机器之心 & ArXiv Weekly Radiostation
参与:杜伟、楚航、罗若天
本周的重要论文包括字节跳动发布的全球最大钢琴 MIDI 数据集,以及谷歌新型 Performer 架构。
GiantMIDI-Piano: A large-scale MIDI dataset for classical piano music
A survey of embedding models of entities and relationships for knowledge graph completion
Optimal Subarchitecture Extraction For BERT
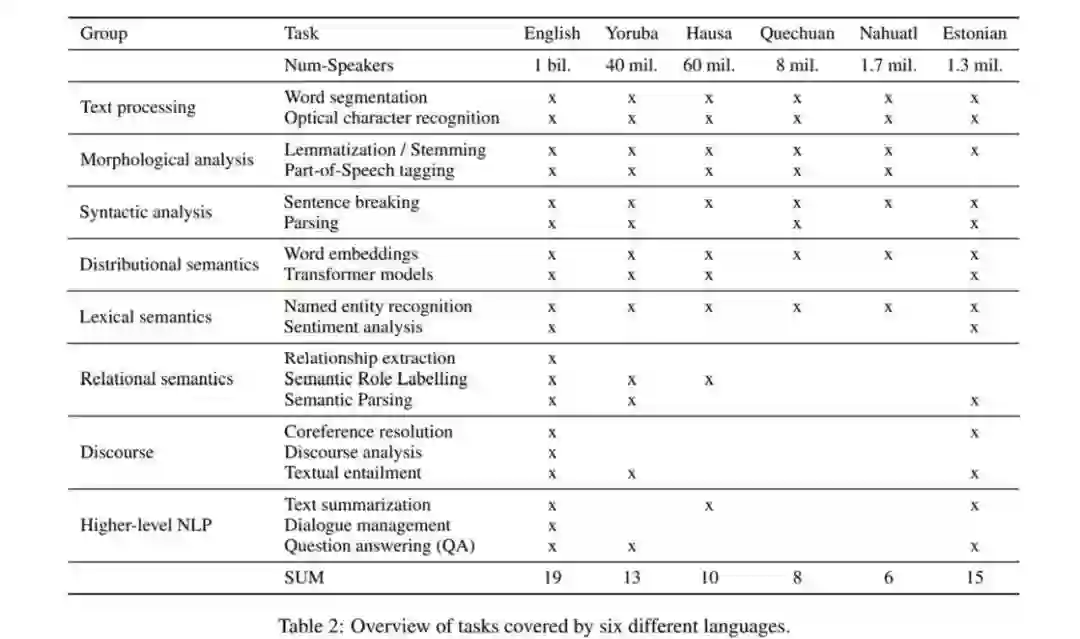
A Survey on Recent Approaches for Natural Language Processing in Low-Resource Scenarios
Rethinking Attention with Performers
Learning Invariances in Neural Networks
Overview of Graph Based Anomaly Detection
ArXiv Weekly Radiostation:NLP、CV、ML 更多精选论文(附音频)
论文 1:GiantMIDI-Piano: A large-scale MIDI dataset for classical piano music
摘要:
钢琴转谱是一项将钢琴录音转为音乐符号(如 MIDI 格式)的任务。在人工智能领域,钢琴转谱被类比于音乐领域的语音识别任务。然而长期以来,在计算机音乐领域一直缺少一个大规模的钢琴 MIDI 数据集。
近期,
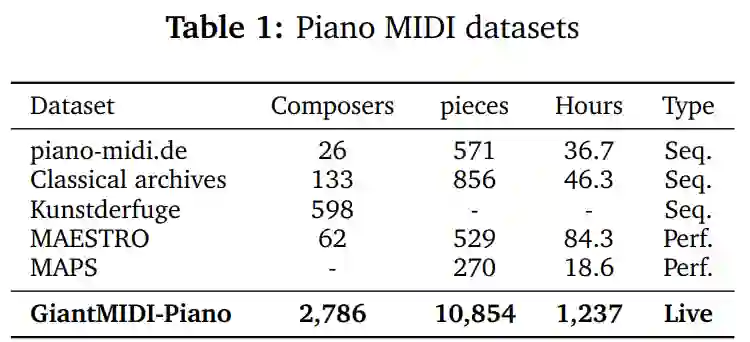
字节跳动发布了全球最大的古典钢琴数据集 GiantMIDI-Piano 。在数据规模上,数据集不同曲目的总时长是谷歌 MAESTRO 数据集的 14 倍
。GiantMIDI-Piano 的用途包括但不限于:音乐信息检索、自动作曲、智能音乐创作、计算音乐学等。
![]()
![]()
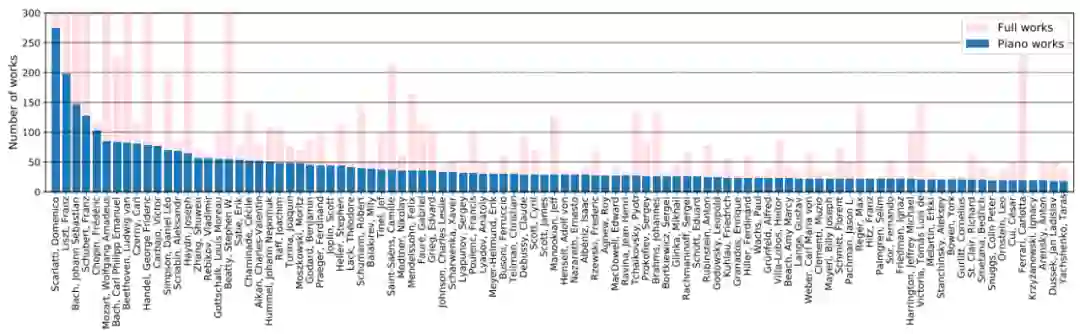
