一文总览近年来YouTube推荐系统算法梳理
作者:张皓
来源:https://zhuanlan.zhihu.com/
p/99953120
整理:深度传送门
作者介绍:南京大学计算机系机器学习与数据挖掘所(LAMDA)硕士,腾讯优图实验室研究员,研究方向为视频理解与推荐。个人主页:https://haomood.github.io/homepage/
YouTube 创建于 2005 年,用于让用户寻找和发布视频。近年来,YouTube 上的视频数量得到了迅猛增长,成为全球最大的视频网站。截止 2008 年,整个 YouTube 视频量已突破四千五百万,每分钟上传视频量 7 小时。截止 2010 年,每分钟上传视频量超过 24 小时。截止 2014 年,每分钟上传视频量超过 100 小时。2019 年,月度活跃用户是 19 亿。如此庞大的视频量,使得用户难以搜索到其感兴趣的视频。YouTube 的成功得益于其精准的推荐系统。
YouTube 视频推荐系统主要面临以下几大难题:
大规模:YouTube 的用户和视频量级都是十亿级别的,需要分布式学习算法和高效的部署。
新鲜度:推荐系统需要及时对新上传的视频和用户的新行为作出响应。
噪声:由于稀疏和外部因素影响,用户的历史行为很难预测。大部分 YouTube 视频只有隐式反馈(即用户对视频的观看行为),缺少显式反馈(即用户对视频的评分)。此外,视频的元信息不够有结构性。我们的算法需要对训练数据的这些因素稳健(robust)。
多模态特征,包括视频内容、缩略图、音频、标题和描述、用户人口统计学信息、设备、时间、位置等。
本文介绍了 YouTube 从开始发展至今使用的五种推荐系统,对应于五篇论文。
[Baluja et al., 2008] Shumeet Baluja, Rohan Seth, D. Sivakumar, Yushi Jing, Jay Yagnik, Shankar Kumar, Deepak Ravichandran, Mohamed Aly. Video suggestion and discovery for YouTube: Taking random walks through the view graph. WWW: 895-904, 2008.
[Bendersky et al., 2014] Michael Bendersky, Lluis Garcia Pueyo, Jeremiah J. Harmsen, Vanja Josifovski, Dima Lepikhin. Up next: retrieval methods for large scale related video suggestion. KDD: 1769-1778, 2014.
[Covington et al., 2016] Paul Covington, Jay Adams, Emre Sargin. Deep Neural Networks for YouTube Recommendations. RecSys: 191-198, 2016.
[Davidson et al., 2010] James Davidson, Benjamin Liebald, Junning Liu, Palash Nandy, Taylor Van Vleet, Ullas Gargi, Sujoy Gupta, Yu He, Mike Lambert, Blake Livingston, Dasarathi Sampath: The YouTube video recommendation system. RecSys, pages 293-296, 2010.
[Zhao et al., 2019] Zhe Zhao, Lichan Hong, Li Wei, Jilin Chen, Aniruddh Nath, Shawn Andrews, Aditee Kumthekar, Maheswaran Sathiamoorthy, Xinyang Yi, Ed H. Chi. Recommending what video to watch next: A multitask ranking system. RecSys: 43-51, 2019.
1. 基线(Baseline)方法
1.1 思路
一种思路是基于视频内容的推荐。尽管可以使用计算机视觉算法进行视频理解来对预测标记,但是难以对 YouTube 如此丰富的视频内容进行预测。此外,YouTube 已有的视频标记体系涵盖范围有限,只能覆盖一小部分视频内容。
另一种思路是基于用户行为数据的推荐。和传统推荐环境如 Netflix 不同,大部分 YouTube 视频只有隐式反馈(即用户对视频的观看行为),缺少显式反馈(即用户对视频的评分)和元信息(如标题、视频描述等),因此,YouTube 推荐算法的基本思路是利用用户-视频观看记录进行个性化推荐。
这其中最直观的算法是推荐用户没看过的全网站最热门视频。还可以基于 ItemCF,比如 Amazon 的“购买这本书的用户也购买了 x”,其关键是定义两个视频 

定义为分别观看视频
和视频
的用户集合的 Jaccard 系数
定义为视频
和视频
的共同观看(co-view)用户数,这实际是未归一化的 ,会倾向于推荐热门视频


找到相似视频之后(这步称为召回阶段),再对这些相似视频进行排序,最终推荐给用户。排序方法可以有以下三种方式:
根据视频总浏览量。这将热门视频排序在前面。
根据视频共同观看数。这将用户看过的相似视频中的热门视频排序在前面。
根据视频召回次数。

从上图可以看出,即使是沿着视频-视频共同观看图前进很短几步,视频的内容主题可能会发生很大变化(水墨画 
1.2 实验结果
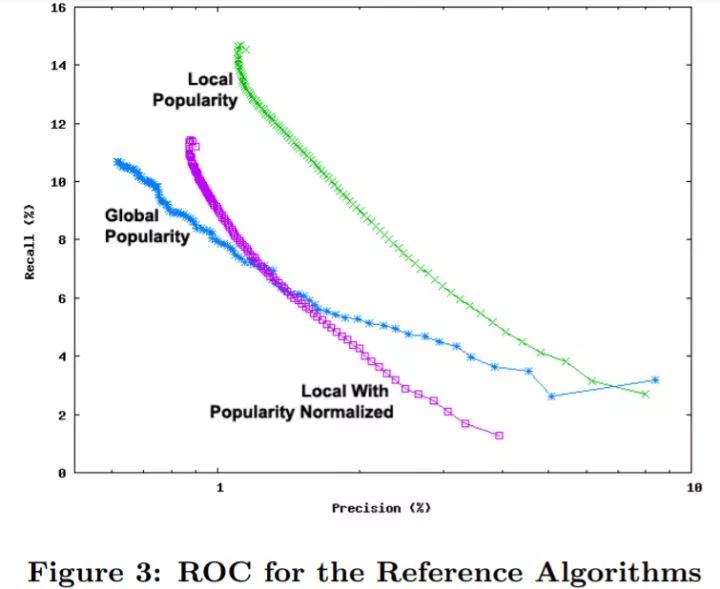
[Baluja et al., 2008] 在 YouTube 2007 年 7 月至 9 月三个月的数据上进行实验。上图是不同 取值下(1 - 100)的 top-N 推荐的查准率和查全率。最右下的点代表 top-1 推荐的结果,最左上的点代表 top-100 推荐的结果。Global Popularity 表示使用全网热门视频、Local with Popularity Normalized 表示使用 作为视频相似度度量的 ItemCF、Local Popularity 表示使用 
YouTube 的用户大部分比较随意地浏览视频,从图中可以看出,推荐全网站最热门视频已经是很强的基线,尤其是在 top-1 推荐。比较基于 
尽管如此,由于 YouTube 上传的视频量非常大、视频的生命期通常很短、需要给用户曝光新的和流行的视频,给用户推荐热门或者最多共同观看的视频效果不佳。YouTube 先后提出了几种不同的推荐算法。
2. 基于图标记传播
2.1 Adsorption(吸附法)
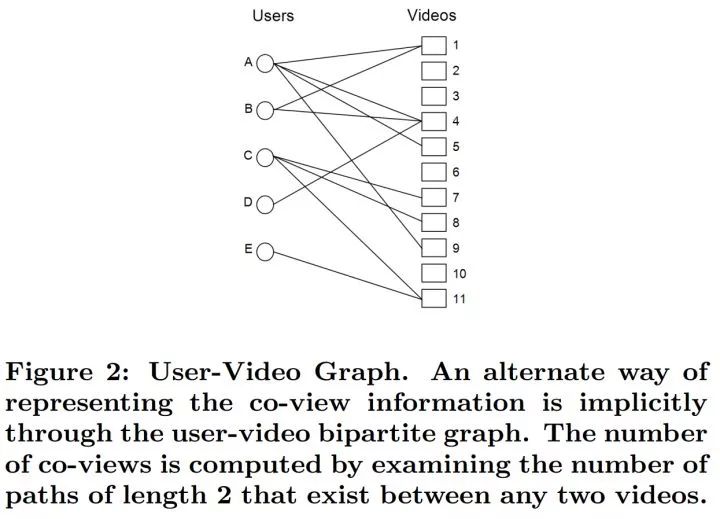
[Baluja et al., 2008] 提出 Adsorption,基于用户-视频(即物品)记录的二部图来进行标记传播,进而实现视频个性化推荐。令 








