机器之心 & ArXiv Weekly Radiostation
参与:杜伟、楚航、罗若天
本周的重要论文包括谷歌大脑研究科学家 Quoc Le 等人将ImageNet top-1准确率提升至 90% 以上的研究,以及 GAN 反转研究综述。
Superintelligence Cannot be Contained: Lessons from Computability Theory
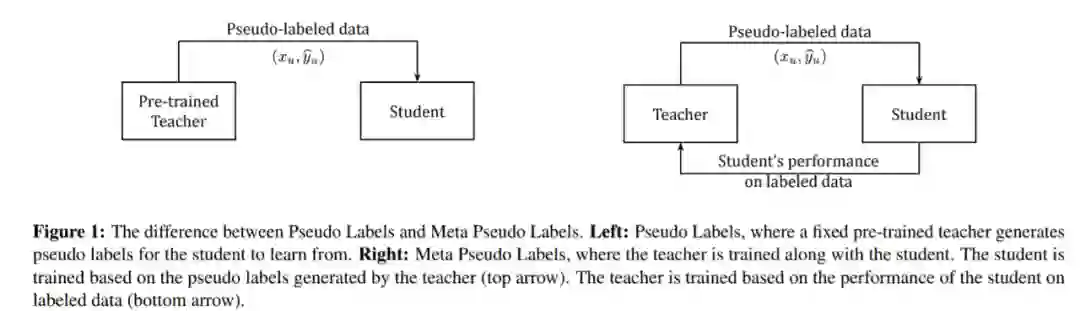
Meta Pseudo Labels
Ten computer codes that transformed science
Learning to Augment for Data-Scarce Domain BERT Knowledge Distillation
GAN Inversion: A Survey
What are the most important statistical ideas of the past 50 years?
Survey on Adversarial Sample of Deep Learning Towards Natural Language Processing
ArXiv Weekly Radiostation:NLP、CV、ML 更多精选论文(附音频)
论文 1:Superintelligence Cannot be Contained: Lessons from Computability Theory
摘要:
在本月初发表在 AI 领域顶级期刊《人工智能研究杂志》(JAIR)上的一篇文章中,马德里自治大学、马克斯 - 普朗克人类发展研究所等机构的研究者认为,
