之江实验室图计算中心副主任陈红阳:生物制药 × Graph AI 大模型

编辑 | ScienceAI
3 月 21 日,在机器之心举办的 ChatGPT 及大模型技术大会上,之江实验室图计算中心副主任陈红阳发表主题演讲《生物制药 × Graph AI 大模型》,在演讲中,他主要探讨了结合图机器学习的大数据预训练大模型,在生物制药领域潜在的应用方向和技术挑战,以及团队在这方面的相关研究进展。
以下为陈红阳教授在机器之心 ChatGPT 及大模型技术大会上的演讲内容,机器之心进行了不改变原意的编辑、整理:
随着 ChatGPT 的大火,大模型受到了广泛关注,相比于通用大模型,今天我要分享的是特定领域,即生物制药领域的大模型,以及我们团队在大规模图预训练上的初步探索。
大模型发展历程
近年来,模型构建范式逐渐从「针对特定任务构建特定模型」转向「可用于多任务的大规模预训练模型」。大模型的发展历程有几个阶段, 从 2017 年的 Transformer 到 GPT-3、ChatGPT,再到包括 GPT-4 在内的面向多模态的预训练模型,这其中模型参数量和数据量都呈现出爆发式的上升趋势。在海量计算能力的支撑下,大模型能更好的应用于更多复杂场景。
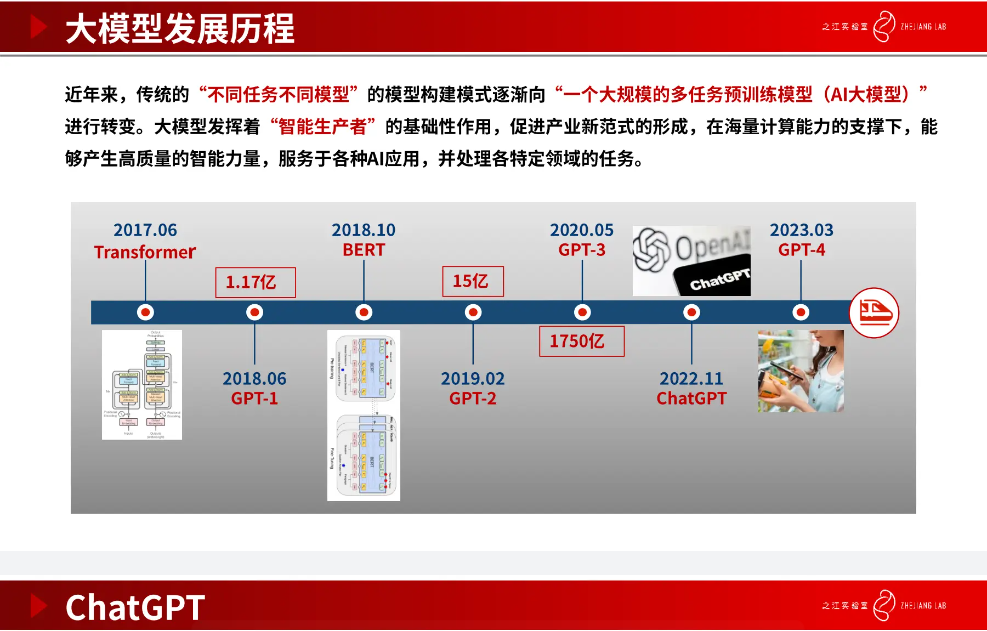
GPT-3 在自然语言处理任务上有很不错的效果,但在发布后并没有引起很大的反响。相反,ChatGPT 发布初期便引起了广泛关注,我们发现它在人机对话过程中可以回答很多问题,并且回答的都特别好。比如,我有一篇新发表的论文,代码还未开源,ChatGPT 能复现其代码,而且结果和论文的结果是一样的,这是非常惊人的。
ChatGPT 之所以能以对话的方式进行人机交互,并给出类似人类的响应,是因为其创新性地使用了很多方法,包括指令学习(Instruction learning)和基于人类反馈的强化学习(RLHF)。指令学习通过构造「指令」数据集,将原本的任务变成更符合人类习惯的任务,以更好的学习人类交互模式,赋予模型近人类思维。另一方面,ChatGPT 基于人类反馈的强化学习(RLHF),首先获取拟合人类偏好的奖励模型,针对回复的质量计算奖励,然后反馈回当前策略用以更新模型,实现模型预测和人类价值观的对齐。
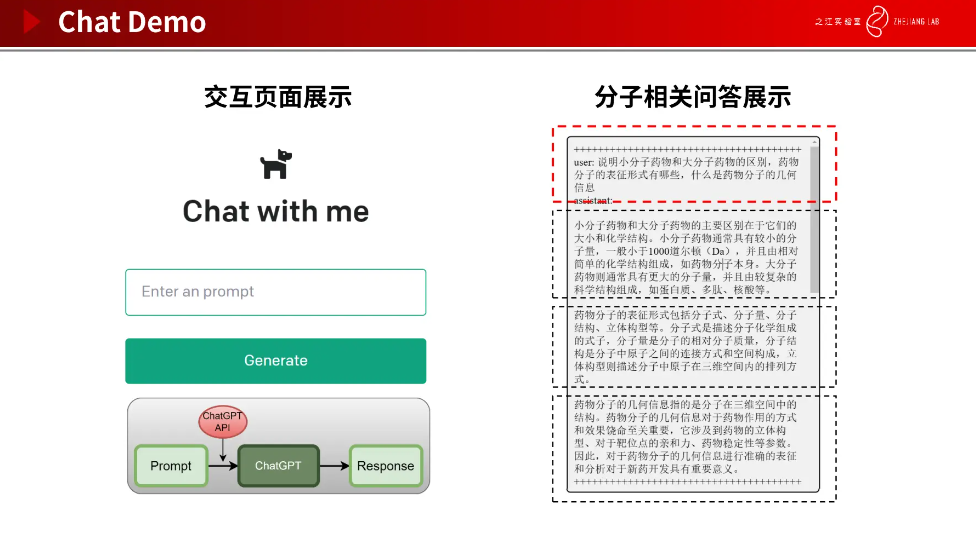
