OPPO在FaaS领域的探索与思考 | Q推荐

ESA Stack(Elastic Service Architecture) 是 OPPO 云计算中心孵化的技术品牌,致力于微服务相关技术栈,帮助用户快速构建高性能,高可用的云原生微服务。产品包含高性能 Web 服务框架、RPC 框架、服务治理框架、注册中心、配置中心、调用链追踪系统,Service Mesh、Serverless 等各类产品及研究方向。
当前部分产品已经对外开源:
开源主站:https://www.esastack.io/
Github: https://github.com/esastack
Serverless 是什么,下面引用的这段来自伯克利大学的论文《A Berkeley View on Serverless Computing》
Put simply, serverless computing = FaaS + BaaS. In our definition, for a service to be considered serverless, it must scale automatically with no need for explicit provisioning, and be billed based on usage.
我们暂且不管 FaaS 和 BaaS 是什么,这段话提到了 2 个核心的点,自动弹性伸缩和按用量付费,一般来说各大云产商会多强调的一个卖点是少运维甚至免运维,开发者可以少关注机器层面的事情。有一个很形象的比喻是,Serverless 就像网约车,需要的时候我们再叫车,不需要的时候我们也不需要承担汽车的闲置、养护成本,我们只需要按需付费。
关于 Serverless 的历史,下面摘录的这段来自 Serverless 白皮书
虽然按需或"pay as you go"模型的想法可以追溯到 2006 年和一个名为 Zimki 的平台,但 Serverless 一词的第一次出现是 Iron.io 在 2012 年推出了 IronWorker 产品,一个基于容器的分布式按需工作平台。
而 Serverless 能真正被大家所熟知,大体是在 2014 年 AWS 推出 Lambda 的时候,后续各大云产商都推出了自己的产品。限于篇幅,本文后述内容会更多的聚焦在 FaaS 的层面。
那 FaaS 又是什么,其实并不是一个容易回答的问题,但我还是想先尝试概括性地描述下自己的理解。FaaS 是一种开发模式,相比传统模式,开发者向基础设施平台让渡了一部分选择的自由,比方语言框架、依赖库、函数必须实现云厂商定义的接口规范等等。与之相对的,平台会为开发者提供一些能力,比方按需执行和计费,弹性伸缩,少运维甚至免运维机器等。正如云计算的发展史,总的趋势都是基础设施平台管的或者提供的通用能力越来越多,为开发者屏蔽了越来越多的复杂性。
文字描述可能有些苍白,下面的代码是 OPPO FaaS 平台一个基于 Java 语言的 Web 函数示例