Adsorption 的第一种理解基于标记传播。在每次迭代,每个结点将自己的状态向量传播到邻接结点,直到整个过程收敛。为方便阐述,在初始状态,对每个状态向量不为 



注意到更新时和
Adsorption 的第二种理解基于图随机游走。记 

这相当于根据概率 





Adsorption 还有第三种基于线性系统的等价理解方式。本文不在这里详细介绍,感兴趣的读者可以看原论文。
尽管基于图随机游走的方式实现起来效率很低,但可以帮助我们进行一些分析理解。由于当进入“影子”结点时游走停止,权重 可以对随机游走过程进行控制,我们将其称为注入概率(injection probability)。另外一个控制随机游走过程的超参数是放弃概率(abandonment probability 或 dummy probability),每次以一定的放弃概率结束游走过程,并不输出任何推荐视频。这在游走到一个很高度的结点时很有用,当进入一个度很高的视频结点(热门视频)时,继续游走很有可能会进入一个和原用户兴趣很不一样的用户结点,他们只是都看了这个热门视频。为了使算法能实现这一特性,我们给所有结点的状态向量增加一维,表示放弃概率。
2.2 实验结果
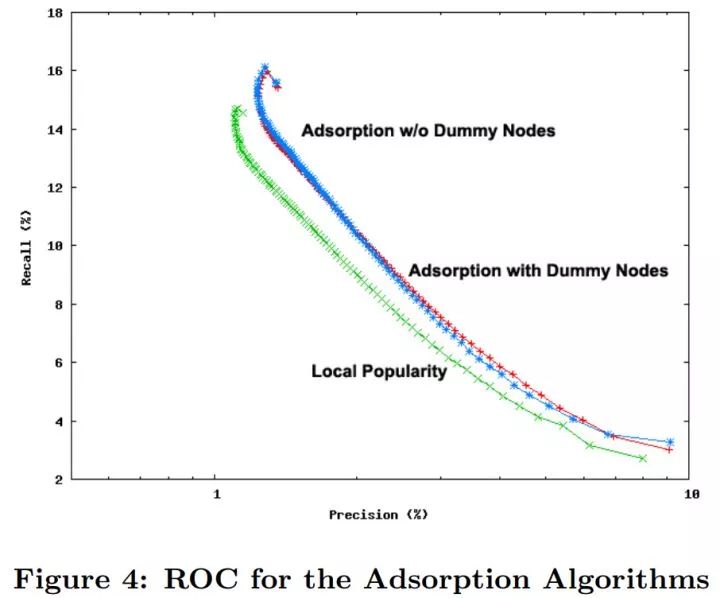
上图的 Adsorption w/o Dummy Nodes 使用 0.25 的注入概率和 0 的放弃概率。Adsorption with Dummy Nodes 使用 0.25 的注入概率和 0.25 的放弃概率。从 P-R 曲线上看,两者十分接近,但都优于使用 作为相似度度量的 ItemCF(Local Popularity)。
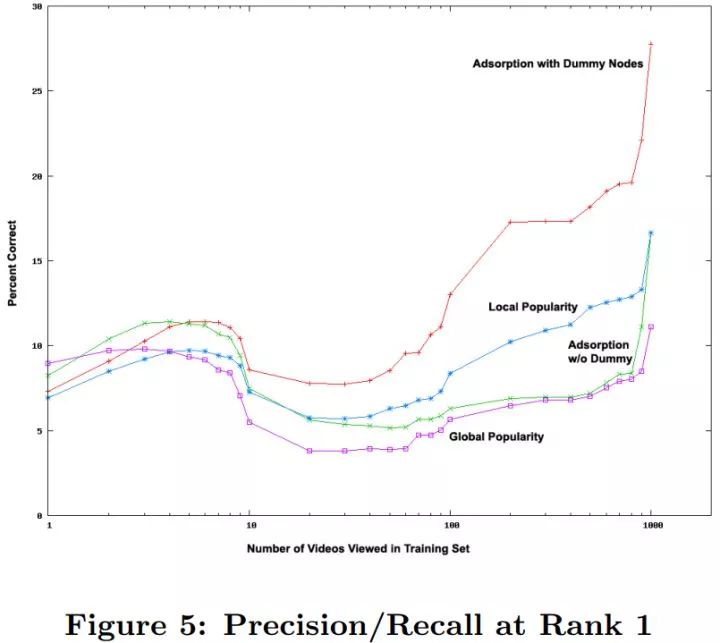
上图进一步比较了在 top-1 条件下,不同用户活跃程度(观看视频数)对推荐准确率(因为只有一个视频,查准率和查全率将退化为准确率)的影响。对于只观看过一个视频的用户(非常不活跃),给他/她推荐全网站最热门的视频(Global Popularity)效果最好。但随着用户观看视频数的增加,推荐最热门视频效果最差。这是因为如果用户看过很多视频,但是用户没有看过该热门视频,说明用户很可能不喜欢该热门视频。这也说明,对于越活跃的用户,个性化推荐的需求越高。
关于 Adsorption w/o Dummy 和 Adsorption with Dummy Nodes 的对比,由于大部分用户只看过少量视频,所以在 P-R 曲线上区别不大。但是对于极其活跃的用户,需要避开热门的影响,推荐小众的结果,Adsorption with Dummy Nodes 的优势则很明显。
3. 基于 ItemCF
3.1 算法思路
[Davidson et al., 2010] 使用基于

