论文浅尝 | 知识库问答中关系检测的学习表示映射
论文笔记整理:吴涵,天津大学硕士,研究方向:自然语言处理。

链接:
Paper: https://arxiv.org/pdf/1907.07328v1.pdf
Code: https://github.com/wudapeng268/KBQA-Adapter
引入
在关系检测任务中,对于训练数据中已出现的关系,往往可以得到很好的准确度。但是对于未出现的关系,检测性能将会大幅衰减。主要原因是我们没有去表示这些未出现的关系。
文章摘要
关系检测是包括知识库问答在内的许多自然语言过程应用的核心步骤。目前能得到较高的准确度,是因为关系已在训练数据中。当应对未出现过的关系时,性能将迅速下降。造成这一问题的主要原因是未出现关系的表示形式缺失。为此,本文提出了一种简单的映射方法——表示适配器(representation adapter),该方法基于先前学习的关系嵌入来学习已出现和未出现关系的表示映射。利用对偶目标和重构目标来提高映射性能。重新组织了 SimpleQuestion 数据集来揭示和评估未出现关系的检测问题。实验表明,本文方法要优于当前的一些方法。
本文主要看点
1、不从训练数据中学习该关系表示,而是使用方法来从整个知识图谱中学习具有更广泛覆盖范围的表示。
2、提出了一种映射机制,称为表示适配器,或者简称为适配器,用以将学习到的表示合并到关系检测模型中。从适配器非平凡训练的简单均方误差损失入手,提出将对抗性和重构目标结合起来,以改进训练过程。
3、将SimpleQuestion数据集重新组织为SimpleQuestion-Balance,以分别评估已出现和未出现关系的性能。
4、实验表明,该论文提出的方法在检测未出现关系方面取得了很大的进步。
Representation Adapter 介绍
Representation Adapter 架构图如下:
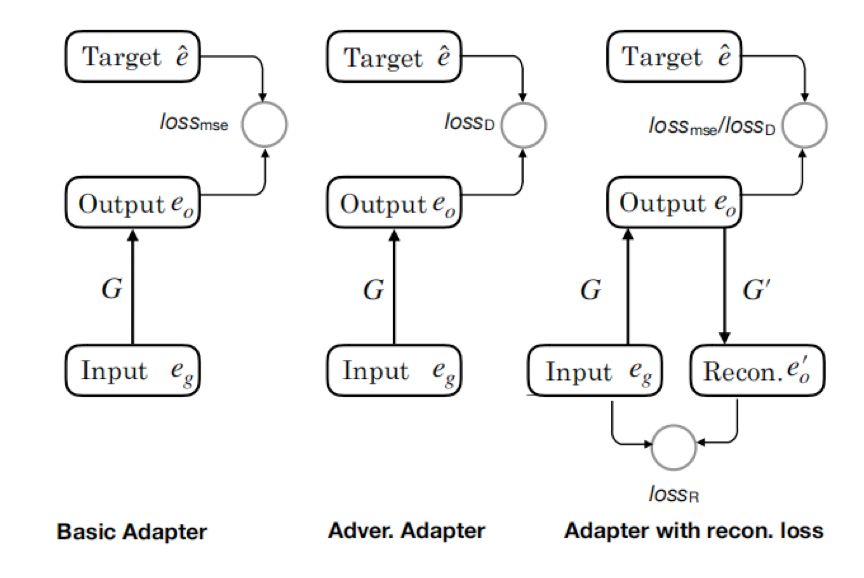
其中,左边是基本适配器;中间是对抗性适配器;右边是带重构损耗的适配器。
应用
将适配器集成到最先进的关系检测框架中(Yu et al.,2017, hierarchy Residual BiLSTM (HR-BiLSTM))。
该框架使用问题网络将问题句编码为矢量 qf,使用关系网络将关系编码为矢量rf。这两个网络都是基于Bi-LSTM和最大池化操作。然后引入余弦相似度来计算qf与rf之间的距离,从而确定检测结果。论文提出的适配器是关系网络中用来增强该框架的一个附加模块,如下图所示:
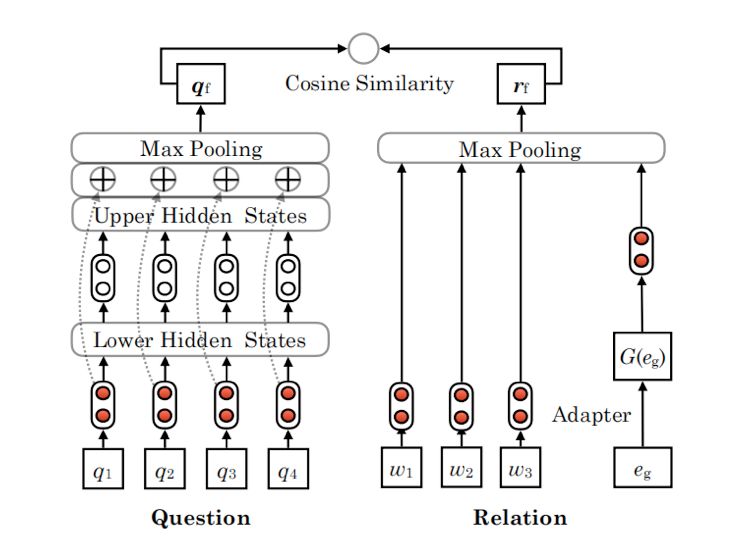
