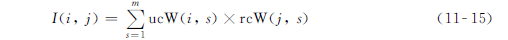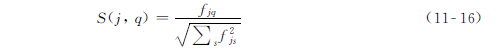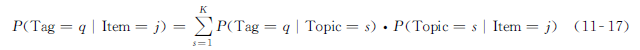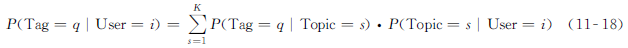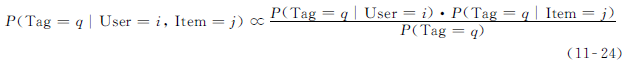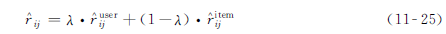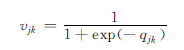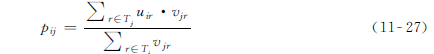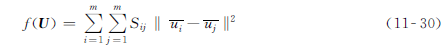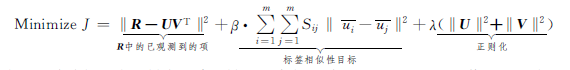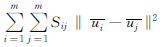文章作者:查鲁·C.阿加沃尔
编辑整理:Hoh
内容来源:《推荐系统原理与实践》
注:文末有赠书活动,欢迎参与~
导读:近年来,社会性标签系统使得用户能够以一种自由的描述方法对网络上的资源进行协同标记。这些描述也被称为大众分类法,它被表示为标签立方体。这些用户的描述十分有用,因为它们包含了有关用户兴趣的丰富知识。标签立方体既可以独立地被使用,也可以与评分矩阵相结合以提供推荐。前一类方法和推荐系统中的多维模型有相似之处。后一类方法可以是基于协作或基于内容的方法。目前已有各种不同的技术被提出,例如近邻法、线性回归和矩阵分解。
01
新一代网络,也被称为Web 2.0,已经支持许多开放式系统的发展,用户在其系统中能积极地参与并留下反馈。尤其是社会标签系统 ( social tagging system ) ,它们允许用户去创造和分享有关媒体对象的元数据。这样的元数据也被称为标签 ( tag )。用户可以给被社交网络支持的任何形式的对象做标签,比如图像、文档、音乐或录像。事实上,所有的社交媒体网站允许若干形式的标签。以下是一些标签系统的例子:
Flickr允许用户使用关键词去标记图像。例如,一个关键词可能描述了一个特定图像中的场景或物品。
网站"last fm"以音乐为主题,并允许用户标记音乐。
Dilicious促进了书签共享和在线链接的发展。
Bibsonomy系统允许用户共享并标记出版物。
Amazon网站曾允许其顾客标记物品。
去检验社会标签网站 ( 例如"last fm" ) 所创建的标签的本质是有启发意义的。关于迈克尔·杰克逊的著名唱片《战栗》,在"last fm"网站的热门标签如下:
"死前必听的1001张唱片"、"20世纪80年代"、"1982"、"1983"、"80年代流行"、"唱片"、"我所拥有的唱片"、"我所拥有的黑胶唱片"、"避开"、"经典"、"流行经典"、"摇滚经典"、"黑胶货箱"、"流行舞曲"、"迪斯科"、"史诗"、"战栗"…
因为这些标签是在一个开放的供人分享的环境下由用户而非专家所创建的,因此它们非常通俗日常。注意,"thirller" ( 战栗 ) 是一个错拼词,在这样的设置中,错拼是非常常见的。此外,所有歌曲按照其标签被创建了索引。例如,点击"摇滚经典"的标签,便可以访问与此标签有关的不同资源 ( 艺术家、唱片或事件 )。换言之,标签"摇滚经典"如同书签或索引一样,能用其访问相关资源。
这种标记过程,也被称为"大众分类法",导致了对内容的组织和对知识的构建。"大众分类法"这一术语源于它的词根"民间"和"分类学",因此该名字直观地表示了这一过程,即是由非专业人士、志愿者、参与者 ( 也就是普通民众 ) 在万维网上对网络对象的分类。这个名字是由Thomas Vander Wal提出的,他对这个词的定义如下:
"大众分类法是:由个人自由地标记被检索出的信息和对象 ( 任何附有URL网址的事物 ) 的结果。标签在一个社交环境 ( 通常是共享以及向他人开放的 ) 中完成。大众分类法是在人们在消费信息时对事物做标记而产生的。
这种外部标签的值来源于人们运用自己的词汇对事物添加明确的含义,这样的含义可能来自于人们对该信息/对象所推断出的理解。相比分类而言,人们更愿意根据自己的理解来提供信息/对象的含义,从而把信息/对象关联起来。"
另一个用于描述社会性标签的术语包括协作标记 ( collaborative tagging )、社会分类 ( social classification ) 和社会索引 ( social indexing )。
