nfk*mc1,维度反而扩了mc1倍,这和预期的特征降维不一致,解决办法和CNN里常用的套路一样,通过pooling做降维。该paper使用的是max pooling,在原先卷积高度hp上选择最大值作为卷积后的特征表达,表达如下所示
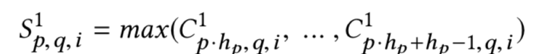
-
pooling层输入
卷积层的输出作为池化层的输出,以第一层为例,pooling层的输入维度为nfkmc1
-
pooling层输出
卷积层输出的时候在高度方向上选择max,只有高度方向维度发生变化,卷积输出后维度为nf/hp * k *mc1,hp为卷积核高度,相当于沿着field的方向压缩了hp倍
(3) 重组层Recombination Layer
经过特征卷积层和特征池化层后,可以通过特征重组Recombination layer生成新的特征组了。还是以第一层的Recombination layer为例,mc1为原始feature map的个数,mr1为新生成的特征feature map的个数,

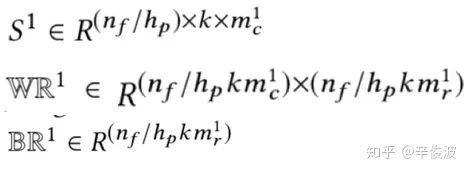
其中s1为池化层的输出,而WR1和BR1为该层待学习的参数
1)Recombination层输入
卷积层的输出S1为该层的输入,通过WR1的矩阵进行特征的recombination
2)Recombination层输出
新生成的特征维度为nf/hpkmr1
(4) 特征输出层Concatenation Layer
第一层Convolution layer->pooling layer->recombination layer后,生成第一层的新特征R1,连同第2,3,4,…,nc层的新特征R2,R3,R4,…,Rnc层一起concat起来,组成新的特征R=(R1,R2,…,Rnc)。之后R可以和原始特征一样做各种可能的交叉,例如和原始特征做二阶交叉等,再一起输入到模型层

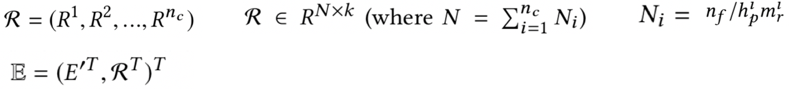
1)concatenation层输入
重组层Recombination layer输出的新特征R1, R2, R3, Rnc,作为concatenation layer的输入
2)concatenation层输出
原有的特征E和新特征R连在一起作为concatenation的特征输出,作为NN层的输入
4.2.10 FiBiNet模型(Feature Importance & Bilinear feature Interaction)
新浪微博张俊林团队2019年提出的结合特征重要性(Fi)和双线性特征交叉(Bi)的方法,Feature Importance & Bilinear feature Interaction,简称FiBiNet,其实是两个相对独立的模块,两个模块可以独立套用在其他的网络结构上,整体框架如图4.34所示
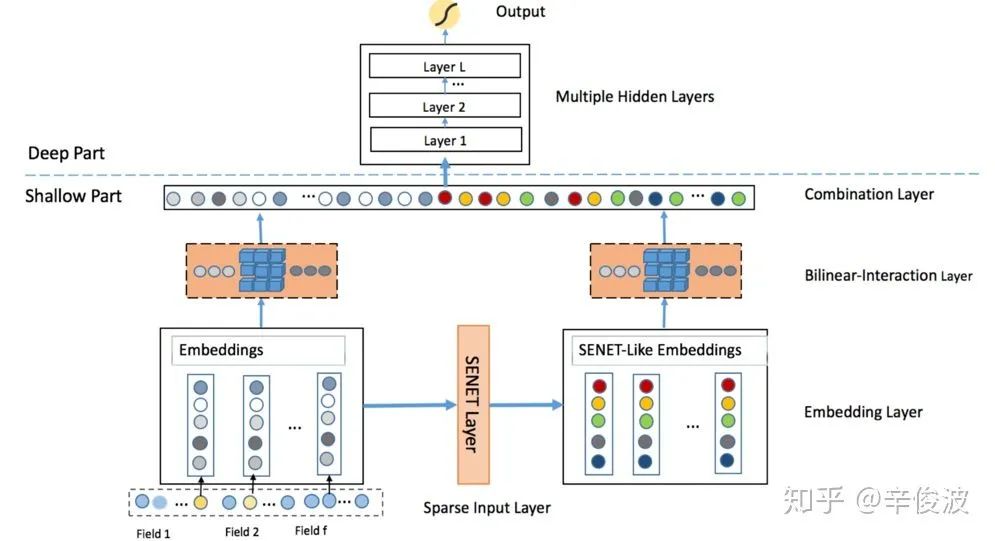
(1) SENet:特征重要性提取层
该层作用主要是提取特征重要性。可以分为三层Squeeze, Extract, Reweight,从原始的特征e1,e2,e3,…,ef 提取到新的特征v1,v2,v3,…, vf,其中f为特征field的个数,整体框架如下
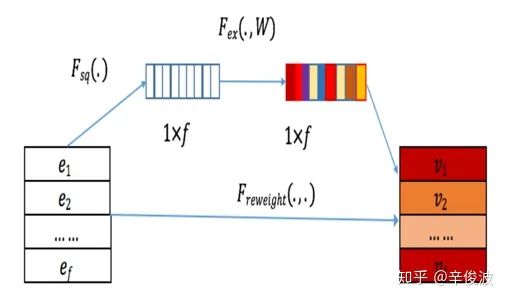
1)Squeeze层
特征压缩层,对每个特征组中的embedding向量进行汇总统计量的pooling操作,每个field的维度为k,从中squeeze压缩提取最重要的1维。典型的方法一般有Max pooling或者average pooling,在更原始的SENet里用的是max pooling,但是在该paper里作者提到average pooling表现更好,个人其实也倾向于认为average pooling直觉上更加make sense,只用max pooling从d维特征提取一维信息损失实在太大。当然具体表现也需要结合具体数据实验才知道
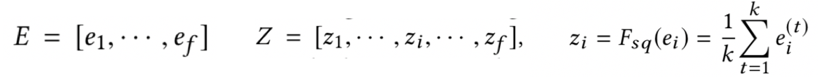