@Path("/")public class HelloWorldFunction {private static final Logger LOGGER = LoggerFactory.getLogger(HelloWorldFunction.class);@POSTpublic String handle(@HeaderParam("name") String name) {LOGGER.info("function is running! name {}", name);return "hello " + name;}}
这是一个比较简单的例子,函数收到请求后,打印了一些日志,然后往客户端返回了"hello ${name}"。上述的开发者对平台让渡了一些选择自由,在这个例子里面。
开发者不知道代码底层跑在一个什么样的 web 框架之上,是 tomcat 还是 jetty 还是其它,多提一句,OPPO FaaS 平台 java 语言的 Runtime 是基于我们自己开源的 web 框架 restlight 实现。
此外,大部分云厂商的 FaaS 产品是需要开发者实现厂商定义的 API 接口的,这里平台限定了开发者只能使用 JAX-RS 这个社区规范而不是提供私有接口。
开发者需要使用平台定义的 logger 来打印日志,这样平台可以做日志路径统一定义方便采集,同时往 logger 里注入诸如 traceid 等方便排查问题的信息。
下图引用自文章 《Serverless 选型:深度解读 Serverless 架构及平台选择》
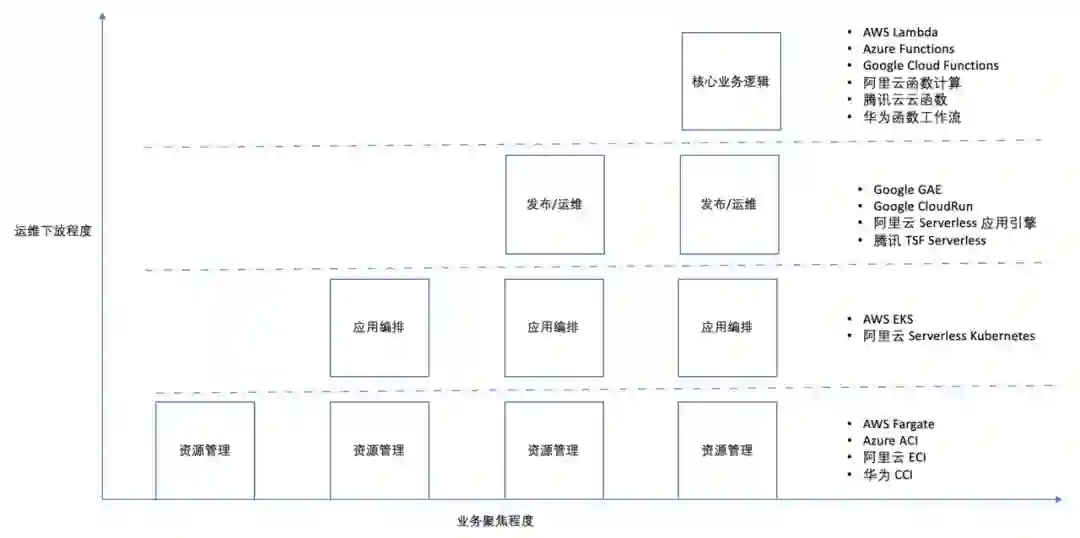
图片图里以业务聚焦程度和运维下放(给云厂商)程度为坐标轴,给市面上的产品大体做了区间划分。FaaS 产品在这两个维度都是最高的那档,意味着这种形态的产品已经在最大限度上让开发者可以聚焦在自己的业务逻辑处理上而不用关心太多的非功能性需求。
当然,正如上面所描述,开发者是需要让渡出很多选择上的自由并且能做的事情有限。此外,想象开发者现在有个普通的 web 应用提供了十多个接口,如果基于 FaaS 产品函数这种粒度,不得不拆分成十多个函数,这会带来管理和操作上的困难。所以,各大云厂商的 FaaS 产品,慢慢都开始提供了基于镜像或者自定义 Runtime 的方式,让开发者可以将一些老应用低成本的迁移上 FaaS。
笔者自己刚开始做 Serverless\FaaS 相关工作的时候,第一款接触的产品是大名鼎鼎的 Knative
apiVersion: serving.knative.dev/v1kind: Servicemetadata:name: helloworld-gospec:template:spec:containers:- image: gcr.io/knative-samples/helloworld-goenv:- name: TARGETvalue: "Go Sample v1"
