【Nature.Com】因果推断在医药图像的应用:数据缺失和数据不匹配
导语
医学图像的机器学习面临两个主要挑战:高质量标注数据的缺失,以及开发数据集和目标环境之间的不匹配。因果推理可以为此提供新视角。此前发表于 Nature Communications 的论文 Causality matters in medical imaging 从因果关系的角度看待这些问题,强调了在图像及其注释之间建立因果关系的重要性。在集智俱乐部因果科学读书会第三季,北京大学数学科学学院的王浩翔详细介绍了这项工作,本文是分享的文字整理。
研究领域:因果推断,机器学习

张伟琨 | 作者
梁金 | 审校
邓一雪 | 编辑

论文题目:
Causality matters in medical imaging
论文链接:
https://www.nature.com/articles/s41467-020-17478-w
一. 数据不完整面临的问题
一. 数据不完整面临的问题
在数据处理方面,数据缺失,主要是高质量数据缺失,或带有标签数据的缺失,主要是高质量标签图像(如CT或MRI数据)缺失。数据不匹配,主要指居住环境训练的机器学习模型,在实际世界的应用效果并不好。例如,临床上,研究者主要关注一些高质量数据,现实世界存在大量没有标签数据或是其分布不能得到有效控制的数据。在这种情形下,机器学习模型中测试效果并没训练的较为乐观。
在传统因果框架中,给定X和Y为带标签的数据,X为输入图像数据,Y为目标预测数据,Z为疾病的特征。在因果关系中,X是产生Y的原因;在反因果关系中,Y产生X,即由外产生X。传统因果关系采用数据回归工具进行识别,事实上,基于材料信息的识别可能更有效。以下图为例:a图为采用皮肤癌来产生图像,进而产生所谓的疑似的判断,最后进行活体组织切片检查(biopsy),然后反过来进行判别,即通过图像识别因果类型;b图为前列腺癌例子,病例产生图像,根据图像进行分区,然后对器官或病例产生的病症进行分化,再对此进行实际估计。
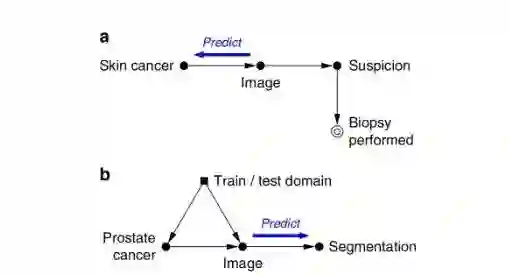
采用图像识别预测因果关系可能更有效。
二. 数据缺失问题如何解决?
二. 数据缺失问题如何解决?
怎么解决现实世界中数据缺失的问题?在现实世界中,对一个数据打标签,是比较耗时或耗经济成本的,采用半监督学习可弥补这一缺失。半监督学习的应用,需要如下的前提:数据存在自然聚类,即在输入空间的数据点存在偏向分布的高密度区域;如果数据偏向低密度区域,采用半监督方法产生的拟合决策边界,通过此边界进行划分,并进行补漏。如果预测任务是因果的(X, Y),那么P(X)相对于P(Y, X)是无信息的,半监督学习在这种情况下理论上是无效的。只有P(X)与标签条件P(Y|X) 的相互作用,半监督学习才有效。适当调整的纯监督模型和在相关标记数据集上预训练的模型(即迁移学习)通常与半监督对应物具有竞争力或优于它们的半监督对应物。在标记和未标记集合之间的目标偏移(稍后讨论为流行偏移)下,半监督学习会损害分类性能。
通过数据扩充解决数据稀缺问题。数据扩充是指系统地对数据应用随机的、受控的扰动,以产生额外的可信数据点的实践。许多任务要求预测对某些类型的变化不敏感。示例包括图像强度增强,例如直方图处理或添加噪声,以及用于图像级任务(例如回归或分类,如在皮肤损伤示例中)的空间增强(例如仿射或弹性变换)。因为这些扩充统一应用于所有输入X而不改变目标Y,所以它们的好处来自于对条件P(X, Y)的精确理解,同时没有贡献关于P(Y)的新信息。对于其他任务,例如分割或定位,预测必须类似于输入而改变,例如应用于图像x的空间变换——例如镜像、仿射或弹性变形——应该同样应用于目标y(例如空间坐标或分割掩模,如在脑瘤例子中)。通过其共享的空间结构获得关于关节分布的信息,例如与解剖和采集条件相关的信息。与半监督学习相比,数据扩充产生额外的(X, Y),从而提供关于联合分布P(X, Y)的更多信息。对联合P(X, Y)的复合效应而不仅仅是对边缘P(X)的复合效应证实了,更是因果和反因果任务的适用性。