标签提供了对对象主题的理解,其常常是通用并易于理解的词汇。
因此,社会性标签的本质是:
其参与者实际上是一笔财产,它们为这样的系统做出了协同合作的贡献。
标签也被称为社会索引,因为它们还起到了组织物品的作用。
例如,通过点击一个标签,用户能够浏览和标签相关的物品。
大众分类法有许多的应用,包括推荐系统。
在特定应用下的推荐系统,大众分类法因为其提供了关于对象的可用知识而十分有价值。
尽管有时标签对对象的描述是有噪声的并且不太相关的,但至少每个标签都能被看作是描述对象的一个特征。
虽然标签具有噪声,但观察发现,通过对评分或其他数据源中的知识进行补充,社会标签法能显著提高推荐系统的有效性。
02
大众分类法的代表
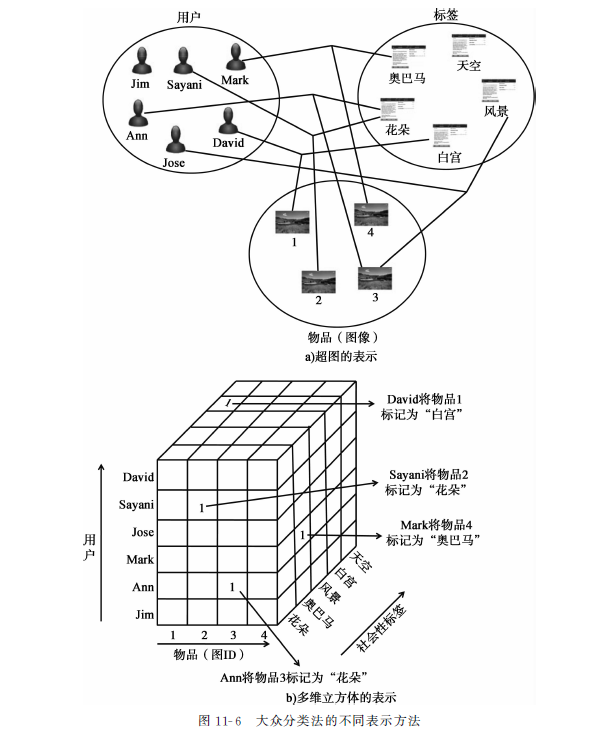
在标签系统中,用户用标签来注释物品 ( 或资源 )。而物品的特性取决于其所在的系统。比如对Flickr来说,其物品可能是一张图片,或者对last.fm来说,一个物品即是一首歌。因此,在用户、物品和标签之间存在着一种三方关系。相应地,它可以被表示成一个超图,其中每一个超边连接着三个对象。它也可以被表示为一个三维立方体 ( 或张量 ),其中包含着一个用户是否已经为一个特定物品 ( 如图像 ) 标记了一个特定的标签 ( 例如,"风景" ) 的一元二进制信息。如果标记了,则对应的位设为1,否则对应位设为未指定的 ( unspecified )。在许多情况下,为了分析的目的,我们将未指定的值约等于0。图中给出了一个由超图和张量表示的由6个用户、4个物品 ( 图像 ) 和5个标签构成的小例子。图a给出了超图的表示,而图b给出了三维立方体的表示。例如,Ann将物品2标记为"花朵",这在图a中则表示为对应三个实体之间的一条超边,而在图b中则表示为对应位被设置为1。大众分类法的形式化定义如下:
给定m个用户、n个物品和p个标签,其大众分类法是一个大小为m×n×p的三维数组F=[fijk],fijk是一个一元的数值,表明用户i是否将物品j标记为第k个标签。换言之,fijk的值被定义如下:
![]()
在实际设置中,未指定的值被默认设置为0,如果在高度稀疏的隐式反馈中的设置一样。今后,我们将用F表示 "标签立方体"。从下图可以看出,大众分类法和上下文敏感的推荐系统中的多维表示形式有很多共同点。我们在后面将会看到,这种共同点十分有用,因为可以用上下文敏感的推荐系统中的许多方法来处理其中一些查询。
尽管图中是一个小例子,而实际的社交平台上,用户和物品的数量会是数以亿计的,例如Flickr,而标签的数量大约有百万个。因此,这样的系统在数据丰富的环境中面临着可扩展性的挑战。对于社会性标签推荐系统来说,这样的问题既是我们的挑战,但同样也是机遇。
03
社会性标签系统中的协同过滤
推荐的形式依赖于应用的类型。
对一些网站,例如Flickr,其标签信息可用但评分信息并不可用。
在这样的情况下,仍可以开发一个基于标签立方体对标签或者物品进行推荐的系统。
在其他一些情况下,m×n的评分矩阵R和m×n×p的标签矩阵F都是可用的。
其评分矩阵和标签立方体都定义在相同的用户集合和物品集合上。
例如,MovieLens网站既包含了评分信息,也包含了标签信息。
其相应的协同过滤系统被称为标签已知的推荐系统,其中评分矩阵是主要数据,而标签信息则提供了额外的辅助信息来提高评分预测的精确度。
注意,评分矩阵可以是一个隐式反馈矩阵,例如对于网站lastfm,用户对物品的访问历史都被记录下来。
事实上,隐式反馈在社会性标签网站中更加普遍。
从算法角度来看,隐式反馈模型因其通常不包含负评分,未知项通常被设为是0作为近似,而更易使用。
在下文中,除非另作说明,我们将假设存在一个明确的评分矩阵。
当评分矩阵可用时,协同过滤查询的形式比只有标签信息可用时的查询形式要丰富很多。
在这种情况下,标签立方体和评分矩阵的用户和物品维度相同,但评分矩阵不包含标签这一维度。
为了提供推荐,这两处来源的信息被集成到一起。
值得注意的是,这一方法可以被看作是基于内容的协同过滤应用的泛化。
在基于内容的协同过滤中,关键词只与物品关联,然而在标签立方体中关键词与"用户物品"的组合关联。
可以将基于内容的推荐系统看成是标签立方体的一个特例,在这其中"物品标签"的二维切片对于每一个用户而言是完全相同的。
因此,后面章节讨论的许多方法也能被用于基于内容的协同过滤。
由于应用的多样性,协同过滤问题的形式也多种多样,而当前的研究工作并没有完全都涵盖。
实际上,仍有许多的协同过滤问题有待研究,正巧这也是近期的热门研究领域。