上面是一个简单的例子,helloworld-go 这个镜像本身是个非常简单的 http 服务,访问之后会返回一串文本。但如果跑在了 knative 环境之内,便可以快速地将应用 Serverless 化,knative 可以根据并发访问量(也支持其它指标)给应用做弹性伸缩甚至把实例数缩容到 0。当然,实例从 0 到 1 由于底层机制,应用就绪到提供服务的时间大概是分钟级比较长,这个业界称为冷启动耗时,后文会再展开。这里只涉及 knative 的一小部分功能,其它的限于篇幅不展开阐述。
当时体验及研究过一段之后,笔者一直反复思考的问题其实是,如果自己作为一个普通的业务使用方,存量的业务如果仅仅只是为了一个弹性伸缩的能力,在公司内部的弹性伸缩产品已经有这种能力了,自己没有动力将服务迁移到 knative 的环境。所以在经过内部讨论及一些尝试后,我们最终没有选择做存量业务的 Serverlss 化,而是决定专注做 FaaS 产品,拉一些适合这种形态的新业务来落地。
事实上,Knative 也并不是 FaaS 产品,关于这点官方也是给出过说明的。当然了,我们是可以基于 Knative 去做 FaaS 产品,国产 FaaS 产品 openFunction 便是一个例子

在决定了专注做 FaaS 产品之后,便面临选型问题。云厂商的 FaaS 产品是没有开源的无从得知实现细节,所以只能调研开源产品。市面上大部分的 FaaS 开源框架都是基于 k8s 实现的,像 fission、openfaas、openfunction 等,好处是这样可以最大程度地利用 k8s 的基础能力和整个生态,而不用什么东西都从 0 开始建设。
想象一下我们现在需要对外提供一个类似 LeetCode 那样的编程环境,给用户编写一些相对简单的代码然后调试运行。如果使用传统的方式来做,部署一组机器然后多个用户编写的代码在这些机器上分配调度之后去运行,一个是隔离性不好会互相抢占资源,另外是需要自己实现一套把代码根据机器的负载情况把任务调度到某台机器的逻辑,再有还需要考虑这些代码访问量和弹性伸缩、后续运维等。上面提到的痛点,正是 FaaS 产品所擅长解决的,所以当时我们就承接了这么一个需求。
如果这个需求我们直接使用 k8s 来实现,每份代码我们跑在一个 deployment 里面,弹性伸缩我们使用 k8s 的 hpa 解决,pod 提供了一定程度的隔离,功能也是可以实现的。但回想一下我们以前在 LeetCode 改代码提交之后点击测试,基本上可以在一两秒内出结果。如果直接使用 k8 原生的这些能力,用户改完代码之后我们需要走编译、打镜像、k8s 调度、kubelet 拉镜像、起服务的流程,整个过程至少是分钟级,用户体验会比较差。这个问题和上面提到的冷启动问题是很接近的,即服务实例在 0 到 1 的过程是比较耗时的。
1)冷启动分析

图片上图是一次实例数从 0 到 1 时冷启动的过程,步骤 1-3 耗时大部分时候远超执行函数的时间。对于步骤 1 来说,如果底层是基于 k8s 利用其原生的调度能力,不管怎么优化,都不可能到毫秒级。对于步骤 2,云厂商一般会限制上传的代码包\镜像大小,另外则是如果用户使用的依赖已经被做进了运行时 Runtime(一般文档里会有依赖列表),则用户上传的代码不需要带有这些依赖可以小很多,这样下载依赖和代码的时间会短很多。针对步骤 3,这里可能需要岔开单独说一下 Runtime 是个什么东西。
