【论文总结】TextGCN
点击上方,选择星标或置顶,每天给你送干货
阅读大概需要4分钟
跟随小博主,每天进步一丢丢


来自 | 知乎
地址 | https://zhuanlan.zhihu.com/p/111945052
作者 | S先森
编辑 | 机器学习算法与自然语言处理公众号
本文仅作学术分享,若侵权,请联系后台删文处理
这篇论文,还是挺简单的基于GCN的应用型文章,主要的贡献在于构建了基于文本和词的异构图,使得在GCN上能够对文本进行半监督分类。
Graph Convolutional Networks for Text Classification
既然图是核心,那我们先看看图是怎么构建的。
1. 图的构建
1.1 节点
这个图包含了两种节点,分别是document节点和word节点,这不难理解,文本就只有词嘛。关于词的预处理,只要我们按照文章给出要求(包括低频词处理、停留词处理、标点符号的处理)来处理,基本上就能获得同样的节点数量(特别是词节点数量)。
1.2 边
这里的边也是包含两种边:document-word 和 word-word
document-word
这个边的权重就是 TF-IDF,用 sklearn 的 TfidfTransformer 函数就能获得,当然,也可以按照作者代码里的那样自己手写。
但是用 TfidfTransformer 值得注意的是一些参数的调整,我下面直接给出代码吧。
使用 Pipeline是为了能够处理更大量的文本,不让会导致内存溢出。
text_tfidf = Pipeline([
("vect", CountVectorizer(min_df=1,
max_df=1.0,
token_pattern=r"\S+")),
("tfidf", TfidfTransformer(norm=None,
use_idf=True,
smooth_idf=False,
sublinear_tf=False
))
])值得注意的 CountVectorizer 中的这三个参数 min_df, max_df 和 token_pattern,如果按照默认的来,会过滤掉一些词,这样就没法完全重现文章的最后效果。
而 TfidfTransformer 中,就要注意 norm=None ,这些都是复现过程中的一些坑。
这样,就能构建document-word的边及其权重。
word-word
在这里,文章用了一个叫做 PMI 的方法来计算的。简单来说,就是在一定的范围内,这两个词共现的频率,这很容易理解,就是共现次数越高,权重越大。
首先我们需要用一个长度为 L 的窗口(window)来把一个句子切割成一个个小段 (注意词去重)。这样,我们就会获得一大堆 windows(一堆长度为 L 的词片段),也就是 #W。
然后统计 词在 windows 里出现的频率;再统计 windows 每个window 里 词 两两组合 的频率。这样我们就能获得 #W(i) 和 #W(i, j)。
最后就是根据公式来计算了,如下图。
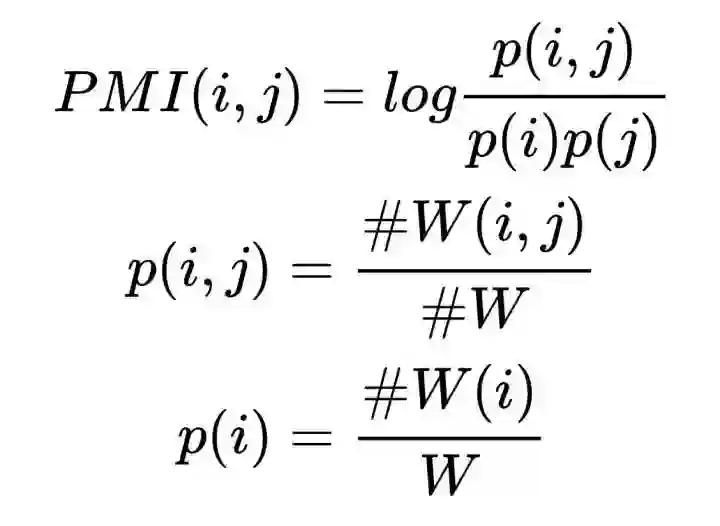
这样子,我们就完成了TextGCN里所说异构图了。
其他
TextGCN使用的是 one-hot 作为特征输入,我试了用随机或者GloVe、BERT,效果都莫名其妙地差,不知道为啥呢?
训练集和测试集 得按照数据集里标注的那样切割,随机划分,效果也会不好。
word-word PMI 这个边,去除了会有1%~3%的准确率下降,但训练速度会快很多,毕竟减少了很多边。
迭代次数和训练率也会影响最后的复现效果,严格按照论文里给出的条件吧。
那就总结到这里,以后补一下其他实验吧。






