实战解析:真实AI场景下,极小目标检测与精度提升 | 百度AI公开课
主讲人 | 哈利 百度高级研发工程师
量子位整理编辑 | 公众号 QbitAI
目前,各个企业行业在AI落地应用中,常常会遇到极小目标检测问题。在这些AI应用中,都需要在一个大图中精准识别出极小目标,其检测至关重要,也面临很多难点。
比如,检测框高宽比不固定,图片背景杂乱,数据源稀缺,检测框相比图片非常小,这些难点都会导致较高的漏检率。
10月21日,「EasyDL AI开发系列公开课」第一期直播中,百度高级工程师以真实的产业场景为例,深入解析了如何解决这些难点、有效提高极小目标检测的准确率,并手把手演示了如何用EasyDL构建高精度物体检测模型。
讲解分为4个部分:
EasyDL平台整体介绍
物体检测任务综述
极小目标检测场景难点分析以及效果的优化
EasyDL经典版实操演示
直播回放见链接:https://www.bilibili.com/video/BV1wv411C7QN
系列课程报名见文末海报哦~ 以下为直播文字实录:
EasyDL平台介绍
在和某咨询公司的联合调研中,我们发现有86%的市场需求需要定制开发业务场景下的AI模型。比如工业场景需要统计原材料的数量,食品安全场景需要监测厨房厨师是否佩戴安全帽,在零售场景需要检查货品的陈列是否满足标准……诸如此类的定制化需求,难以用统一的、标准化的服务去涵盖,是需要定制开发的。

△需要定制开发AI模型的场景
2017年到2020年,百度AI开发平台收到的定制化需求增长速度非常快。但是我们知道,机器学习系统构建涉及到非常多的模块,这些模块的组合开发具有很大的挑战性,需要投入大量的人力来做。因此,百度也总结了AI定制需求开发与应用中的核心的痛点:
第一个痛点:数据。用户很难获得和场景匹配的数据,并且数据清洗标注、数据的多样性等方面都存在一些问题。
第二个痛点:开发训练。用户开发模型的成本非常高,算力资源不足,算法的调优比较困难,并且训练耗时长。
第三个痛点:部署。部署的成本非常高,难以落地,模型的适配、迁移难,并且还会有重复开发,预测性能差,硬件成本高等问题。
为了解决这些痛点,百度面向AI开发全流程,提供了一站式的AI开发平台—EasyDL。EasyDL主要分成三个部分。

第一部分是智能数据服务(EasyData),包括数据采集、数据清洗、数据扩充、数据标注四大能力。
EasyData智能数据服务大幅降低了AI定制模型的数据成本。用户如果需要进行全流程的数据采集、数据标注、模型迭代,就会涉及非常多环节,而且需要不断的迭代。而EasyData把整个流程抽象成了5个模块:软硬一体数据采集方案,自动数据清洗/扩充,智能标注,模型训练与发布,自动数据闭环。通过这五大模块的能力,帮助用户把数据采集、模型训练以及最后人工部署的成本都尽可能降低。

第二部分是开发与训练,提供了AutoDL工具,帮助用户自动进行模型调优;并引入了百度自有的超大规模预训练模型,并且预置了很多场景化算法和网络;在训练方面提供分布式训练加速的能力。
EasyDL训练平台可以帮助用户使用更少的数据,获得更优的效果,而且训练速度更快。具体来说,基于百度自研的大规模预训练模型,大幅降低了数据成本;模型的调优方面,采用了领先的AutoDL技术;在训练方面,应用了飞桨内的训练加速机制。

第三部分是端云一体服务部署,支持公有云部署、私有化部署和设备端部署(EasyEdge)。
EasyDL提供了灵活丰富的服务部署形态,包含公有云部署、本地服务器部署、设备端SDK以及软硬一体产品。