2)Runtime 是什么
由于 FaaS 的模式开发者只提供业务逻辑那一小部分代码,肯定是不足以运行起来的,它需要有个环境去承接运行,我们一般把 FaaS 平台提供的这个运行时环境称为 Runtime。这里又可以分成两部分,一个是代码片段底层运行的语言相关的框架(tomcat、jetty 等)。另外一部分是语言无关的环境,像你的服务是跑在容器里面还是 vm 或者其他环境里面。
一般来说,函数的调用和执行有两种方式。一种是真的完全按需,每个请求由独立的进程(容器)来执行,执行完就销毁,这种一般也称为 Exec 模式。另外一种是执行完还是会保持一段时间,后续没有请求再销毁,也叫 Runtime 模式。关于这两种模式的讨论,参考链接 5 的文章写的挺好,这里摘抄一段
调用和执行方式。Exec 模式虽然开发成本比较小,但运行效率上有差距,本质上是把所有的语言都当做脚本语言对待,等于放弃了各种语言这么多年性能的优化成果。如果是比较重的事件处理,还可以承受,但如果要承载高并发任务就比较困难,这也是为什么 Azure 后来放弃自己的第一版 Function 实现的原因。当前看来,如果要做通用的 FaaS 兼顾性能和效率,还是要通过 Runtime 的方式。但 Runtime 的方式带来的一个问题是依赖的管理和隔离,如果 Runtime 没有很好的机制隔离用户代码和 Runtime 的代码,二者的依赖就有耦合,导致用户的 Function 的依赖选择上受限于 Runtime 的平台。
Runtime 的启动速度及隔离性是最重要的两部分。一般来说基于 k8s 的 FaaS 产品底层当前跑的都是容器,启动速度并不慢。而传统上来说我们会觉得 vm 的启动速度远低于容器,但从公开资料来看,一些云厂商会使用轻型 vm 来跑 FaaS,这样可以兼顾启动速度和隔离性。
Firecracker 目前已经能提供小于 125ms 的 MircroVM 启动速度,每秒 150 台的启动能力,小于 5MiB 的内存开销,并发运行 4000 台的极限承载容量(AWS i3.metal EC2 作为宿主机),以及热升级能力等。这些都是传统虚拟机所遥不可及,但现代化弹性工作负载又有强烈需求的性能指标。 ——此处引用可参考引用文章 4
此外,现在业界已经有些项目在调研甚至落地使用 WebAssembly(后文简称 wasm)跑 FaaS,公有云暂时没有看到直接支持,但是可以在 docker 镜像里面跑 wasm 这样的方式间接支持。主要还是考虑隔离性、启动速度、还有 wasm 可以支持多语言编译成.wasm 文件运行。虽然当前 wasm 技术整个配套并不十分完善,但相信随着发展后面市面上应该会有越来越多的 FaaS 产品支持跑在 wasm 的 Runtime 里面。
至此,我们分析了冷启动问题的多个环节,及 Runtime 在 FaaS 产品里的重要性,聊完了问题我们讲讲解决方案。
3)热 pod 池技术