经过S层,第i维特征从ei变成了zi,从维度为d的向量变成了一个维度为1的实数。整个输入从f*d的矩阵变为f维的向量
2)Excitation层
特征激活层,向量先做压缩r(r为压缩的倍数),然后扩展恢复,类似auto-encoder思路
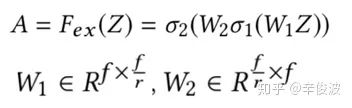
W1和W2为两个转换矩阵,先经过压缩然后恢复,最终得到的A还是一个维度为f的向量
3)Reweight层
经过前面Squeeze和Excitation得到的A相当于是原始特征E的权重向量,乘以原始的特征E后,可以得到最终加权提取的V向量,可以认为是原始特征的重要性表达
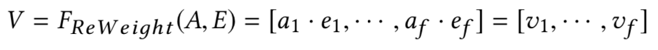
总结来说:SENet,用两层全连接阶层提取每个field的特征重要性
S层:压缩提取field中最重要的特征(max或者average特征)
E层:对s层提取的特征信息进行auto-encoder式的信息提取
R层:SE提取到的每个field特征重要性,进行加权提取
(2) Bilinear特征交叉层
从SENet提取到的新特征V,还有原始特征E,可以组合成为新的特征一起输入到模型的MLP网络中。但是如前面提到的MLP对特征交叉很弱的学习能力一样,本文一样提出了一些做特征交叉的方法。我们回顾下在前面提到的两个向量的交叉,无非是向量内积,得到一个实数;或者是向量的哈达马积分如图4.36的a所示,得到的还是一个向量,如图中4.36的b方法所示。这两种方法都是直接计算的,没有新的参数学习。在该paper中,作者提出了另一种引入参数的方法,也就是Bilinear双线性特征交叉的方法,如图中4.36的c方法所示
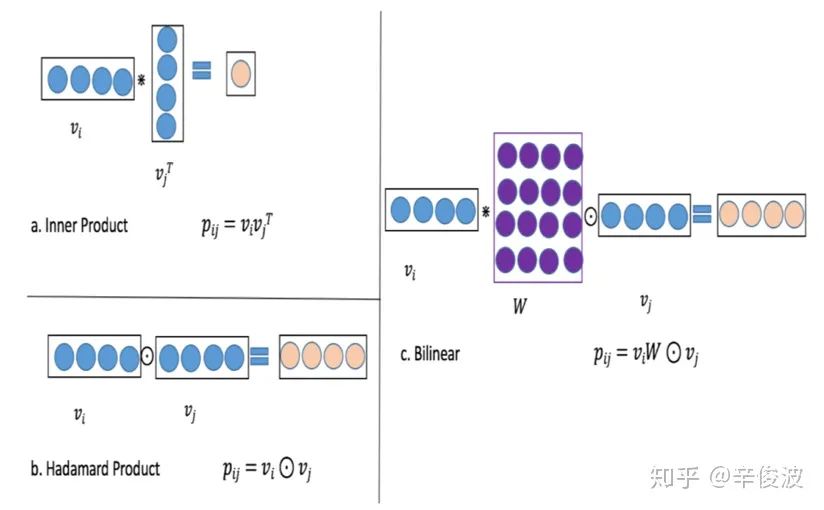
假设特征field的个数是f个,每个field的隐层维度为d。那么,如何确定需要学习的参数W呢?根据W的共享情况,可以分为以下三种类型
1) field type
W在所有特征之间是完全共享的,也就是说在任意两个需要交叉的特征i和特征j之间(vi, vj)共享一个W,W的参数维度为k*k
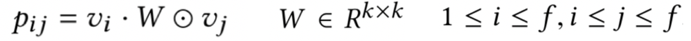
2) field each
对于每个特征i来说,都需要学习唯一的一个Wi矩阵,该Wi只和左乘的特征vi有关,和右乘特征vj无关,一共有f个field,所以W的参数维度为fkk
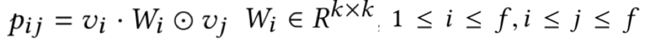
3) field-interaction type
对于任意两个需要交叉的特征vi和vj,都需要学习一个唯一的矩阵Wij,Wij不仅和左乘的特征有关,也和右乘的特征有关,也就是说,vi和vj的交叉,以及vj和vi的特征交叉,两者用到的wij和wji是不一样的,所以W的参数维度为ffk*k
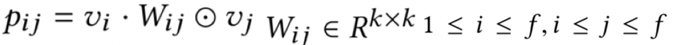
当然,以上三种不同的特征类型没有绝对的谁好谁坏,不存在越复杂效果越好的情况,对于简单的数据集,可能w共享是最好的,具体还是需要实验才能知道。在文章里用了criteio和avazu数据集进行实验时,使用不同的模型,三种交叉方法也是各有千秋。
总结本文的两个核心工作,第一个工作,SENet,目的是从一个fd的特征向量中,提取得到表达了特征重要性的同样维度为fd的新特征向量,该网络结构可以和其他模型结构套用。第二个工作bi-net, 从输入的embedding特征中提出了几种不同的特征交叉的方法,也可以给其他网络模型做特征交叉提供一些不同的手段。
4.2.11 AutoInt模型(Auto Feature Interaction)
目前为止讲到的模型中,使用到attention的是AFM模型,而在AutoInt文章中,作者除了attention机制,还使用了在transform中很火的multi-head和self-attention的概念,整体框架如图4.37所示
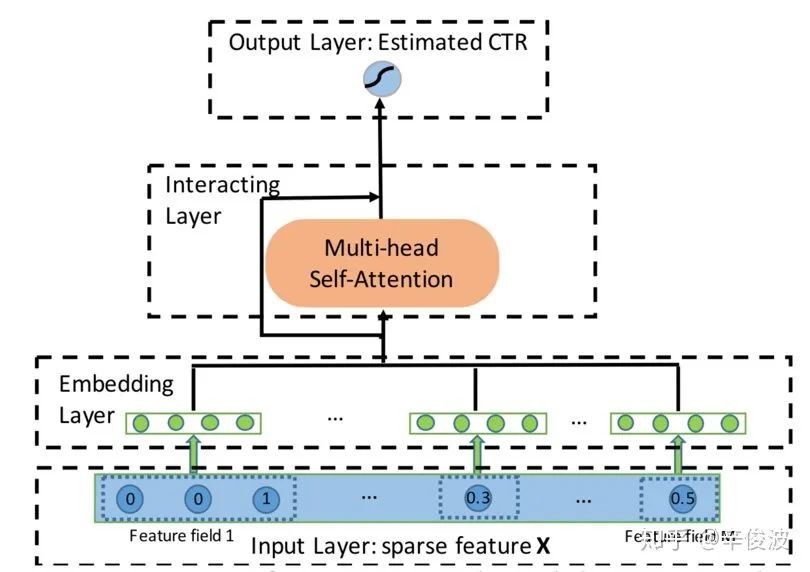