的 ItemCF。由于我们在找视频 

作为视频相似度度量。
在产生推荐列表时,我们将用户观看过、收藏过、点赞、评分或加入播放列表的视频作为种子视频集 



许多情况下,使用 

为从种子视频集 


由于分支数很多,即使沿着视频-视频共同观看图前几很小几步,视频内容也会变得很宽广和多样。 
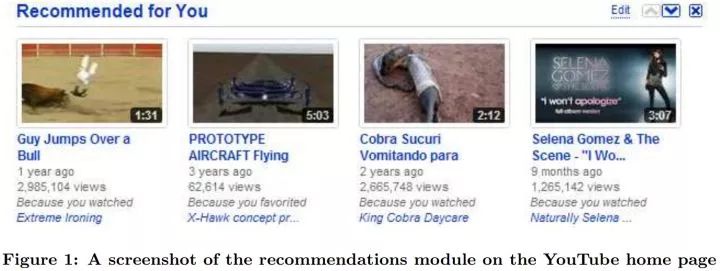
在得到候选视频之后,我们需要对齐进行排序。大致来说,排序的准则有以下三种,我们考虑这三者的线性组合:
视频质量:包括视频观看次数、视频评分、评论、收藏数、分享数和上传时间。
用户偏好,指视频和用户偏好的匹配程度。为了这个目的,我们使用种子视频的用户历史记录,例如观看次数和观看时长。
视频多样性。由于能给用户展示的推荐结果数是有限的(通常是 4-60 个),我们需要从排序结果中选择一个子集。由于用户通常在不同时期有不同的兴趣,为了增加多样性,我们去除推荐列表中过于相似的视频。一种简单的方式是限制每个种子视频对应的视频推荐数的上限,或者限制每个频道(每个用户)的视频推荐数上限。也可以使用更加复杂的技巧,比如主题聚类和内容分析。
此外,由于展示的推荐结果知识候选列表的一部分,这使得即使底层的推荐没有重新计算,用户每次进入网站时都能看到新的推荐结果。
完整的推荐系统包括三步:
数据收集。数据从用户日志中收集得到,处理好后,按照用户存储在 Bigtable 中。目前是百万用户规模和亿级行为信息。
推荐生成。使用 MapReduce 进行计算。
部署。推荐结果数据量只有 GB 规模,可以在网络服务器上使用只读 Bigtable 进行部署。由于推荐结果是预先计算出来的,为了减少和用户新行为之间的延迟,我们一天更新若干次推荐结果。
3.2 实验结果
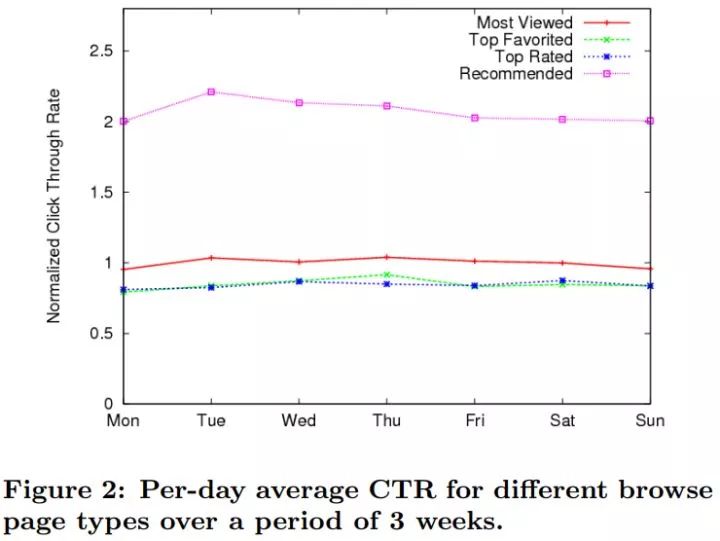
本文使用了 21 天线上 A/B 测试进行点击率(Click Through Rate,CTR)评估,只有观看了一定比例的视频才认为是有效点击。Most Viewed 是指一天内观看次数最多的视频、Top Favorited 是指用户加入收藏夹的视频、Top Rated 是指一天内获得最多赞的视频。可以看出,使用基于 ItemCF 的方法可以使点击率翻倍。
4. 基于视频主题内容
由于新上传的视频或被观看次数很少的视频(长尾视频)的观看历史记录很稀疏并有噪声,ItemCF 对这类视频的效果不佳。这是基于用户行为数据进行推荐共同面临的挑战。一种思路是将基于行为的推荐算法和基于内容的推荐算法相结合。[Bendersky et al., 2014] 从视频的文本信息中的得到视频的主题,对视频不同主题计算权重使用了两种方案:一种是利用信息检索中经典的 TF-IDF,计算得到视频称为 IRTopics;另一种利用用户隐式行为数据学习最优的主题权重,称为 TransTopics。
4.1 IRTopics

相比图像信息,我们有很多的文本信息的视频源,例如视频的元数据、经常使用的上传者关键词、常用搜索词、播放列表名称、Freebase 和 Wikipedia 等。因此,我们从视频的文本信息中可以得到视频的主题,这是视频内容的语义表示。例如,上图展示了僵尸世界大战(World War Z)的电影预告片对应的主题(包括标题、类型、主演、视频本身信息)及其权重。
我们利用这些主题进行相关视频检索。为了这个目的,我们将视频表示为主题权重的向量,利用内积进行相似性度量。令 


其中,
表示视频
的质量分。从视频上传时间、上传者、点赞次数、厌恶次数、视频流行度和新鲜度计算得到。
是话题
的词频。
是某个常数。受信息检索中去除停止词的启发,我们去除一些词频很低的话题。我们发现这对于去除噪声和冗余话题很有用,并且可以提高查询的效率。
是逆文档词频(Inverse Document Frequency, IDF)。用于惩罚频繁出现的话题,这用来抑制宽泛的、模糊的、不精确的话题。
是归一化后的和视频
一起观看的视频被标注为话题
的个数。这反映了视频
对话题
的时事性。





由于所有视频有几乎一样的主题数目,我们不使用任何文档长度规范化的方法,如余弦距离、旋转长度规范化(pivoted length normalization)等。
4.2 TransTopics
这种方案基于用户行为数据学习主题的权重。假设用户观看了视频 ,我们给用户推荐了视频 