GiantMIDI-Piano 中前 100 位不同作曲家的曲目数量分布。
![]()
推荐:
字节跳动研究科学家表示:「GiantMIDI-Piano 将所有古典钢琴作品转录成 MIDI 格式,并向全世界开放,此举旨在推动音乐科技和计算机音乐学的发展」。
论文 2:A survey of embedding models of entities and relationships for knowledge graph completion
摘要:
对于多样化语言处理任务而言,有关实体及其关系事实的知识图谱(KG)是非常有用的资源。但是,由于知识图谱通常不完备,所以执行知识图谱补全(knowledge graph completion)或链路预测(即预测不在知识图谱中的关系是否有可能是真的)有助于弥补知识图谱的不足。
在本文中,
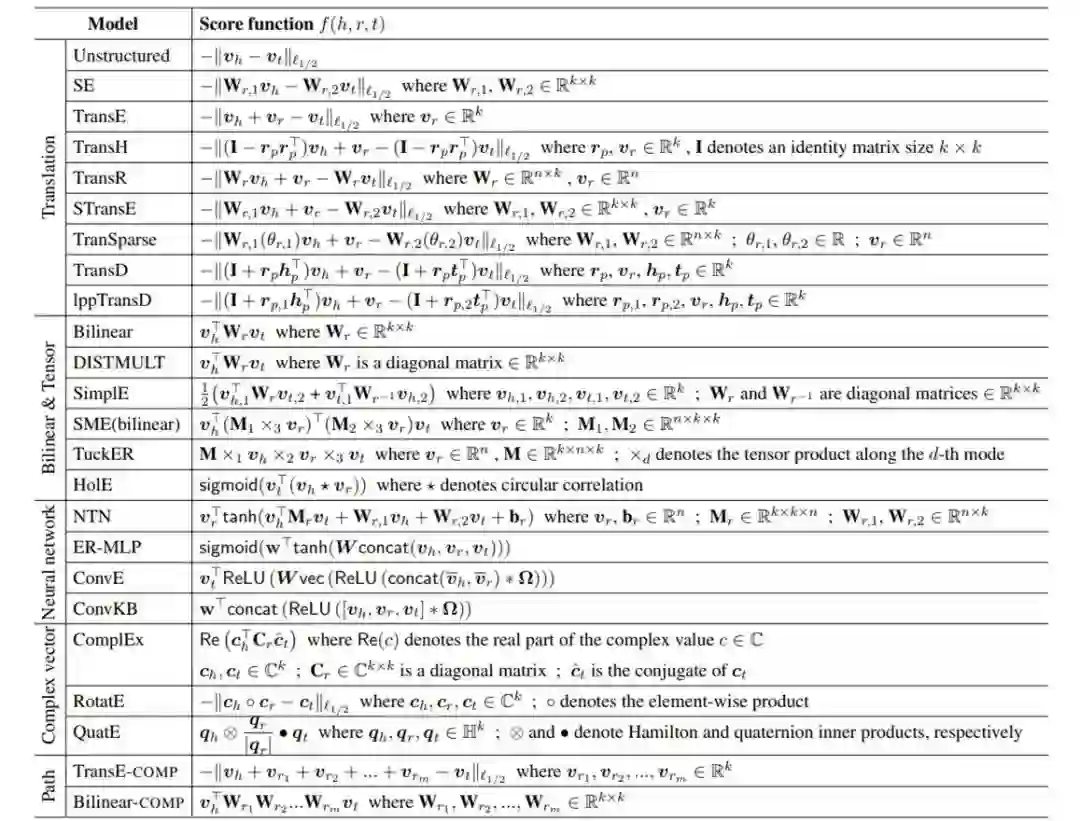
来自 VinAI 人工智能研究所的学者 Dat Quoc Nguyen 对用于知识图谱补全的实体和关系嵌入模型展开了全面综述,总结了标准基准数据集上最新的实验结果,并指出了未来潜在的研究发展方向
。
![]()
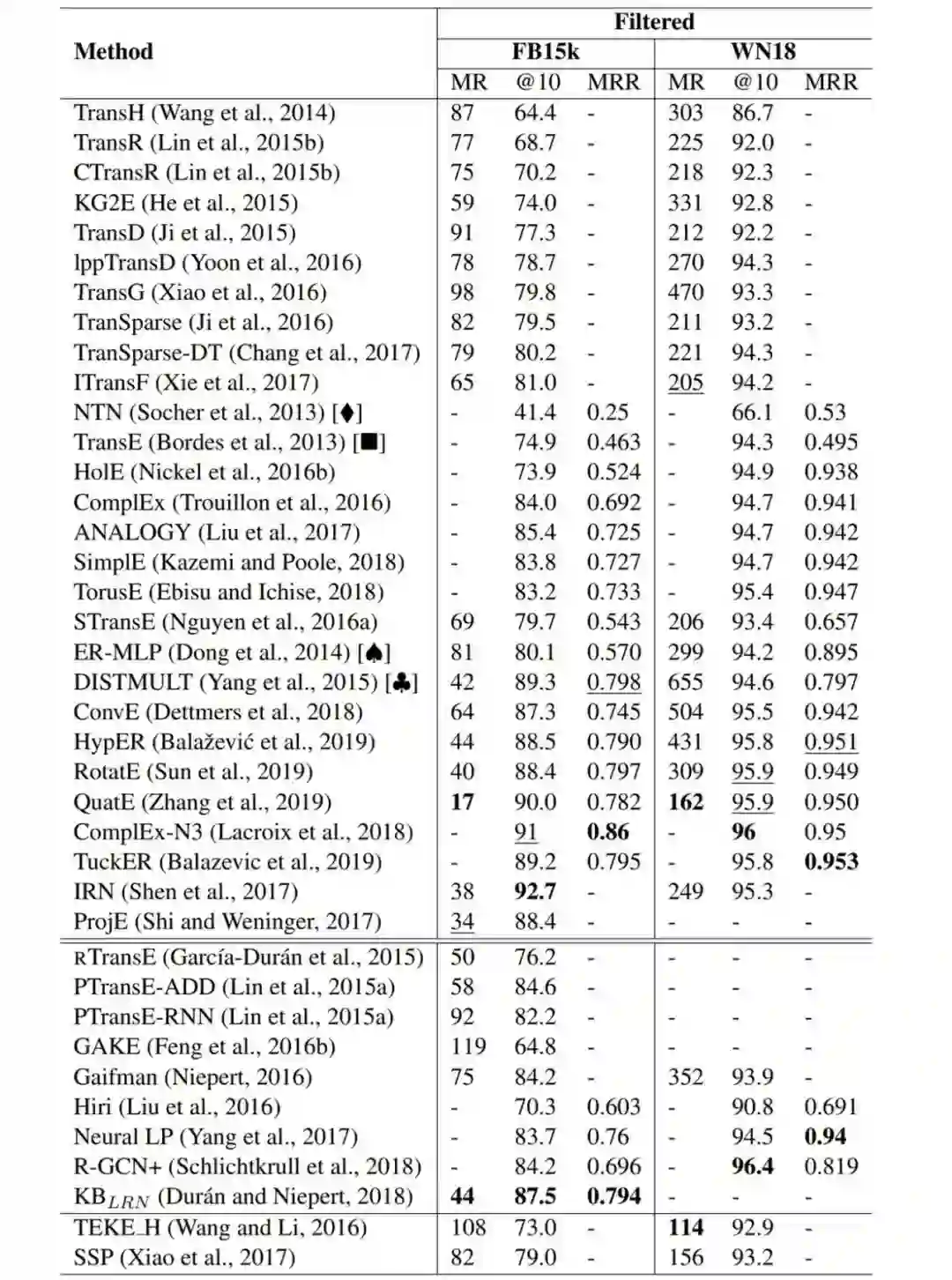
知识图谱补全嵌入模型的评分函数 f(h, r, t)。
![]()
![]()
WN18 和 FB15k 基准上实体预测结果比较。
推荐:
本文作者 Dat Quoc Nguyen 为 VinAI 人工智能研究所的高级研究科学家。
论文 3:Optimal Subarchitecture Extraction For BERT
摘要:
在本文中,来自 Amazon Alexa 团队的研究者将提取 BERT 最优子架构参数集这一问题细化为三个指标:推断延迟、参数大小和误差率。该研究证明:BERT 具备 strong AB^nC 属性,可满足这些条件组合,使上述算法表现得像 FPTAS。然后,研究者
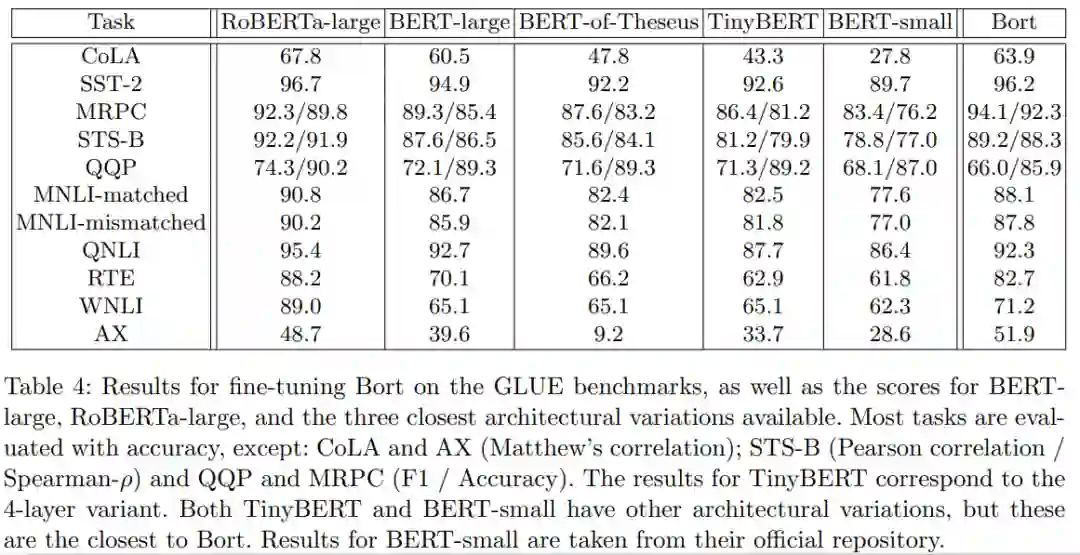
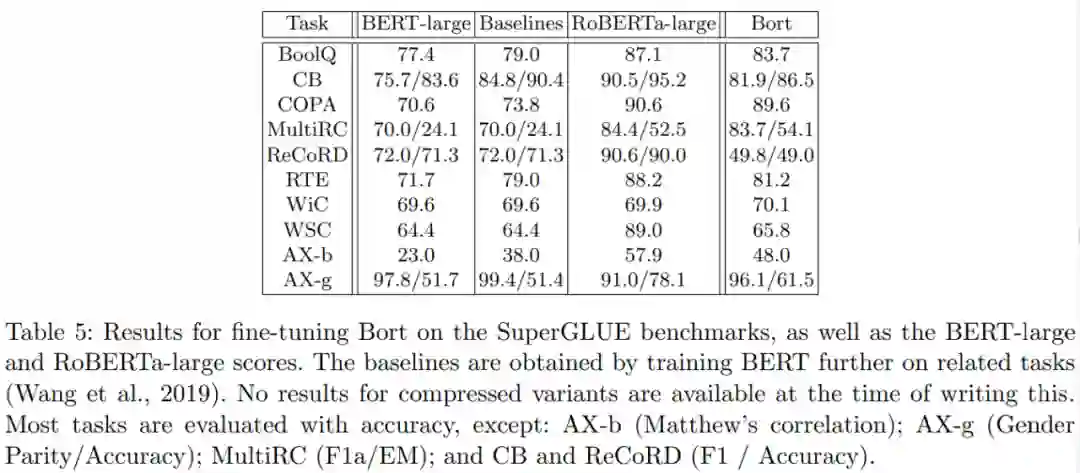