以上是EasyDL在移动端/设备端的应用案例,以深圳旅影为例,用户训练一个场景识别的模型,仅仅迭代两版就获得了97%以上的准确率,效果非常不错。
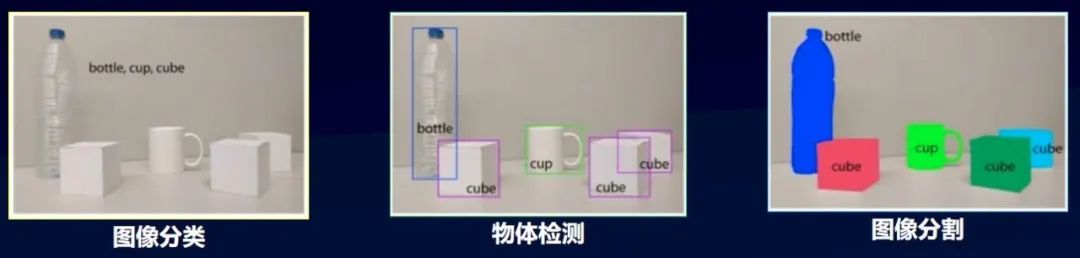
EasyDL目前支持的图像任务类型包括图像分类、物体检测、图像分割。在企业应用中,图像分类和物体检测占比较高,因此百度在这两方面投入了很多的人力来进行优化。
物体检测任务综述
物体检测定义
物体检测是指,给定一张图片,识别出图片中的物体属于哪个类别,并对相应的物体进行位置的定位。

物体检测技术已经发展了很久,从13年至今,主要有两个方面的发展,一是两阶段检测器,二是单阶段检测器。总体来说技术朝着越来越自动化、越来越高效的方向发展,来满足商业化的需求。
检测器的通用框架
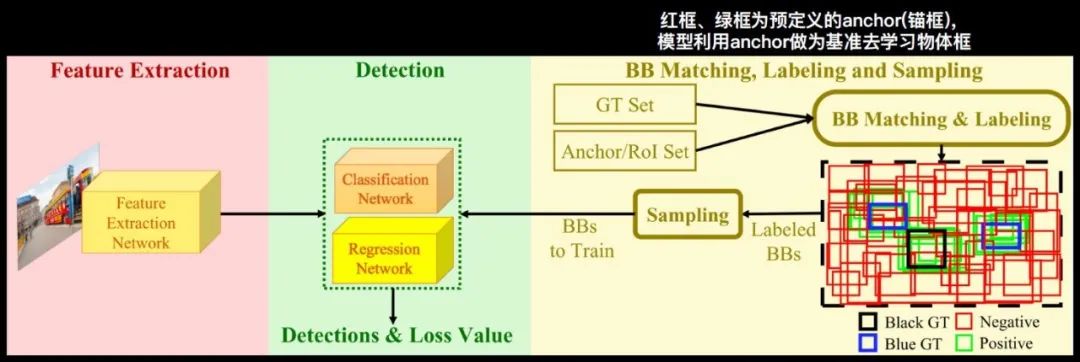
第一个部分是Feature Extraction特征提取模块,图像通过这个网络可以提取出相应的特征。
第二个部分是bonding box Matching,Labeling and Sampling模块,输入一系列的物体标注框,会有一系列的anchor(锚框),比如上图最右边的红色和绿色框就是我们预先定义好的anchor,模型就会用这些anchor作为一个基准,再去学习物体的定位。有了这些anchor之后,我们要和这些GT框进行匹配,去挑选出与物体比较吻合的框,称为正样本,就是绿色的框,不符合的框是负样本。
从上图中可以看出,这里的负样本的数量非常多,无法直接拿来学习。所以接下来要增加一个采样的模块,挑选出适合模型训练的正负样本,再输入到下一个模块—Detection检测器,并进行分类网络和回归网络的学习。
极小目标检测场景难点分析及效果优化
以COCO数据集中的物体定义为例,小物体是指小于32×32个像素点。在实际场景中,我们更倾向于使用相对于原图的比例来定义。

