![]()
编译 | 龚倩
校对 | 青暮
现实世界中,各种性质的交易网络、社会互动和交往等许多问题都是动态的,并且都可以被建模成节点和边随时间变化的图。在这篇文章中,我们介绍了时态图网络,这是由Twitter开发的,用于动态图深度学习的通用框架。本文作者是Twitter的图学习研究负责人Michael Bronstein。
图神经网络(GNN)的研究已经飞速成为今年机器学习领域最热门的话题之一。近期,人们见证了GNN在生物学、化学、社会科学、物理学和许多其他领域中取得了一系列的成功。
到目前为止,GNN模型主要是针对不随时间变化的静态图开发的。然而,真实世界里许多值得关注的图却是动态的,是会随着时间的推移不断发展变化的,其中突出的例子包括社交网络、金融交易和推荐系统等。
在许多情况下,正是这类系统的动态行为向人们传达出重要的信息,而如果只考虑静态图,我们就很难得到这些重要的信息。
![]() 在一个动态的Twitter用户网络里,用户们通过发布推特进行交互并相互关注。
图中所有的边都有一个时间戳。
我们想要基于这样一个动态图来预测未来的交互如何发生,比如用户会喜欢哪种类型的
推特,或者他们会选择关注谁。
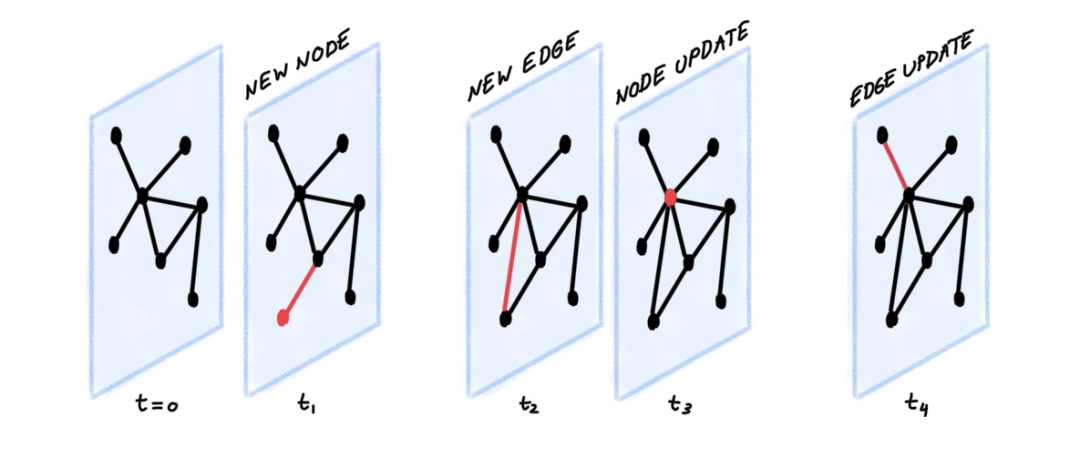
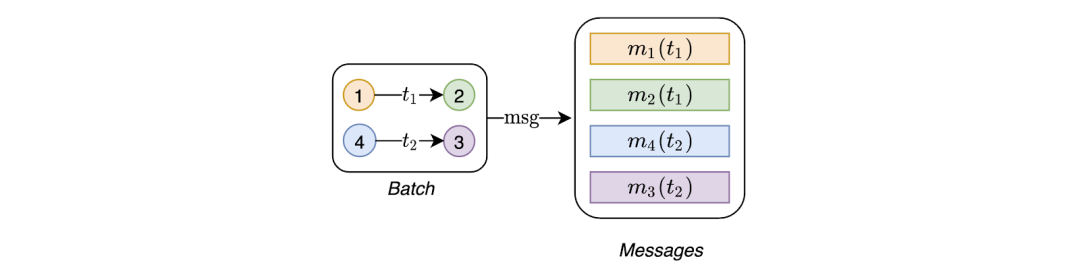
动态图可以表示为时间事件的有序列表或异步“流”,例如节点和边的添加或删除。像Twitter这样的社交网络就是一个很好的例子:
当一个人开始使用Twitter时,图中就会创建一个新的节点。当用户们关注另一个用户时,图中就会创建一个边。当用户更改其配置文件时,图中的节点将会被更新。
事件流被编码器神经网络接收,该神经网络为图的每个节点生成了一个与时间相关的嵌入。嵌入的内容可以被传输到针对特定任务而设计的解码器。
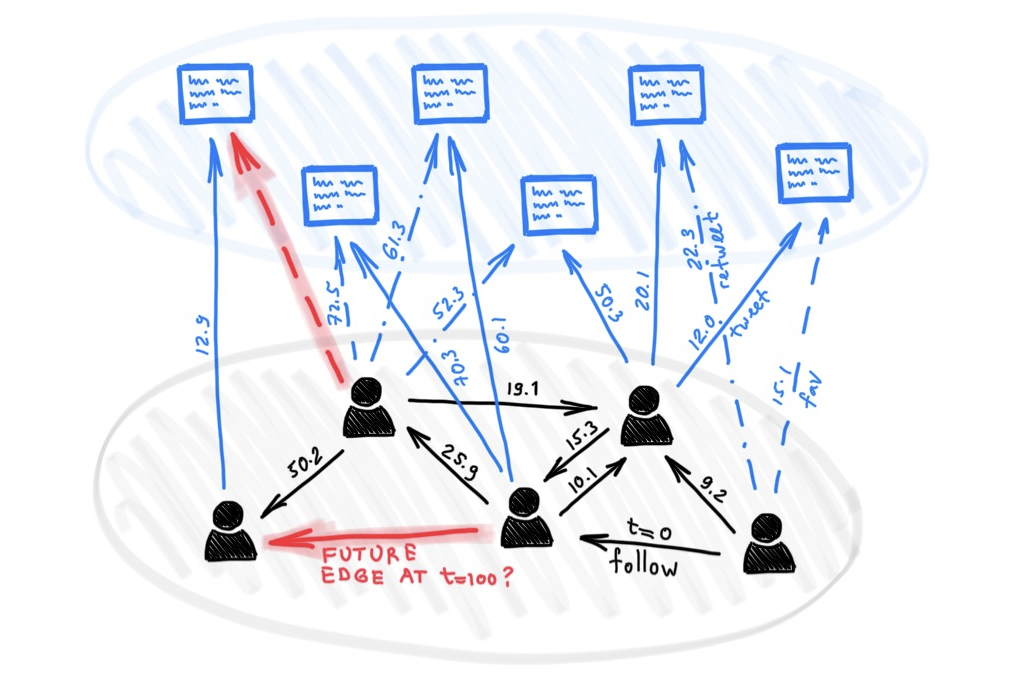
一个示例任务是通过尝试回答以下问题来预测未来的交互:节点i和 j在t时刻出现边的概率是多少?对于推荐系统来说,解决这个问题的能力是至关重要的,例如为社交网络用户推荐关注者,或者为特定用户推荐展示内容。如下图所示:
在一个动态的Twitter用户网络里,用户们通过发布推特进行交互并相互关注。
图中所有的边都有一个时间戳。
我们想要基于这样一个动态图来预测未来的交互如何发生,比如用户会喜欢哪种类型的
推特,或者他们会选择关注谁。
动态图可以表示为时间事件的有序列表或异步“流”,例如节点和边的添加或删除。像Twitter这样的社交网络就是一个很好的例子:
当一个人开始使用Twitter时,图中就会创建一个新的节点。当用户们关注另一个用户时,图中就会创建一个边。当用户更改其配置文件时,图中的节点将会被更新。
事件流被编码器神经网络接收,该神经网络为图的每个节点生成了一个与时间相关的嵌入。嵌入的内容可以被传输到针对特定任务而设计的解码器。
一个示例任务是通过尝试回答以下问题来预测未来的交互:节点i和 j在t时刻出现边的概率是多少?对于推荐系统来说,解决这个问题的能力是至关重要的,例如为社交网络用户推荐关注者,或者为特定用户推荐展示内容。如下图所示:
![]() 本图展示了一个TGN编码器接收了一个具有七条可视边(分别带有时间戳 t₁到 t₇)的动态图,目的是预测在t₈时刻(即图中灰色边缘),节点2和节点4之间出现交互的概率。为此,TGN在t₈时间点计算节点2和节点4的嵌入,然后将这些嵌入串联起来并传输到解码器(例如MLP),最后解码器输出两节点发生交互的概率。
以上设置中的关键部分是编码器,它可以与任何解码器一起训练。在前面提到的未来交互预测任务中,编码器可以采用自监督的方式进行训练:在每一代训练过程中(即每个epoch),编码器按时间顺序处理事件,并基于之前的事件预测下一个交互。
时态图网络(TGN)是我们在Twitter上与Fabrizio Frasca、Davide Eynard、Ben Chamberlain和Federico Monti等同事共同开发的一个通用编码器架构。
该模型适用于各种各样的以事件流表征的动态图的学习问题。简而言之,TGN编码器根据节点的交互创建节点的压缩表征,并在每次事件发生时更新节点。
基于此,TGN主要有以下组件:
内存。
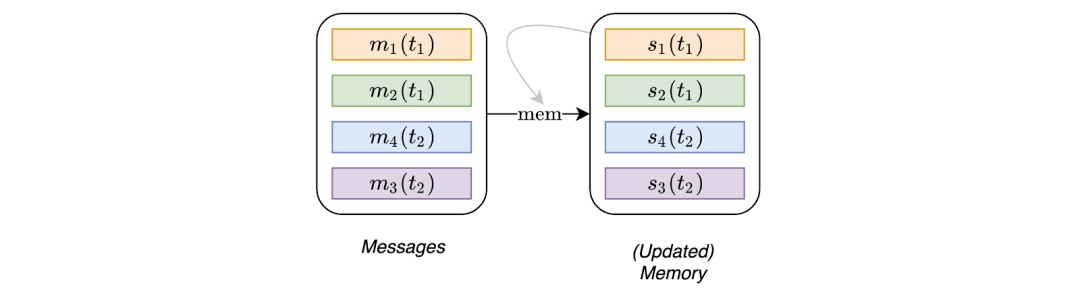
内存中存储着所有节点的状态,其作用是作为节点过去交互的压缩表征。它类似于RNN的隐藏状态;不同的是每个节点 i都有一个单独的状态向量sᵢ(t)。
当一个新节点出现时,我们相应地添加一个初始化为零的状态向量。此外,由于每个节点的内存只是一个状态向量(而不是一个参数),所以当模型接收到新的交互时,节点在测试时间也可以进行更新。
消息函数。
消息函数是内存更新的主要机制。给定在t时刻节点i和节点 j之间的交互,信息函数计算出两条消息用于更新内存(一条用于节点i,另一条用于节点 j)。这类似于在消息传递图神经网络中计算的消息,这一消息是在交互出现前的 t⁻时刻节点i和节点 j的内存、交互出现的时间t、边缘特征这三个变量的函数:
内存更新程序。
内存更新程序的作用是使用新消息更新内存。此模块通常使用一个RNN网络来实现。
考虑到节点的内存是一个随时间更新的向量,那么最直接的方法是直接将其作为节点嵌入来使用。