从一个高性能的 BERT 变体中提取了一个最优的子架构,称为 Bort,其大小是 BERT-large 的 16%,在 CPU 上的推理速度提升到原来的 8 倍
。
研究者还在 GLUE、SuperGLUE 以及 RACE 公共 NLU 基准上对 Bort 进行了评估。结果表明,与 BERT-large 相比,Bort 在所有这些基准上都获得了显著提高,提升幅度从 0.3% 到 31% 不等。
![]()
![]()
![]()
推荐:
研究者已经在 GitHub 上开源了训练模型以及代码。
论文 4:A Survey on Recent Approaches for Natural Language Processing in Low-Resource Scenarios
摘要:在本文中,基于神经模型的基础变化以及当前流行的预训练和微调范式,
来自德国萨尔兰大学和博世人工智能中心的研究者概述了低资源自然语言处理的有前途方法
。他们首先讨论了低资源场景的定义和数据可用性的不同维度,然后研究了训练数据稀疏时赋能学习的方法。这包括创建数据增强和远程监督等附加标签数据的机制以及减少目标监督需求的可迁移学习设置。
![]()
![]()
多语言 transformer 模型涵盖的 100 万 speaker 以上的语系。
![]()
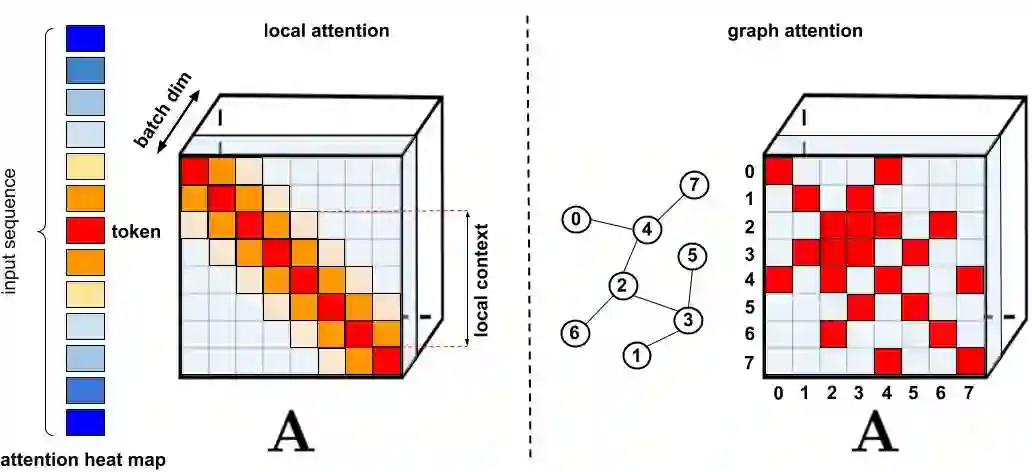
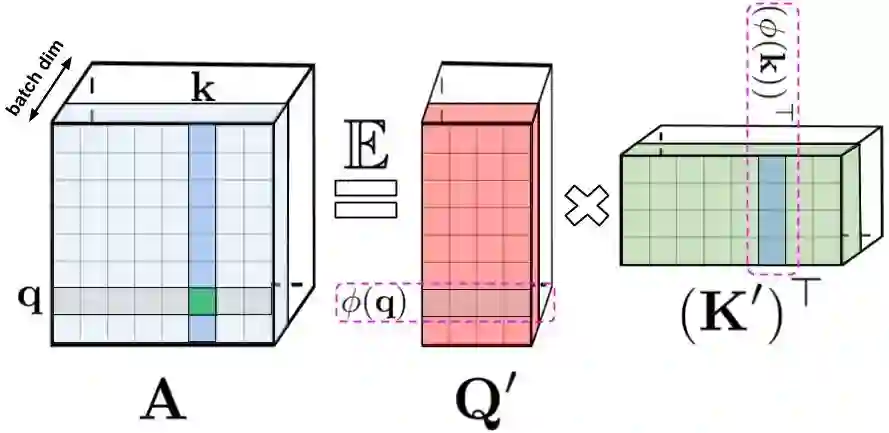
论文 5:Rethinking Attention with Performers
摘要:
来自
谷歌、剑桥大学、DeepMind、阿兰 · 图灵研究所的研究者提出了一种新的 Transformer 架构——Performer
。它的注意力机制能够线性扩展,因此能够在处理长序列的同时缩短训练时间。这点在 ImageNet64 等图像数据集和 PG-19 文本数据集等序列的处理过程中都非常有用。
Performer 使用一个高效的(线性)广义注意力框架(generalized attention framework),允许基于不同相似性度量(核)的一类广泛的注意力机制。该框架通过谷歌的新算法 FAVOR+( Fast Attention Via Positive Orthogonal Random Features)来实现,后者能够提供注意力机制的可扩展低方差、无偏估计,这可以通过随机特征图分解(常规 softmax-attention)来表达。该方法在保持线性空间和时间复杂度的同时准确率也很有保证,也可以应用到独立的 softmax 运算。此外,该方法还可以和可逆层等其他技术进行互操作。