业界在这个问题上其实大概那么几个手段。一个是实例预留,既不把实例数缩容到 0。还有就是上文描述的,探索极致的 Runtime 启动速度配合调度系统,这个投入比较大。另外就是预先准备实例热池的方案,提前准备好一组实例,在用户请求到来时从中选一个实例绑定用户的代码然后执行逻辑。业界开源的 FaaS 产品 fission 即实现了热池的方案,并且像 nodejs、python 这样的语言,代码包不大的情况下,冷启动耗时大概在 100+ms 左右。
4)fission 从 0 到 1 的流程分析
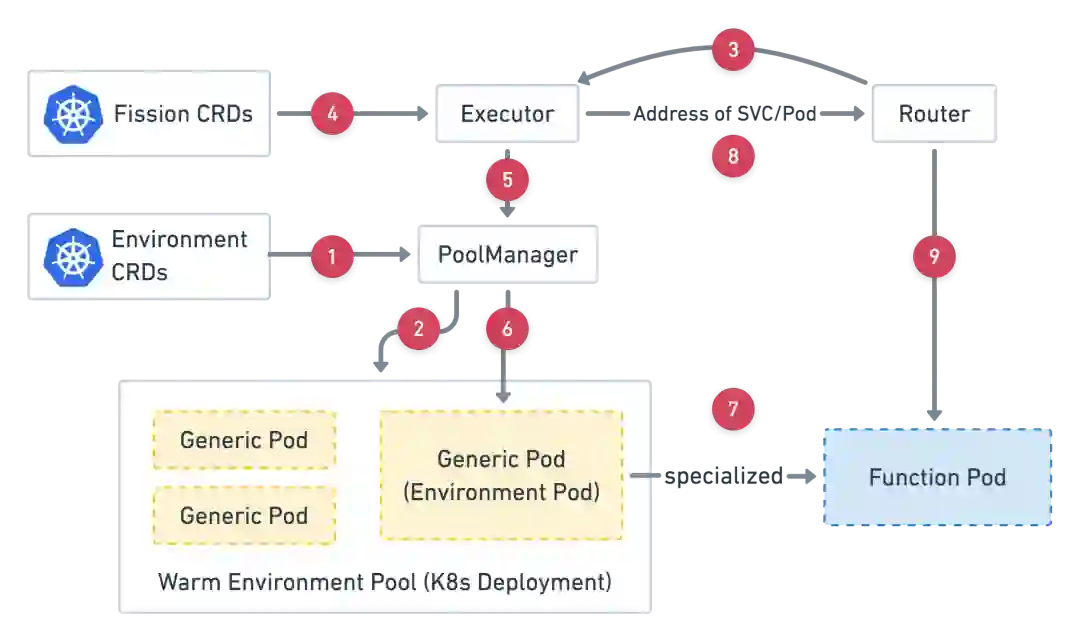
上图是从 fission 官方文档拿下来的。左下角 Warm Environment Pool 即是所谓的热 pod 池。里面的 pod 是已经启动了的服务实例,实例已经走完了 k8s 调度、拉镜像、起服务等耗时的步骤。我们这里从步骤 3 看起,当请求打到入口代理 router 时,其会从 executor 处拿一个函数的访问地址(步骤 3),而 executor 若发现函数实例为 0,会从热 pod 池里随机挑一个 pod,然后到 pod 自己去下载代码,利用语言的动态加载机制加载用户代码(步骤 5、6、7),完成上述步骤意味着 pod 已经具备提供服务能力,router 拿到返回的地址直接请求函数即可。
5)不足分析
上述是一个简要的流程分析,实际会更复杂些。看到这里读者可能会有疑问
router 请求 executor 取函数地址,是每次请求都需要这么做嘛
流程里没有体现弹性伸缩和并发控制的流程,这块是在哪里实现的
关于问题 1,是的,fission 原生的流程就是这么做的。而且在 router 和 executor 的流程里还有一些查询 k8s 的操作,每次请求都会做,换句话说核心链路里是强依赖了 k8s 的,不仅稳定性有限,吞吐量也非常有限,设计不合理。
关于问题 2,并发控制的流程是在 executor 服务里控制的,它的实现是在内存里存了类似下面这个结构来计数做并发控制,由于把数据存在内存里,executor 服务只能部署单台,这也是一个非常不合理的设计。这里针对的是 web 函数,fission 事件函数的弹性伸缩限于篇幅,本文就不展开叙述了。
{"函数id":{"实例1":10, // 记录当前实例在处理的请求数"实例2":3},……}
考虑到人员投入情况和需要业务落地的牵引,我们决定先使用开源产品来建设自己的 FaaS 产品,后面慢慢建设完善。具体来说我们选用了 fission,它底层基于 kubernetes,像上文描述,其使用了热 pod 池技术解决冷启动的问题,我们另外打通了公司内部许多成熟的产品,支撑了第一个业务落地。
1)产品全景图
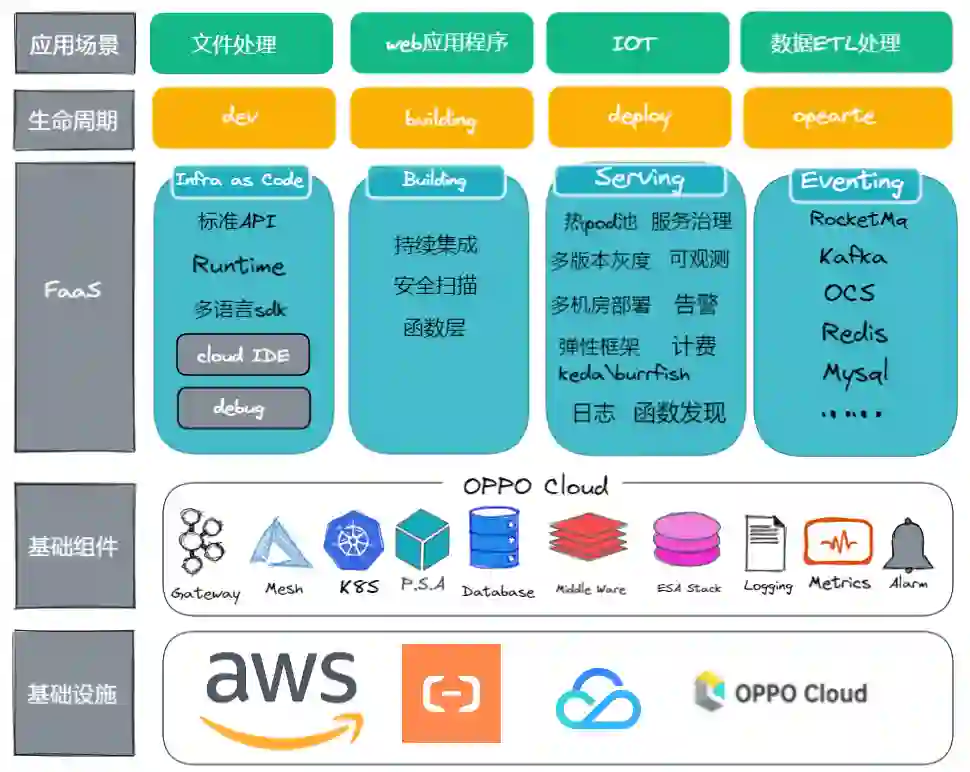
上图是我们 FaaS 产品的概览图,我们是基于公司内部很多成熟的产品来搭建服务。Kubernetes 集群是使用了 OPPO 定制的版本 OKE(OPPO Kubernetes Engine),好处是在多云的环境里我们的服务无须做适配即可部署。此外我们也打通了 CMDB、日志、监控、API 网关、注册中心、弹性伸缩等产品,这些都是一个 FaaS 系统必不可少的。限于篇幅,下文主要涉及的还是 Serving 部分。
