离线强化学习新基准 NeoRL 包含来自不同领域、大小可控的数据集,以及用来做策略验证的额外测试数据集。目前,该项目向开发者免费提供。
2016 年,AlphaGo 以 4:1 的绝对优势击败世界顶级围棋大师李世石,将强化学习带入大众视野。此后,该领域成果频出,如 AlphaGo 的进阶版 AlphaGo Zero、AlphaZero 等。然而,将强化学习部署到现实世界还存在着许多挑战。
![]()
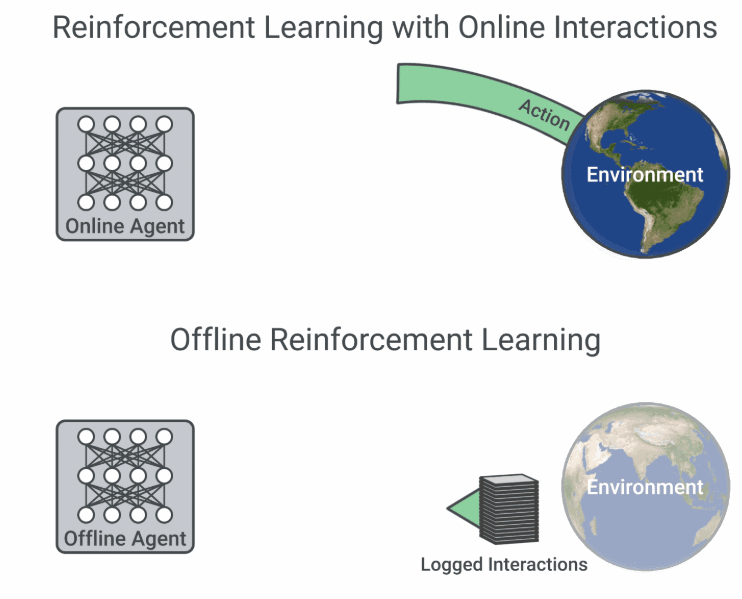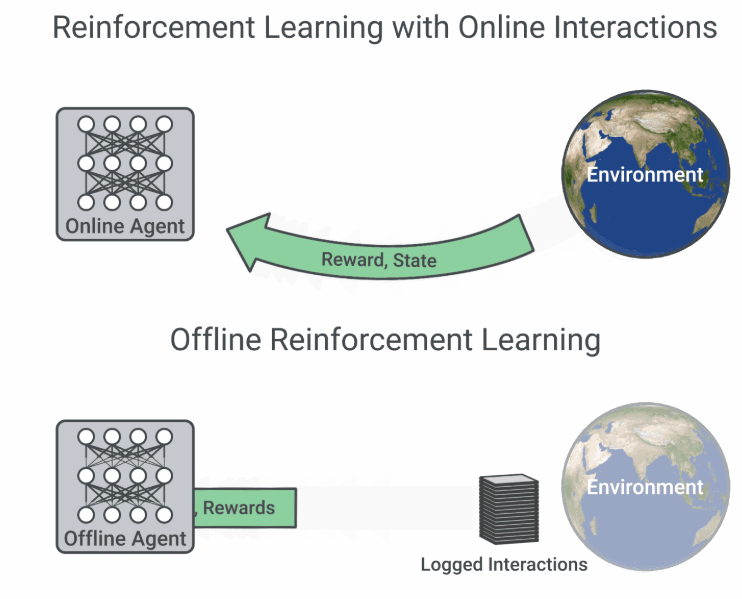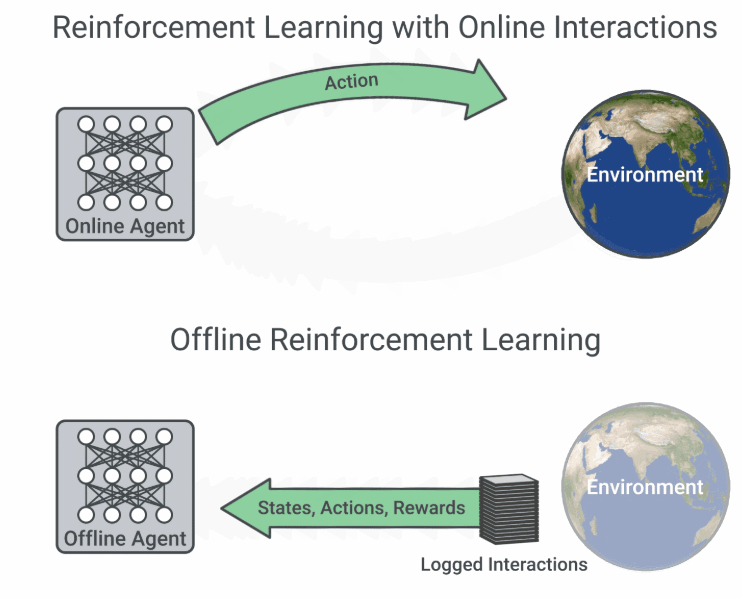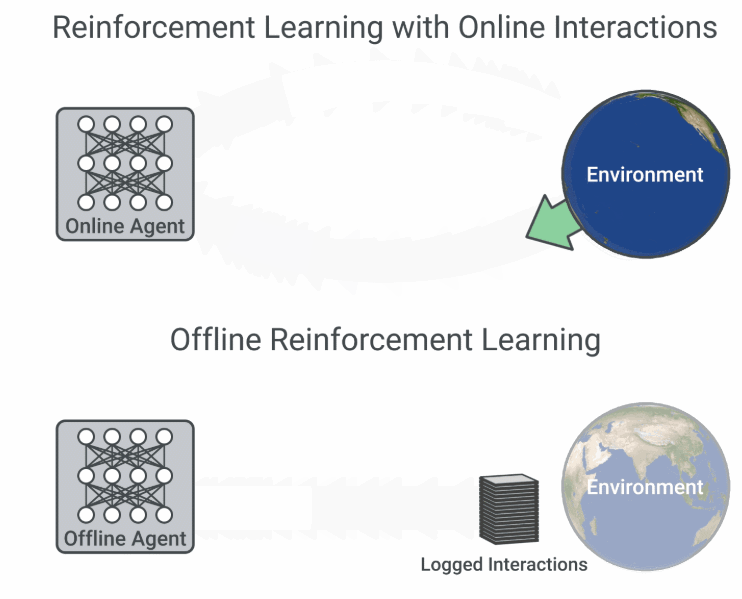
多数强化学习算法假设智能体主动与在线环境交互,从自己收集的经验中学习。然而这类算法在复杂现实问题中的应用却困难重重,因为从现实世界中收集大量数据可能样本效率极低,还会带来意想不到的行为,同时在仿真环境中运行的算法需要高保真模拟器,而高保真模拟器的构建并非易事。
然而,对于许多现实世界中的强化学习应用来说,此前已经收集了很多交互数据,可用于训练可行的强化学习智能体,同时通过结合之前的丰富经验来提升泛化性能。现有的交互数据可以实现离线强化学习 (Offline RL) 的有效训练,后者是完全的异策略(off-policy)强化学习设置,智能体从一个固定的数据集中学习,不与环境进行交互。
![]()