下面给出了一些查询的例子:
1. ( 只有标签数据 ) 给定一个m×n×p的标签立方体F,推荐:
-
-
给用户i一份有着相同兴趣 ( 标签模式 ) 的用户排序表。
-
-
-
2. ( 有标签数据和评分矩阵 ) 给定一个评分矩阵R和一个m×n×p的标签立方体F,推荐:
上述的查询可以被分成两类。
第一类查询并不使用评分矩阵。
在这样的查询中,对标签和用户的推荐比对物品的推荐更为重要,尽管其方法也可能被用于物品推荐。
因为标签充当着资源 ( 物品 ) 的书签和索引,所以寻找相关的标签也是寻找相关物品的一种方法。
第二类查询与传统推荐系统关联更紧密,因为它们主要是基于评分矩阵R。
与传统推荐系统唯一的不同之处在于,标签立方体被当作辅助信息使用,并因其中包含了噪声,故扮演着一个次等的角色。
这样的方法也被称为"标签推荐"或"提供标签的协同过滤"。
此类系统最主要的优势在于它们能将用户评分和标签活动的这两个重要的方面整合在一起。
一般来说,第二种类型的查询方法较少,但有越来越多的方法可以把评分矩阵和标签立方体的知识集成到一起。
值得一提的是,可能并没有明确的评分矩阵,可用的只有隐式反馈 ( 例如,购买行为 ),那么矩阵R就是一个一元评分矩阵。
注意,即使R是隐式反馈得来的,它仍然是独立于标签立方体的数据。
04
选择有价值的标签
由于对标签的创建和使用都是开放式的,因此标签通常有很多噪声。
在许多情况下,用户可能会使用不规范的词汇或错拼词去标记物品。
这就导致出现了很大比例的噪声和不相关标签。
若使用不相关的标签,将会对许多推荐应用产生有害的影响。
因此,预先挑选出一个小规模的标签会带来帮助。
从计算复杂性来说,对标签的预先选择也减少了数据挖掘过程中的计算。
因此,标签选择算法通常是基于简易的规则对标签进行排序并依据这些标准预先挑选出排在前面的标签。
许多标签网站会使用一种简单的方法,被称为"数量物品应用"。
该方法用给一个物品添加一个特定标签的人数来估计未来会有多少人愿意看到这个标签。
这个评估也可以看作是该标签的权重。
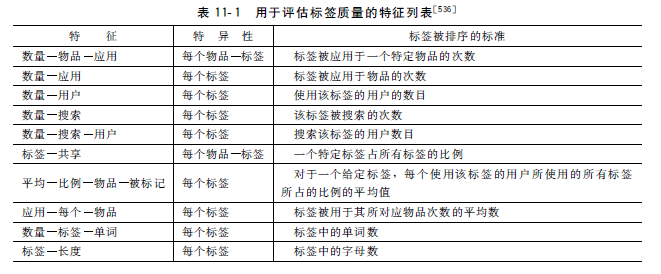
还有其他一些启发式的特征常常被用于评估标签的质量。
例如,一些标签可能是全局有价值的,而其他一些标签可能只针对特定物品。参考S.Len, J.Vig, and J.Riedl. Learning to recognize valuable tags
中提出了大量的这样的特征来评估标签的质量。下
表中列出了其中一些特征。
标签的特异性 ( 全局或局部 ) 也被指明。
值得一提的是,其中某些特征假设用户对标签进行了"喜欢"或"不喜欢"的评分。
这样的信息并不在所有系统中都有用,因此在下表中并没有包括这类特征。
实验结果发现:
在例如数量物品应用、标签共享和平均比例物品被标记这类特征上的推荐性能很好。
另一方面,对于其他一些特征,例如数量应用、数量用户和标签长度,其推荐性能并不是最佳。
进一步地,如果把5个最好的特征合并为一个特征,被称为"全部隐式",会使得系统的性能比使用单一特征时更好。
05
无评分矩阵的社会性标签推荐
这种情况也可以被看作是在上下文敏感推荐系统的多维模型的一个特例。
标签立方体可以被看作是一个多维立方体,其中标签表示上下文。
因此,上下文敏感模型可以用来解决这些查询。
事实上,从原则上讲,被用于上下文敏感排序的张量分解模型与标签推荐中的张量分解模型没有太大区别。
如前面所讨论的,在社会标签推荐中的查询可以有多种形式,可能是推荐物品、者标签或者用户。
标签立方体是三维的,且人们可能从各种维度上做推荐。
在这些不同的形式中,推荐标签是最常见的。
这样做的原因是推荐标签对用户和平台都是有益的:
对平台的效用:
由于标签不规范,不同的用户对同样的物品 ( 资源 ) 可以使用不同的关键词描述。对一个特定物品推荐标签有助于巩固其描述。这种隐式描述的巩固有助于系统收集更好的标签,因此需提高推荐的质量。
对用户的效用:
可能会根据一个物品向用户推荐标签,也可能根据用户的兴趣对用户推荐标签。基于物品的标签推荐的动机是:用户可能会觉得给物品添加标签很麻烦。当对一个给定物品推荐相关标签时,这使得他们的工作变得更容易,而且他们更有可能参与对物品标记的过程。相应地,系统也因此收集到更多的标签数据。对特定用户的标签推荐是有益的,因为标签的目的常常是对不同用户个性化地组织物品。例如,图11-6可能代表了如Flickr的图像浏览环境。如果根据Ann的其他标签,Ann被推荐了标签天空 ( sky ),通过点击这个标签,她可能会发现其他感兴趣的物品。也可以将标签数据与评分矩阵相结合,得到高质量的推荐。