然而,由于过期问题,这一方法实践起来也有弊端:由于节点只有在参与交互时才会更新其内存,那么节点长时间不活动就会导致其内存过期。
举个例子,假设一个用户好几个月都没有登录Twitter,当他(她)重新登录时,他(她)可能已经在这段时间里发展出了新的兴趣,导致存储着此用户过去活动的内存不再和他(她)现在的兴趣相关。因此,我们需要一种更好的方法来计算嵌入。
嵌入。
一个解决方案是查找临近的节点。为了解决过期问题,嵌入模块通过在与目标节点时空邻近的节点上执行图聚合来计算目标节点的时间嵌入。
即使一个节点在一段时间内处于非活动状态,但与它临近的一些节点却很可能处于活动状态,因此通过聚合临近节点的内存,TGN可以计算出目标节点的最新嵌入。
在我们所举的例子中,即使用户一段时间不登录Twitter,但他的朋友仍然在Twitter上保持活跃,所以当用户重新登录Twitter时,相比用户自己的历史记录,用户的朋友的最近活动可能与其当前兴趣更相关。
本图展示了一个TGN编码器接收了一个具有七条可视边(分别带有时间戳 t₁到 t₇)的动态图,目的是预测在t₈时刻(即图中灰色边缘),节点2和节点4之间出现交互的概率。为此,TGN在t₈时间点计算节点2和节点4的嵌入,然后将这些嵌入串联起来并传输到解码器(例如MLP),最后解码器输出两节点发生交互的概率。
以上设置中的关键部分是编码器,它可以与任何解码器一起训练。在前面提到的未来交互预测任务中,编码器可以采用自监督的方式进行训练:在每一代训练过程中(即每个epoch),编码器按时间顺序处理事件,并基于之前的事件预测下一个交互。
时态图网络(TGN)是我们在Twitter上与Fabrizio Frasca、Davide Eynard、Ben Chamberlain和Federico Monti等同事共同开发的一个通用编码器架构。
该模型适用于各种各样的以事件流表征的动态图的学习问题。简而言之,TGN编码器根据节点的交互创建节点的压缩表征,并在每次事件发生时更新节点。
基于此,TGN主要有以下组件:
内存。
内存中存储着所有节点的状态,其作用是作为节点过去交互的压缩表征。它类似于RNN的隐藏状态;不同的是每个节点 i都有一个单独的状态向量sᵢ(t)。
当一个新节点出现时,我们相应地添加一个初始化为零的状态向量。此外,由于每个节点的内存只是一个状态向量(而不是一个参数),所以当模型接收到新的交互时,节点在测试时间也可以进行更新。
消息函数。
消息函数是内存更新的主要机制。给定在t时刻节点i和节点 j之间的交互,信息函数计算出两条消息用于更新内存(一条用于节点i,另一条用于节点 j)。这类似于在消息传递图神经网络中计算的消息,这一消息是在交互出现前的 t⁻时刻节点i和节点 j的内存、交互出现的时间t、边缘特征这三个变量的函数:
内存更新程序。
内存更新程序的作用是使用新消息更新内存。此模块通常使用一个RNN网络来实现。
考虑到节点的内存是一个随时间更新的向量,那么最直接的方法是直接将其作为节点嵌入来使用。
然而,由于过期问题,这一方法实践起来也有弊端:由于节点只有在参与交互时才会更新其内存,那么节点长时间不活动就会导致其内存过期。
举个例子,假设一个用户好几个月都没有登录Twitter,当他(她)重新登录时,他(她)可能已经在这段时间里发展出了新的兴趣,导致存储着此用户过去活动的内存不再和他(她)现在的兴趣相关。因此,我们需要一种更好的方法来计算嵌入。
嵌入。
一个解决方案是查找临近的节点。为了解决过期问题,嵌入模块通过在与目标节点时空邻近的节点上执行图聚合来计算目标节点的时间嵌入。
即使一个节点在一段时间内处于非活动状态,但与它临近的一些节点却很可能处于活动状态,因此通过聚合临近节点的内存,TGN可以计算出目标节点的最新嵌入。
在我们所举的例子中,即使用户一段时间不登录Twitter,但他的朋友仍然在Twitter上保持活跃,所以当用户重新登录Twitter时,相比用户自己的历史记录,用户的朋友的最近活动可能与其当前兴趣更相关。
![]() 图嵌入模块通过在与目标节点时间临近的节点上执行聚合来计算目标节点的嵌入。在上图中,当在某个时刻t(t大于t₂、 t₃ 和 t₄, 但小于 t₅)计算节点1的嵌入时,时间临近的节点将只包括在时刻t之前出现的边。因此,节点5的边不参与计算,因为它是在时刻t之后才出现。然而,嵌入模块是通过聚合临近点2、3和4的特征(v)和内存(s)以及边缘上的特征来计算节点1的表征。在我们的实验中,表现最好的图形嵌入模块是图注意力(graph attention),它能够根据临近节点的内存、特征和交互时间来得出哪些是最重要的临近节点。
图嵌入模块通过在与目标节点时间临近的节点上执行聚合来计算目标节点的嵌入。在上图中,当在某个时刻t(t大于t₂、 t₃ 和 t₄, 但小于 t₅)计算节点1的嵌入时,时间临近的节点将只包括在时刻t之前出现的边。因此,节点5的边不参与计算,因为它是在时刻t之后才出现。然而,嵌入模块是通过聚合临近点2、3和4的特征(v)和内存(s)以及边缘上的特征来计算节点1的表征。在我们的实验中,表现最好的图形嵌入模块是图注意力(graph attention),它能够根据临近节点的内存、特征和交互时间来得出哪些是最重要的临近节点。