由于计算本身固有的基本限制,人类可能无法控制超级人工智能
。他们表示,任何旨在确保超级人工智能无法伤害人类的算法都必须首先模拟机器行为以预测其行动的潜在后果。如果超级智能机器确实可能造成伤害,那么此类抑制算法(containment algorithm)需要停止机器的运行。
然而,科学家们认为,任何抑制算法都不可能模拟 AI 的行为,也就无法百分之百地预测 AI 的行为是否会造成伤害。抑制算法可能无法正确模拟 AI 的行为或准确预测 AI 行动的后果,也就无法分辨出这些失败。
![]()
![]()
推荐:
最新研究:超级人工智能,从理论上就无法控制。
摘要:
近日,谷歌大脑研究科学家、AutoML 鼻祖 Quoc Le 发文表示,他们提出了一种新的半监督学习方法,
可以将模型在 ImageNet 上的 top-1 准确率提升到 90.2%,与之前的 SOTA 相比实现了 1.6% 的性能提升
。
这一成果刷新了 Quoc Le 对于 ImageNet 的看法。2016 年左右,他认为深度学习模型在 ImageNet 上的 top-1 准确率上限是 85%,但随着这一数字被多个模型不断刷新,Quoc Le 也开始对该领域的最新研究抱有更多期待。而此次 90.2% 的新纪录更是让他相信:ImageNet 的 top-1 还有很大空间。
Quoc Le 介绍称,为了实现这一结果,他们使用了一种名为「元伪标签(Meta Pseudo Label)」的半监督学习方法来训练 EfficientNet-L2。
![]()
![]()
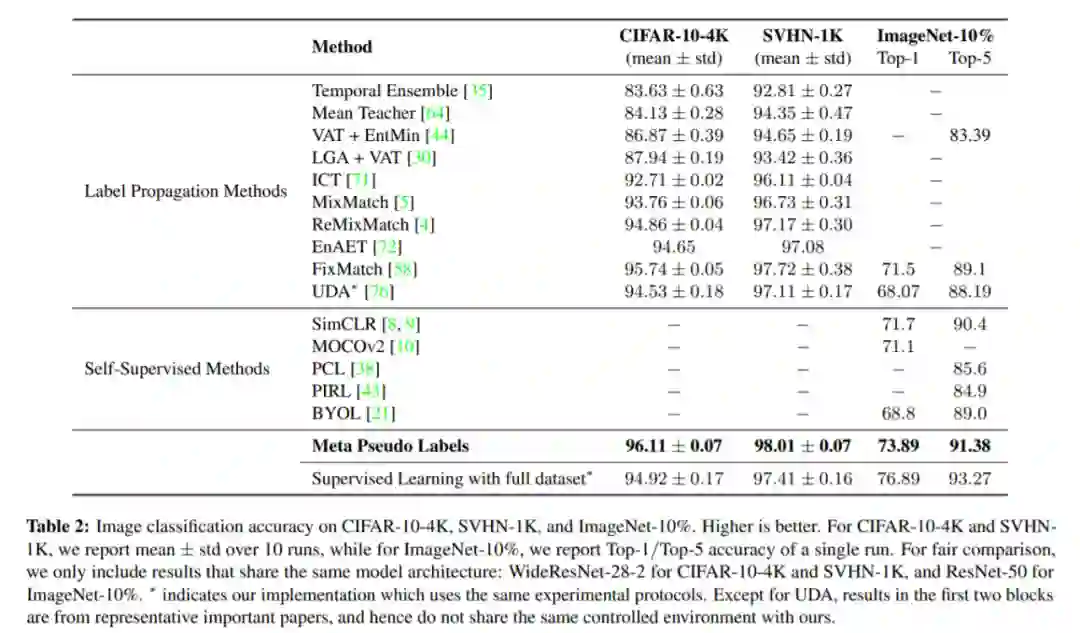