以下部分回顾了已经提出的用于在社会标签系统的各类推荐方法。
采用多维方法可用于构建社会性标签推荐系统。
其基本思想是在查询的一对特定维度上对数据进行投影,然后在三个维度上使用基于内容查询的预过滤方法。
例如,为了给特定用户推荐最佳标签,可以对不同物品上的标签的频率做聚集。
换句话说,就是计算一个用户在所有物品上使用特定标签的次数。
这就产生了一个二维的用户标签的非负频率矩阵。
任何传统的协同过滤算法可以用在该矩阵上给特定用户来推荐标签。
这是给用户推荐标签的最好的方法,但它们不使用物品信息。
尽管如此,这种方法在现实生活中仍很有用。
由于标签还有索引功能,标签可以被用于发现用户感兴趣的资源。
类似地,沿标签维度对频率的聚集导致产生了一个用户物品矩阵。
这个矩阵能够被用于向用户推荐物品。
使用这些聚合方法的一个缺点是,沿着某一维的信息会被忽略。
也可以在推荐过程中,整合所有维度的信息。
假设我们要给一个特定用户推荐最佳的标签或最优的物品。
其中一种方法就是基于聚集的用户标签矩阵来计算用户之间的相似度。
同样,也可以在聚集的用户物品矩阵上做这样的计算。
两个测度的线性组合被用于生成一个和目标用户最相似的用户。
接着,可以使用标准预测方法来推荐最相关的物品或者最相关的标签。
类似的方法也可以被用于基于物品的协同过滤。
即从一个目标物品开始,根据聚集的用户物品矩阵或者聚集的标签物品矩阵,找到和它最相似的物品。
另一个有用的查询是针对某个特定标签的上下文向用户做物品推荐。
上下文敏感系统中的预过滤和后过滤方法可以被用于实现这一目标。
例如,如果想要推荐和标签"animation" ( 卡通片 ) 相关的电影,那么对应着"animation"的标签立方体的切片就可以被提取出来。
这个过程会产生一个关于卡通电影的二维的用户物品矩阵。
传统的协同过滤算法可以被用于该矩阵来做推荐。
使用该方法的一个挑战是所提取的用户物品切片可能会过于稀疏。
为了解决稀疏性问题,可以将相关的标签分成一组,即标签的聚类。
例如,一个标签类可能包含"animation""children" ( 儿童 ) "for kids" ( 给小孩的 ) 等。
这些相关标签对应的用户物品的标签频率可以被加和到一起构成一个聚集的用户物品矩阵,这比之前的矩阵要稠密。
从而可以在这个聚集的矩阵上做有效的推荐。
基于排名的方法使用PageRank的方法,以便在有标签的情况下做出推荐。
其中有两个著名的方法:
FolkRank和SocialRank。
FolkRank和SocialRank之间的主要区别在于,SocialRank在排名过程中还使用了对象之间以内容为中心的相似性。
例如,可能基于图像内容的相似性在两个图像之间添加链接。
此外,SocialRank可以被应用于任意的社交媒体网络,而不只是带标签的超图。
为了对不同形式的效果进行平衡,SocialRank算法相比PageRank算法有了显著的变化。
该方法也能被应用于大众分类 ( folksonomy )。
而FolkRank是专门为大众分类中带标签的超图而设计的。
在此我们将集中描述FolkRank方法。
FolkRank是个性化PageRank算法的简单调整。
应用FolkRank的第一步是从标签超图中提取一个三分图。
从标签超图中提取的三分图G=(N, A)描述如下:
然后在该网络上直接应用个性化的PageRank方法。
个性化向量被设置为:
喜欢的物品、用户或标签具有更高的重启概率。
通过对重启概率的不同设置方法,可以对特定的用户、标签、物品、"用户物品"对、"用户标签"对或"标签物品"对进行查询。
对查询响应的形式也可以不同。
作为这一进程的结果,高排名的标签、用户和物品对网络中相关结点提供了不同的观点。
FolkRank的一个重要特点是,它在特定用户相关性中加入了对全局流行度 ( 声望 ) 的考虑。
这是因为所有的排名机制倾向于选择高联通度的结点。
例如,即使在个性化的PageRank机制中,一个被大量使用的标签也总是被排得很靠前。
重启概率的值在特异性和普及性之间权衡。
为了取消这些因素产生的作用,差异版本的FolkRank被提出。
其基本思路是执行以下步骤:
PageRank在被提取出的三分图上进行无偏计算。换言之,所有结点的重启概率都是相同的值:1/(m+n+p)。回想一下,标签立方体的大小为m×n×p,网络中的结点数是 ( m+n+p )。令所得的概率向量为π1。
