第六届中文语法错误诊断大赛,哈工大讯飞联合实验室再获多项冠军

AI也能改作文
 中文语法错误诊断大赛官方网页
中文语法错误诊断大赛官方网页

 语病错误类型举例表
语病错误类型举例表
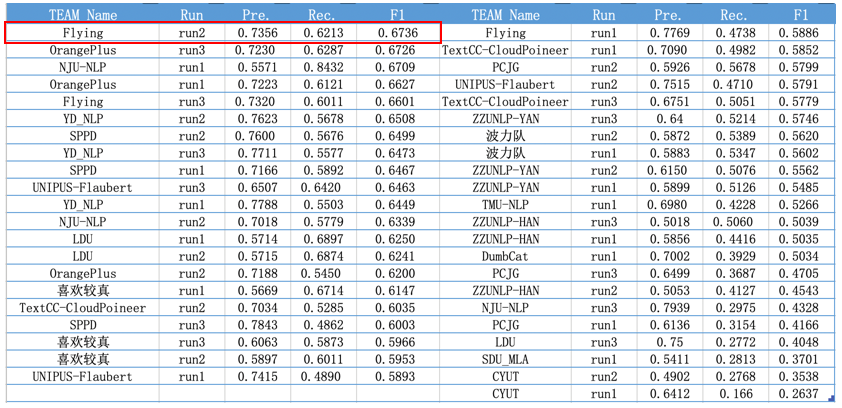 CGED 2020 Identification-level指标情况
CGED 2020 Identification-level指标情况
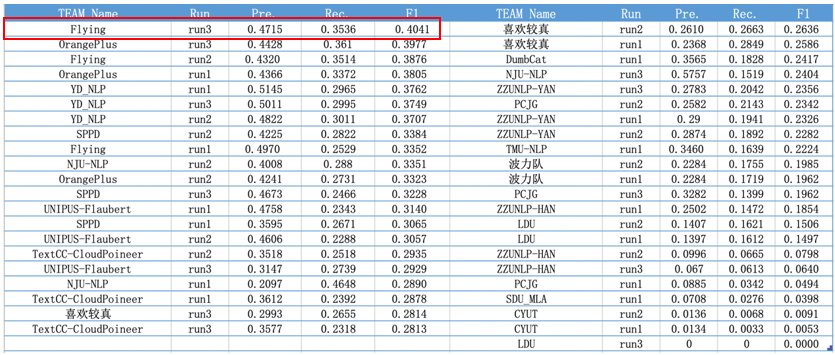 CGED 2020 Position-level指标情况
CGED 2020 Position-level指标情况
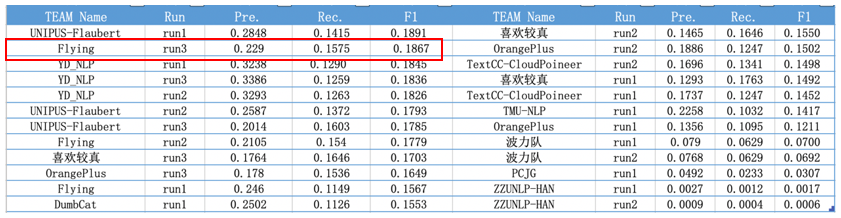 CGED 2020 Correction top1 指标情况