类比于视频共同观看,这是话题共同出现情况。当视频 




在预测阶段,我们根据学得的最优参数 

4.3 实验结果
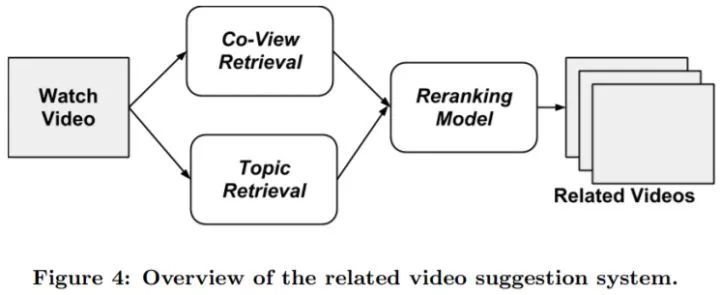
在用户观看一个视频之后,两个推荐模块并行地进行。一个基于共同观看(ItemCF)、一个基于主题模型。两个模块各自找到最相似的 

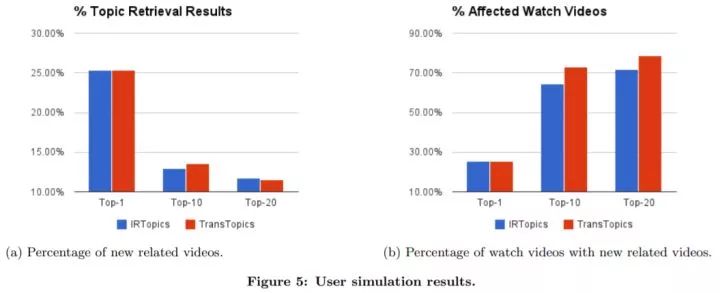
上图 (a) 展示了相比 ItemCF,利用视频主题的推荐产生的新视频的比例。上图 (b) 展示了有多大比例的已观看视频,其推荐结果中利用视频主题新产生结果中至少有一个视频被认为是相关的。
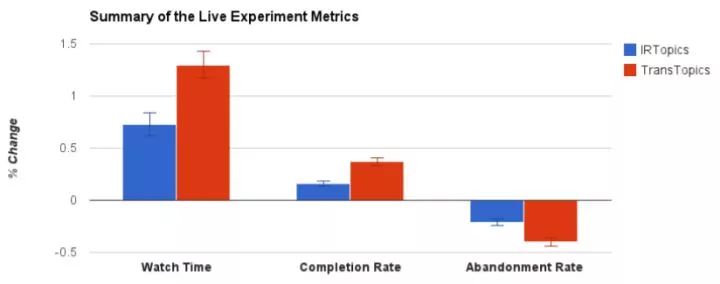
上图是 YouTube 2013 年一个月在线 A/B 测试的结果,对比方法是 ItemCF。包括三个指标。完成率是指有多少视频被完整的观看了。放弃率是指有多大比例的已观看视频,其推荐结果用户一个都没有观看。
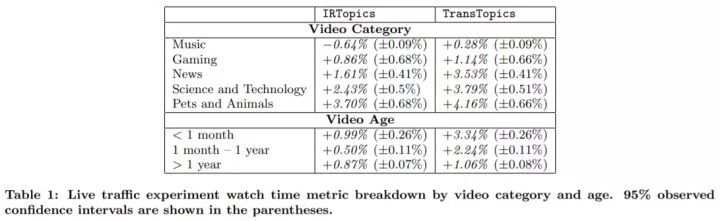
上表展示了对不同视频类型和不同视频年龄的算法比较结果,对比方法是 ItemCF。由于本文提出的算法基于视频主题,可以看出,对视频主题丰富、共同观看少的视频,例如新闻、科技类,算法表现更佳。表现最好的是宠物动物类,其非常的长尾,有很多视频共同观看很少。另一方面,对于音乐和游戏类,有更流行的视频、共同观看更多,利用视频主题进行推荐的效果比较微弱。其中,对于 IRTopics 在音乐类甚至起到负作用。从视频年龄来看,对于新上传的视频(< 1 个月),由于共同观看少,利用视频主题的方法提升很明显。
5. 基于深度模型
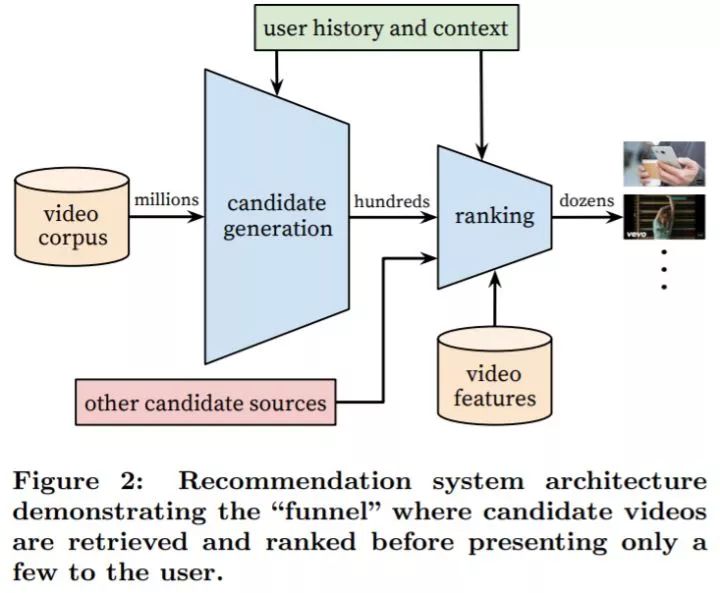
和 Google 的其他产品一样,YouTube 推荐系统迁移到了基于深度学习的解决方案 [Covington et al., 2016]。如上图所示,模型分为两个阶段:召回阶段和排序阶段。模型使用千亿级别数据训练得到,有百万级别的参数量。
召回阶段基于协同过滤,将用户行为历史数据作为输入,从庞大的视频库中检索一小部分(通常几百的量级)作为输出。召回阶段需要比较高的查准率(precision),检索到的视频只提供比较宽泛的个性化推荐,用户相似度只是从一些粗粒度的特征中计算得到,如用户观看的视频 ID、查询词、用户人口结构信息等。
排序阶段对召回的结果进行精细化的排序,区分对用户的相对重要性,最后将 top-N 结果返回给用户。这一步需要比较高的查全率(recall)。这一步会用到更加精细的用户和视频特征,具体实现方式是选定一个指标(如点击率、观看时长等),对每个视频进行指标预测,根据指标进行排序。
5.1 召回模型
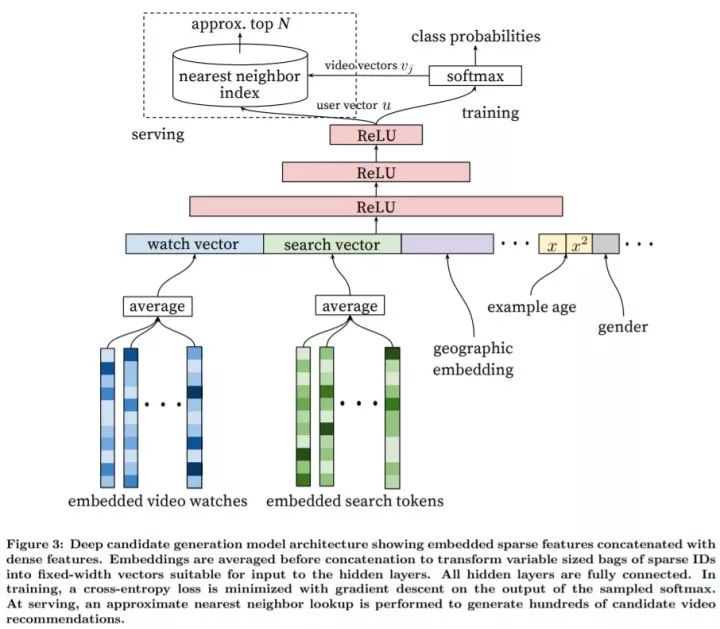
我们将召回任务看作是一个极其多类别数的多分类问题。网络分为几个部分:
Watch Vector:这部分的任务是从用户行为历史中学习用户 Embedding。我们将用户的观看历史编码为变长的视频 ID 序列,每个视频 ID 映射到实数 Embedding 向量,随后对观看视频的 Embedding 向量取平均得到固定长度表示,最后经过深度神经网络得到用户 Embedding
。
Search Vector:和 Watch Vector 的处理方法类似,将用户的查询词用 Unigrams 和 Bigrams 编码,Embedding 之后进行平均。
人口统计学习信息:用于提供先验,使其对新用户也能做出合理的推荐。具体来说,对用户的地理区域和使用的设备进行 Embedding 并将特征进行拼接(concatenation)。
Example Age:给用户推荐新上传的视频(新鲜内容)是至关重要的,我们发现用户很喜欢新鲜内容。而机器学习模型通常隐式地偏好过去的视频,这是因为这些视频被用来学习对用户历史行为进行预测。为了缓解这个问题,我们将视频年龄作为一个特征输入到网络中。在部署阶段,我们我们将 Example Age 特征置为 0,或一个很小的负数,用来反应模型在训练窗口的末端进行预测。
其他信息:包括用户性别(0/1)、登录状态(0/1)、年龄(规范化到
),将其直接输入网络。
MLP:使用常见的塔状设计,底层最宽,往上每层的神经元数目减半,直到 Softmax 输入层是 256 维。