文章中的输入没有什么特别需要讲的,就是常规的one-hot稀疏的特征经过embedding层得到dense value。这里embedding层倒是值得一提,一般在大多数推荐系统里,对于one-hot做embedding是因为需要转成dense的特征,而原本就是dense的特征原本就是定长dense特征,比较少见到做embedding的,而在该文章中将连续值特征和one-hot一样去做embedding处理。不过这一块不影响auto-int部分的理解。

该paper里提到的attention机制,才是文章里的核心亮点,在介绍文章的核心机制之前,先在这里简单介绍下NLP里的attention里涉及到的3个重要的概念,query, keys, value。想象一下,你在搜索引擎输入了一个搜索词,这个搜索词就是query,假设你搜了“应用宝”,然后存在一堆候选结果就叫做keys,例如“下载app的地方”,“手机应用市场”,“app store“,“手机系统”等等,对这里的每个key,都去计算和候选词query的相似度,例如“手机应用市场“对“应用宝”的权重,显然是要高于“手机系统”,最终的表达,其实就是每个keys的value的加权求和,也就是说,谁和query的相似度高,在结果中value的权重占比就更高。经典的QKV结果表达如下:
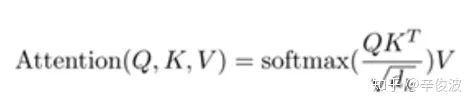
回到本文的attention机制中,假设特征field个数为M,对于第m个field,在第h个head空间下的特征表达如下
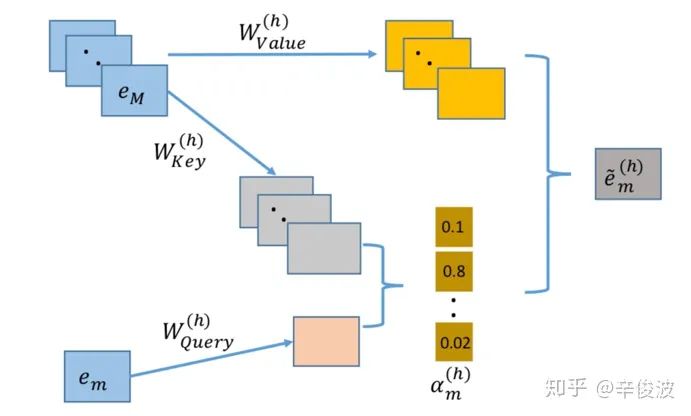
(1) 特征m在空间h下的新映射
每个特征m,在空间h下都有3组向量表示,分表代表特征m在空间h下的query向量Equery、key向量Ekey、value向量Evalue
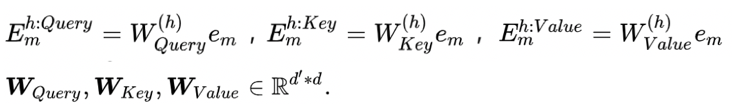
这里需要学习的参数为WQuery,Wkey,Wvalue,每个矩阵的维度为d’*d,从而将特征从d维映射为d’。W在所有特征中都是共享的,并不是每组特征都需要学习3个W
(2) 特征k对特征m相似度表达,使用向量的点积
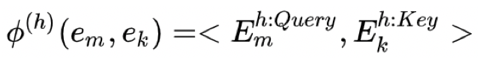
(3) 特征k对特征m的归一化注意力(M个特征做归一化)

(4) 特征m在空间h下的加权新特征
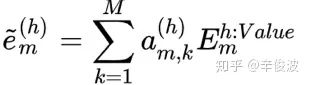
(5) 特征m的全空间表达

有H个head,特征m最终的表达为H个新特征的concat,特征长度为H*d’
(6) 特征m最终表达: resnet保留原始信息
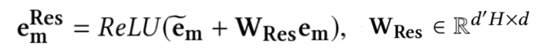
作者为了保留更多信息,除了第5步得到的multi-head的新特征,也将原始的特征em引入到进来,其实就是一种resnet思路,所以在这里需要有个额外的参数WRes需要学习,需要将原始的特征维度d映射为和em一致的H*d’,所以WRes的参数维度为d’Hd
4.2.12 DIN模型(Deep Interest Network)
4.2.11提到的AutoInt里特征的attention机制有个特点,就是在计算特征的重要性的时候,所有特征都有机会成为query, 将其他特征作为keys去计算和当前query的重要性从而得到权重的。而提到推荐系统里的attention机制,不得不提的就是阿里的这篇deep interest network了,简称DIN。工业界的做法不像学术界,很多模型网络结构优化并不一味的追求模型的复杂和网络结构有多fancy,每一步背后都有大量的业务思考后沉淀下来的。
阿里这篇din也如此。在了解din之前,我们先看下din前身的模型,GwEN模型(Group-wise Embedding Network,阿里内部称呼)

前面讲到的很多模型,输入层都是大规模稀疏特征,经过embedding层后输入到MLP网络中。这里的一个假设就是,每个field都是one-hot的,如果不是one-hot而是multi-hot,那么就用pooling的方式,如sum pooling,average pooling,max pooling等,这样才能保证每个特征field embedding都是定长的。DIN的前身GwEN模型也一样,对于multi-hot特征的典型代表,用户历史行为,比如用户在电商系统里购买过的商品,往往都是几十几百甚至几千的,需要经过sum pooling和其他特征concat一起。