因此,我们给出相对的定义,物体标注框的长宽乘积,除以整个图像的长宽乘积,再开根号,如果结果小于3%,就称之为小物体。

常见的极小目标检测场景如图示。这些检测场景有什么难点呢?总结来说:
难点1:检测框的高宽比多变,甚至出现极端的高宽比,漏检率比较高;
难点2:背景杂乱,误检率比较高;
难点3:数据源稀缺,没有丰富的数据训练;
难点4:图片非常大,检测框非常小,所以漏检率高。
优化案例1:以货架挡板检测场景为例

如图中绿框所示,货架挡板检测的难点在于货架挡板的高宽比非常极端,我们先选一些基础的模型来训练。
比如我们取SSD、YOLO、Faster RCNN等,就发现Faster RCNN达到了最好的效果—0.812。怎么进一步优化呢?
针对上述难点1,业界有Anchor自适应算法可以解决这类问题:
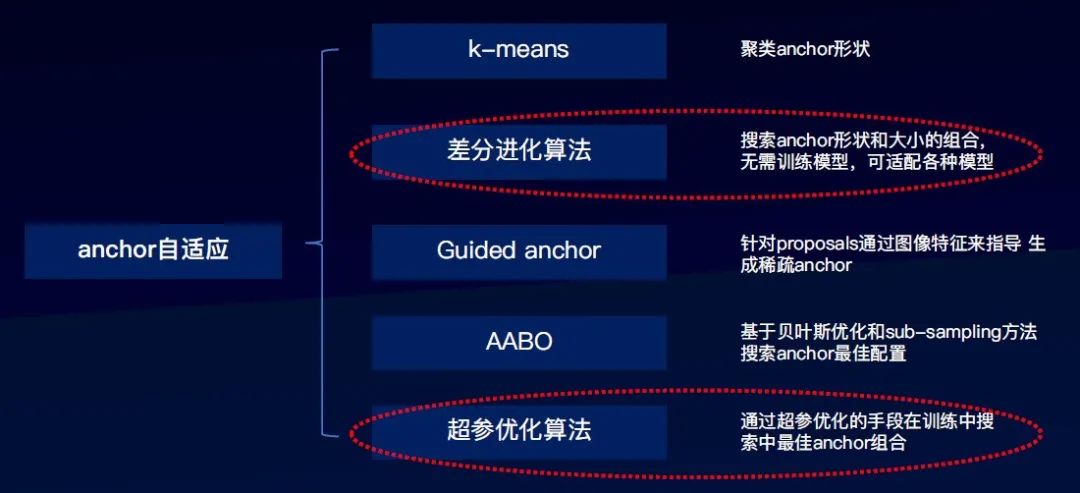
△Anchor自适应算法概览
我们重点介绍差分进化算法、超参优化算法这两种具有通用性的技术。
1、差分进化算法
其特点是简单、高效、可拓展。搜索超参是anchor的高宽比和尺度,优化目标是所有检测框与匹配的anchor的iou总和最大。
算法上,第一步是初始化种群。第二步是开始迭代的差分进化,保留优秀个体,淘汰劣质个体。包含变异-交叉-选择3个操作:
变异:从种群中随机挑选两个个体,用一定的规则去产生一个变异个体;
交叉:变异个体与事先指定的某个目标个体进行参数混合,生成实验个体;
选择:将实验个体的优化指标与目标个体进行对比,保留优化指标较好的个体;
以上3个操作迭代循环,实现优胜劣汰的能力。
这个方案的优点就是速度快,无需训练模型,并且可以广泛的适用于各种检测模型,这种算法已经在EasyDL经典版上集成了。
2、超参优化算法
其特点是优化目标和训练模型是一致的。优化目标是训练中的模型指标(AP)最优,可以运用贝叶斯优化、进化算法等超参优化算法。
优点是以模型评估指标作为优化的目标,效果更佳,并可广泛适用于各种检测模型。
其缺点是比较耗费计算资源。但是相关算法能力已经在EasyDL专业版集成,用户可以通过EasyDL专业版创建项目,实现自动超参搜索。
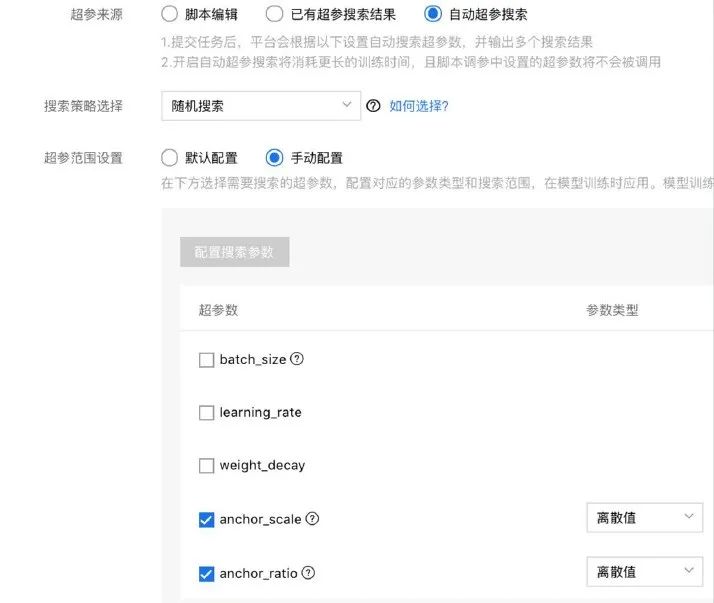
货架挡板检测优化—anchor优化
我们将anchor自适应的方法应用在本案例上。相对于默认ratios来说,自适应算法算出了5个比例,也就是说5个比例比较适合于这个模型。