对于被查询的特定的"用户—物品"组合,个性化的PageRank设置一个增加的偏差。例如,考虑对一个特定"用户—物品"组合的查询。令被查询的用户结点的重启概率正比于(m+1)/(2m+2n+p),被查询的物品结点的重启概率正比于(n+1)/(2m+2n+p),剩余结点的重启概率正比于1/(2m+2n+p)。令所得的概率向量为π2。
结点的相关性可以从向量π2—π1中提取。其值可能为正也可能为负,这取决于相似性或不相似性的程度。
这种方法的主要优点是,它在很大程度上抵消了全局流行度的影响。
基于内容的方法既可以向用户推荐物品也可以向用户推荐标签。
为了将物品推荐给用户,可以创建一个特定用户的训练数据集,训练集中对每个物品的描述被表示成m个用户描述该物品所使用的标签的频率。
这些频率可以用tf-idf格式来表示。
对于一个给定的用户,其训练数据中包含所有标记的物品,和一个没有添加任何标签的物品的负样本。
这些对象的标记频率需要被学习。
特征变量和因变量 ( 学习处理过程中 ) 对应于每个物品的tf-idf表示,以及标签的用户给每个物品标记的标签数目。
注意到对负样本来说,因变量为0。
我们在该训练数据集上使用基于回归的模型来进行预测。
类似的方法可以用于推荐标签给用户。
其主要区别是标签被表示为物品的tf-idf向量而非其他形式。
训练集把标签当作对象进行分类。
因此,根据用户在不同物品上使用标签的次数,可以对标签进行标记。
这个训练集被用于在用户兴趣未知的情况下预测用户对标签的兴趣。
一个基于标签聚类的物品推荐算法:
该算法根据标签的tf-idf描述来创建簇。
换句话说,每个标签被视为物品频率的向量,然后这些向量被用于创建m个簇。
聚类为用户兴趣和物品之间的关联性的度量和集成提供了中间表示形式。
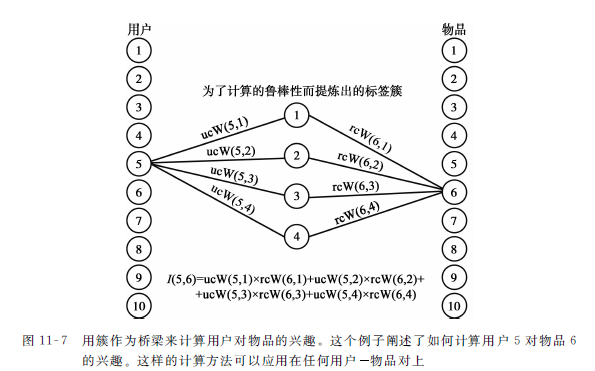
令第s个簇中的第i个用户的兴趣记为ucW(i,s),第j个物品 ( 资源 ) 和第s个簇的关联度被记为rcW(j,s)。
ucW(i,s)被定义为用户i所使用的标签在第s个簇所占的比例,rcW(j,s)被定义为物品j的标签在第s个簇中所占的比例。
那么用户i对物品j的总的兴趣I(i,j)的计算如下:
下图展示了如何把簇当作中间步骤来计算用户对物品的兴趣。
注意,这样的兴趣值可以被用作物品推荐排名。
其基本思想是簇为稀疏的用户物品标签行为提供了一个更具健壮性的总结,可以被用于高品质的兴趣计算。
此外,根据用户的标签查询向用户提供个性化的物品推荐。
例如,如果Mary搜索"动画",她得到的推荐电影可能和Bob搜索"动画"得到的推荐电影并不完全相同。
对于给定的查询标签q,它和物品j的相似度S(j, q)的定义如下,它是根据物品j被标记为标签q的频率fjq同物品j被标记为其他标签的频率相比较来定义的:
对于一个特定用户i的搜索,虽然S(j, q)的值也可直接被用于物品排名,但我们需要利用用户兴趣I(i, j)对结果进行个性化。I(i, j)的值使用公式 ( 11-15 ) 计算。因此,查询结果按照S(j, q)×I(i, j)而非S(j, q)排序。值得注意的是,对标签查询的物品推荐不一定需要对特定用户进行个性化,我们可以简单地使用S(j, q)来排序物品。进一步地,对物品推荐标签也同样不需要进行个性化。可以简单使用物品的标签特征为用户做推荐。在这种情况下,被推荐的标签取决于被查询的物品,而不会依赖于进行查询的用户。事实上,最早的关于标签推荐的研究工作就使用标签和物品同时出现的统计信息来做推荐。因此,其结果也并不依赖提出查询的用户。
类似地,还有一种以内容为中心的使用潜在狄利克雷分布模型 ( LDA ) 的推荐方法。
该方法把每个物品看作一个包含标签 ( 或"单词" ) 频率的"文档"。
和传统的文档主题生成模型类似,该方法按下面的关系表示了第q个标签和物品j的关联:
在这里,K表示主题的数量,这是一项由用户定义的参数。
注意到公式 ( 11-17 ) 的左边提供了一个以排序为目的的推荐概率,而右边的量可以通过LDA方法中的参数学习来进行评估。
没有必要使用LDA做主题建模。
例如,可以用更简单的概率隐语义分析 ( PL-SA ) 模型来替换LDA。
注意,我们也可以把用户所使用的标签看作"文档",利用主题建模方法对这些用户按照主题进行聚类,从而实现推荐的个性化。
在确定了主题以后,我们可以按如下方法计算不同标签和每个用户的关联度:
注意,公式 ( 11-18 ) 相较于公式 ( 11-17 ) 使用了一个不同的主题集合,前者对用户聚类,而后者
对物品聚类。
给定用户i的个性化内容,公式 ( 11-17 ) 和公式 ( 11-18 ) 的线性组合可以被用来确定标签q和物品j的相关性。