而这种数学假设其实往往都是和实际的发生场景不一致的。例如一个女性用户过去在淘宝买过白色针织衫、连衣裙、帽子、高跟鞋、单肩包、洗漱用品等,当前候选商品是一件黑色外套,白色针织衫对黑色外套的权重影响应该更大,洗漱用品权重应该更小。如果将这些历史行为过的商品做sum pooling,那么无论对于当前推荐什么商品,用户都是一个固定向量的表达,信息损失很大,显然优化空间很大。
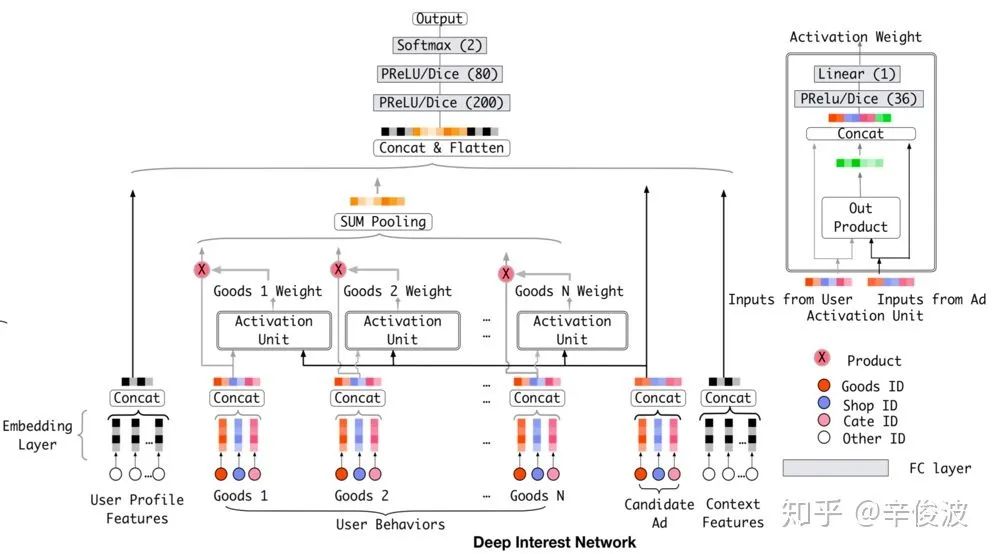
针对sum/average pooling的缺点,DIN提出了一种local activation的思想,基于一种基本的假设:用户历史不同的行为,对当前不同的商品权重是不一样的。例如用户过去有a, b, c三个行为,如果当前商品是d,那么a, b, c的权重可能是0.8,0.2,0.2;如果是商品e,那么a, b, c的权重可能变成了0.4,0.8,0.1。也就是说,不同的query,激发用户历史行为不同的keys的权重是不一样的。
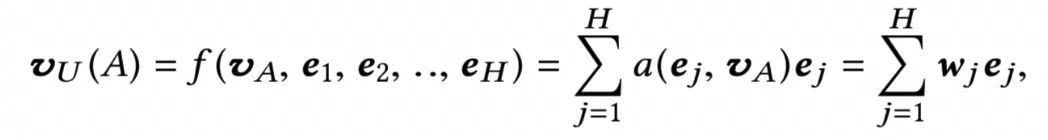
(1)query: 用户历史行为,长度为H,e,e2,…,eH表示用户历史行为的向量表示
(2)keys: 当前候选广告(店铺、类目、或者其他item实体)
关于DIN里的activation weight还有个可以稍微讲几句的点。两个向量的相似度,在前面讲各种CF的方法的时候基本是用的点积或者cosine,2017年DIN挂在arXiv的版本中是使用了两个向量本身以及concat后进入MLP得到其相似度,2018发在KDD的版本中多了outer product,以及向量相减,相当于引入和保留了更多特征的信息。另外作者在文章提到为了保持不同历史行为对当前attention的影响,权重也不做归一化,这个和原始的attention也有所不同。

作为工业界的落地实践,阿里在DIN上很“克制”的只用了最能表达用户个性化需求的特征--用户行为keys,而query也是当前候选的商品广告,与线上提升ctr的指标更为吻合,对工业界的推荐系统来说借鉴意义还是很大的。当然这不是说之前的其他attention机制模型没用,不同的数据集,不同的落地场景需求不一致,也给工业界更多的尝试提供了很多思路的借鉴。
4.2.13 DIEN模型(Deep Interest Evolution Network)
在前面讲到的模型中,所使用的特征都是时间无序的,din也如此,用户的行为特征之间并没有先后顺序,强调的是用户兴趣的多样性。但是实际用户的兴趣应该是在不断进化的,用户越近期的行为,对于预测后续的行为越重要,而用户越早期的行为,对于预测后续行为的权重影响应该小一点。因此,为了捕获用户行为兴趣随时间如何发展变化,在din提出一年后,阿里又进一步提出了DIEN,引入了时间序列概念,深度兴趣进化网络。
DIEN文章里提到,在以往的推荐模型中存在的序列模型中,主要利用RNN来捕获用户行为序列也就是用户历史行为数据中的依赖关系,比对用户行为序列直接做pooling要好。但是以往这些模型有两个缺点,第一是直接将RNN的隐层作为兴趣表达,而一般来隐层的表达和真正表达的商品embedding一般不是等价的,并不能直接反映用户的兴趣;另外一点,RNN将用户历史行为的每个行为看成等权的一般来说也不合理。整个DIEN的整体框架,如图4.43所示。

(1) 输入层
和DIN的输入一样。按照类型可以分为4大类
a) 用户画像特征:如年龄、性别、职业等
b) context特征:如网络环境、时间、IP地址、手机型号等,与user以及item无关
c) target ad特征:当前候选广告
d) 用户行为特征:DIEN里最重要的能体现用户个性化的特征,对于每个用户来说,假设有T个历史行为,按照发生的先后顺序依次输入模型
(2) embedding层