![]()
![]()
标准注意力矩阵包括每一对 entry 的相似度系数,由 query 和 key 上的 softmax 计算组成,表示为 q 和 k。
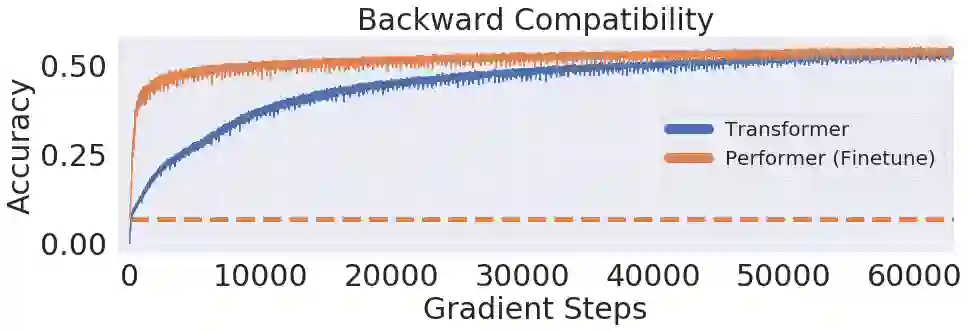
![]()
在 One Billion Word Benchmark (LM1B) 数据集上,研究者将原始预训练 Transformer 的权重迁移至 Performer 模型,使得初始非零准确度为 0.07(橙色虚线)。但在微调之后,Performer 的准确度在很少的梯度步数之后迅速恢复。
推荐:
这一方法超越了注意力机制,甚至可以说为下一代深度学习架构打开了思路。
论文 6:Learning Invariances in Neural Networks
摘要:
平移的不变性(invariance)为卷积神经网络注入了强大的泛化性能。然而,我们常常无法预先知道数据中存在哪些不变性,也不清楚模型在多大程度上对指定对称群保持不变。
在这篇论文中
,来自纽约大学柯朗数学科学研究所的研究者向读者展示了,如何通过参数化增强分布以及优化网络和增强参数的训练损失来学习不变性和同变性
。通过这一简单过程,我们可以仅通过训练数据从规模较大的增强空间中恢复图像分类、回归、分割和分子性质预测的正确集和不变性范围。
![]()
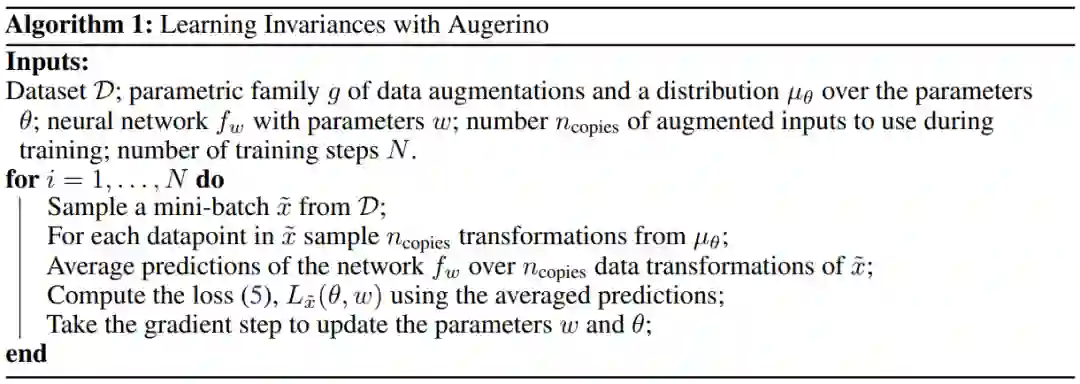
研究者通过所提方法 Augerino 学习不变性的算法 1。
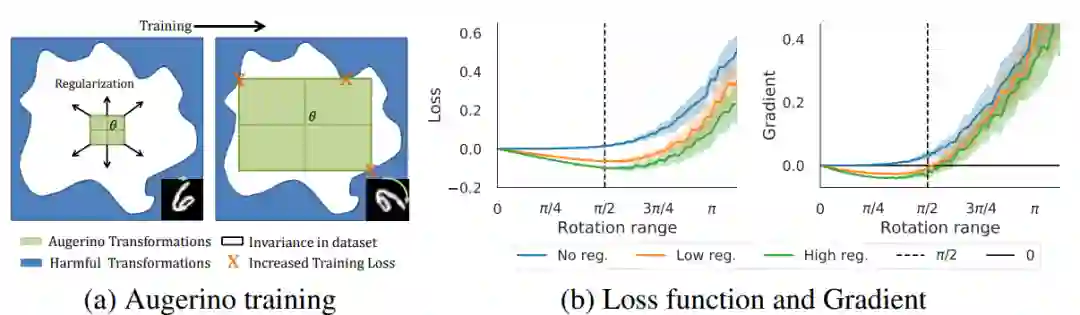
![]()
(a)Augerino 训练示意图;(b)损失函数和梯度变化曲线图。
![]()
当训练数据应用不同的增强时,CIFAR-10 数据集上训练模型的测试准确度结果比较。
推荐:
研究者表示,Augerino 是首个不需要验证集或特殊损失函数的情况下,仅通过训练数据即可以在神经网络中学习对称性的方法。