这一线性组合的权重确定了用户特异性和物品特异性之间的权衡。
还有一些其他的方法,通过在主题建模过程中利用贝叶斯的思想来组合用户特异性和物品特异性
。
特别地,我们可以直接计算个性化的和特定物品的推荐概率P(Tag=q|User=i,Item=j)。
使用朴素贝叶斯规则,可以将此概率简化为如下:
注意到,以上我们忽略了分母的项:
P(User=i,Item=j)。
这是因为我们希望在特定用户和物品的情况下,按照标签推荐概率来排列不同的标签。
因此,这一常数项可以在排序过程中被忽略。
现在,上述公式右手边的P(User=i|Tag=q)和P(Item=j|Tag=q)可以依据用户推荐概率和物品推荐概率,运用贝叶斯规则表示为:
因此,将这些项代入公式 ( 11-21 ) 中,我们可获得如下:
类似于任何贝叶斯分类器,公式右边的项可以很容易地以数据驱动的方式被估计。
例如,P(Tag=q)的值可以被估计为标签立方体中第q个标签对应的非空项所占的比例。
P(Tag=q|User=i)的值可以被估计为标签立方体中用户i对应切片上第q个标签所对应的非空项所占的比例。
P(Tag=q|Item=j)的值可以被估计为标签立方体中物品j对应切片上第q个标签所对应的非空项所占的比例。
拉普拉斯算符也经常用于避免过度拟合。
06
使用评分矩阵的社会性标签推荐
当标签作为物品评分的附加信息被加入系统时,它对提高推荐的质量具有巨大的潜力。
例如,设想一个情节,Mary已观看了《Shrek》和《Lion King》这样的许多被评分网站 ( 例如IMDb ) 标记为"动画"的电影。
然而,Mary也许还未在标签立方体中标记任何这样的电影,这些喜好是通过评分矩阵得到的。
现在设想一个情景,有一部电影,例如《Despicable Me》,也被标记为"动画",但Mary并没有看过这部电影。
在这样的情况下,可以合理地猜测Mary可能会对《Despicable Me》感兴趣。
即使评分矩阵也提供了同样的预测,但是当加入标签信息的时候其预测的错误率降低了。
这是因为标签提供了独立于评分数据的信息。
尤其是对于新电影来说,往往没有足够的评分或者标签来对用户的喜好做预测。
在这样的情况下,评分和标签可以互补,使其做出更有健壮性的判定。
在绝大多数的情况下,标签系统在评分矩阵中包含了隐式评分 ( 例如用户是否浏览过一个物品 )。
这是因为像"last.fm"这样的网站能够自动地将用户对物品的浏览记录保存下来。
注意,隐式评分是一项独立的信息来源,因为一个用户可能浏览过一个物品,但却没有对它进行标记。
在这一节中,我们将学习隐式和显式评分这两种情况。
一种最直接的方法是使用混合式推荐系统将基于标签的预测和基于评分的预测进行结合。
例如,在第5节中讨论的任何方法,可以被用于基于标签做预测。
此外,任何传统的协同过滤算法可以进行基于评分的预测。
对两类评分的加权平均可以被用于做最终的预测。
权重可以使用混合式推荐系统中讨论的方法来学习。
然而,这样的方法并未将两个来源的预测密切地统一起来。
将不同来源的数据密切统一的算法可能会获得更好的结果。
参考Tag-aware recommender systems by fusion of collaborative filtering algorithms 中的方法适用于隐式反馈数据集,其评分矩阵被设为一元的。
这在社会性标签系统中很常见。
例如,在像诸如"last.fm"的网站中,用户对物品的访问记录是可获取的,但显式的评分不能被获取。
此论文中将未知项设为0。
因此,评分矩阵R被看作一个二元矩阵而非一元矩阵。
通过创造附加的伪用户和伪物品,Tag-aware recommender systems by fusion of collaborative filtering algorithms利用m×n×p标签立方体F的数据对m×n的评分矩阵R进行增广。例如,可以在基于扩展物品集的评分矩阵上使用基于用户的协同过滤。为了创建一个物品维度被扩展的评分矩阵R
1
,每一个标签被看作是一个伪物品。此外,如果用户至少使用了一次该标签 ( 可年能对多个物品而言 ),那么用户标签组合的值被设为1。否则,该值被设为0。注意,一共有m×p个用户标签组合。通过将标签看作新的伪物品,可以将m×p个组合添加到m×n的评分矩阵后面。这就产生了一个大小为m×(n+p)的扩展的矩阵R1。可以利用这个扩展矩阵来计算用户i和其他用户的相似度。因为附加列上包含了用户标签的活动信息,所以用于相似度计算的信息得以丰富。用户i对物品的评分通过i的相似用户群对应1的个数来计算。预测评分