在线交互 RL 与离线 RL 的流程图比较(图源:https://ai.googleblog.com/2020/04/an-optimistic-perspective-on-offline.html)
离线强化学习旨在从已收集到的数据中学习最优的策略,在训练过程中不需要与环境进行额外的交互。它试图减少在环境中的危险行为,从而极大地拓宽强化学习的应用范围。
然而,目前的离线强化学习基准普遍存在较大的现实差距(reality gap)。它们包含由高度探索性策略收集的大型数据集,并且直接在环境中评估训练得到的策略。同时,为了确保系统安全,现实世界往往会禁止运行具有高度探索性的策略。数据通常非常有限,因此在部署之前应该对训练好的策略进行充分验证。
![]()
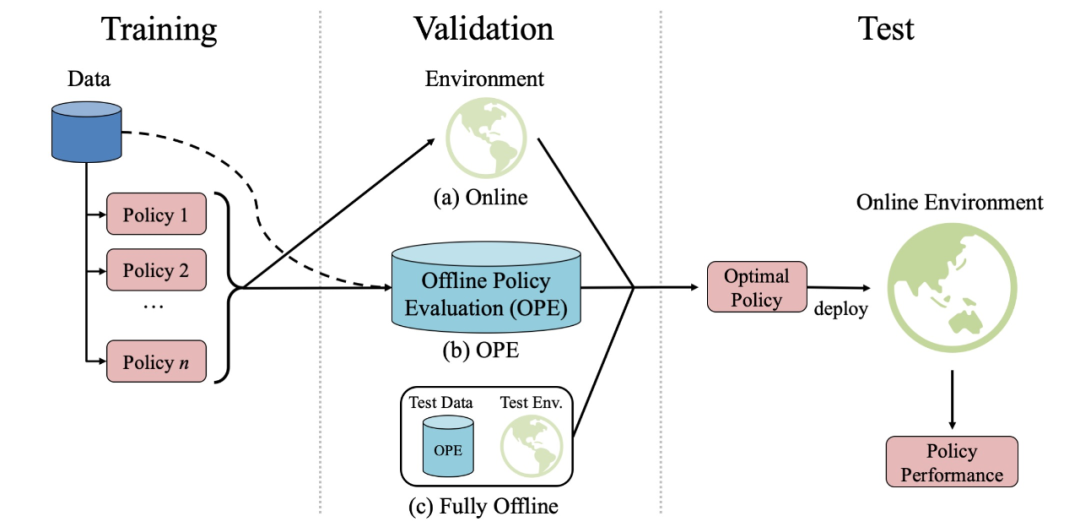
训练和部署离线强化学习的 pipeline,包括训练、验证(部署前的离线测试)和测试(部署)三个阶段。
如何解决现实差距问题呢?最近,人工智能新锐公司南栖仙策提出了一套接近真实世界的基准——NeoRL。它包含来自不同领域的多个大小可控的数据集,以及用来做策略验证的额外测试数据集。
研究人员在 NeoRL 上评估了现有的离线强化学习算法。在实验中,研究者认为策略的表现应该与确定性行为策略进行对比,而不是数据集奖励。因为确定性行为策略是真实场景中的基线,而数据集的收集过程常伴随着动作扰动,会降低策略的性能。实验结果表明,在许多数据集上,离线强化学习算法的表现和采样所用的确定性策略相当,而离线策略评估几乎没有帮助。
该项目目前向开发者免费提供。研发团队表示,希望这项工作能对强化学习在实际系统中的研究和部署有所帮助。