Softmax 层:深度神经网络的视频的 Embedding 向量
和用户的 Embedding 向量 ,召回任务预测用户
在
时刻观看的视频:
 。
。 ),将其直接输入网络。
),将其直接输入网络。 和用户的 Embedding 向量 ,召回任务预测用户
和用户的 Embedding 向量 ,召回任务预测用户 
监督信息:尽管 YouTube 存在显式反馈机制,如点赞、厌恶、调查问卷等,由于显式反馈数据量显著少于隐式反馈数据量,我们使用隐式反馈训练模型,这更利于对长尾数据进行推荐。如果用户完整观看完一个视频被任务是正样本。
ANN 层:在部署阶段,需要计算所有视频对应的概率并进行排序,从而得到召回阶段的输出。由于我们并不真正关心 Softmax 后概率数值大小,为了提高速度,我们将分类问题转化为用户 Embedding 在视频 Embedding 之间最近邻检索问题,这样可以使用一些通用的检索库。实验发现,A/B 测试结果对使用什么检索库并不敏感。
此外,训练时有几点注意事项:
使用用户所有的观看记录(不仅仅是观看推荐的结果)作为训练样例。否则,将很难发现新视频。如果用户通过其他非推荐途径观看了某视频,我们希望能通过协同过滤很快地将这个视频推荐给其他人。
高效地训练一个有几百万类的模型十分困难,我们有选择地对负样本进行采样(实际使用几千个负样本),并使用重要性加权(importance weighting)的方式校正这个采样。相比经典 Softmax,这有几百倍的速度提升。另外一种常用的策略是分层(hierarchical)Softmax,但是我们达不到相同的准确率。在分层 Softmax 中,在树中遍历结点需要区分通常不相关的类别集合,这使得分类问题更困难。
对每个用户产生固定长度的训练样例,在损失函数中高效地给不同用户加权。这避免一小部分十分活跃的用户对整体损失函数起主导作用。
注意分类器的保留信息,防止模型利用网页结构和过拟合到代理学习问题中。假设用户最后一次行为是搜索 “Taylor Swift”,由于我们的模型是要预测下一个观看的视频,那么模型会将很多 “Taylor Swift” 的搜索结果作为推荐结果展示给用户。但是,将用户最后一次搜索得到的视频页面作为主页推荐表现很差。去除序列信息并将查询词当做无序的词的集合,分类器将不会直接意识到标记的起源。
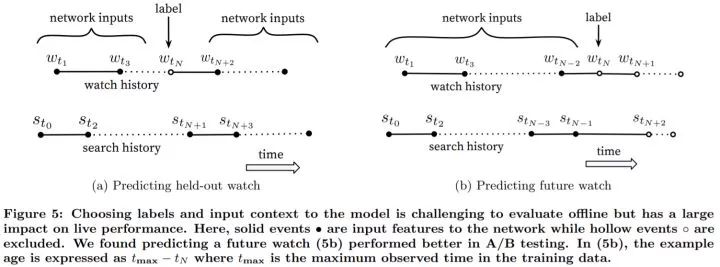
视频的共同观看不是对称的。电视剧通常是一集集顺序观看的,用户发现新的一类艺术家时通常是先看最广受欢迎的再关注小众的。因此,相比很多推荐算法随机留出一部分视频作为验证集,如下图 (a),这会泄露未来信息以及忽略视频共同观看不对称的情况。因此,预测用户的下一个观看视频会更好,如下图 (b),我们随机选择一个视频,并用此之前的用户行为作为网络输入。
5.2 排序模型
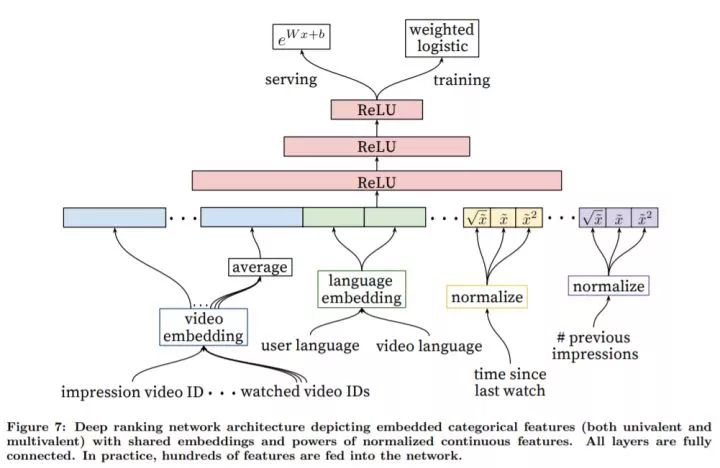
通过利用更多的特征,排序模型用来对召回模型的结果进行微调。如上图所示,排序模型和召回模型的网络结果很相似。
尽管深度学习可以学到合适的特征表示,直接输入原始数据效果不佳,我们花费了大量的时间进行特征工程。其主要挑战是如何表示用户行为的时序序列,以及这些行为和当前视频的关系,而后者最为重要。例如,考虑用户的观看历史和某个频道新上传的一个视频,之间的关系有:用户观看过该频道的视频数量、用户上一次观看过该主题的视频的时间。这些关系非常的有用,对于全异的视频之间泛化的很好。此外,把视频召回阶段的特征给排序模型也很重要。
输入特征包括用户登录状态(0/1)、用户上一次的搜索词、当前视频 ID、用户最近观看的 个视频的 ID、当前视频的曝光量等(给用户推荐了一个视频,但是用户没有看,应在后续推荐时对该视频降级)。此外,输入特征还包括几个 Embedding 特征,相同类型Embedding(如当前视频 ID、用户观看过的历史视频 ID、启动推荐的种子视频 ID)共享投影参数,不同类型 Embedding 独立学习其投影参数。共享 Embedding 对于提高泛化性能、加速模型训练、减少内存需求方面很重要。Embedding 的维度大致和词典的大小的对数成正比。当词典大小非常大时,我们按频次排序,取前
和树模型不同,神经网络对数据的数值范围和分布十分敏感,我们发现,对连续特征进行规范化很重要。给定连续特征 