r
ijitem
被归一化,使得它们表示访问 ( 或购买 ) 不同物品的概率。注意,在隐式反馈中评分表示了活动的频率。
可以用类似的方法来扩展基于物品的方法。
在这个情况下,一个p×n的对应"标签物品"组合的矩阵被创造出来。
如果物品被某标签标记过至少一次,那么此矩阵中的值为1。
现在标签被看作是伪用户,因此在原始评分矩阵R上需要附加行。
这导致了一个大小为(m+p)×n的扩展矩阵R2。
这一扩展矩阵被用于执行基于物品的协同过滤的相似度计算。
然后对于一个给定的用户i,预测评分rijitem将被归一化,使它们在所有j上求和为1。
因此,在这个情况中,预测的评分也表示了访问或购买物品的概率。
在完成基于用户的和基于物品的协同过滤后,通过一个参数λ∈(0,1)将两种评分预测进行如下融合:
λ的最优值可使用交叉验证法来选择。
Tag-aware recommender systems by fusion of collaborative filtering algorithms 中的结果展示了加入标签信息后对传统协同过滤的性能的提升。
为了实现标签信息的嵌入,将基于用户的和基于物品的方法进行融合是必不可少的。
在推荐过程中使用了线性回归的方法来嵌入标签信息。
相比用户评分,标签在识别用户喜好方面的精确性较差,因此选取对于推荐过程中唯一有价值的标签是十分重要的。
为了达到这个目标,可以利用第3节所描述的方法。
这里采用的基本方法是通过融合用户评分的信息来补充用户对不同物品的标签的喜好信息。
例如,如果一个用户已对《Lion King》和《Shrek》有了高评分,且两部电影都被标记为"动画",那么可以推测出这个用户很有可能对于这一标签的电影感兴趣。
该方法的第一步是确定物品和标签之间的相关性权重。
例如,在刚刚的表中任何"物品标签"的特定概率可以被当作相关性权重。
设qjk是物品j对于标签k的相关性,第二步是用s型函数将其转化成物品对标签的偏好值:
之后,结合"标签物品"关联性和用户对于物品的兴趣,来计算用户i对于标签k的偏好uik。
可以使用评分矩阵R=[r
ij
]来推导出用户对物品的偏好。
用户i对标签k的偏好u
ik
可以按如下推导:
以上公式的分子和分母中忽略了没有被用户i评分的物品。
当评分不可用时,u
ik
的值也可以通过用户的访问、点击、购买、给物品做标签的频率的相关信息间接推导出。
例如,在公式 ( 11-26 ) 中r
ij
的值可以为用户对物品j标记的次数 ( 并不一定是标签k )。
一个预测物品j对用户i的偏好值pij的简单方法是:
确定物品j上的所有标签的集合Tj,并对T
j
中所有标签r求u
ir
的平均值:
注意,p
ij
的值可能不在评分的取值范围中。
尽管如此,仍然可以利用pij对物品进行排序。
一个预测评分更加有效的方法是使用线性回归。
其基本思路是假设用户i对物品j的评分r
ij
是基于一个线性关系,当固定j,把i当作变量时,这个假设是成立的。
其中 ( 未知 ) 系数w
jr
表示标签r对于物品j的重要度,且它能通过对物品j的所有已知评分用回归方法学习得到。
它与公式 ( 1-27 ) 中最主要的不同点在于,对标签r不再使用一个启发式的权重值v
jr (
对物品j ),而是在评分矩阵上使用线性回归学习得到权重值w
jr
。
该方法因其更好的监督性而更为优胜。
因为回归训练过程中使用了所有用户对物品j的评分,所以这一方法运用了不同用户评分的协作力量。
此外,相比传统的协同过滤算法,这一方法具有更好的结果,因为它在推荐过程中使用了标签这一辅助信息。
在一个混合系统中,如果将这一方法和一个简单的矩阵分解法相结合则会产生更好的结果。
研究结果表明在训练过程中回归支持向量机方法的结果最佳,而最小二乘法回归可作为一个简单的替代。
一种矩阵分解的方法被称为TagiCoFi
,可以将评分矩阵R近似分解为两个矩阵,一个m×q的矩阵U和一个n×q的矩阵V。
此条件可以被表达为如下:
对R中的已观测项,可以通过对Frobenius范数g(U, V, R)=‖R-UV
T
‖
2
近似最小化来实现该条件。
另外,一种相似性约束被应用于用户因子矩阵U,使得有相似标记行为的用户有着相似的因子。
令S
ij
为用户i和j之间的相似性,并令u
i
为U的第i行。
为了确保有着相似标记行为的用户有着相似的因子,我们想要将下列相似性目标函数f(U)最小化:
因为有两个不同的目标函数g(U, V, R)和f(U),我们引入平衡参数β,用于将g(U, V, R)+βf(U)最小化。
