论文浅尝 | FL-MSRE:一种基于小样本学习的多模态社会关系抽取方法

笔记整理:王大壮
链接:https://www.aaai.org/AAAI21Papers/AAAI-2215.WanH.pdf
动机
现有的社会关系抽取方法只考虑从文本或图像等单峰信息中抽取社会关系而忽略了多峰信息的高耦合性。为此,该论文提出了FL-MSRE,一种基于小样本学习的方法,从文本和人脸图像中抽取社会关系。同时,这也是第一次尝试在社会关系抽取中同时使用文本和图像的方法。
论文方法
社会关系抽取旨在推断日常生活中两个人之间的社会关系的方法。
FL-MSRE方法设计了基于社会关系抽取多模态编码器的原型网络。
1.多模态编码器的结构分为三个部分:1)句子编码器;2)人脸图像编码器;3)跨模态编码器。
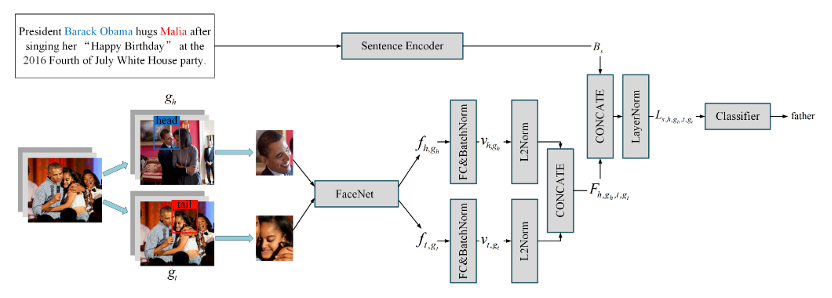
•句子编码器
在句子编码器中,每个句子由预训练好的BERT模型来进行编码,将第一个词牌的BERT编码向量(V_([CLS]))经过一个全连接层得到句子特征表示:
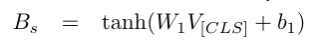
•人脸图像编码器
人脸图像编码器建立在FaceNet基础上,采用了GoogleNet的inception网络作为主干结构。不同的是,该工作去掉了inception网络的最后一层全连接层并且从最后一个平均池化层中提取特征。
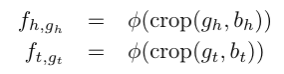
式中crop(g_h,b_h)代表将头实体所在的图像g_h剪切到边界框b_h的大小,ϕ代表修改后的inception网络。
为了获得高级特征,在上述操作之后加入了一个全连接层和批归一化。
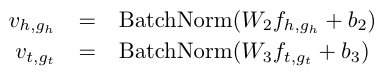
最后使用L2正则上述二者,并对其拼接获得最终的人脸图像特征表示:
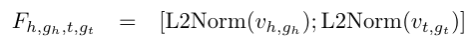
•跨模态编码器
跨模态编码器整合句子特征表示和人脸图像特征表示,在该论文中对两个表示进行简单的拼接然后应用了一个层标准化层来避免梯度消失或梯度爆炸的问题:

2.原型网络设计
采用小样本的N way K shot设置(N个类别,每类K个样例),对于某一关系的原型表示被定义为该类别下K个样例的跨模态表示的平均:
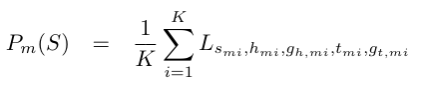
给出一个待分类的查询q,先计算q和N个关系的原型表示的欧几里得距离,接着使用softmax来生成该查询q所属关系的概率分布:
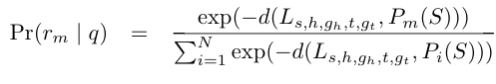
实验
•提出的数据集
该工作从四部经典名著和相应电视剧中提取了三个多模态数据集,分别命名为:Dream of the Red Chamber(DRC-TF)、Outlaws of the Marsh(OM-TF)、the Four Classic(FC-TF),TF代表了数据集包含了文本和人脸图像。这些数据集所包含的关系、人物、三元组、句子和图像的数目如下:
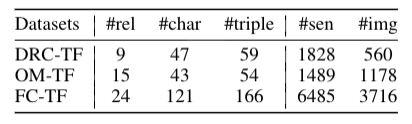
•与BERT的比较
为了验证提出的方法的有效性,该工作的基线使用BERT从文本中抽取社会关系。二者效果如下:

FL-MSRE相较于BERT的提升如下:

•人脸图像来自同一图像和不同图像的对比
考虑人脸图像来源对社会关系抽取任务的影响:1)人脸图像来自同一图像可能表明两个实体之间的关系更准确;2)人脸图像来自不同图像会扩大社会关系抽取应用的范围,特别是当两个实体从未出现在一张图像中的时候。
实验表明:1)FL-MSRE能够成功地将文本信息和图像信息整合到一个表示中,并在三个提出的数据集上比纯文本表示模型取得了更好的效果;2)在将来自同一图像的人脸图像替换为来自不同图像后,在FC-TF上的表现不相上下,在DRC-TF和OM-TF上后者都表现得更好,这个原因可能代表该处理使得模型更能关注到人脸图像的不变特征。
总结
该论文提出了一种新的基于文本信息和人脸信息的社会关系抽取方法FL-MSRE,通过在该工作提出的三个数据集上与基线的比较验证了所提出的模型的有效性。同时,FL-MSRE方法使用不同场景收集的人脸信息和同一场景收集的人脸信息不相上下,甚至更优,这意味着该工作能够很好地预测不曾出现在同一张照片中的人之间的社会关系。
OpenKG
OpenKG(中文开放知识图谱)旨在推动以中文为核心的知识图谱数据的开放、互联及众包,并促进知识图谱算法、工具及平台的开源开放。

点击阅读原文,进入 OpenKG 网站。

