图灵奖大佬+谷歌团队,为通用人工智能背书!CV 任务也能用 LM 建模!

文 | ZenMoore
编 | 小轶
图灵奖大佬 Geoffrey Hinton 的团队和 Google Brain 团队近日发布新工作 Pix2seq,将 CV 经典任务 目标检测 转换为了语言模型的下游任务。
这就很有意思了朋友们!因为这是一个很一般化的范式!也就是说,不光是目标检测,我们 可以把语言作为中介接口,尝试将一切视觉上的任务映射为序列任务。这颇有点通用人工智能的意思。
所以,是不是万物皆可 LM 的时代真的要到来了?
论文标题:
Pix2seq: A Language Modeling Framework for Object Detection
论文链接:
https://arxiv.org/abs/2109.10852
![]() 模型框架
模型框架![]()
 模型框架
模型框架整个模型由四个部分组成,分别是图像数据增强,序列构造和数据增强,模型结构以及损失函数。
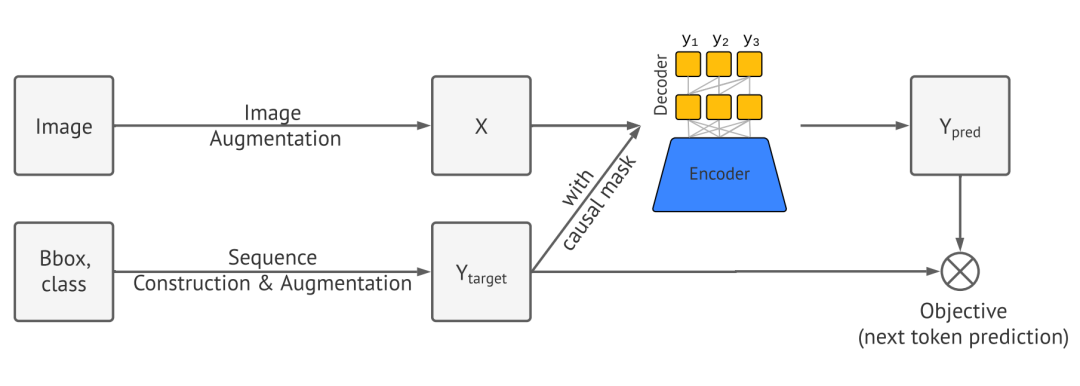
图像数据增强
图像数据增强没什么新奇的,就是为了扩充数据集,可圈可点的是后面几个部分。
序列构造
目标检测的目标一般是通过 Bbox 框和相应的目标类别组成。Bbox 用四个点的坐标组成 , 类别用一个指标变量 来表示。我们希望把这个目标输出转换为像语言一样的离散序列。主要是两个步骤:量化(Quantization) 和 序列化(Serialization)。
量化需要把连续的坐标均等地分为离散的坐标值,用 来表示(整数)。 的选取很讲究,可大可小,不同的大小决定了检测目标的大小尺度。例如, 的图像,最大的 可以是 . 实验表明, 就足矣!这样, 就可以表示成离散的 token. 还剩下一个 , 我们不用管,因为它本来就是离散的。
序列化需要把图像中的所有目标整理到一起。在量化中,我们把一个目标用五个离散的 token 来表示了,在这个步骤中,我们把图像中的多个目标的离散 token 表示按照一定的顺序线性地排列起来。实验证明,随机的排列顺序会取得更好的效果。
模型结构
本文采用的是编码器-解码器的结构,例如 Transformer. 通过自回归的方式生成输出序列。
损失函数
训练的目标非常简单,即语言模型中最普通不过的极大对数似然!四两拨千斤,简洁才是美!
其中, 和 分别是输入序列和目标序列(在一般的语言模型中,二者是相同的), 是目标序列长度, 是预先指定的第 个 token 的权重(本文都设置成了 1,当然也可以使用其他方式进行设置), 是给定的图像。
在 inference 阶段,我们根据条件概率对下一时刻的 token 进行采样,可以选择似然最大的 token, 但更好的方式是使用 Nucleus 采样,以提高召回率。最后,当得到 EOS 这个 token 的时候,结束生成,经过量化的逆操作得到 Bbox 和 Class.
序列数据增强
介绍到这里,好像一切都很完美......

问题出在哪儿了呢?实验表明,序列生成往往过早就结束了,导致很多目标都被漏掉了。可能是因为数据标注的噪声以及目标识别或定位的不确定性。所以作者想到的 trick 是:人为降低似然,延迟生成 EOS,提高召回率!然后就被打脸了......这又带来了很多噪声,以及重复的检测结果。
这又是为啥?作者觉得这主要是因为模型不依赖于任务,因为去掉了太多任务的先验知识。所以如果想要在 precision 和 recall 上打好这套太极玩好平衡术,还是得加点先验调一调味儿。于是天降猛料——序列数据增强!即:Altered sequence construction.