![]() 图示为TGN对一批训练数据进行的计算。一方面,嵌入模块使用时间图和节点内存(1)生成嵌入,然后使用嵌入来预测批处理交互作用并计算损失(2,3)。另一方面,这些预测出的交互被用来更新内存(4,5)。
看了上面的图 ,你可能很好奇内存相关模块(消息函数、消息聚合器和内存更新器)是如何训练的,因为它们似乎不会直接影响损失值,因此也不会接收到梯度。
为了让这些模块能够影响损失值,我们需要在预测批处理交互之前更新内存。但是,由于内存中已经包含了我们试图预测的信息,因此这会导致内存泄漏。
为了解决这个问题,我们提出的方法是用来自前一个批处理的信息来更新内存,然后再预测交互。下图显示了训练内存相关模块所必需的TGN的操作流程:
图示为TGN对一批训练数据进行的计算。一方面,嵌入模块使用时间图和节点内存(1)生成嵌入,然后使用嵌入来预测批处理交互作用并计算损失(2,3)。另一方面,这些预测出的交互被用来更新内存(4,5)。
看了上面的图 ,你可能很好奇内存相关模块(消息函数、消息聚合器和内存更新器)是如何训练的,因为它们似乎不会直接影响损失值,因此也不会接收到梯度。
为了让这些模块能够影响损失值,我们需要在预测批处理交互之前更新内存。但是,由于内存中已经包含了我们试图预测的信息,因此这会导致内存泄漏。
为了解决这个问题,我们提出的方法是用来自前一个批处理的信息来更新内存,然后再预测交互。下图显示了训练内存相关模块所必需的TGN的操作流程:
![]() 图示为训练内存相关模块所需的TGN操作流程。我们引入了一个叫做“原始消息存储”(raw message store)的新组件,用于存储模型已经处理过的交互。raw message store存储了计算消息(我们称之为raw messages)所必须的信息。这样模型就可以将交互时进行的内存更新推迟到后续的批处理。首先,用存储在前一个批处理(1和2)中的原始消息来计算信息,并用此信息来更新内存。然后可以用这一更新过的内存(即图中灰色连线)(3)来计算嵌入。这样就使得内存相关模块的计算能够直接影响损失值(4和5),并且它们会接收到一个梯度。最后,此批处理交互的原始消息被存储在raw message store(6)中,以供后续的批处理使用。
在各种动态图的大量实验研究中,TGN在未来边缘预测和动态节点分类的任务上,无论在精度还是速度上都明显优于竞争方法。
维基百科就是这样一个动态图,其中用户和页面是节点,用户编辑页面就是进行交互。将编辑文本这一交互行为进行编码,就可作为交互特征。在这个例子中,模型的任务就是预测用户在给定时间内会编辑哪个页面。我们用基线方法比较了TGN的不同变式:
图示为训练内存相关模块所需的TGN操作流程。我们引入了一个叫做“原始消息存储”(raw message store)的新组件,用于存储模型已经处理过的交互。raw message store存储了计算消息(我们称之为raw messages)所必须的信息。这样模型就可以将交互时进行的内存更新推迟到后续的批处理。首先,用存储在前一个批处理(1和2)中的原始消息来计算信息,并用此信息来更新内存。然后可以用这一更新过的内存(即图中灰色连线)(3)来计算嵌入。这样就使得内存相关模块的计算能够直接影响损失值(4和5),并且它们会接收到一个梯度。最后,此批处理交互的原始消息被存储在raw message store(6)中,以供后续的批处理使用。
在各种动态图的大量实验研究中,TGN在未来边缘预测和动态节点分类的任务上,无论在精度还是速度上都明显优于竞争方法。
维基百科就是这样一个动态图,其中用户和页面是节点,用户编辑页面就是进行交互。将编辑文本这一交互行为进行编码,就可作为交互特征。在这个例子中,模型的任务就是预测用户在给定时间内会编辑哪个页面。我们用基线方法比较了TGN的不同变式:
![]() 图示为基于维基百科数据集,在未来链路预测的预测精度和时间方面,比较不同配置的TGN和已有的方法(如TGAT和Jodie)。我们希望更多的论文能够以严谨的方式报告这两个重要数据。
这项消融研究揭示了不同TGN模块的重要性,并帮助我们得出了一些一般性结论:
图示为基于维基百科数据集,在未来链路预测的预测精度和时间方面,比较不同配置的TGN和已有的方法(如TGAT和Jodie)。我们希望更多的论文能够以严谨的方式报告这两个重要数据。
这项消融研究揭示了不同TGN模块的重要性,并帮助我们得出了一些一般性结论:
-
-
使用嵌入模块(而不是直接输出内存状态)非常重要,基于图注意的嵌入性能最好。
-
由于1-hop临近节点的内存能使模型间接访问1-hop临近节点的信息,因此在有内存的情况下,模型仅仅使用一个图注意层就足够了(这样就极大地减少了计算时间)。
总结。我们认为动态图的学习几乎是一个全新的研究领域,具有许多重要且激动人心的应用价值,对未来的潜在影响也十分深远。我们相信,TGN模型是朝着提高动态图学习能力、巩固和扩展已有的研究成果所迈出的重要一步。随着这一研究领域的发展,更好更大的基准将变得至关重要。
https://towardsdatascience.com/temporal-graph-networks-ab8f327f2efe
![]()
 在一个动态的Twitter用户网络里,用户们通过发布推特进行交互并相互关注。
图中所有的边都有一个时间戳。
我们想要基于这样一个动态图来预测未来的交互如何发生,比如用户会喜欢哪种类型的