现实中我们无法计算积分。在训练开始前,我们对所有数据遍历一遍,计算特征值的分位数,并用分位数的线性插值进行近似。除了使用 


关于优化目标,常用的优化目标是点击率,但是优化点击率会倾向于推荐标题党(clickbait)视频,用户通常不会完整看完该视频。因此,我们对观看时长进行预测,实际的目标函数是观看时长的一个简单函数。为此,我们在输出层使用加权对数几率回归。对于正样例(用户点击了该视频),根据观看时长进行加权,对于负样例(用户没有点击该视频),使用单位权重。这样,对数几率回归模型学到的几率(odds)是 






5.3 实验结果
对于召回网络,我们分别使用一百万视频和一百万查询词构建词典,变长视频和查询词输入的上限是 50,Embedding 特征是 256 维。Softmax 的输入是 256 维(可以认为是用户 Embedding),对这相同的一百万视频进行预测。
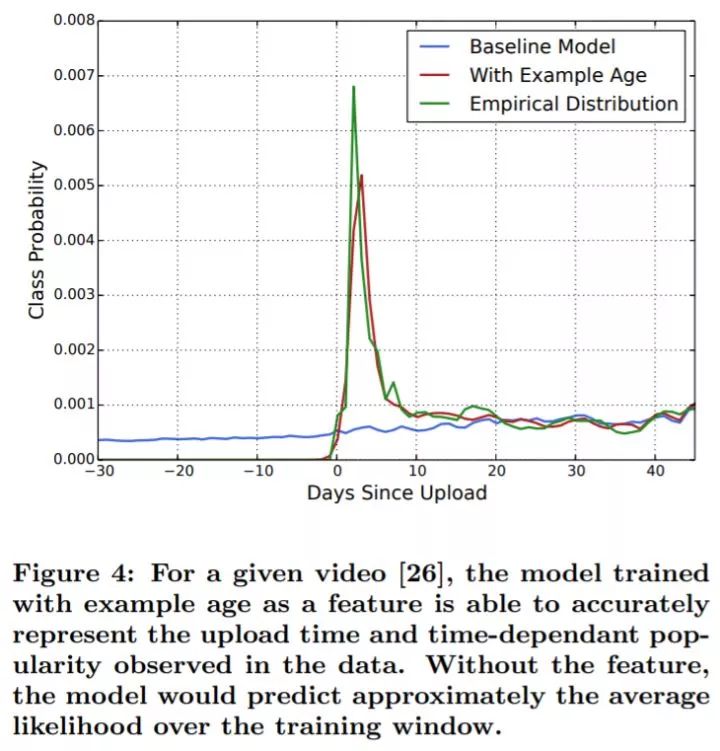
上图展示了召回网络中使用 Example Age 特征对一个随机选取的视频的效果。在 A/B 测试中,这可以显著的提高最近视频的观看时长。
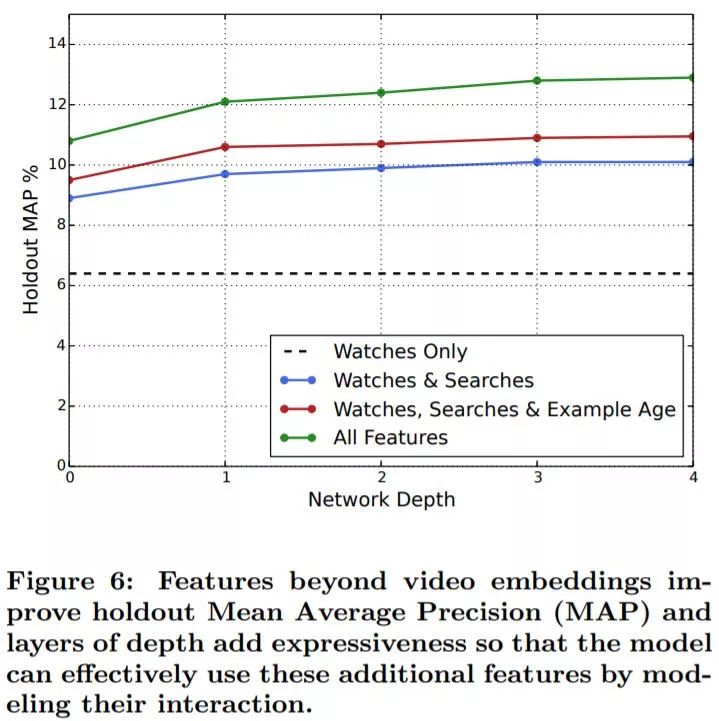
从上图可以看出,加深和加宽召回网络对结果的影响很显著。
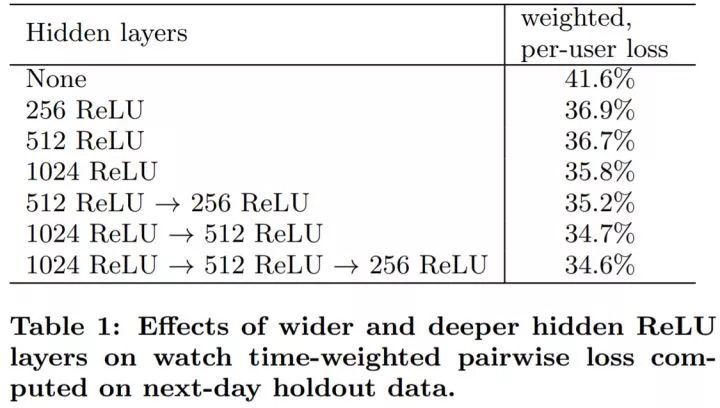
在上表计算评价指标时,我们同时考虑给用户推荐的一个页面中的正例(有用户点击)和负例(没有用户点击),我们首先通过模型对这两类视频进行打分,如果负例分数超过正例,我们认为正例的观看时长被预测错误,weighted per-user loss 是指预测错误的观看时长占总观看时长的比例。从上表可以看出,加深和加宽排序网络对结果的影响很显著。对于最后一行的网络结构( 
6. 基于多任务排序
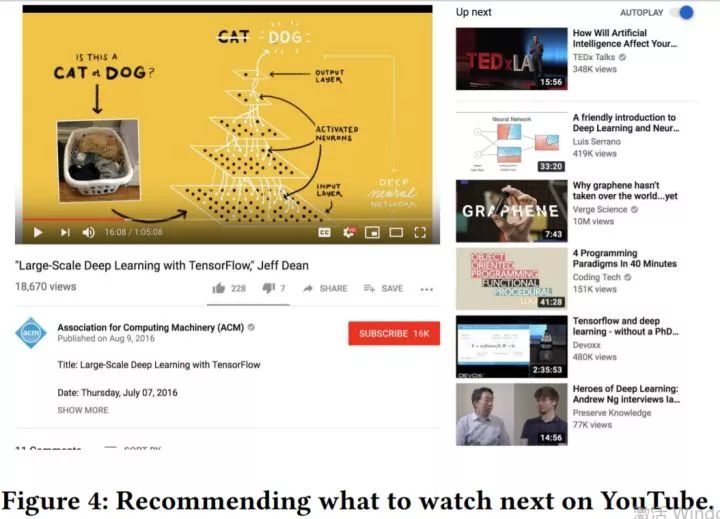
[Zhao et al., 2019] 旨在设计排序网络,用于给用户推荐下一个观看的视频(上图的 Up next)。现实任务中面临很多挑战,包括:
由于我们通常使用隐式反馈数据,无法直接得到用户对视频的喜好,我们需要优化一个代理问题来进行推荐。代理优化问题有多种选择,其中有许多甚至相互冲突的优化目标。用户有多种行为:如点击、评分和评论。用户可能点击了一个视频,但是并不喜欢该视频。除了想要用户观看之外,我们想要推荐一些用户评分很高并且想要给朋友推荐的视频。
系统通常存在隐式的偏好(bias)。用户观看了某视频可能只是因为它被排序在很前面,而不是因为用户最喜欢它。因此,用当前系统产生的数据进行训练将是有偏的,将会造成一个恶性循环。
本文使用的召回模型大致沿用 [Covington et al., 2016] 的召回模型。
6.1 排序模型
针对有多个目标需要优化的问题,多个优化目标包括两种类型:一种类型是参与度目标,例如用户点击和观看时长;另一种类型是满意度目标,例如用户对视频点赞、对推荐视频的评分等。我们将其转化为多个任务,每个任务是一个分类或回归问题,例如点击(二分类)、观看时长(回归)、点赞(二分类)、评分(回归)。最终对这些目标加权组合输出,权重是根据验证集合在线指标人工调节的。
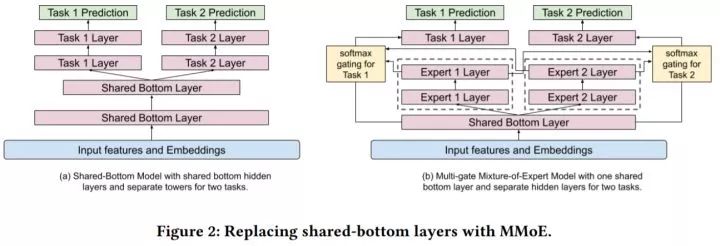