三. 数据不匹配问题如何解决?
三. 数据不匹配问题如何解决?
数据不匹配会导致训练集和测试集的数据分布不匹配,从而损害学习模型的可泛化性。因果推断帮助我们认识到在某些特殊情况下,直接概括是可能的,并设计出原则性的策略来减轻偏见。可以分为两部分:数据集偏移和样本选择偏差。
在数据的不匹配方面,表现为:
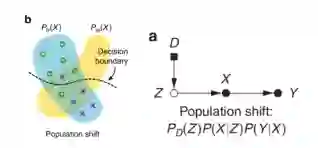
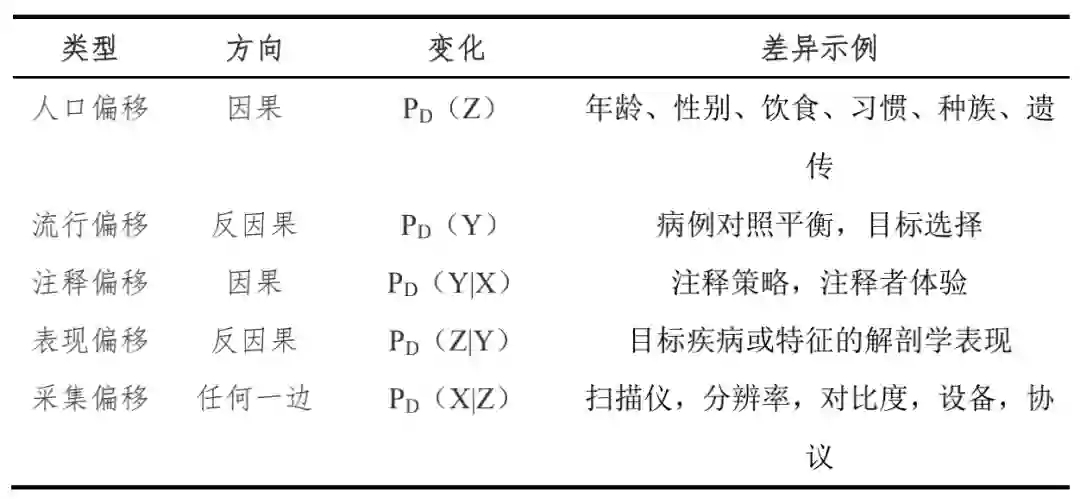
数据迁移:人口迁移。主要表现为人群疾病分布和斜率不同,指的是样本中人口的内在特征(例如人口统计学)不同,即。但是,该统计结果可以直接移植,即在一个域中估计的预测值在另一个域中同样有效。这是一种常见的缓解人口转移的策略。存在一个局限性是,只有当训练数据的可变性涵盖了测试分布的支持时,它才有意义,即不能保证对训练环境中缺失的变化模式的外推性能。需要以加权分类器处理,即
。
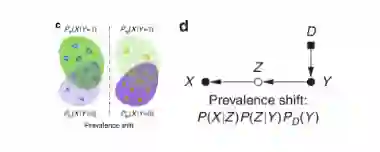
数据迁移:流行迁移。数据集之间的差异与类别平衡有关: 。一般,由环境因素的变化引起,或是流行率的转变中训练和测试人群中不同素质引起的。如果测试类分布Pte(Y)是先验已知的(例如,根据流行病学研究),则生成模型可以在贝叶斯规则中重用估计的外观模型 Ptr(XY ) (= Pte(XY))。对于判别模型,可以通过
进行加权,校正估计训练损失中的偏差。
数据迁移:注释转变。相同的数据在每个领域的标签可能不同:。参与国际项目的一些医疗中心可能会执行稍微不同的注释政策或分级标准,或者雇用具有不同专业水平的注释者(例如,高级放射科医师与实习生)。没有对这种变化背后的机制的明确假设,被训练来预测Ptr(YX)的模型显然不能被期望在测试环境中明智地执行,并且没有明确的解决方案可以被设计,可能需要冗长且耗时的标签校准或(部分)重新注释来校正注释偏移。
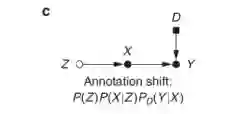
数据迁移:表现转移。反因果预测的物理表现形式是域间的解剖学变化。。与注释的变化一样,如果没有对这些差异的本质进行强有力的参数假设,这种变化就无法得到纠正。
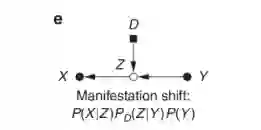
数据迁移:采集偏移。由于使用了不同的扫描仪或成像协议,导致了采集偏移,这是医学成像中最臭名昭著和研究得最充分的数据集偏移来源之一。缓解这一问题的典型管道包括空间对准(通常通过严格配准和重采样到共同分辨率)和强度归一化。对于特殊领域(如图像合成)和适应研究领域需要使用复杂的转换,如提取领域不变表示或图像形态之间的转换,如合成MRI形成CT图像。
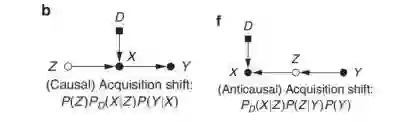
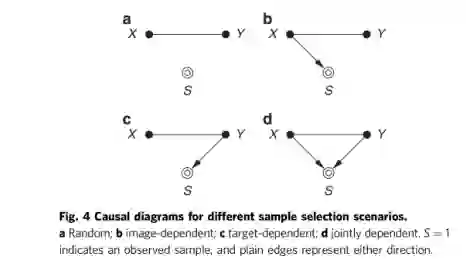
数据迁移:样本选择偏差导致的数据不匹配。训练和测试队列来自相同的人群,并被接受(S = 1)或拒绝(S = 0)。当选择仅依赖于图像(X→S)或目标(Y→S)时,它可以以类似于数据集移动的方式处理。当选择仅依赖于图像(X→S)或目标时(Y→S),虽然在第一种情况下,但目标函数可以有偏倚,可以采用相应的方法减轻数据集的偏移。当选择变量S是X和Y的共同效应时,就会出现选择偏差,一般情况下需要控制额外的变量,通过对撞机S的调节来消除X对Y的间接影响。

专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“CIMM” 就可以获取《【Nature.COM】因果推断在医药图像的应用:数据缺失和数据不匹配》专知下载链接