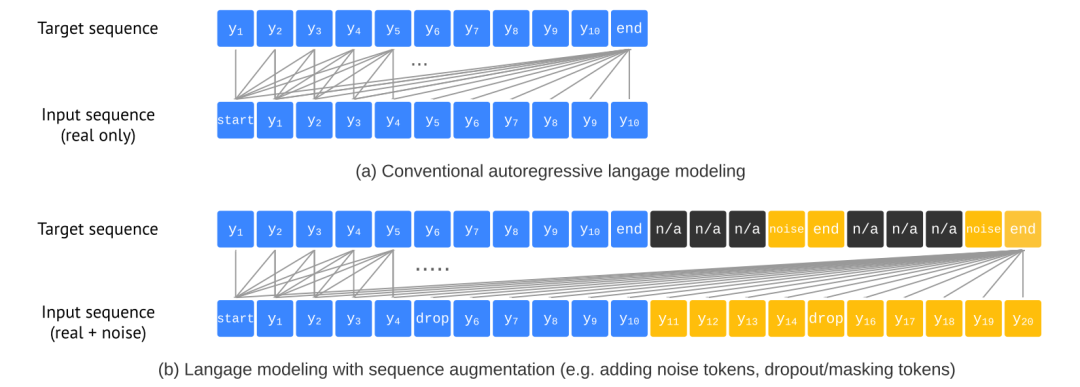
我们在输入序列 的后面加一些人为制造的噪声 token,可以是已检测出的真实目标的随机缩放平移,也可以是完全随机的 box 和类别。然后在目标序列 上,给噪声 token 设置成 “noise” 这个特殊的类别,相应的坐标都表示为 “N/A”, 损失权重 要设置为零。
因此在 inference 的时候,我们让模型预测最大长度的序列,在重构 box 和 class 的时候,用似然最大的实际类别替换 noise 类别,并将似然作为其打分。
看到这里,不得不说,Hinton 不愧是 Hinton... 这也能搞 work...
![]() 实验结果
实验结果![]()
实验结果非常的够看啊!
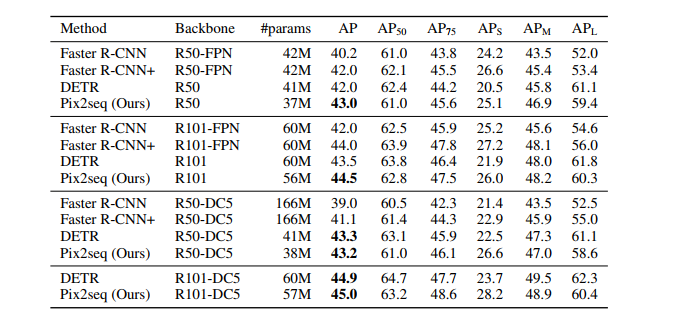
总结一下主要是以下两点:
-
对标 Faster R-CNN : 小中型目标差异不大,但在大型目标上,本文的模型表现更好! -
对标 DETR : 大型目标上差异不大(或者略差一点), 但在小中型目标上,本文的模型表现突出!
![]() 结论
结论![]()
Pix2Seq 是一个简单而通用的目标检测框架,简化了目标检测的 pipeline, 消除了大部分先验知识,效果也非常能打!当然,这个架构还可以进行进一步地优化。
作者认为,这个框架不仅适用于目标检测,其他产生低带宽输出的视觉任务(即输出可以用简洁的离散 token 序列表示)也可以尝试用这个框架来解决。因此,作者希望将其做成一个通用统一的接口以解决各种各样的视觉任务。另外,也希望能让模型减少对于人工标注的依赖,多一点无监督学习的能力。
![]() 最后的话
最后的话![]()
小编认为,这是一个很有开创性意义的工作,或者说学术思想。从哲学的角度讲,如果我们信奉 萨丕尔-沃尔夫假设(语言决定思维) 的话,就很容易坚信自然语言的伟大潜力。人类用语言描述世间万物,下到家常小事,上到天文地理,所有的任务,都可以用自然语言来表示输入和输出,因此我们坚信语言具有非常强大甚至是接近于无限的表达能力:Language is the embedding of everything ! 回到本文,Hinton 成功地将目标检测这一个典型的视觉任务转化成了语言的任务,那么我们是不是可以猜想,一切任务都能用序列来解决:All in Seq ! 如果真的如同萨丕尔和沃尔夫所说,人类的思考过程都是基于语言的(即人类通过心中语言整理和推演自己的思路),那么,我们是不是可以不断地发掘本文的潜力,找到机器推理的密码?Hinton 作为心理学家出身的 AIer,不知道对此究竟是怎么思考的......
所以,是有一个 “宇宙” 蕴含在这篇论文中的!欢迎大家进行思考与讨论,即便是科幻也无妨(比如在知乎上或者评论区等等)。
后台回复关键词【入群】
加入卖萌屋NLP/IR/Rec与求职讨论群
后台回复关键词【顶会】
获取ACL、CIKM等各大顶会论文集!
![]()
 后台回复关键词【
后台回复关键词【