我们用anchor自适应的算法进行优化,效果从0.812提升到0.87。
那么如何进一步优化?我们之前提到了难点2(背景杂乱)和难点3(数据稀缺),现在继续采用自动数据增强的方案,去优化数据本身。

△自动数据增强算法概览
我们概览下自动数据增强的一些主要算法。AutoAugment是第一个能得到很好效果的增强算法,但其搜索成本很高。
PBA算法采用优胜劣汰的思路,在多个网络的并发训练中不断“利用”和“扰动”网络的权重,以期获得最优的数据增强调度策略。这个思路直觉上是可以通过优胜劣汰来搜索到最优策略。
DADA借鉴了DARTS的可微设计思路,搜索成本低,但增强算子权重梯度更新的方式限制了数据读取速度。
以PBA为例,其特点是灵活、可拓展。
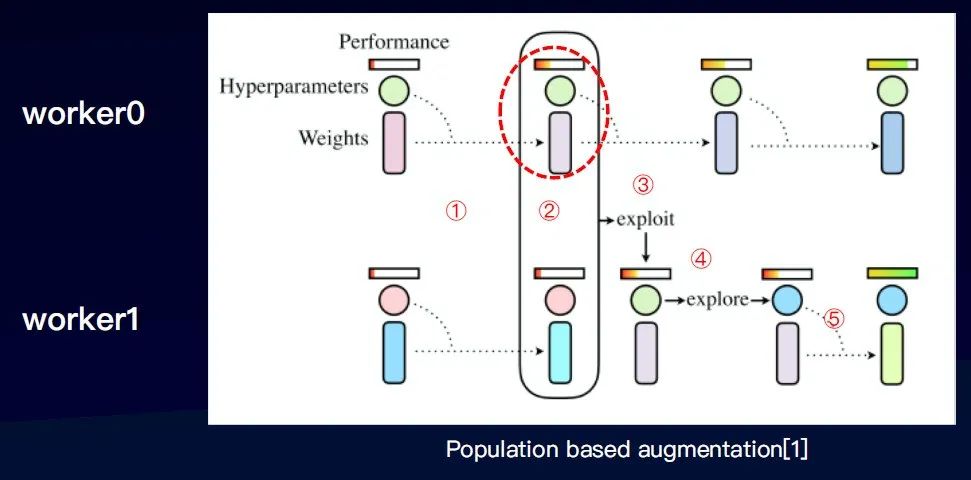
如图,起两个进程分别训练模型,训练模型的主要参数一是超参,另外一个是权重(模型本身的参数)。