CGED 2020 Correction top1 指标情况
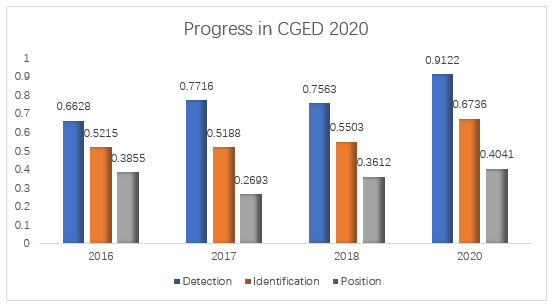
真题实战,看看这位AI冠军如何修炼
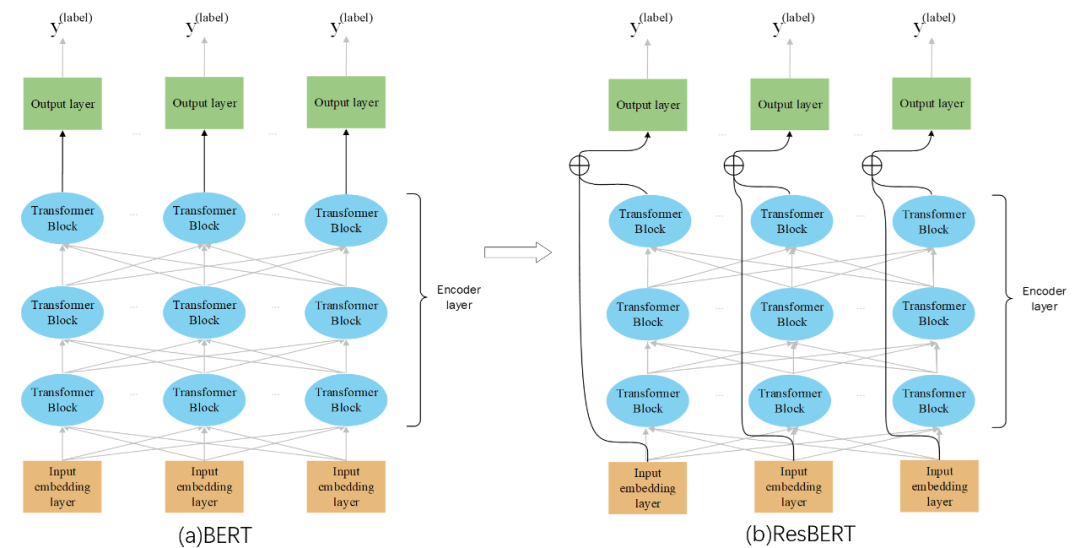 ResBERT模型结构图
ResBERT模型结构图
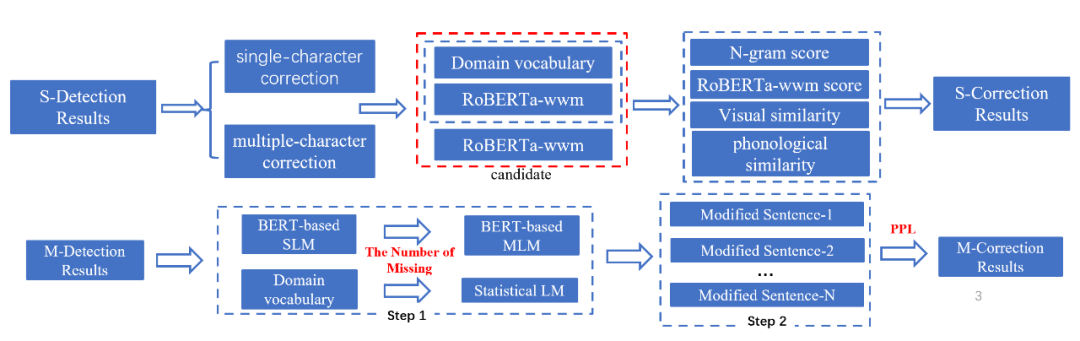 修正技术框架图
修正技术框架图
技术落地应用,让AI走得更远
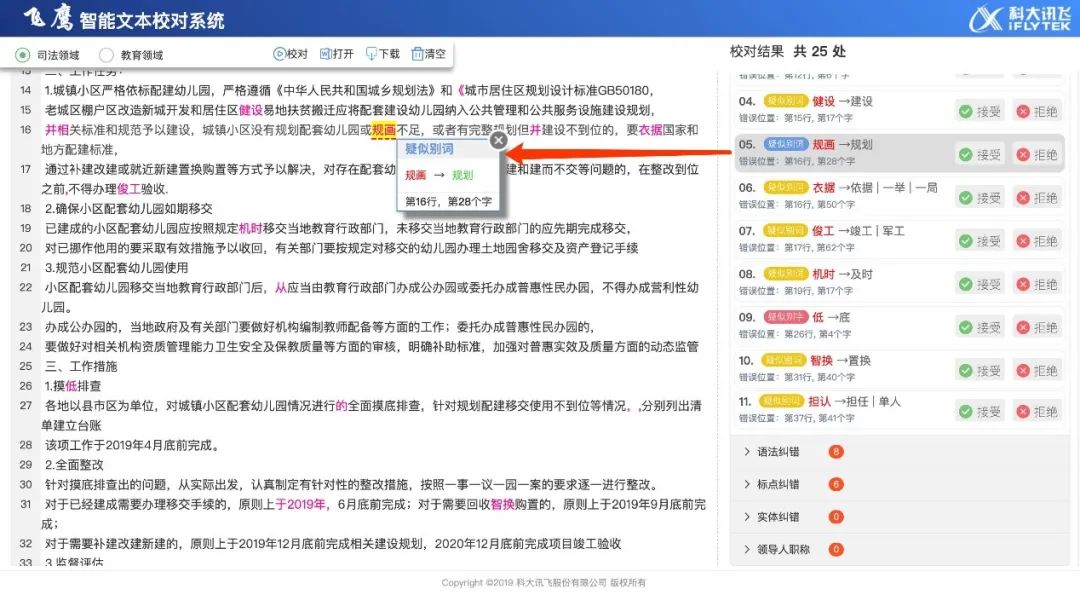 飞鹰智能文本校对系统
飞鹰智能文本校对系统