将one-hot特征转为dense的embedding向量
(3) 兴趣抽取层(interest extractor layer)
该层的主要作用和DIN一样,为了从embedding层中抽取出用户的兴趣。该paper认为用户当前对候选广告是否感兴趣,是和历史行为behavior有关的,所以引入了GRU的序列模型来拟合抽取用户兴趣。

经过GRU结构后,商品的embedding表达从e(t)变成了h(t),表示第t个行为序列的embedding表达。
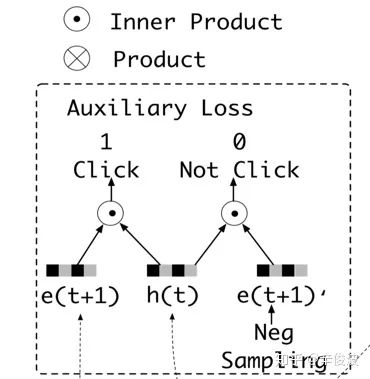
除了GRU结构提取隐层的向量,DIEN还引入了有监督学习,强行让原始的行为向量e(t)和h(t)产生交互。如图4.44所示,引入了辅助loss(auxiliary loss),当前时刻h(t)作为输入,下一刻的输入e(t+1)认为是正样本(click),负样本进行负采样(不等于当前时刻);然后让h(t)与正负样本分别做向量内积,辅助loss定义为:
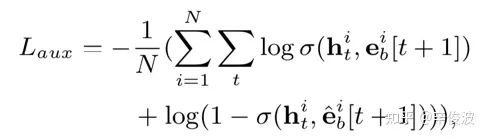
最终的loss表达为:
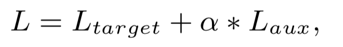
其中a为超参数,代表的是辅助loss对整体loss的贡献。有了这个辅助loss,t时刻提取的隐层向量h(t)可以比原始的h(t)更有助于表达用户兴趣,也可以加速网络的训练过程。
(4) 兴趣进化层(interest evolving layer)
理论上来说,h(t)如果替代e(t)作为商品的最终表达其实也是可以的,把用户序列t=1,2,3,…,T当成用户的T个行为过的商品,然后和当前的候选广告套用DIN的attention 网络去计算每个行为和当前候选广告的权重,最终得到用户的历史行为加权表达也是完全ok的。但作者认为用户的行为模式是会发展的,因此引入了第二层GRU网络来学习每个历史行为序列和当前候选广告之间的权重.
对于每个历史行为ht,当前候选广告ea,通过softmax求出两者的权重。注意这里不是直接向量点击,而是引入了矩阵W,可以认为是简单的一层全连接网络。
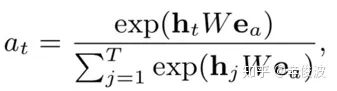
如何使用这里学习的attention作为兴趣进化层的输入,作者又提出了三种计算方法
(1) AIGRU(attention input with GRU)
最基础的版本,兴趣进化层第t个行为序列的input就是隐层ht的加权
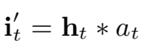
作者尝试后发现效果并不好,原因是如果是输入0,也会参与到隐层ht的计算和更新,相当于给用户兴趣的提取引入了噪音,不相关的用户行为会干扰模型的学习
(2) AGRU(attention base GRU)
这里作者使用了attention权重at来取代原始GRU中的更新门,表达如下

(3) AUGRU(GRU with attentional update gate)
这里作者依然对原始GRU做了改造,公式如下
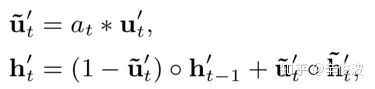

其中,ut’引入了at来取代原有的更新向量ut,表达的是当前ut’对结果的影响。如果当前权重at较大,ut’也较大,当前时刻ht’保留更多,上一个时刻ht-1影响也会少一点。从而整个AUGRU结果可以更平滑的学习用户兴趣
4.3 feature-based模型总结
Feature-based的模型主要在于学习特征之间的交叉,是近年来整个推荐系统在排序层面的主流研究方向,按照不同维度,我个人把4.2列到的模型分为4个类型,同一个模型可能会分到不同的类型里。这里的分类仅仅代表个人的观点,欢迎探讨。
4.3.1 基于框架的模型
(1) wide&deep模型
深度加宽度的模型范式,本身并不是一个具体的模型,wide和deep部分可以用任意结构框架,wide的baseline是LR模型;deep的baseline是MLP模型。
(2) deep crossing模型