NeoRL 官网介绍:http://47.56.161.173/research/neorl
测试基准代码库:https://agit.ai/Polixir/neorl
离线强化学习代码库:https://agit.ai/Polixir/OfflineRL
相关论文:https://arxiv.org/pdf/2102.00714.pdf
在实际应用中,对真实场景建立一个高保真模拟器往往非常不易。例如,在工业控制任务场景中,数据是直接从生产环境中获得的。和模拟器中产生的数据相比,真实场景的数据往往具有以下几个特点:
由于随机探索的成本和潜在风险,在生产环境中倾向于采取保守的行为,使用世代相传的专家经验。这将导致数据集的多样性低于当前的基准,而且这些数据集的质量可能参差不齐。
尽管之前的工作通常假设在真实世界的系统中很容易获得大量日志数据,但它只适用于大规模或流式应用,如推荐系统。要从一小部分离线数据中进行学习是非常具有挑战性的。
现实环境的困难之一是其随机性(或非平稳性)。环境可能会不断自我演变或产生任意的不确定性,使信用分配更加困难。
生产环境对风险非常敏感,部署前必须对策略进行充分评估。在监督学习中,训练好的策略在最终部署前会在一个未曾接触过的测试集上进行评估。现实系统中的强化学习策略也应该是相同的。
然而,当前的离线强化学习基准使用全部数据集来训练模型并提出流程规范,比如 OPE 方法来进行离线评估或在具有相似动态的不同模拟环境中进行在线评估。不同的模拟环境评价方法在一定程度上与离线性质相矛盾。如果我们有一个易于获得的模拟器,并且具有类似的动态,那么模拟器可以带来很多好处,例如,预先训练一个策略。在只有生产环境可用的情况下,这种验证是难以实现的。