元伪标签方法与之前的 SOTA 半监督学习方法进行了对比。
![]()
研究者得到的学生模型在 ImageNet ILSVRC 2012 验证集上实现了 90.2% top-1 准确率,比之前的 SOTA 方法提升了 1.6 个百分点。
推荐:
ImageNet 的 top-1 终于上了 90%,不过网友质疑:用额外数据集还不公开,让人怎么信服?
论文 3:Ten computer codes that transformed science
摘要:
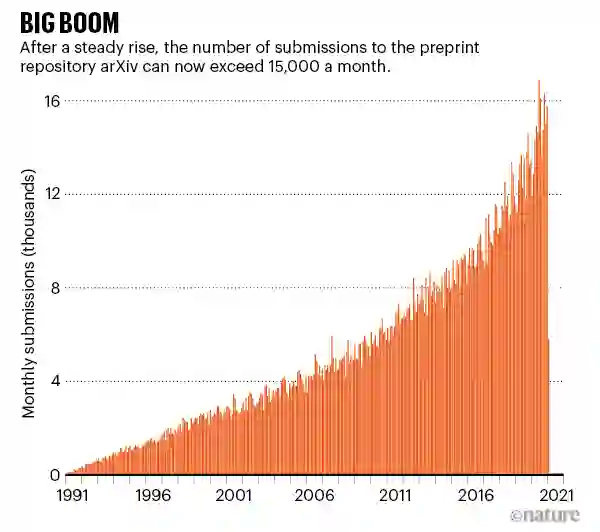
最近,Nature 上的一篇文章试图揭示科学发现背后的重要代码,正是它们在过去几十年中改变了科研领域。这篇文章介绍了
对科学界带来重大影响的十个软件工具,其中就包括与人工智能领域密切相关的 Fortran 编译器、arXiv、IPython Notebook、AlexNet 等
。
![]()
这台使用 Fortran 编译器编程的 CDC 3600 计算机于 1963 年移送至美国国家大气研究中心。(图源:美国大气科学研究大学联盟 / 科学图片库。)
![]()
Cray-1 超级计算机。(图源:科学历史图像 / Alamy)
![]()
1991 年至 2021 年,arXiv 提交论文数量暴增。
推荐:
Nature 盘点:从 Fortran、arXiv 到 AlexNet,这些代码改变了科学界。
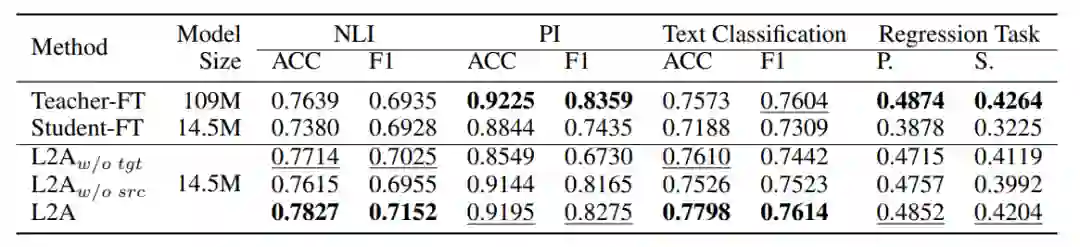
论文 4:Learning to Augment for Data-Scarce Domain BERT Knowledge Distillation