通过第一步训练,第二步需在某一个时间点,比较两个进程的效果,效果更优的进程就会取代效果差的进程的权重。第三步,直接复制权重。第四步,扰动原来的超参,产生一组新的超参,并继续训练。
迭代循环这个训练流程,就可以产生一个增强算子的调度组合,并且是比较适合于这个数据集本身的。
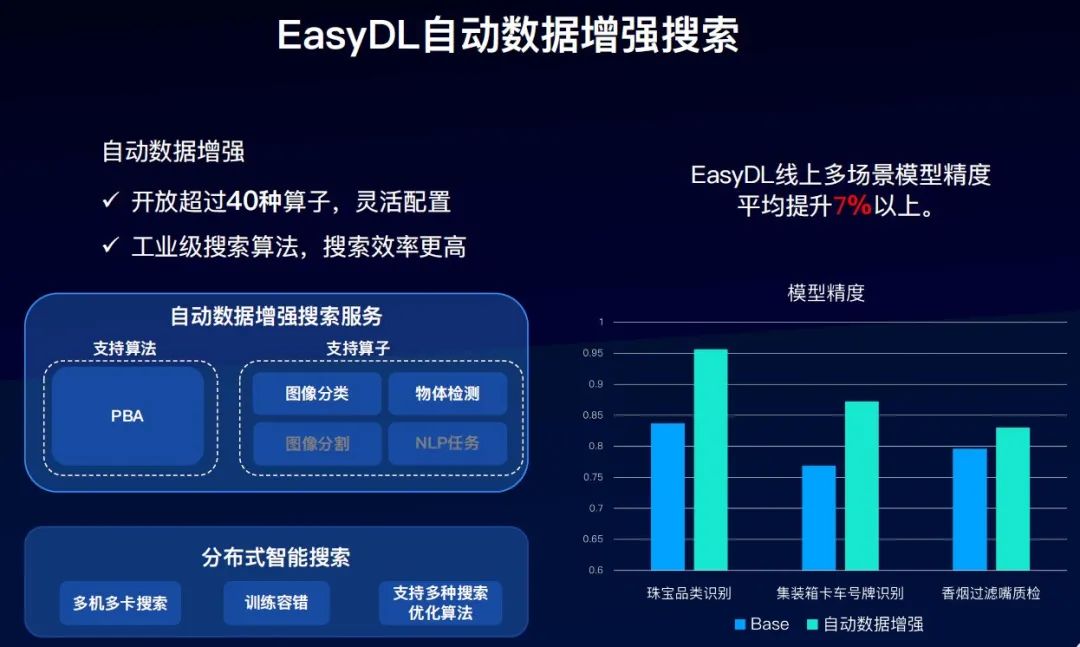
EasyDL也上线了自动数据增强搜索的能力,基于百度自研的分布式智能搜索的能力,目前支持PBA算法。算子方面,支持图像分类和物体检测两种,开放了超过40种的算子。
并且提供了工业级的搜索算法,搜索的效率更高。在EasyDL线上的多场景模型精度上,平均提升了7%以上。
货架挡板检测优化—自动数据增强
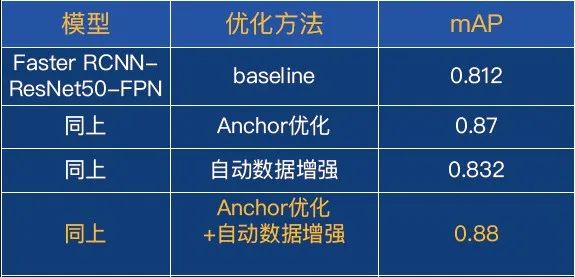
我们把自动数据增强应用在货架挡板检测案例上,从原来的0.87提升到了0.88。
我们再考虑一个问题,模型训练本身的超参非常多,如何才能搜索出最佳超参下的效果呢?
我们可以采用自动超参搜索的技术。