为了弥补这一现实差距,南栖仙策研发团队选择一些任务构建具有接近真实世界应用属性的数据集。与之前的工作相比,他们提出的任务考虑了上述现实差距,并在此基础上模拟现实世界中可能遇到的各种复杂情况,构建不同性质的离线数据集。该新型基准数据集具备以下特点:
接近现实的环境和奖励函数
多级策略和灵活的数据划分
统一的 API 接口和丰富的基准算法对比
NeoRL 基准涉及多项任务:MuJoCo 连续控制任务、工业基准(IB)、FinRL 和 CityLearn(CL)。
具体而言,MuJoCo 连续控制任务是在线强化学习算法的标准测试平台。由于具有高维的状态和动作空间,即使它的物理引擎是确定性的,对于离线强化学习任务来说,MuJoCo 仍然非常有挑战性。
研究者从中选择了 Halfcheetah-v3、Walker2d-v3 和 Hopper-v3 三种环境构建离线强化学习任务。和已有工作的区别在于,他们在观察空间中增加了一个维度来记录智能体的位置信息,这是因为这三种环境的奖励函数中有一部分是向前移动的距离,增加位置信息可以简化当前步骤的奖励计算。研究者还发现,这些位置信息对训练策略的影响可以忽略不计。
工业基准(IB)是一种强化学习基准环境,旨在模拟各种工业控制任务(如风力或燃气轮机、化学反应器)中呈现的特性。它包括现实工业环境中经常遇到的问题,如高维连续状态和动作空间、延迟奖励、复杂的噪声模式以及多个反应目标的高随机性。研究者还扩展了原始的工业基准环境,将系统状态的两个维度添加到观测空间中,以计算每一步的即时奖励。由于工业基准环境本身是一个高维度、高随机性的环境,所以在这个环境上采样数据时,并没有给动作添加显式噪声。