摘要:
通过在下游 NLP 任务上的微调,BERT、XLNet 和 RoBERTa 等预训练语言模型已经展示出了卓越的性能。但是,这些模型中的大量参数导致储存和计算成本过高,从而对模型在资源受限应用场景中的部署造成负担。典型的解决方案是采用知识蒸馏(knowledge distillation, KD)来降低储存计算成本并加速推理过程。KD 的基本思路是将大型 BERT 模型压缩为小型学生模型,同时保留教师模型的知识。然而,对于稀疏训练数据的目标领域而言,教师模型很难将有用的知识传递给学生模型,导致学生模型性能下降。
这时,数据增强(data augmentation, DA)成为处理数据稀疏问题的常用策略,该策略基于标注训练集生成新数据,进而增强目标数据。但是,学界没有出现很多用于 BERT 知识蒸馏的高效数据增强方法。当前蒸馏增强方法往往手动设计,诸如基于同义词替换的 thesaurus 方法、利用聚合关系的单词替换或大型语言模型的预测方法。这类增强方法的预训练不仅耗时,还很难找到有益于知识蒸馏的最优方案。设计一种自动增强数据稀疏领域中有用数据的高效策略仍是一项具有挑战性的任务。
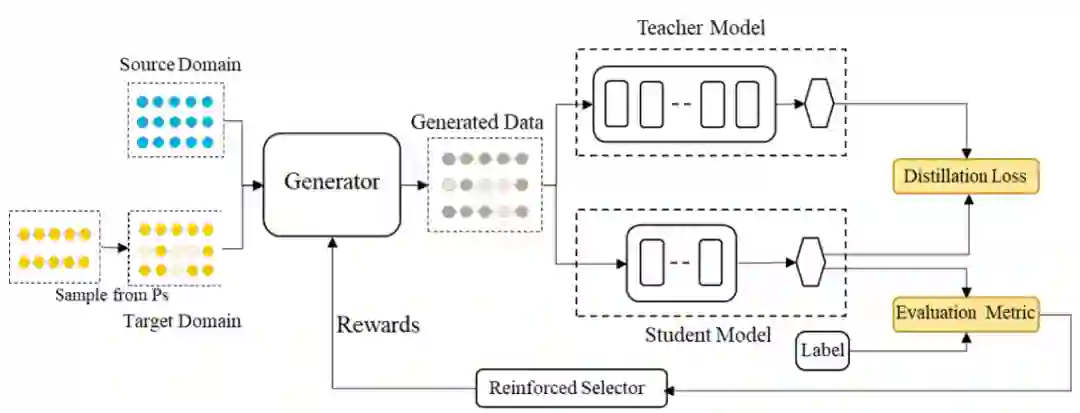
在阿里巴巴等机构合作的这篇被 AAAI 2021 接收的论文《Learning to Augment for Data-Scarce Domain BERT Knowledge Distillation 》中,研究者们提出了
一种跨域自动数据增强方法来为数据稀缺领域进行扩充,并在多个不同的任务上显著优于最新的基准
。
![]()