和wide&deep最大的不同是deep部分引用了res-net,但个人觉得在目前主流的模型里用的较少。虽然res-net理论上可以使用更深的模型提升效果,但在目前工业界大规模稀疏的推荐系统里,还没见到太多往res-net方向取得较大进展的工作。
4.3.2 基于FM特征二阶组合的模型
学习特征交叉的主要手段是将特征的embedding做交叉,特点是特征的交叉是二维的,无非是二阶交叉如何做。
(1)deepFM模型
特征交叉使用的element-wise product,最终得到的是一个实数
(2)NFM模型
交叉使用的bi-interaction,可以理解成是所有vector的sum pooling,最终得到的是一个向量
(3) AFM模型
交叉使用的带权重的bi-interaction,可以理解成所有vector的weight sum pooling,然后使用一个简单的线性模型得到最终的值
(4) PNN模型
PNN模型放到基于FM的模型是因为本质上和FM一样,都是在学习特征的二阶组合。和deepFM不同的是,以IPNN为例,PNN的所有特征两两product交叉学习得到的值conat后得到现实的product vector后进入MLP模型;而deepFM是直接将FM模型的vector输入到MLP模型中。
4.3.3 基于attention的模型
(1) AutoInt模型
使用multi head机制,每个特征用self-attention得到其他特征和自己的attention权重。每个特征的所有head得到的特征concat起来作为新特征
(2) DIN模型
只使用户历史行为特征作为keys,keys之前没有时间序列;得到keys和当前候选item的attention。
(3) DIEN模型
只使用用户历史行为特征作为keys,keys之间具有先后顺序,引入两层GRU表达,第一层GRU学习用户历史行为序列的信息,每个时刻t输出的隐层embedding为该时刻item的embedding表达;第二层GRU用来学习历史每个时刻t的历史行为和当前候选广告的权重。
(4) FiBiNet 模型
把FiBiNet模型放在attention模型主要是它的SENet部分,通过squeeze->Excitation->reweight提取原始embedding的特征重要性,得到新特征,这里其实也体现了每个特征embedding的attention。
4.3.4 基于特征高阶组合的模型
(1) DCN模型
使用多层的cross 来做特征交叉,对于cross网络中每一层的输入都由前一层以及第一层的输入组成,从这个维度上代表的是高阶特征的组合。比如说,第四层网络的输出包含了第三层和第二层的输入;而第三层又包含了第二层和第一层,因此这里就是个3阶的特征交叉。特征的交叉使用的是bit-wise,也就是每个特征内部embedding的element也会两两交叉
(2) xdeepFM模型
使用CIN模型来提取特征交叉。和DCN模型一样的是,这里也使用了多层的cross,每一层的输入也是由第一层和上一层的输入组成,不同的是,xdeepFM模型的特征交叉是vector wise层级的,而DCN模型是bit-wise的
(3)FGCNN模型
通过使用CNN模块,先是卷积层提取局部特征的连接,如高度等于3能够提取相邻3个field的特征的关系,因此具有高阶特征的交叉能力。然后又通过池化层提取global信息,确保特征的输入顺序对结果的影响能够被捕捉到。
5.总结
推荐和搜索的本质其实都是匹配,前者匹配用户和物品;后者匹配query和doc。具体到匹配方法,分为传统模型和深度模型两大类,第二章讲的是传统模型,第三章和第四章讲的是深度模型。
对于传统模型,主要分为基于协同过滤的模型和基于特征的模型,两者最大的不同在于是否使用了side information。基于协同过滤的模型,如CF, MF, FISM, SVD++,只用到了用户-物品的交互信息,如userid, itemid, 以及用户交互过的item集合本身来表达。而基于特征的模型以FM为例,主要特点是除了用户-物品的交互之外,还引入了更多的side information。FM模型是很多其他模型的特例,如MF, SVD++,FISM等。