多任务学习通常共享底层的特征学习部分,如上图左所示,但是当多个任务之间的关系比较弱时,共享底层特征学习部分会限制学习能力。为了缓和学习多个目标的冲突,我们使用了多门控混合专家(Multi-gate Mixture-of-Experts,MMoE)在潜在可能产生冲突的目标之间来学习共享参数,如上图右所示。
混合专家将共享底层特征(Shared Bottom Layer)的输出 




有的工作在使用 MMoE 时会用很多的专家层,同时使用一个稀疏约束,为了提高训练效率,我们使用较少的专家数。此外,本文也尝试了门控网络的输入使用输入层,相比使用 Shared Bottom Layer,线上指标显示没有什么显著区别。
在面对大规模数据时,我们常常需要分布式计算,但这时常会导致模型训练发散,一个例子是 ReLU death。使用 MMoE 的学得的门控分布通常是不均衡的,在分布式训练中我们发现,大约 20% 的专家层对输出几乎没有贡献。为了解决这个问题,我们对门控网络使用 10% 的 Dropout,并重新对 Softmax 结果进行规范化,这解决了门控网络输出两级分化的问题。
针对系统存在隐式偏好的问题,为了建模和去除偏好,我们使用了一个小网络(Shallow Tower)对偏好进行建模,如上图右边所示。该网络输入和选择偏好有关的特征,例如当前系统的排序顺序,输出一个实数,作为主模型最终预测(MMoE 的输出)的偏置项。这个模型将训练数据的标记分解为两项:一个是从主模型学到的无偏的预测,一个是从小网络学到的偏好值。我们可以认为该模型是 Wide & Deep 的扩展,其中小网络是 Wide 模块。在训练的时候,小网络输入位置特征和设备信息,并使用 10% 的 Dropout,以防止网络对位置参数过拟合。使用设备信息的原因是,不同位置的偏好是在不同类型的设备上观测得到的。在部署时,我们将位置特征处理为缺失值。
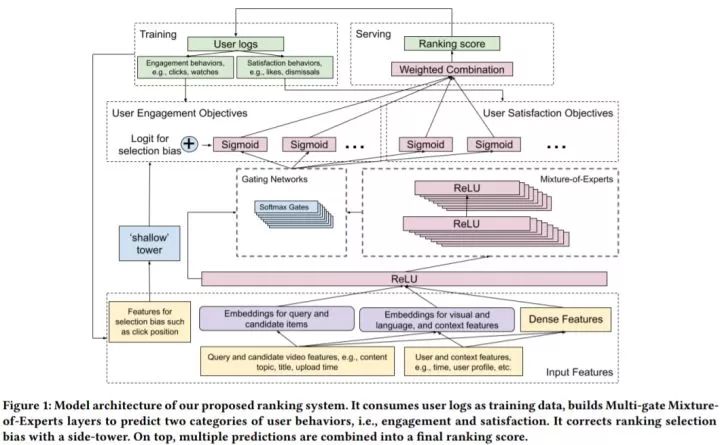
最终,排序网络如上图所示。关于排序网络的设计,有人将自然语言处理中的 Multi-head Attention 或计算机视觉中的 CNN 网络结构扩展到推荐系统中。我们发现,这样的网络不能直接满足我们的需要。这是因为:
多模态特征空间:这些特征包括了类别特征、自然语言、图像等。从这种混合特征空间中进行学习很难。
可扩展性和多优化目标:许多模型结构设计用来一种信息,如特征交叉或序列信息。这能提高一种优化目标的性能,但是会损伤其他的目标。此外,将多种复杂的模型结合起来会使整体模型难以扩展。
噪声和局部稀疏的训练数据:我们的系统需要训练 Embedding 层,但是大多数稀疏特征服从长尾分布,在用户反馈上有高方差(例如由于外界因素的一些变化,用户对相同的推荐结果可能点击也可能不点击)。
分布式随机梯度下降学习:由于数据量十分庞大,我们需要进行分布式学习,这本身带来了许多固有的挑战。
有效性和效率的折中:一个过于复杂的模型会减缓推荐响应速度,这会影响用户体验。因此,我们通常选择一个简单直接的模型结构。
线下指标和线上指标的差异:有时线下指标高不一定表示线上指标也高,因此,我们倾向于选择简单的模型,这样对线上指标有比较好的泛化能力。
训练时,我们按时间顺序提供训练数据,让模型消化新到来的训练数据。这样使我们的模型适应最新的数据。这对许多现实推荐任务很重要,这是因为用的行为的分布随着时间有剧烈变化。
6.2 实验结果