本文提出的 Learning to Augment (L2A) 方法示意图。
![]()
Learning to Augment (L2A) 算法。
![]()
推荐:
基于跨领域数据增强的 BERT 模型蒸馏技术。
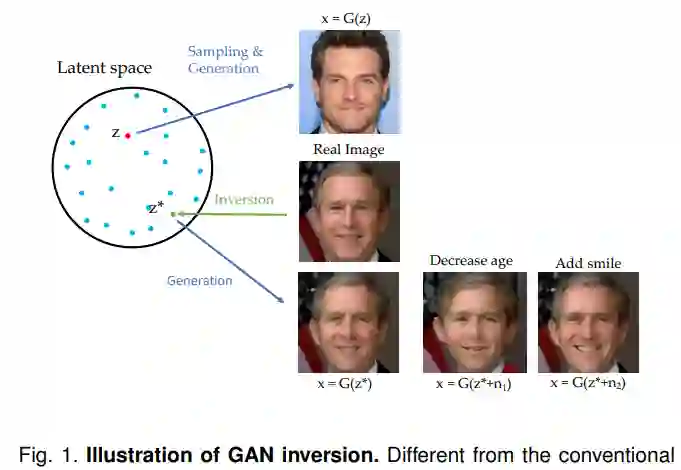
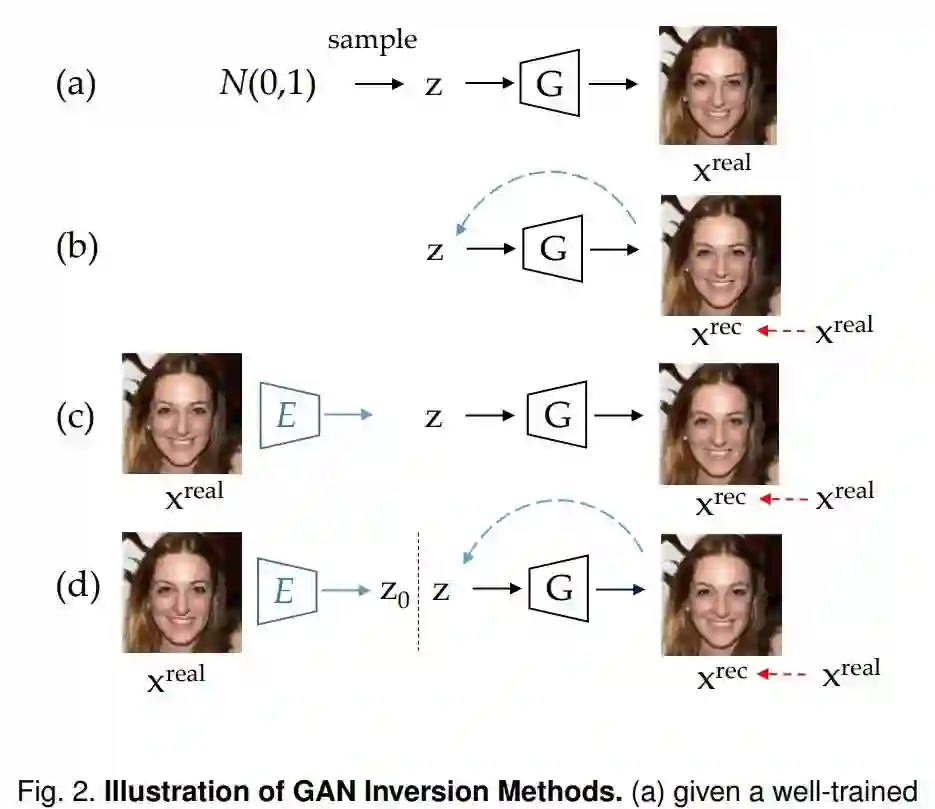
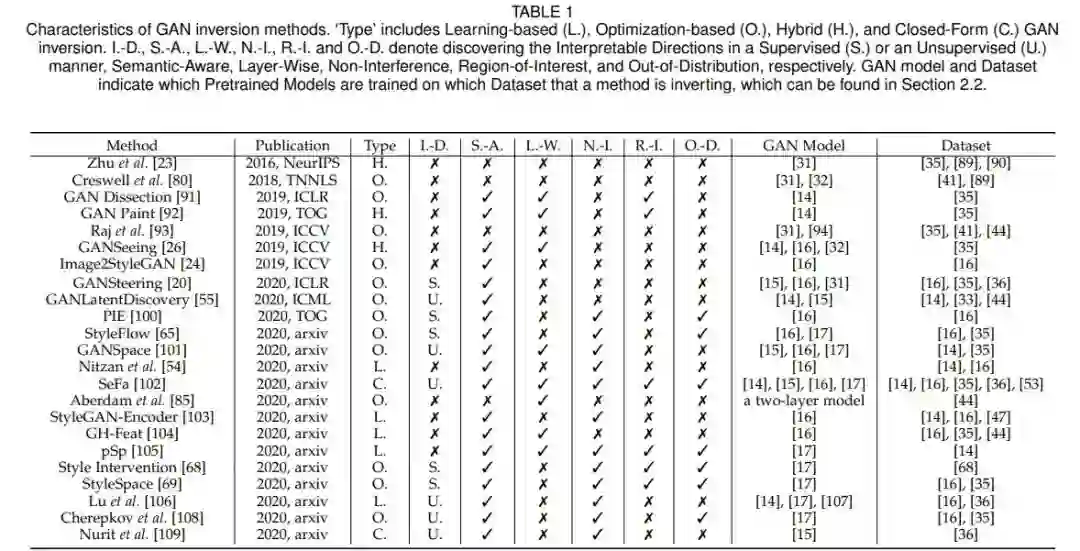
论文 5:GAN Inversion: A Survey
作者:Weihao Xia, Yulun Zhang, Yujiu Yang 等
论文链接:https://arxiv.org/pdf/2101.05278.pdf
摘要:
GAN 反转(inversion)旨在将给定图像逆映射到预训练好的 GAN 模型的潜在空间,以便由生成器基于反代码忠实地重建图像。作为一种新兴的连接真假图像领域的技术,GAN 逆映射在使 StyleGAN 和 BigGAN 等预训练好的 GAN 模型用于真实图像编辑应用中起着至关重要的作用。同时,GAN 反转也为 GAN 潜在空间的解读以及如何生成逼真图像提供了思路。在本文中,来自
清华大学深圳国际研究生院和美国东北大学等机构的研究者对 GAN 反转进行了概述,并重点介绍了最近的算法和应用
。论文涵盖了 GAN 反转的重要技术及其在图像恢复和处理中的应用。研究者最后进一步阐述了未来的一些发展趋势和挑战。
![]()
![]()
![]()
论文 6:What are the most important statistical ideas of the past 50 years?