对于深度模型,主要分为基于representation learning的深度模型以及match function learning的深度模型。基于representation learning的深度模型学习的是用户和物品的表示,然后通过匹配函数来计算,这里重点在与representation learning阶段,可以通过CNN网络,auto-encoder, 知识图谱等模型结构来学习。
对于match function learning的深度模型,也分为基于协同过滤的模型和基于特征的模型。前者和传统CF模型一样,不同在于后面接入了MLP模型来增强非线性表达,目的是为了使得user 和item的vector尽可能接近,这种方法就是基于NCF的模型;也有通过引入relation vector来是的user vector加上relation vector后接近item vector,这种方法是基于翻译的模型。
对于match function learning另一种模型框架,是基于特征层面的,有基于fm模型的,基于attention的,以及高阶特征捕捉的,另外还有基于时间序列的文章中只提到了DIEN模型。
整理本篇综述主要基于原始slides,对其中的paper部分粗读部分精读,收获颇多,在全文用如何做好推荐match的思路,将各种方法尽可能串到一起,主要体现背后一致的思想指导。多有错漏,欢迎批评指出。
6. 参考文献
(1) https://www.comp.nus.edu.sg/~xiangnan/sigir18-deep.pdf
(2) Xiangnan He, Hanwang Zhang, Min-Yen Kan, and Tat-Seng Chua. Fast matrix factorization for online recommendation with implicit feedback. In SIGIR 2016.
(3) Yehuda Koren, and Robert Bell. Advances in collaborative filtering. Recommender systems handbook. Springer, Boston, MA, 2015. 77-118.
(4) Santosh Kabbur, Xia Ning, and George Karypis. Fism: factored item similarity models for top-n recommender systems. In KDD 2013.
(5) Yehuda Koren. Factorization meets the neighborhood: a multifaceted collaborative filtering model. In KDD 2018.
(6) Steffen Rendle. Factorization machines. In ICDM 2010.
(7) Hong-Jian Xue, Xin-Yu Dai, Jianbing Zhang, Shujian Huang, and Jiajun Chen. Deep matrix factorization models for recommender systems. IJCAI 2017.
(8) Suvash Sedhain, Aditya Krishna Menon, Scott Sanner, and Lexing Xie. Autorec: Autoencoders meet collaborative filtering. In WWW 2015.
(9) Yao Wu, Christopher DuBois, Alice X. Zheng, and Martin Ester. Collaborative denoising auto- encoders for top-n recommender systems. In WSDM 2016.
(10) Sheng Li, Jaya Kawale, and Yun Fu. Deep collaborative filtering via marginalized denoising auto- encoder. In CIKM 2015.