在上表,我们使用乘法次数度量模型复杂度。可以看出,在相同的乘法次数下,相比简单共享底层特征,MMoE 可以有效提高性能。
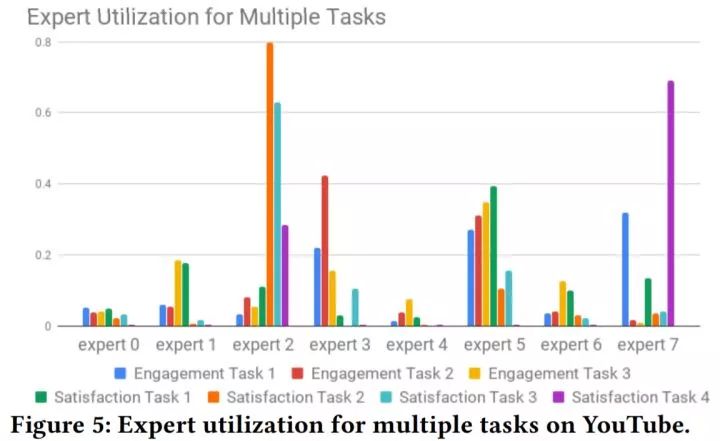
上图展示了门控网络的累计概率输出。可以看出,有的目标使用了多个门控(对应多个专家层)的结果。
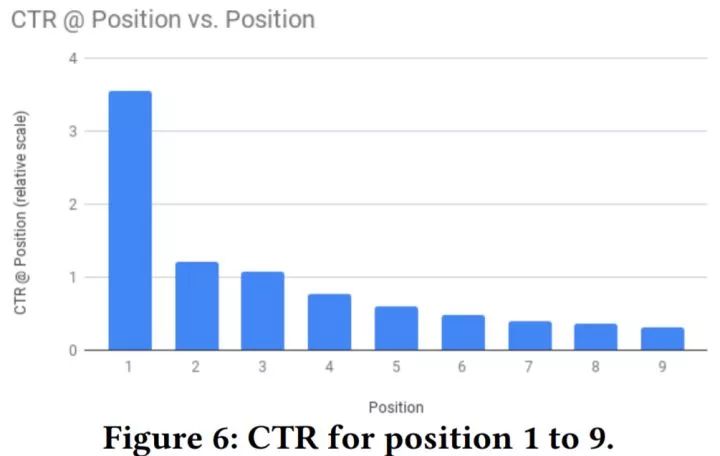
上图展示了不同位置的点击率(CTR)。可以看出,由于更高的位置推荐更相关的视频以及位置自身的因素,其有更高的CTR。
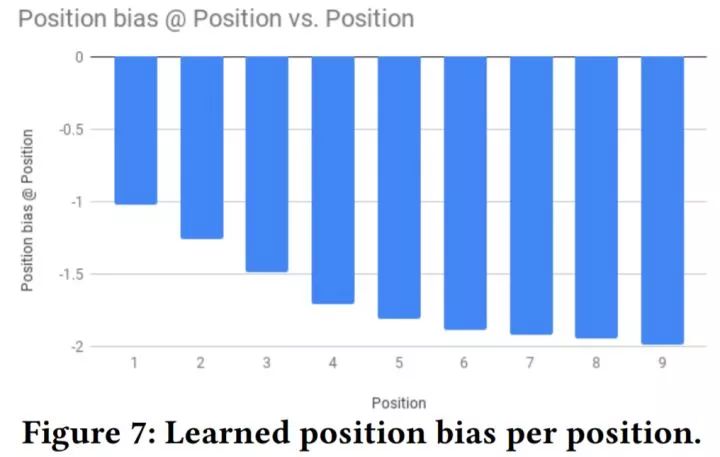
上图展示了不同位置学到的位置偏好。
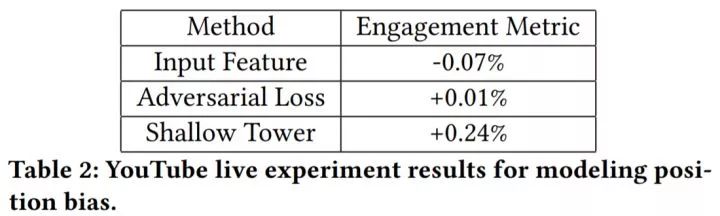
上图对比了三种方案:
直接使用位置特征作为输入特征(Input Feature):这是推荐系统广泛使用的方式。
对抗学习(Adversarial Loss):使用一个辅助任务预测训练数据的位置,在反向传播时,将梯度取反,保证主模型的预测不受位置特征的影响。
本文使用的小模型(Shallow Tower)。
可以看出,我们的方法效果最好。
本文转载自公众号:深度传送门,作者张皓
推荐阅读
AINLP-DBC GPU 云服务器租用平台建立,价格足够便宜
我们建了一个免费的知识星球:AINLP芝麻街,欢迎来玩,期待一个高质量的NLP问答社区
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLP君微信(id:AINLP2),备注工作/研究方向+加群目的。