论文 7:Overview of Graph Based Anomaly Detection
摘要:
近年来,随着 web2.0 的普及,使用图挖掘技术进行异常检测受到人们越来越多的关注. 图异常检测在欺诈检测、入侵检测、虚假投票、僵尸粉丝分析等领域发挥着重要作用。
本文在广泛调研国内外大量文献以及最新科研成果的基础上,按照数据表示形式将面向图的异常检测划分成静态图上的异常检测与动态图上的异常检测两大类,进一步按照异常类型将静态图上的异常分为孤立个体异常和群组异常检测两种类别,动态图上的异常分为孤立个体异常、群体异常以及事件异常三种类型。对每一类异常检测方法当前的研究进展加以介绍,对每种异常检测算法的基本思想、优缺点进行分析、对比,总结面向图的异常检测的关键技术、常用框架、应用领域、常用数据集以及性能评估方法,并对未来可能的发展趋势进行展望。
![]()
![]()
![]()
ArXiv Weekly Radiostation
机器之心联合由楚航、罗若天发起的ArXiv Weekly Radiostation,在 7 Papers 的基础上,精选本周更多重要论文,包括NLP、CV、ML领域各10篇精选,并提供音频形式的论文摘要简介,详情如下:
1. On the Transformer Growth for Progressive BERT Training. (from Jiawei Han)
2. Retrieve, Rerank, Read, then Iterate: Answering Open-Domain Questions of Arbitrary Complexity from Text. (from Christopher D. Manning)
3. DeSMOG: Detecting Stance in Media On Global Warming. (from Dan Jurafsky)
4. Understanding the Extent to which Summarization Evaluation Metrics Measure the Information Quality of Summaries. (from Dan Roth)