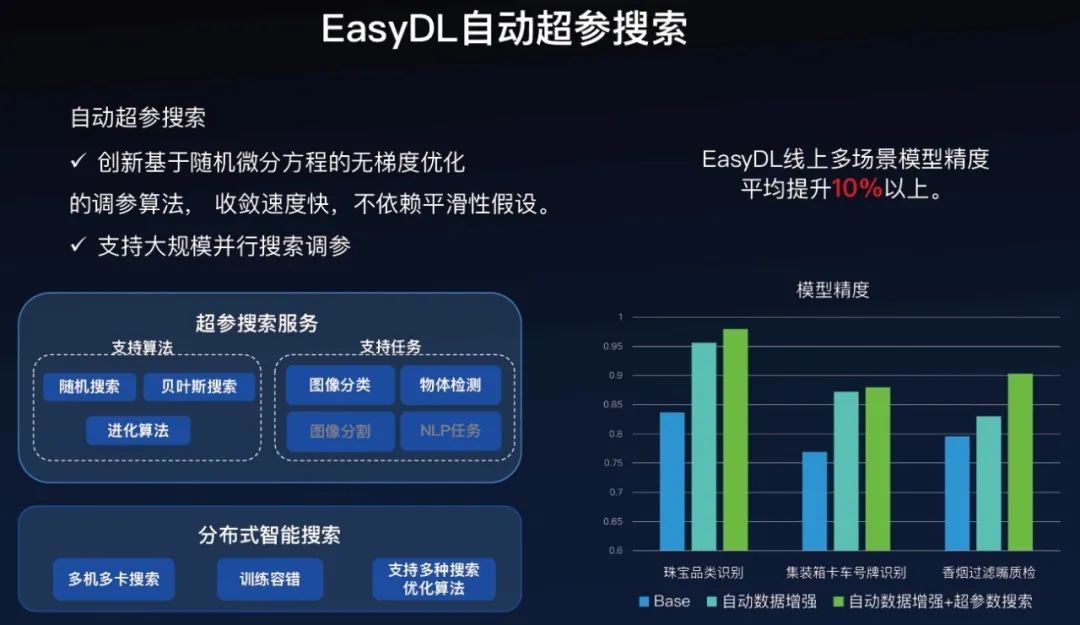
EasyDL的自动超参搜索技术是基于百度内部的分布式智能搜索服务,目前支持随机搜索、贝叶斯搜索和进化算法三种算法,支持图像分类和物体检测两类任务。
有两大特点,一是其中的一些算法可以进行无梯度优化,不依赖于平滑性假设。二是支持大规模并行搜索调参。
在EasyDL线上多场景上面,加上我们自动数据增强,再加上超参搜索,检测精度平均提升10%以上。
货架挡板检测优化—自动超参搜索效果
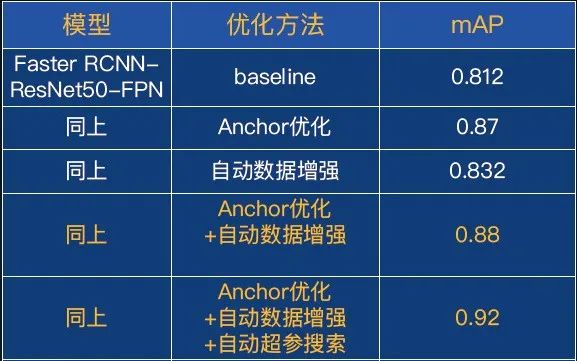
继续把自动超参搜索应用到本案例中,效果从0.88提升到0.92。总体来说,我们通过一系列的效果优化,从最初的0.812提升到了现在的0.92,效果上非常可观。
优化案例2:以电力巡检缺陷检测为例
接下来我们再看电力巡检缺陷检测案例的优化。这个案例的难点在于图片非常大(4k分辨率),但是检测框却非常小,所以其漏检率非常高。