摘要:
近日,哥伦比亚大学和阿尔托大学的两位知名统计学研究者撰文总结了
过去 50 年最重要的统计学思想
,包括反事实因果推理、bootstrapping 和基于模拟的推理、过参数化模型和正则化、多层次模型、通用计算算法、自适应决策分析、鲁棒性推理和探索性数据分析。除了详细描述这些统计学思想的具体概念和发展历程,研究者还概述了它们之间的共同特征、它们与现代计算和大数据之间的关系以及它们在未来如何发展和扩展。研究者表示,本文旨在激发人们对统计学和数据科学研究中更大主题的思考和讨论。
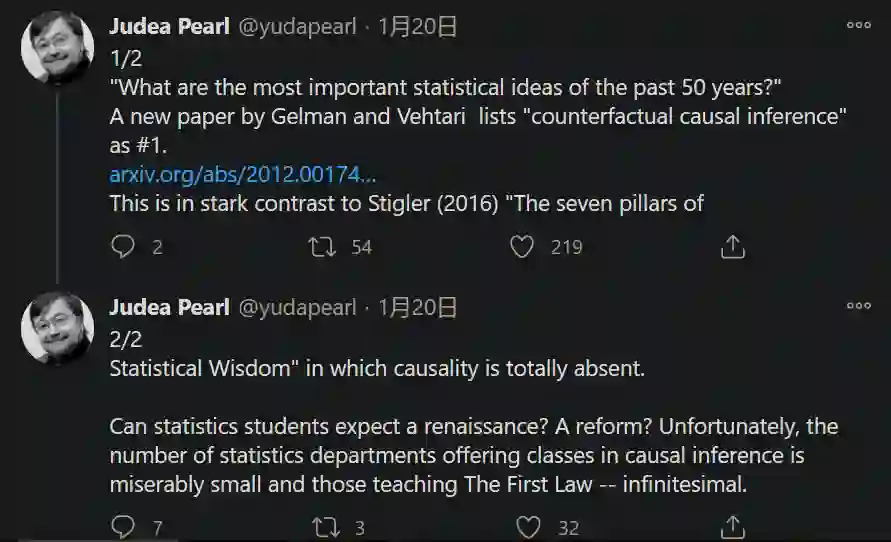
![]()
图灵奖得主、贝叶斯网络之父 Judea Pearl 表示:「这篇论文将因果推理列入了统计学思想之一,与芝加哥大学统计系教授 Stephen Stigler 所著《统计学七支柱》中的观点截然不同。」
![]()
本文作者:哥伦比亚大学统计学与政治学教授 Andrew Gelman(左)和阿尔托大学计算概率建模副教授 Aki Vehtari(右)。
论文 7:Survey on Adversarial Sample of Deep Learning Towards Natural Language Processing
摘要:
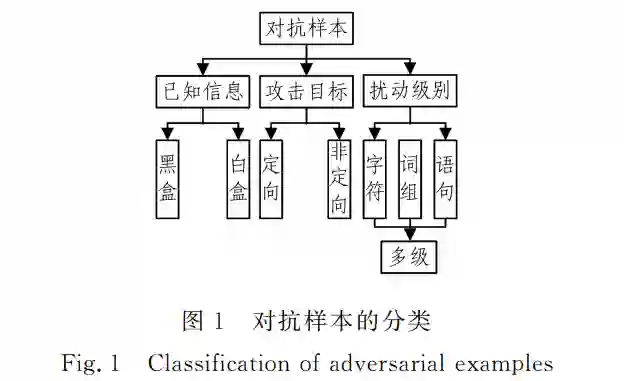
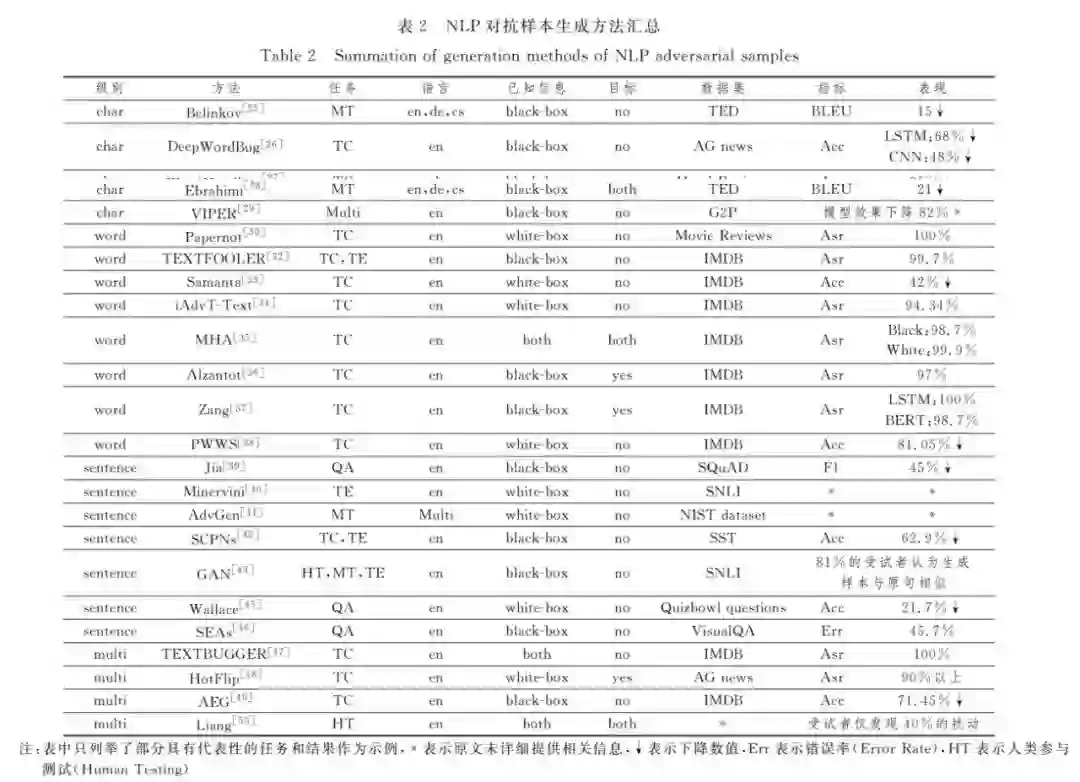
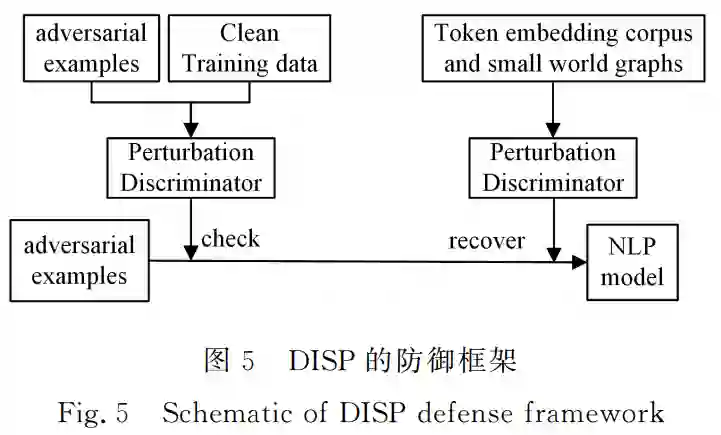
深度学习模型被证明存在脆弱性并容易遭到对抗样本的攻击,但目前对于对抗样本的研究主要集中在计算机视觉领 域而忽略了自然语言处理模型的安全问题。针对自然语言处理领域同样面临对抗样本的风险, 在阐明对抗样本相关概念的基 础上,文中首先对基于深度学习的自然语言处理模型的复杂结构、难以探知的训练过程和朴素的基本原理等脆弱性成因进行分 析,进一步阐述了文本对抗样本的特点、分类和评价指标,并对该领域对抗技术涉及到的典型任务和数据集进行了阐述;然后按 照扰动级别对主流的字、词、句和多级扰动组合的文本对抗样本生成技术进行了梳理,并对相关防御方法进行了归纳总结;最后 对目前自然语言处理对抗样本领域攻防双方存在的痛点问题进行了进一步的讨论和展望。
![]()
![]()
![]()
ArXiv Weekly Radiostation
机器之心联合由楚航、罗若天发起的ArXiv Weekly Radiostation,在 7 Papers 的基础上,精选本周更多重要论文,包括NLP、CV、ML领域各10篇精选,并提供音频形式的论文摘要简介,详情如下:
1. Can a Fruit Fly Learn Word Embeddings?. (from Mohammed J. Zaki)
2. Towards Facilitating Empathic Conversations in Online Mental Health Support: A Reinforcement Learning Approach. (from David C. Atkins)