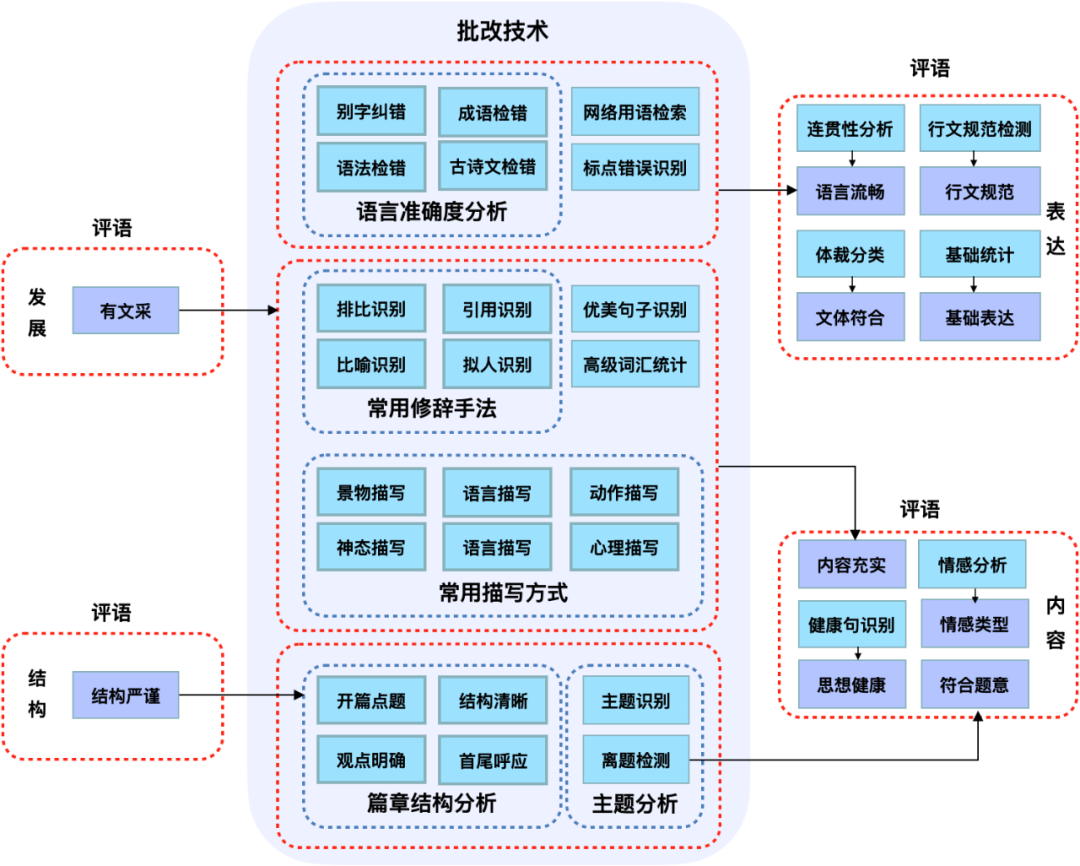 科大讯飞作文自动批改
科大讯飞作文自动批改


点击阅读原文,直达NeurIPS小组!
由于微信公众号试行乱序推送,您可能不再能准时收到AI科技评论的推送。为了第一时间收到AI科技评论的报道, 请将“AI科技评论”设为星标账号,以及常点文末右下角的“在看”。
登录查看更多
相关内容
专知会员服务
14+阅读 · 2019年11月11日
Arxiv
8+阅读 · 2018年5月12日
Arxiv
4+阅读 · 2017年8月17日




相关VIP内容
专知会员服务
14+阅读 · 2019年11月11日
相关资讯
相关论文
Arxiv
8+阅读 · 2018年5月12日
Arxiv
4+阅读 · 2017年8月17日