推特,或者他们会选择关注谁。
在一个动态的Twitter用户网络里,用户们通过发布推特进行交互并相互关注。
图中所有的边都有一个时间戳。
我们想要基于这样一个动态图来预测未来的交互如何发生,比如用户会喜欢哪种类型的
推特,或者他们会选择关注谁。
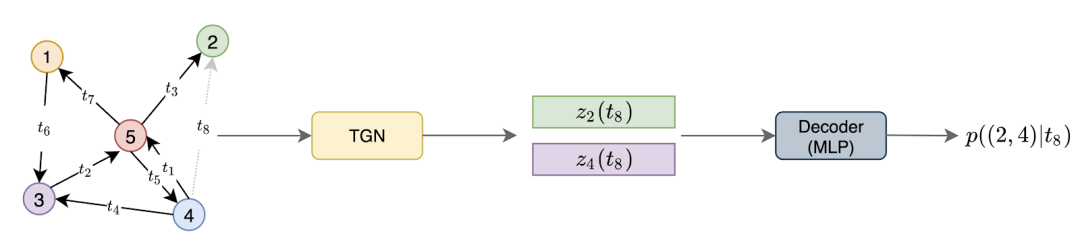 本图展示了一个TGN编码器接收了一个具有七条可视边(分别带有时间戳 t₁到 t₇)的动态图,目的是预测在t₈时刻(即图中灰色边缘),节点2和节点4之间出现交互的概率。为此,TGN在t₈时间点计算节点2和节点4的嵌入,然后将这些嵌入串联起来并传输到解码器(例如MLP),最后解码器输出两节点发生交互的概率。
本图展示了一个TGN编码器接收了一个具有七条可视边(分别带有时间戳 t₁到 t₇)的动态图,目的是预测在t₈时刻(即图中灰色边缘),节点2和节点4之间出现交互的概率。为此,TGN在t₈时间点计算节点2和节点4的嵌入,然后将这些嵌入串联起来并传输到解码器(例如MLP),最后解码器输出两节点发生交互的概率。
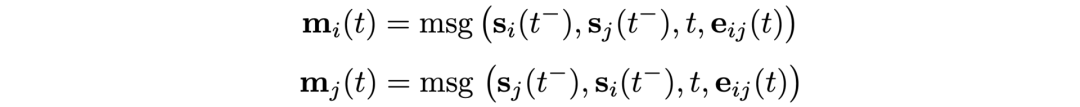
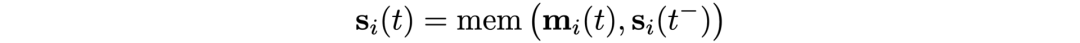
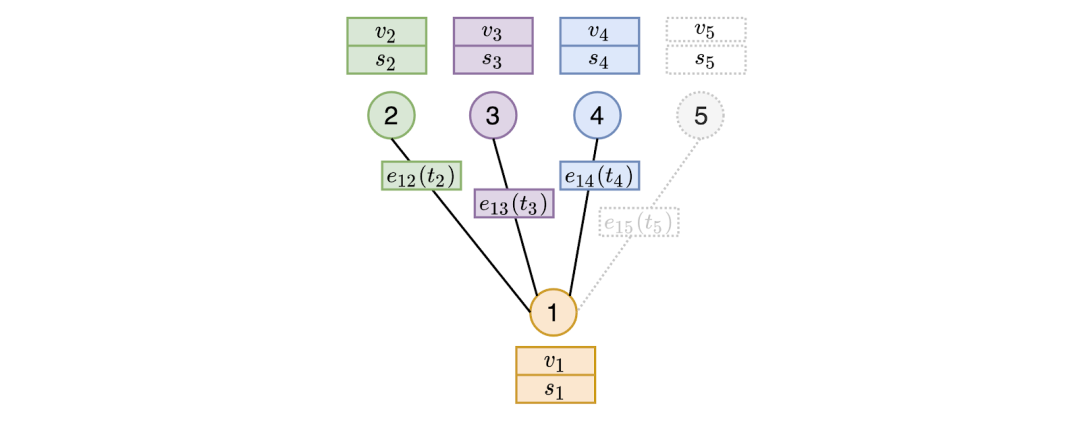 图嵌入模块通过在与目标节点时间临近的节点上执行聚合来计算目标节点的嵌入。在上图中,当在某个时刻t(t大于t₂、 t₃ 和 t₄, 但小于 t₅)计算节点1的嵌入时,时间临近的节点将只包括在时刻t之前出现的边。因此,节点5的边不参与计算,因为它是在时刻t之后才出现。然而,嵌入模块是通过聚合临近点2、3和4的特征(v)和内存(s)以及边缘上的特征来计算节点1的表征。在我们的实验中,表现最好的图形嵌入模块是图注意力(graph attention),它能够根据临近节点的内存、特征和交互时间来得出哪些是最重要的临近节点。
图嵌入模块通过在与目标节点时间临近的节点上执行聚合来计算目标节点的嵌入。在上图中,当在某个时刻t(t大于t₂、 t₃ 和 t₄, 但小于 t₅)计算节点1的嵌入时,时间临近的节点将只包括在时刻t之前出现的边。因此,节点5的边不参与计算,因为它是在时刻t之后才出现。然而,嵌入模块是通过聚合临近点2、3和4的特征(v)和内存(s)以及边缘上的特征来计算节点1的表征。在我们的实验中,表现最好的图形嵌入模块是图注意力(graph attention),它能够根据临近节点的内存、特征和交互时间来得出哪些是最重要的临近节点。