与以往的方法不同,该论文在关系表示中使用了所提出的适配器G(·)来解决未出现关系检测的问题。共享的Bi-LSTM用相同的颜色标记。适配器映射依赖于特定任务的关系,而特定任务又依赖于相应的网络。
线性映射:表示相似语言的表示空间可以通过线性映射传递。
训练
适配器 G(·) 在 GaN 中充当生成器。对于从训练集取样的任何关系,鉴别器的损耗lossD和生成器损耗lossG的目标函数是:
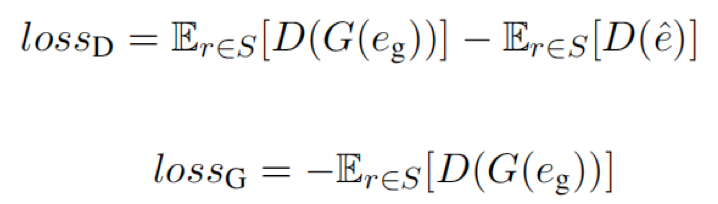
这里对于D(·),使用了一个前馈神经网络,没有最后一层的Sigmoid函数。
通常,适配器只能通过已出现关系的表示来学习映射,而忽略了潜在的大量未出现的关系。在这里,该论文使用额外的重构损失来增强适配器。更具体地说,采用了反向适配器 G’(·),将 G(e) 映射回e。
引入反向训练的好处是双重的。一方面,反向适配器可以通过所有的关系表示进行训练,无论是已出现的还是未出现的。另一方面,反向映射也可能成为规范正向映射的额外约束。
对于反向适配器G’(·),只使用类似于G(·)的线性映射函数,并使用均方误差损失来训练它:
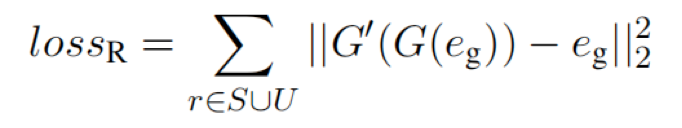
关系检测模型由hinge损失训练,该方法试图将每一个负样本关系与正样本关系的分数使用差值分隔开:
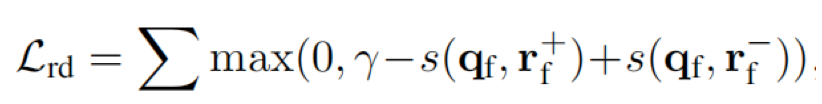
其中γ是试图将每一个负关系从正关系中分离出来的范围,rf+是标注训练数据的正关系,rf-是从其余关系中抽取的负关系,s(·,·)是qf与rf之间的余弦距离。
数据集
SimpleQuestion是一个大规模的KBQA数据集。在SQ中的每个样本包括一个人工注释的问题和相应的知识三元组。但是,测试集中的关系是不平衡的,测试集中的大部分关系都在训练数据中得到了体现。为了更好地评估未出现关系的检测性能,该论文重新组织了SQ数据集,以平衡开发和测试集中已出现和未出现的关系的数量,新的数据集表示为SimpleQuestion-Balance(SQB)。
实验结果
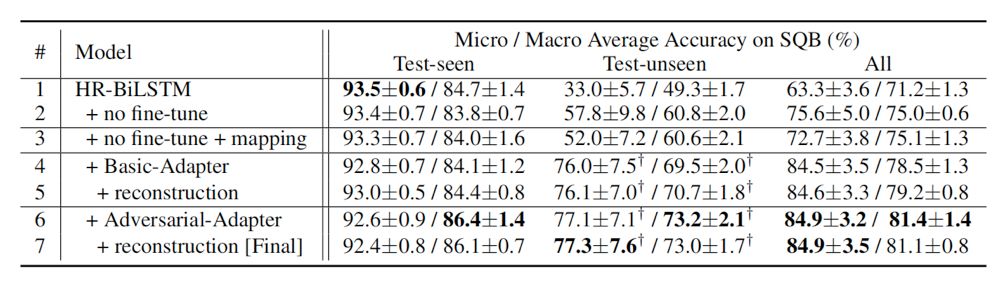
1、关系检测在SQB数据集上的微观平均精度和宏观平均精度。
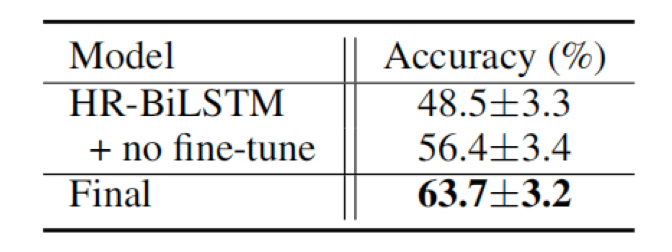
2、采用不同的关系检测模型对整个KBQA系统的微观平均精度进行了测试。
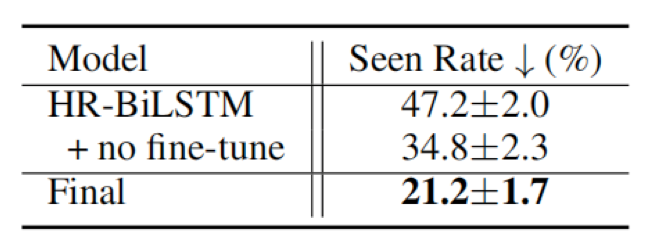
3、在测试未出现关系的集合中,计算了该预测率的宏观平均精度。
OpenKG
开放知识图谱(简称 OpenKG)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenKG 博客。