首先,选择一个基础模型,这里选择了retinanet和Faster RCNN,mAP最高是0.61。
anchor自适应优化

接下来用anchor自适应优化进行调节,蓝框是K-means聚类的结果;粉红框是差分进化的结果,可以看出差分进化算法在匹配效果上更加优秀。
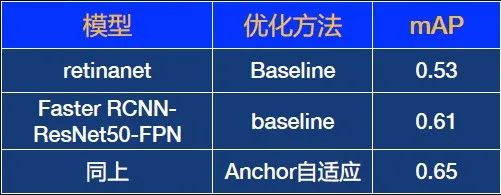
利用anchor自适应优化算法,检测结果从0.61提升到0.65。效果有所提升,但对于商用场景来说不够理想。那么,如何从根本上提升效果?
自动切图优化
这里涉及到了上述的第4个难点,图片非常大,检测框非常小。因此,这里就考虑用到自动切图技术,既能够不放大图片尺寸,又能够放大检测目标。

我们把这张图切成了9个子图,9个子图有一定的相交。问题是这9张子图全部都要参与训练,也就是会增加9倍的简单的负样本,而且模型并没有可以选择的机会。就会导致模型越学越简单,无法检测很难的案例。
如何解决这个问题?首先,挑选出包含较难负样本的Negative chips切图,把包括这些较难的负样本的区域提取出来,作为一个子图,实现自动挑难负样本的能力。

△SNIPER-正样本切图策略
其次,用切图代替原图,并降低计算量。
SNIPER论文考虑到了这个问题,以正样本的切图为例,小尺寸图对应小GT框。

△SNIPER-负样本切图策略
对于负样本,则先训练几个epochs,使模型具有一定的分辨能力,标记假阳性的难负样本,并学习错误的样本。通过这种方式,可以找到最难的一批负样本切图。
接下来,把这些正负样本切图直接送入到模型的训练中。SNIPER切图技术本质上就是一种切图采样策略,也就是说,针对任意一个检测器,都可以采用这样的前置策略。
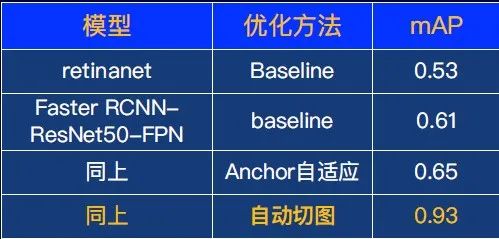
回到案例,采用这种自动切图技术,效果从0.65直接提升到0.93,这个效果的跨越幅度非常大。这也证明了自动切图算法能够从根本上能够解决小目标检测的问题。
EasyDL经典版实操演示

详细操作指南可参考官网介绍文档,或参考直播回放视频,这里不再赘述:
使用文档:https://ai.baidu.com/ai-doc/EASYDL/qk38n31an
直播回放:https://www.bilibili.com/video/BV1wv411C7QN
直播预告
端计算模型目前已应用到各行业的AI技术实践中,如部署在野外气象观测点用于环境监测,以及响应垃圾分类政策用来打造智能垃圾桶等等。
10月28号,第二期「EasyDL AI开发系列公开课」直播中,百度高级研发工程师将深入讲解如何优化端模型识别速度、如何解决端模型部署问题,同时手把手直播演示如何使用EasyDL&EasyEdge进行模型训练和端模型部署。
▽扫码即可免费报名,还为大家精心准备了小礼物哦~

One More Thing:
为了进一步降低企业应用AI的门槛与成本,EasyDL还重磅推出「万有引力」计划,为有AI应用需求的企业提供专项基金,详情请点击「阅读原文」。
— 完 —
本文系网易新闻•网易号特色内容激励计划签约账号【量子位】原创内容,未经账号授权,禁止随意转载。

量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态
一键三连「分享」、「点赞」和「在看」
科技前沿进展日日相见~