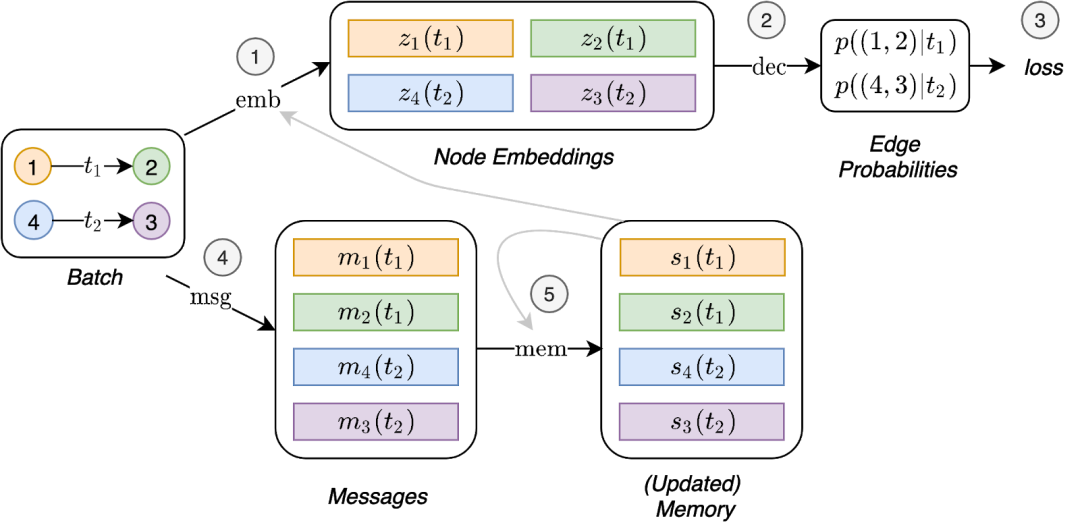 图示为TGN对一批训练数据进行的计算。一方面,嵌入模块使用时间图和节点内存(1)生成嵌入,然后使用嵌入来预测批处理交互作用并计算损失(2,3)。另一方面,这些预测出的交互被用来更新内存(4,5)。
图示为TGN对一批训练数据进行的计算。一方面,嵌入模块使用时间图和节点内存(1)生成嵌入,然后使用嵌入来预测批处理交互作用并计算损失(2,3)。另一方面,这些预测出的交互被用来更新内存(4,5)。
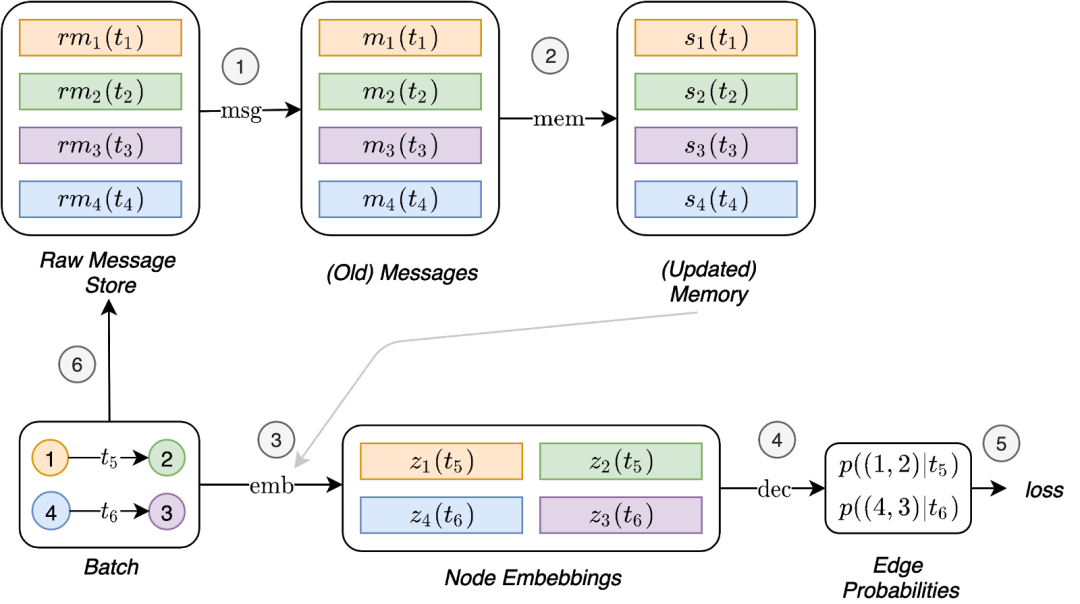 图示为训练内存相关模块所需的TGN操作流程。我们引入了一个叫做“原始消息存储”(raw message store)的新组件,用于存储模型已经处理过的交互。raw message store存储了计算消息(我们称之为raw messages)所必须的信息。这样模型就可以将交互时进行的内存更新推迟到后续的批处理。首先,用存储在前一个批处理(1和2)中的原始消息来计算信息,并用此信息来更新内存。然后可以用这一更新过的内存(即图中灰色连线)(3)来计算嵌入。这样就使得内存相关模块的计算能够直接影响损失值(4和5),并且它们会接收到一个梯度。最后,此批处理交互的原始消息被存储在raw message store(6)中,以供后续的批处理使用。
图示为训练内存相关模块所需的TGN操作流程。我们引入了一个叫做“原始消息存储”(raw message store)的新组件,用于存储模型已经处理过的交互。raw message store存储了计算消息(我们称之为raw messages)所必须的信息。这样模型就可以将交互时进行的内存更新推迟到后续的批处理。首先,用存储在前一个批处理(1和2)中的原始消息来计算信息,并用此信息来更新内存。然后可以用这一更新过的内存(即图中灰色连线)(3)来计算嵌入。这样就使得内存相关模块的计算能够直接影响损失值(4和5),并且它们会接收到一个梯度。最后,此批处理交互的原始消息被存储在raw message store(6)中,以供后续的批处理使用。
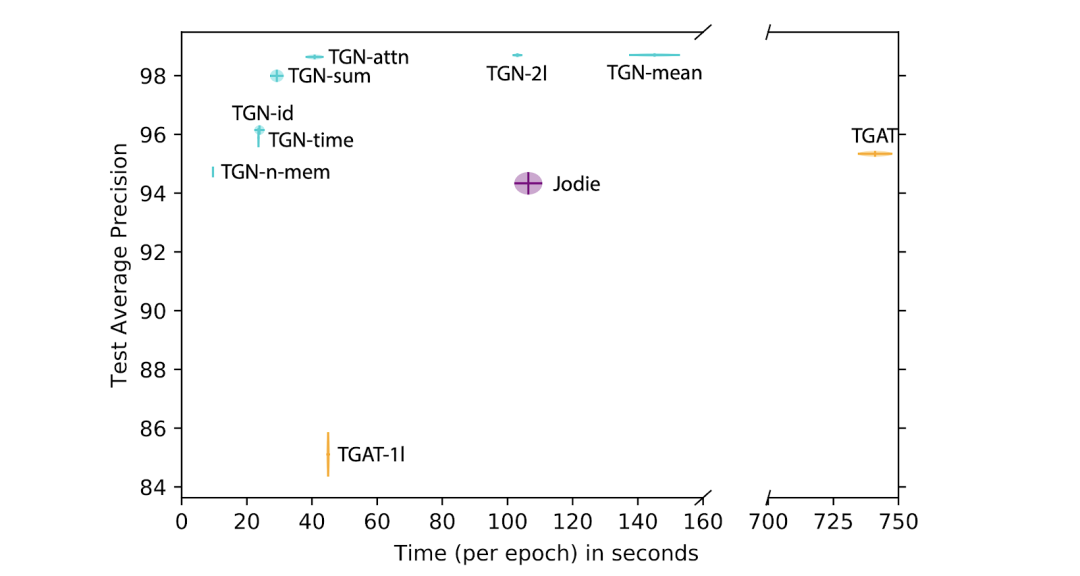 图示为基于维基百科数据集,在未来链路预测的预测精度和时间方面,比较不同配置的TGN和已有的方法(如TGAT和Jodie)。我们希望更多的论文能够以严谨的方式报告这两个重要数据。
图示为基于维基百科数据集,在未来链路预测的预测精度和时间方面,比较不同配置的TGN和已有的方法(如TGAT和Jodie)。我们希望更多的论文能够以严谨的方式报告这两个重要数据。