5. A Scalable Framework for Learning From Implicit User Feedback to Improve Natural Language Understanding in Large-Scale Conversational AI Systems. (from Young-Bum Kim)
6. Generating Plausible Counterfactual Explanations for Deep Transformers in Financial Text Classification. (from Yi Yang, Barry Smyth)
7. BARThez: a Skilled Pretrained French Sequence-to-Sequence Model. (from Michalis Vazirgiannis)
8. Meta-Learning for Domain Generalization in Semantic Parsing. (from Mirella Lapata)
9. MTGAT: Multimodal Temporal Graph Attention Networks for Unaligned Human Multimodal Language Sequences. (from Louis-Philippe Morency)
10. ERNIE-Gram: Pre-Training with Explicitly N-Gram Masked Language Modeling for Natural Language Understanding. (from Yu Sun)
1. SAHDL: Sparse Attention Hypergraph Regularized Dictionary Learning. (from Yan-Jiang Wang)
2. DLDL: Dynamic Label Dictionary Learning via Hypergraph Regularization. (from Yan-Jiang Wang)
3. Hard Example Generation by Texture Synthesis for Cross-domain Shape Similarity Learning. (from Dacheng Tao)
4. Unsupervised deep learning for grading of age-related macular degeneration using retinal fundus images. (from Stella Yu)
5. Lightweight Generative Adversarial Networks for Text-Guided Image Manipulation. (from Philip H. S. Torr)
6. Point Cloud Attribute Compression via Successive Subspace Graph Transform. (from C.-C. Jay Kuo)
7. Deep Shells: Unsupervised Shape Correspondence with Optimal Transport. (from Daniel Cremers)
8. A Teacher-Student Framework for Semi-supervised Medical Image Segmentation From Mixed Supervision. (from Guisheng Wang)
9. AdaCrowd: Unlabeled Scene Adaptation for Crowd Counting. (from Yang Wang)
10. Permute, Quantize, and Fine-tune: Efficient Compression of Neural Networks. (from Raquel Urtasun)
1. BiTe-GCN: A New GCN Architecture via BidirectionalConvolution of Topology and Features on Text-Rich Networks. (from Jiawei Han)
2. Understanding the Pathologies of Approximate Policy Evaluation when Combined with Greedification in Reinforcement Learning. (from Richard S. Sutton)
3. Abstract Value Iteration for Hierarchical Reinforcement Learning. (from Rajeev Alur)
4. Robustifying Binary Classification to Adversarial Perturbation. (from Babak Hassibi)
5. Stochastic groundwater flow analysis in heterogeneous aquifer with modified neural architecture search (NAS) based physics-informed neural networks using transfer learning. (from Timon Rabczuk)
6. Analysis of three dimensional potential problems in non-homogeneous media with deep learning based collocation method. (from Timon Rabczuk)
7. Representation learning for improved interpretability and classification accuracy of clinical factors from EEG. (from Greg Hajcak)
8. Bridging Imagination and Reality for Model-Based Deep Reinforcement Learning. (from Honglak Lee)
9. Autoregressive Asymmetric Linear Gaussian Hidden Markov Models. (from Pedro Larrañaga)
10. Shared Space Transfer Learning for analyzing multi-site fMRI data. (from Daoqiang Zhang, Russell Greiner)
![]()