最新!NLG顶会INLG2021最佳长论文出炉!一作华人学生代表出席今晚INLG

最新消息,华人学者 Steven Y. Feng 与四位学者Jessica Huynh、Chaitanya Narisetty、Eduard Hovy与Varun Gangal 共同发表的题为“SAPPHIIRE: Approaches for Enhanced Concept-to-Text Generation”的研究论文获得了2021年 INLG 的最佳长论文奖!
今晚,论文作者 Steven Y. Feng 将作为代表出席第14届INLG会议,线上分享自然语言生成的团队研究。

INLG(International Conference on Natural Language Generation )始于1980年代,旨在讨论和传播自然语言生成领域的突破性成果。今年,会议于9月20日至24日在苏格兰阿伯丁举行,与会者会通过虚拟会议介绍他们的研究。
除了世界级的研究报告外,今年的会议还包括研讨会、学习教程、受邀专家的讲座和一个讨论小组(讨论题目为“用户希望从NLG的现实应用中获得什么”)。小组讨论由目前在计算机学习、NLG 和认知 AI 辅助行业任职的权威学者领导。
虽然自然语言生成(NLG)的研究已经持续了70多年,但旨在将NLG落地的基础技术却是在近些年才出现。最近,越来越多学术界与产业界的资深人员也已认识到 NLG 是一种核心能力。INLG也称,会议现已从小众的专业学术组织发展成了一个产学研相结合的国际性学术交流平台。
Steven Y. Feng,现为卡耐基梅隆大学(CMU)研究生,对NLP、机器学习、深度学习和人工智能研究有着丰富的经验和极高的研究热情。

个人主页:https://mobile.twitter.com/stevenyfeng

论文地址:tinyurl.com/sapphirelNLG
人类能够从常识推理,甚至反演,这种能力可以定义为从一组概念生成逻辑句子来描述日常场景。在这种情况下,这些概念是必须以某种形式在输出文本中表示的单个单词。
因此,论文作者提出了一套简单而有效的概念到文本生成改进方案,称为“SAPPHIRE”。具体来说,SAPPHIRE由两种主要方法组成:
1)增加输入概念集
2)将从baseline中提取的短语重组成更流畅、更有逻辑的文本。这些主要是与模型无关的(model-agnostic)改进,分别依赖于数据本身和模型自己的初始代。
通过使用BART和T5模型的实验,他们证明了这两种模型在CommonGen任务上的有效性。通过广泛的自动和人工评估,SAPPHIRE能显著提高模型的性能。深入的定性分析表明,SAPPHIRE有效地解决了基线模型生成的许多问题,包括缺乏常识、不够具体和流利性差等问题。

6种语言生成模型的对比
以上几种NLG模型对比揭示了baseline的几个问题:
1)概念覆盖率与概念集大小密切相关,概念集越大,概念的覆盖率越低,即遗漏概念的概率越高
2)许多短语不完整
3)反应迟钝

Baseline和人工的对比
如何解决BL模型的固有问题?近年来,随着模型改进的研究取得了重大进展,许多文本生成任务的性能也得到了显著改善。
在获奖团队中,他们设计了两步走战略:通过提取关键字和注意矩阵,在训练期间从参考文献中扩充概念。对于短语重组直觉,他们提出了基于新训练阶段和掩蔽填充的两个方法。最后,通过综合评估,他们展示了SAPPHIRE是如何通过各种指标提高模型性能,以及解决baseline在常识、特异性和流畅性方面的问题。
他们的第一个方法:Kw-aug和Att-aug,分别在训练现成的关键字提取模型注意值时,从参考文献中提取关键字,使用它们在训练时扩展输入概念集。(通过动作联想场景,通过名词联想动作,也就是由名词扩增动词,由动词扩增状语等)
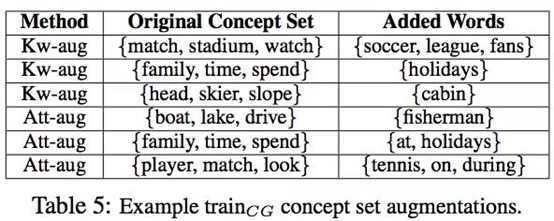
概念扩增
概念扩增的方法激发了Steven Y. Feng五人的想象力:是否有简单有效的方法可以从数据本身来提高这些自然语言生成的性能? 此外,是否有可能利用这些模型本身的输出来进一步提高它们的任务表现——某种"自我反省"?
在第二种方法中,他们从模型输出中提取非重叠的关键短语,然后构建一个新的概念集,其中包含这些关键短语和原始概念集中的其他非重叠概念。

也就是说,从原有的低端模型中输出“不那么流畅的句子”,然后提取新句子中的关键词,再根据新的关键词“扩增概念”。多次迭代,就能从相似逼近到精确。
如此,机器完成一轮“自我启发”,虽然并不算是自然语言范畴的“艺术创作”,却在实验中贯穿了形象思维与抽象思维经过复杂的辩证关系构成的思维方式。想象与联想,灵感与直觉,理智与情感,意识与无意识,它们在未来能否卡定在不同的向量图中,建模、量化,或许一问出口,便已有知。

由于微信公众号试行乱序推送,您可能不再能准时收到AI科技评论的推送。为了第一时间收到AI科技评论的报道, 请将“AI科技评论”设为星标账号,以及常点文末右下角的“在看”。
由于微信公众号试行乱序推送,您可能不再能准时收到AI科技评论的推送。为了第一时间收到AI科技评论的报道, 请将“AI科技评论”设为星标账号,以及常点文末右下角的“在看”。