2)函数从 0 到 1 流程图
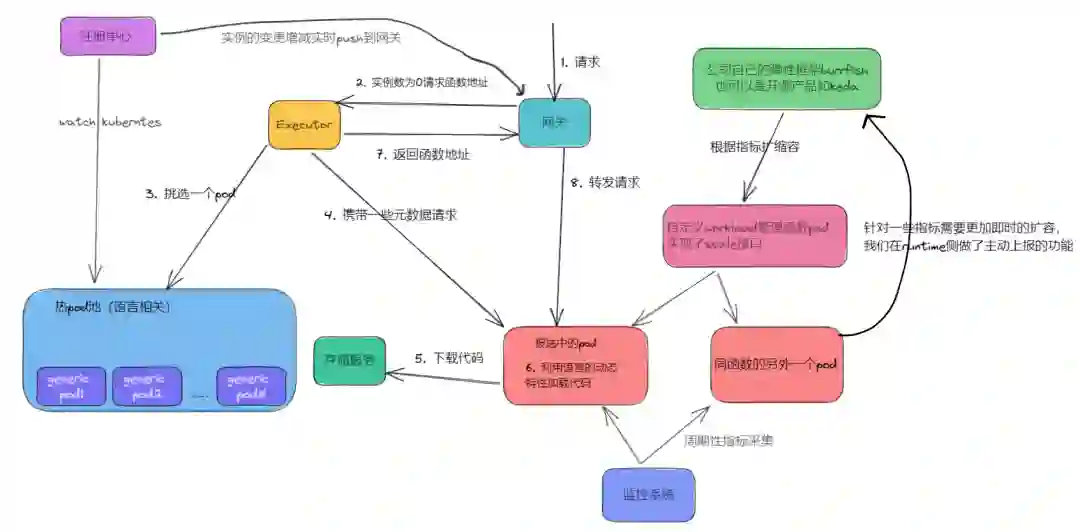
前文提到 fission 存在的问题,我们在自己的流程设计里做了改进和优化。下文会分成几个方面来讨论。
3)API 网关
我们并没有使用 fission 原生的 router 网关,而是使用公司自己的 API 网关。主要是基于以下两点考虑
公司的 API 网关已经经过很长时间超大规模流量的考验,远比 fission 的 router 网关来的稳定和可靠。
公司的网关本身的功能也丰富的多,事实上我们也利用了网关的分流能力,实现了一套按一定规则路由到函数不同版本的方案,crd 的设计及具体流程为了简洁上图未有体现。
4)注册发现机制
fission 原生是没有注册发现这套机制的,我们对接了公司的网关及注册中心产品,实现了函数发现功能,实例数的增删可以实时通过注册中心推送给到网关。此时仅在实例数从 0 到 1 时会从调用 executor 组件拿一个函数地址,其余的实例增减都是通过函数发现的功能来实现。解决了 fission 原生的缺陷,在核心链路里依赖了 executor 服务及 k8s 带来的吞吐量及稳定性问题。
5)弹性伸缩
k8s 里面的 deployment 我们都比较熟悉,由于我们的产品实现底层是基于热 pod 池技术,加载完代码之后的 pod 还是需要有一个工作负载来管理。好处是如果 pod 所在宿主机有异常,我们可以感知到并做故障转移。另外出于可扩展性的考虑,我们希望长期来看函数可以在不同的弹性框架上做切换。基于上述考虑,我们实现了一个自定义的工作负载叫 fndeployment 来管理函数的 pod 实例,然后对接了公司的弹性框架产品 burrfish,同时由于实现了 k8s 的 scale 接口,这样后续需要的话可以很容易的对接上 hpa、keda 等其他弹性伸缩产品。
函数的指标都采集到了公司的监控产品内,弹性伸缩框架可以基于这些指标做弹性伸缩。由于监控系统对实例的指标采集是周期性的,时效性上会差一些。对于一些需要更加即时扩容的指标,我们在 Runtime 侧做了主动上报的功能,可以实现更加即时的扩容。
6)servicemesh 产品集成
我们的环境里集成了 linkerd 这个 servicemesh 产品,关于 servermesh 产品是什么这里不多做展开,只聊下我们引入了 servicemesh 是为了解决什么问题,主要基于以下几点考虑
函数针对各种语言需要实现各自的 Runtime,而像可观测、服务治理这些能力是需要多语言重复建设的,使用了 servicemesh 之后这部分的工作可以只建设一次
FaaS 产品和 servicemesh 产品结合在业界并不是一个孤例,除了上述提到的可观测和服务治理,长期来看函数在多语言间还是会有很多共性能力需要建设,引入 servicemesh 之后可以基于其提供的扩展能力来做建设,多语言共用。
