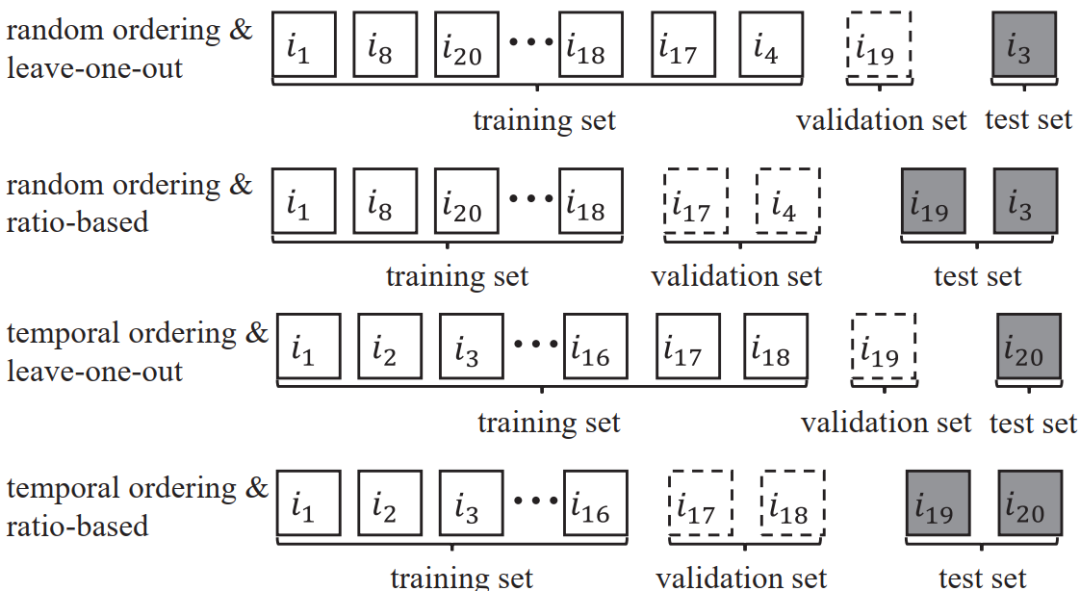
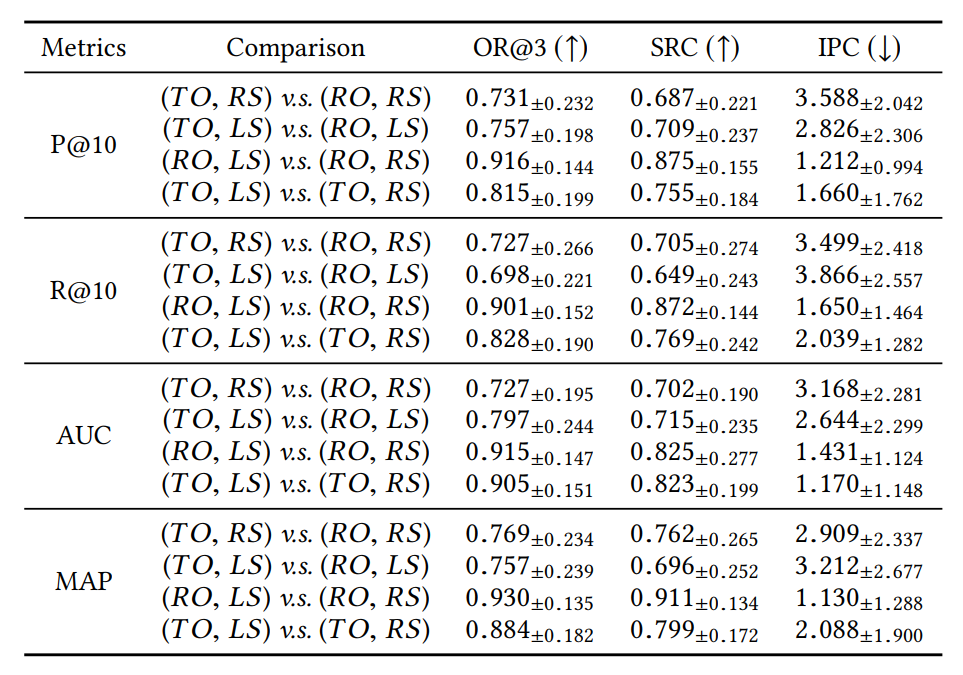
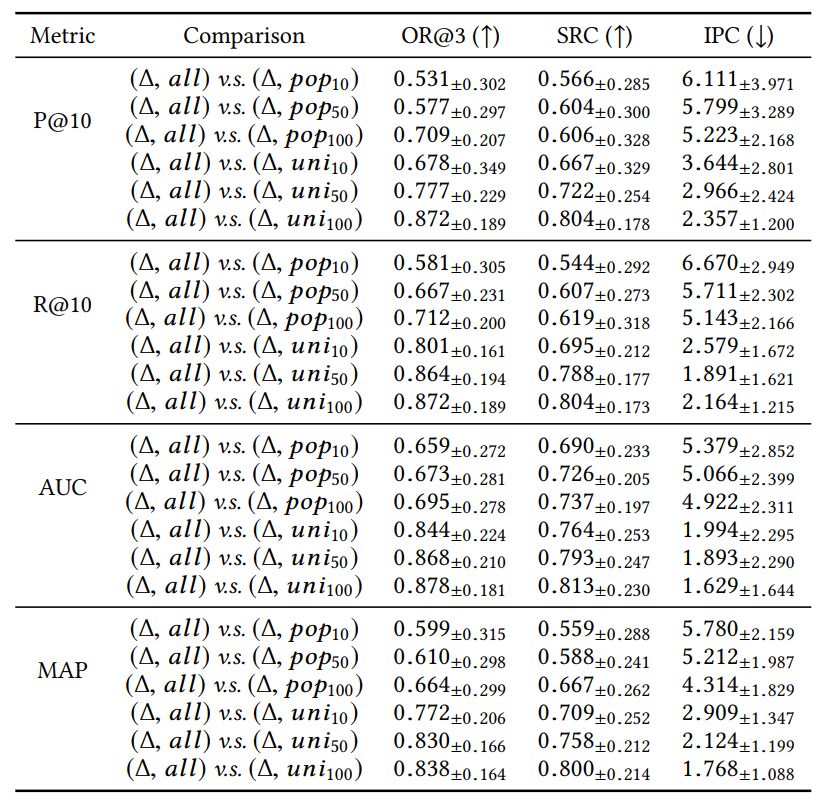
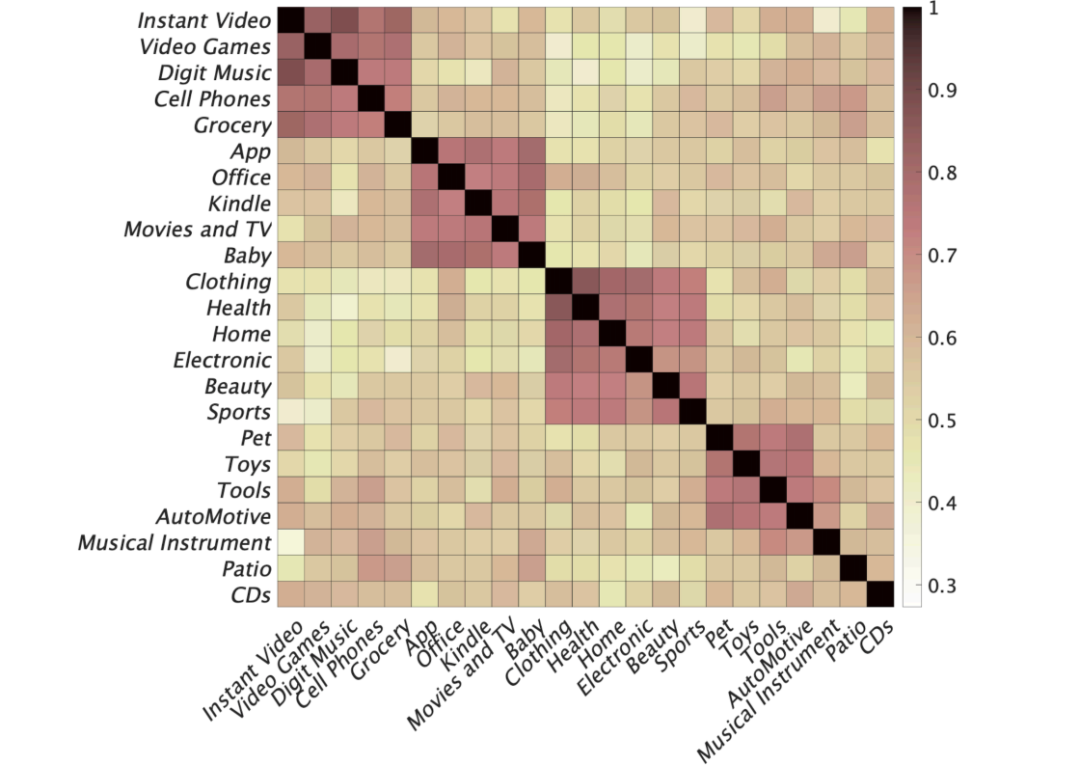
评价指标。Top-N项目推荐可以视为一项排序任务,排在前端的结果需要重点考虑。根据[4-14],在下面的实验中,我们使用了四个指标:(1)顶部K个位置的截断精度和召回率(P@K and R@K),(2)平均准确率(MAP),(3)ROC曲线下面积(AUC)。我们还计算了另外两个指标的结果nDCG@K和MRR。它们与上述四个指标产生了相似的结果,我们省略了对应的实验结果。
[1] S. Rendle, C. Freudenthaler, Z. Gantner, BPR:Bayesian Personalized Rankingfrom Implicit Feedback, in: UAI 2009, 452–461,2009. [2] S. Zhang, L. Yao, A. Sun, Y. Tay, Deep Learning Based Recommender System: ASurveyand New Perspectives, ACM Comput. Surv. 52 (1) (2019) 5:1–5:38. [3] A. Bellogín, P. Castells, I. Cantador, Precision-oriented evaluation ofrecommendersystems:an algorithmic comparison, in: ACM RecSys, 333–336, 2011. [4] T. Silveira, M. Zhang, X. Lin, Y. Liu, S. Ma, How