FinRL 环境提供了一种建立股票交易模拟器的方法,可以复制真实的股票市场,并提供回测支持,其实施考虑了交易手续费、市场流动性和投资者风险规避等因素。在 FinRL 环境下,每个交易日可以对股票池中的股票进行一次交易。奖励函数是当天结束时与前一天总资产价值的差额。随着时间的推移,环境存在自我演化。
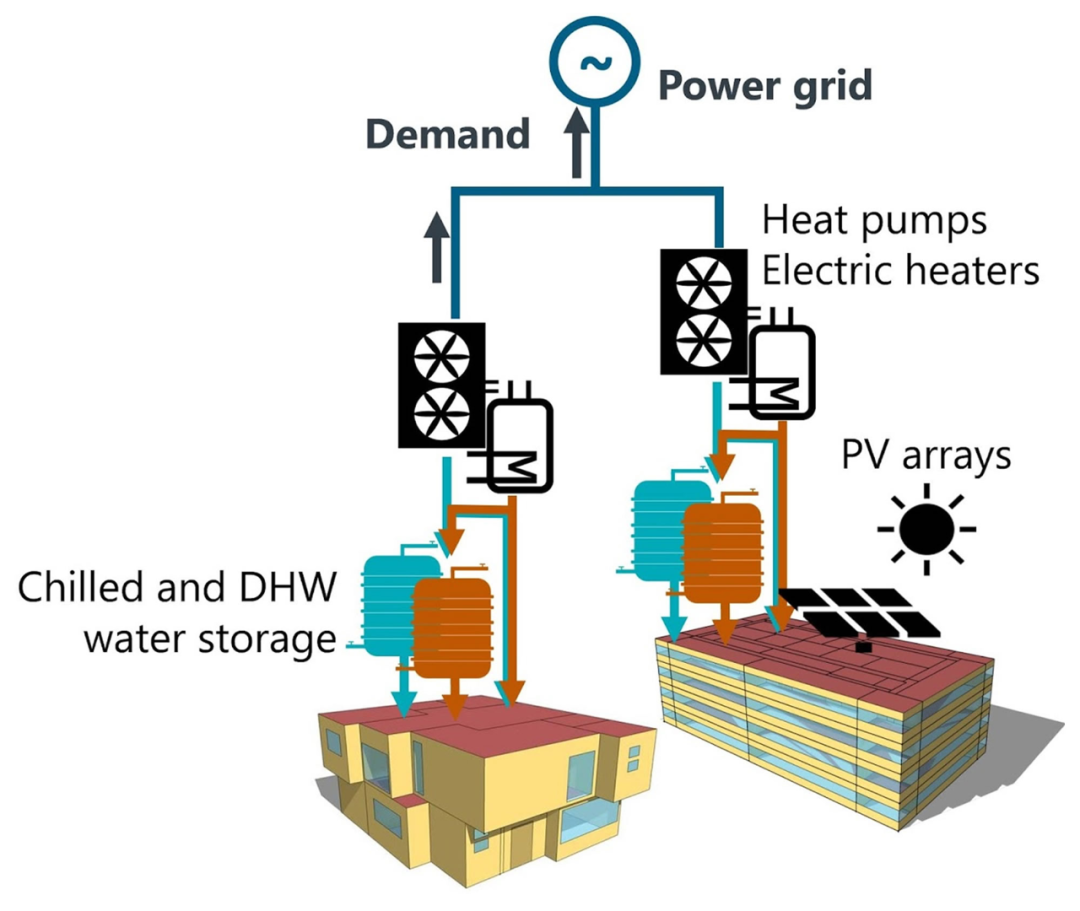
CityLearn(CL)环境是一个类似 OpenAI Gym 的环境,它通过控制不同类型建筑的储能来重塑电力需求的聚集曲线。高电力需求提高了电价和配电网的总体成本,扁平化、平滑化和缩小电力需求曲线有助于降低发电、输电和配电的运营和资本成本。优化的目标是协调用电方(即建筑物)对生活热水和冷水储存的控制,以重塑电力需求的总体曲线。
![]()
为了公平地对比所有离线强化学习算法,研究者重新实现了多个算法,并在 D4RL 数据集上进行验证。研究者将这些算法粗略地分为两个类别:Model-Free 方法(如 BC、BCQ、CQL)和 Model-Based 方法(如 MB-PPO、MOPO)。由于离线强化学习算法对超参数选择较为敏感,因此研究者在训练过程中进行模型选择,以选出最优策略。
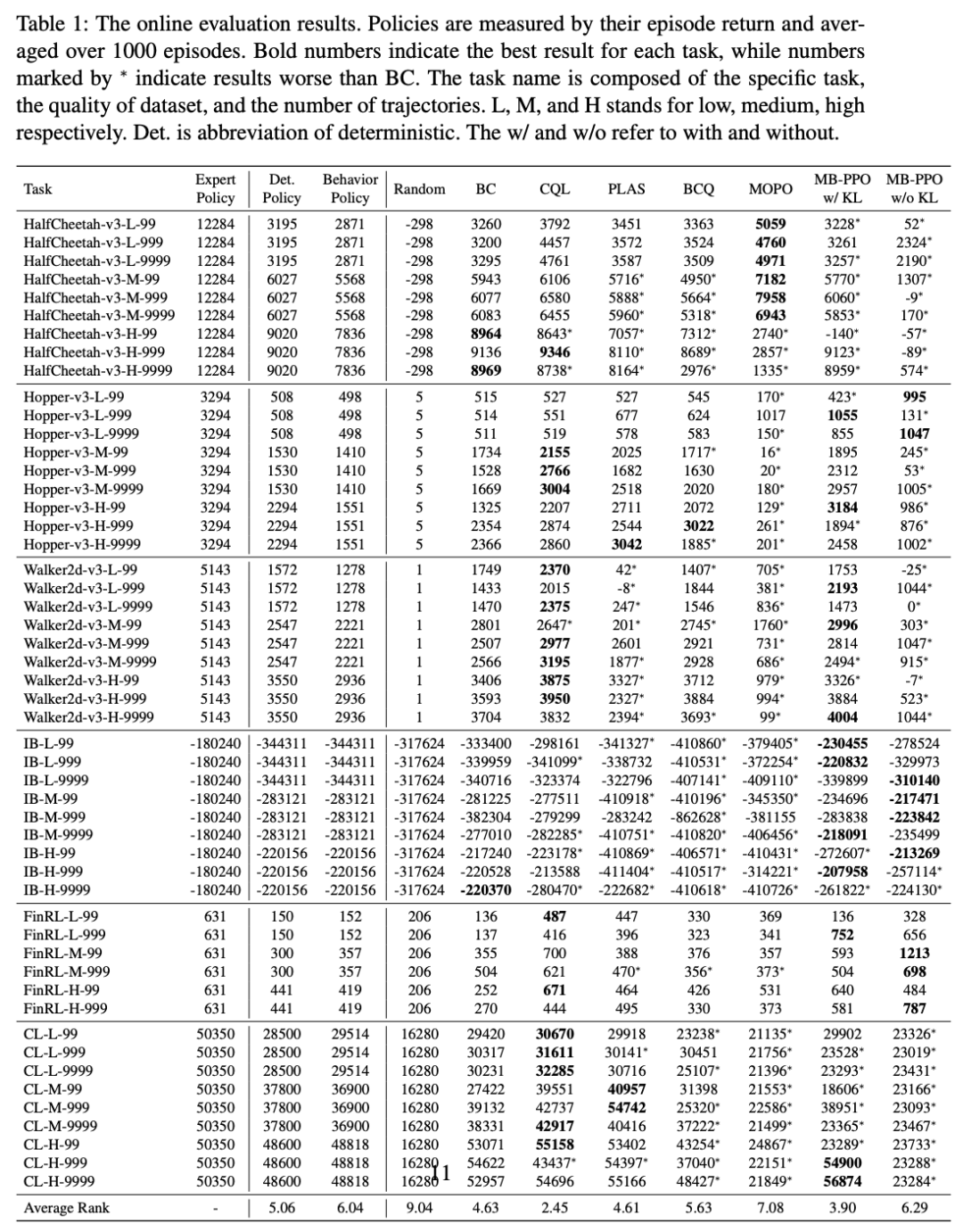
评估离线强化学习的一种直接方式是在环境中运行学得的策略,并计算 episode 平均收益。研究者遵循这一方式,通过在线评估选出了最优策略,结果参见下表 1:
![]()
从表 1 中可以看到,在大多数任务中,BC(behavioral cloning)算法的性能可以媲美确定性策略。有趣的是,BC 的结果形成了强大的基线:其他四种离线强化学习算法在 306 种配置中的 153 种里不敌 BC。在其他离线强化学习算法中,CQL 在 1/3 的任务中取得最优性能,但它在 MuJoco 和 IB 环境上相比于确定性策略的性能提升不够显著。
而 model-based 方法的整体性能逊色于 model-free 方法。
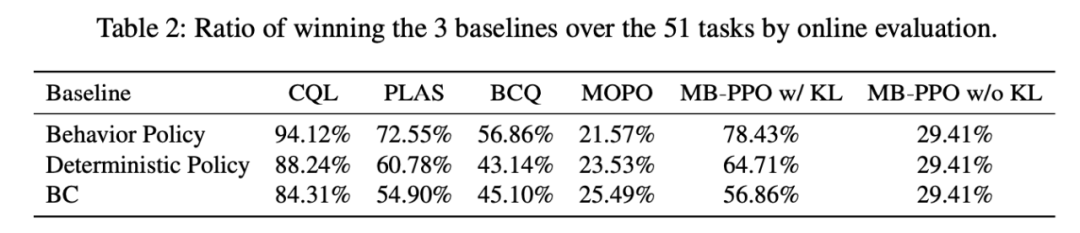
表 2 总结了离线强化学习算法和 behavior policy、确定性策略、BC 对比时的赢率。从中可以看出,与 behavior policy 对比时的赢率和与确定性策略对比时的赢率存在很大差距。很多方法没有显著优于 BC 算法。
![]()
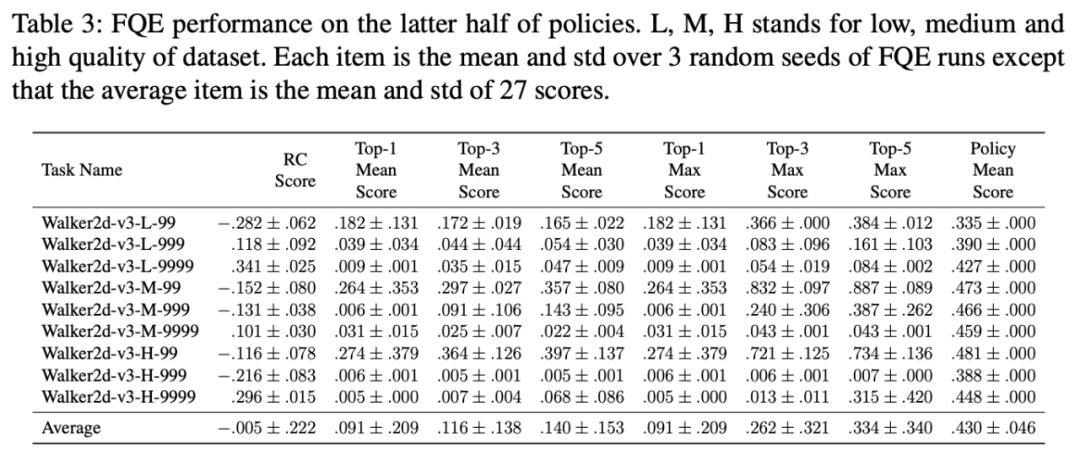
在线评估可以验证给定策略在部署时的实际性能,但在现实场景中并不实用,其主要缺陷在于训练策略的性能在部署前仍属未知。因此,离线评估对于现实世界部署至关重要。于是,研究者进行了离线模型选择,并报告了实验结果,参见下表 3:
总体而言,实验结果令人惊讶:
除了 CQL,这些离线强化学习
算法无法胜过最简单的 BC 方法或确定性行为策略,其性能可能严重受限
于数据。
model-based 方法整体上弱于 model-free 方法,但 model-based 方法可能有更大潜力获得 out-of-data 泛化能力。此外,研究者还注意到基于对抗学习的更好模型学习方法或许将有所帮助。
NeoRL 基准的使用较为简单,如下介绍了「安装」和「加载数据集」两个重要步骤。
git clone https://agit.ai/Polixir/neorl.gitcd neorlpip install -e .
使用以上命令安装 NeoRL,用户即可直接调用 CityLearn、FinRL、IB 三个数据集。如果想要使用 MuJoCo,则需要获取许可 (https://www.roboti.us/license.html) 并按说明安装后,运行:
当前,NeoRL 基准中的 MuJoCo 环境支持 HalfCheetah-v3、Walker2d-v3 和 Hopper-v3。
import neorlenv = neorl.make("citylearn")data = env.get_dataset()
该团队表示,将不断提供接近现实的新型数据集和任务,以进一步靠拢现实场景,解决更多现实场景离线强化学习的应用挑战。他们希望 NeoRL 基准能够让大家更加关注现实世界强化学习应用。
报告内容涵盖人工智能顶会趋势分析、整体技术趋势发展结论、六大细分领域(自然语言处理、计算机视觉、机器人与自动化技术、机器学习、智能基础设施、数据智能技术、前沿智能技术)技术发展趋势数据与问卷结论详解,最后附有六大技术领域5年突破事件、Synced Indicator 完整数据。
识别下方二维码,立即购买报告。
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com