函数在集群内访问另外一个函数,同样需要灰度分流的功能,这一块由于有 sidecar 的存在,函数可以直接访问另外一个函数而不必绕道网关
可能有读者会好奇为什么在 servicemesh 产品上我们选用了 linkerd 而不是 istio,主要是基于几个方面考虑
linkerd 三大设计原则,简单、够用就行(just work)、最小化资源消耗,istio 相对复杂,而当前函数的诉求用不上 istio 那么多功能
linkerd 在性能及资源消耗上相对 istio 更优,数据参考
linkerd 是少数几个 cncf 毕业的项目,linkerd-proxy 基于 rust 开发,相比 envoy 基于 c++,后续若有扩展需求门槛相对低些
本文主要介绍了 OPPO 在 FaaS 领域的探索和思考,包括对选型,冷启动、Runtime、整个 FaaS 产品的思考及分析,针对 fission 不足所做的优化改进。行文至此发现篇幅已经较长,还未涉及到的内容如事件体系又是一大主题,还有关于笔者作为 Serverless 使用者的视角对 FaaS 及 BaaS 产品结合的思考,后续有机会再做分享。
我们也会一直持续关注业界动态,对新技术如 wasm 等长期关注,以期做出更优秀的产品。
1. Serverless 选型:深度解读 Serverless 架构及平台选择:
https://zhuanlan.zhihu.com/p/141217056
2. Serverless Whitepaper:
https://github.com/cncf/wg-serverless/tree/master/whitepapers/serverless-overview
3. 一直在说的冷启动,究竟是个啥子呦:
http://bluo.cn/serverless-code-start
4. 深度解析 AWS Firecracker 原理篇 – 虚拟化与容器运行时技术:
https://aws.amazon.com/cn/blogs/china/deep-analysis-aws-firecracker-principle-virtualization-container-runtime-technology/
5. Serverless\FaaS 现在和未来:
https://jolestar.com/serverless-faas-current-status-and-future/
6. 容器技术之容器引擎与江湖门派:
https://developer.aliyun.com/article/778752#slide-13
7. 在腾讯云上部署基于 WebAssembly 的高性能 serverless 函数:
https://my.oschina.net/u/4532842/blog/5172639
8. wasm 对比 docker:
https://wasmedge.org/wasm_docker/
9. 基于 Knative 打造生产级 Serverless 平台:https://www.sofastack.tech/blog/knative-serverless-kubecon-na2019/