3. Content Selection Network for Document-grounded Retrieval-based Chatbots. (from Kun Zhou)
4. Empirical Evaluation of Supervision Signals for Style Transfer Models. (from Iryna Gurevych)
5. UniSpeech: Unified Speech Representation Learning with Labeled and Unlabeled Data. (from Furu Wei)
6. Evaluating Multilingual Text Encoders for Unsupervised Cross-Lingual Retrieval. (from Simone Paolo Ponzetto)
7. Divide and Conquer: An Ensemble Approach for Hostile Post Detection in Hindi. (from Pushpak Bhattacharyya)
8. Can Taxonomy Help? Improving Semantic Question Matching using Question Taxonomy. (from Pushpak Bhattacharyya)
9. Situation and Behavior Understanding by Trope Detection on Films. (from Winston H. Hsu)
10. Word Alignment by Fine-tuning Embeddings on Parallel Corpora. (from Graham Neubig)
1. Pre-training without Natural Images. (from Yutaka Satoh)
2. Joint Learning of 3D Shape Retrieval and Deformation. (from Leonidas Guibas)
3. ArtEmis: Affective Language for Visual Art. (from Leonidas Guibas)
4. Deep Feedback Inverse Problem Solver. (from Antonio Torralba, Raquel Urtasun)
5. TCLR: Temporal Contrastive Learning for Video Representation. (from Rohit Gupta, Mubarak Shah)
6. Hybrid Trilinear and Bilinear Programming for Aligning Partially Overlapping Point Sets. (from Wangmeng Zuo, Lei Zhang)
7. CAA : Channelized Axial Attention for Semantic Segmentation. (from Dacheng Tao)