(11) Xue Geng, Hanwang Zhang, Jingwen Bian, and Tat-Seng Chua. Learning image and user features for recommendation in social networks. In ICCV 2015.
(12) Jingyuan Chen, Hanwang Zhang, Xiangnan He, Liqiang Nie, Wei Liu, and Tat-Seng Chua. Attentive collaborative filtering: Multimedia recommendation with item-and component-level attention. In SIGIR 2017.
(13) Fuzheng, Zhang, Nicholas Jing Yuan, Defu Lian, Xing Xie, and Wei-Ying Ma. Collaborative knowledge base embedding for recommender systems. In KDD 2016.
(14) Xiangnan He, Lizi Liao, Hanwang Zhang, Liqiang Nie, Xia Hu, and Tat-Seng Chua. Neural collaborative filtering. In WWW 2017.
(15) Ting Bai, Ji-Rong Wen, Jun Zhang, and Wayne Xin Zhao. A Neural Collaborative Filtering Model with Interaction-based Neighborhood. CIKM 2017.
(16) Xiangnan He, Xiaoyu Du, Xiang Wang, Feng Tian, Jinhui Tang, and Tat-Seng Chua. Out Product-based Neural Collaborative Filtering. In IJCAI 2018.
(17) Tay, Yi, Shuai Zhang, Luu Anh Tuan, and Siu Cheung Hui. "Self-Attentive Neural Collaborative Filtering." arXiv preprint arXiv:1806.06446 (2018).
(18) Ruining He, Wang-Cheng Kang, and Julian McAuley. Translation-based Recommendation. In Recsys 2017.
(19) Yi Tay, Luu Anh Tuan, and Siu Cheung Hui. Latent Relational Metric Learning via Memory-based Attention for Collaborative Ranking. In WWW 2018.
(20) Heng-Tze Cheng, Levent Koc, Jeremiah Harmsen, Tal Shaked, Tushar Chandra, Hrishi Aradhye, Glen Anderson et al. Wide & deep learning for recommender systems. In DLRS 2016.
(21) Ying Shan, T. Ryan Hoens, Jian Jiao, Haijing Wang, Dong Yu, and J. C. Mao. Deep crossing: Web-scale modeling without manually crafted combinatorial features. In KDD 2016.
(22) Xiangnan He, and Tat-Seng Chua. Neural factorization machines for sparse predictive analytics. In SIGIR 2017.
(23) Jun Xiao, Hao Ye, Xiangnan He, Hanwang Zhang, Fei Wu, and Tat-Seng Chua. Attentional factorization machines: Learning the weight of feature interactions via attention networks. IJCAI 2017.
(24) Guo, Huifeng, Ruiming Tang, Yunming Ye, Zhenguo Li, and Xiuqiang He. Deepfm: A factorization-machine based neural network for CTR prediction. IJCAI 2017.
(25) Ruoxi Wang, Gang Fu, Bin Fu, Mingliang Wang. Deep & Cross Network for Ad Click Predictions. ADKDD2017.
(26) Jianxun Lian, Xiaohuan Zhou, Fuzheng Zhang, Zhongxia Chen, Xing Xie, Guangzhong Sun. xDeepFM: Combining Explicit and Implicit Feature Interactions for Recommender Systems. KDD2018.
(27) Bin Liu, Ruiming Tang, Yingzhi Chen, Jinkai Yu,Huifeng Guo, Yuzhou Zhang. Feature Generation by Convolutional Neural Network for Click-Through Rate Prediction. WWW2019.
(28) Tongwen Huang, Zhiqi Zhang, Julin Zhang. FiBiNET: Combining Feature Importance and Bilinear feature Interaction for Click-Through Rate Prediction. Recsys2019.
(29) Weiping Song, Chence Shi, Zhiping Xiao, Zhijian Duan, Yewen Xu, Ming Zhang,Jian Tang. AutoInt: Automatic Feature Interaction Learning via Self-Attentive Neural Networks. CIKM2019.
(30) Guorui Zhou, Xiaoqiang Zhu, Chengru Song, Ying Fan, Han Zhu, Xiao Ma,Yanghui Yan,Junqi Jin,Han Li, Kun Gai. Deep Interest Network for Click-Through Rate Prediction. KDD2018.
(31) Guorui Zhou, Na Mou, Ying Fan, Qi Pi,Weijie Bian, Chang Zhou, Xiaoqiang Zhu and Kungai. Deep Interest Evolution Network for Click-Through Rate Prediction. AAAI2019.
下载一:中文版!学习TensorFlow、PyTorch、机器学习、深度学习和数据结构五件套!
![]()
![]()
![]()
后台回复【五件套】
下载二:南大模式识别PPT
![]()
后台回复【南大模式识别】




由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方“深度学习自然语言处理”,进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心
投稿或交流学习,备注:昵称-学校(公司)-方向,进入DL&NLP交流群。
方向有很多:机器学习、深度学习,python,情感分析、意见挖掘、句法分析、机器翻译、人机对话、知识图谱、语音识别等。

记得备注呦
整理不易,还望给个在看!