good your recommendersystemis?A survey on evaluations in recommendation, JMLC 10 (5) (2019) 813–831. [5] H. Steck, Evaluation of recommendations: rating-prediction and ranking, in:ACM,RecSys 2013, 213–220, 2013. [6] A. Said, A. Bellogín, Comparative Recommender System Evaluation: BenchmarkingRecommendationFrameworks,in: ACM RecSys, 129–136, 2014. [7] W. Krichene, S. Rendle, On Sampled Metrics for Item Recommendation, in: ACMSIGKDD,2020. [8] R. He, J. J. McAuley, Ups and Downs: Modeling the Visual Evolution of FashionTrendswith One-Class Collaborative Filtering, in: WWW 2016, 507–517, 2016. [9]Y. Koren, Factorization meets the neighborhood: a multifacetedcollaborativeflteringmodel, in: ACM, SIGKDD 2008, 426–434, 2008. [10] P. Huang, X. He, J. Gao, L. Deng, A. Acero, L. P. Heck, Learning deepstructuredsemanticmodels for web search using clickthrough data, in: CIKM, 2013. [11] X. He, L. Liao, H. Zhang, L. Nie, X. Hu, T. Chua, Neural CollaborativeFiltering,in:WWW, 2017, 173–182, 2017. [12] G. Zhou, X. Zhu, C. Song, Y. Fan, H. Zhu, X. Ma, Y. Yan, J. Jin, H. Li, K.Gai,DeepInterest Network for Click-Through Rate Prediction, in: ACM, SIGKDD,1059–1068,2018. [13] R. van den Berg, T. N. Kipf, M. Welling, Graph Convolutional MatrixCompletion,CoRRabs/1706.02263. [14] J. L. Herlocker, J. A. Konstan, L. G. Terveen, J. Riedl, Evaluatingcollaborativeflteringrecommender systems, ACM Trans. Inf. Syst. 22 (1) (2004) 5–53.
数据集,又称为资料集、数据集合或资料集合,是一种由数据所组成的集合。
Data set(或dataset)是一个数据的集合,通常以表格形式出现。每一列代表一个特定变量。每一行都对应于某一成员的数据集的问题。它列出的价值观为每一个变量,如身高和体重的一个物体或价值的随机数。每个数值被称为数据资料。对应于行数,该数据集的数据可能包括一个或多个成员。