此外,我们在矩阵分解 ( 对Frobenius范数求和 ) 中有标准正则项,其正则项为λ(‖U‖
2
+‖V‖
2
),λ为正则化参数。
将这些不同的项求和,我们将获得以下目标函数:
在所有的矩阵分解法中,梯度下降法被用于求解矩阵U和V。
β和λ的值可以用交叉验证法来计算。
值得注意的是,此法在技术上与信任推荐系统中的社会正则法
相似。
在其方法中,一个信任矩阵T被用于在目标函数中增加相似项∑i,j:t
ij>0
t
ij
‖u
i
-u
j
‖
2
。
换句话说,在用户i和j之间的信任/趋同性被用户i和用户j之间的标签相似性Sij所替换。
因此,相同技术模型的较小变化可以被用于解决不同的社交推荐场景。
此外,与其要求基于标记行为的用户因子更加相似,我们也可以要求基于标记行为的物品因子更加相似。
上述方法需要计算用户i和用户j之间的标签相似性S
ij
。
首先,由标签立方体F生成tf-idf矩阵,其中用户使用一个特定标签的次数被计算出来。
换句话说,所有特定的"用户标签"组合的1的个数被求和。
因此,对每个用户会生成一个频率向量。
然后,利用信息检索中的标准tf-idf归一化方法将该频率归一化。参考TagiCoFi: tag informend collaborative filtering
中提出了几种计算相似性的不同方法:
Pearson相似性:
Pearson相关系数ρ
ij
是根据用户i和用户j使用的所有标签计算得出。两者都未使用的标签忽略不计。Sigmoid函数被用于将相关系数转化为一个在(0,1)的非负相似性S
ij
:
余弦相似性:
频率向量之间的标准余弦相似性被用作相似度值。
欧几里得相似性:
欧几里得距离d
ij
在相似性向量之间计算,然后用一个高斯函数将欧几里得距离转化为一个取值在(0,1)的相似度值:
在这里,σ是一个用户控制的参数,可以通过交叉验证来选择该参数。
在TagiCoFi: tag informend collaborative filtering的结果
中,Pearson相似性表现最优,欧几里得相似性表现最差。
社会性标记方法对使用基于内容的方法提供了一个直截了当的途径。
对于一部电影的标签的频率向量可以被看作是对该电影的描述。
用户对电影做出的评分可以被看作是用标签定义的特征空间上的训练样本。
评分被看作标签类。
通过该训练样本可以构建特定用户的训练模型。
该模型被用于预测用户对其他电影的评分。
使用分类还是回归模型取决于评分是一元的还是基于区间的。
这样基于内容的模型也可以与任何上述的协同系统相结合。
介绍一种在IMDb数据集上的简单的基于内容的推荐模型。
它使用标签云的概念来表示基于标签的电影描述。
各个关键词根据其相关性加权,然后和用户评分结合,以做出最终的预测。
使用基于内容的方法的一个挑战是,大量同义性词导致了标签的噪声很大。可以
使用语言学方法消歧,然后与朴素贝叶斯分类法相结合。
此外,利用特征选择法去提高表达质量也是十分有益的。
注:为了保证阅读的流畅性,本文略有删减,参考资料请参见原书。
《推荐系统:原理与实践》
在文末分享、点赞、在看,给个三连击呗~~
推荐系统是一种预测用户对商品和信息的喜好的模型,可以帮助用户发现自己感兴趣的信息和商品。
构建推荐系统时,既要考虑效率,也要考虑有效性;
既要考虑用户心理,也要考虑用户的行为;
既要考虑商品和信息的外在属性,又要考虑商品和信息的相互关联。
由于其综合性和复杂性,推荐系统可以看成是数据库、自然语言处理、机器学习、信息检索、算法甚至心理学等领域的综合与交叉。
本书从上述庞杂知识领域中梳理出一个完整的知识体系,有助于初学者系统地学习推荐系统知识。
福利时间:本期活动为大家带来5本正版新书。在文末留言区留言谈谈你对推荐系统的理解,2020年7月16日20点前,我们将在评论点赞超过5
的留言中选取
5
个最有意思的评论
,赠送正版图书1本。赠书由机械工业出版社华章公司提供,在此表示感谢。注:等不及的小伙伴也可以点击下面的购买按钮直接拿下哦。
大会推荐:
一年一度的DataFun大会上线啦,100余位嘉宾参与的干货分享,点击图片了解详情哦!
![]()
关于我们:
DataFunTalk 专注于大数据、人工智能技术应用的分享与交流。发起于2017年,在北京、上海、深圳、杭州等城市举办超过100场线下沙龙、论坛及峰会,已邀请近500位专家和学者参与分享。其公众号 DataFunTalk 累计生产原创文章300+,百万+阅读,6万+精准粉丝。
![]()
🧐分享、点赞、在看,给个三连击呗!👇