8. Fast Convergence of DETR with Spatially Modulated Co-Attention. (from Xiaogang Wang)
9. Focal and Efficient IOU Loss for Accurate Bounding Box Regression. (from Liang Wang, Tieniu Tan)
10. Using Shape to Categorize: Low-Shot Learning with an Explicit Shape Bias. (from James M. Rehg)
1. Dynamic Planning of Bicycle Stations in Dockless Public Bicycle-sharing System Using Gated Graph Neural Network. (from Philip S. Yu)
2. Knowledge-Preserving Incremental Social Event Detection via Heterogeneous GNNs. (from Philip S. Yu)
3. Momentum^2 Teacher: Momentum Teacher with Momentum Statistics for Self-Supervised Learning. (from Jian Sun)
4. Inductive Representation Learning in Temporal Networks via Causal Anonymous Walks. (from Jure Leskovec)
5. Ensemble manifold based regularized multi-modal graph convolutional network for cognitive ability prediction. (from Vince D. Calhoun)
6. LIME: Learning Inductive Bias for Primitives of Mathematical Reasoning. (from Jimmy Ba)
7. Collaborative Teacher-Student Learning via Multiple Knowledge Transfer. (from Dacheng Tao)
8. Scaling the Convex Barrier with Active Sets. (from Philip H.S. Torr)
9. DiffPD: Differentiable Projective Dynamics with Contact. (from Daniela Rus, Wojciech Matusik)
10. Continual Deterioration Prediction for Hospitalized COVID-19 Patients. (from Jaideep Srivastava)