我们尝试对 ChatGPT 官网提供的 API 进行接入,制作了一个 Demo,让其解答分子相关问题。问题包括说明小分子药物和大分子药物的区别,药物分子的表征形式有哪些,什么是药物分子的几何信息等。这些都是非常专业的问题,涉及到药物领域的专业知识,ChatGPT 都给出了非常专业的答案(如下图所示)。
目前有很多国内外企业正在部署大模型,包括百度、微软、谷歌等,其大部分研究领域都在智能搜索,智能问答等方向,并没有布局到智能制药方向。GPT 能否应用在生物制药领域,或者直接搬过来行不行?当我们把 ChatGPT 直接应用到专业领域时还存在很多不足。一是无法保证其可信性,例如分子生成任务,需要通过引入领域知识、结合强化学习和湿实验等来验证生成分子的有效性。其次,由于训练过程使用的通用数据缺少领域知识,造成 ChatGPT 在特定领域表现并不好。另外,模型的训练部署以及相关湿实验的成本都非常高昂,这也是药物研发里流程长、投入大的原因之一。
生物制药 GPT
接下来,我将探讨生物制药 GPT 的潜在应用,以及利用大模型加速药物研发过程中存在的技术挑战。
生物制药 GPT 的潜在应用包括药物设计和靶点发现等。药物设计是生物制药领域中至关重要的一个环节,传统的药物设计过程缺乏高效性,通常需要大量的化学实验,依赖于昂贵的设备和专业技能,耗费大量时间和金钱。与传统的药物设计方法相比,生物 GPT 可以在短时间内生成大量具有多样性的分子,提供更加广泛的分子库供药物筛选。此外,生物 GPT 还能够针对特定的生物化学属性(如分子量、溶解性等)进行诱导生成,从而提高药物研发的效率和成功率。生物 GPT 的应用不仅限于新药研发领域,它还可以用于药物优化和药效预测,为新药的研发和上市提供重要的参考和指导。
靶点发现是药物研发过程中的关键环节,其中靶点是药物在体内的作用结合位点,我们可以把药物想象成一把「钥匙」,而靶点就是与之匹配的「锁」。传统的药物靶点研究需要耗费大量的时间和人力资源,且成功率低,导致研发成本高昂。基于大量的医学材料和生化数据,生物 GPT 可以发掘潜在的药物靶点,甚至预测靶点与潜在药物之间的相互作用。这种方法不仅可以减少实验周期,节省成本,还可以帮助研究人员确定更加准确和有效的靶点,提高药物研发成功率。
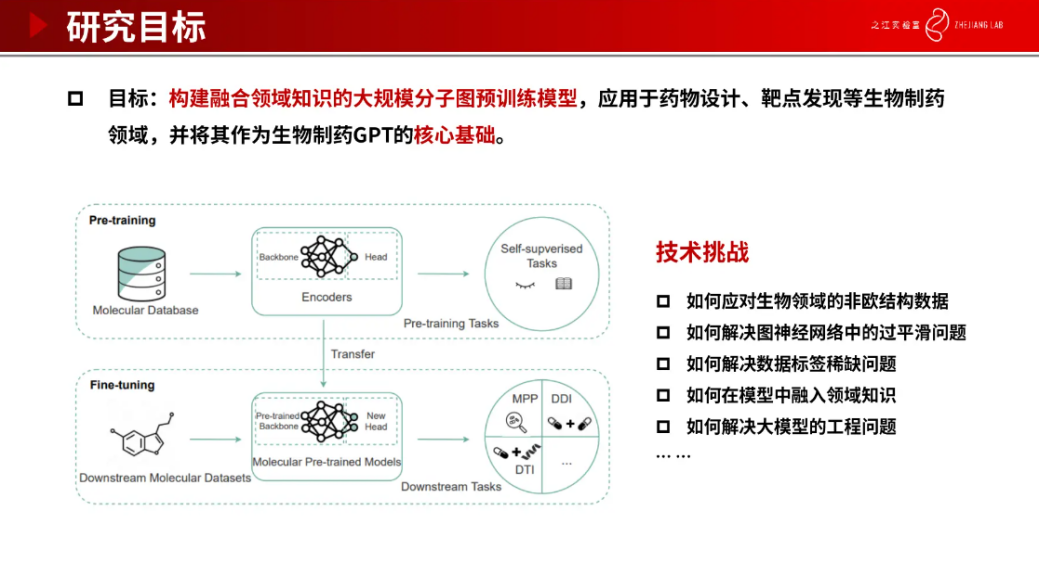
我们构建融合领域知识的大规模分子图预训练模型, 应用于药物设计、靶点发现等生物制药领域,并将其作为生物制药 GPT 的核心基础。在大量分子数据上进行自监督预训练任务后,将得到的编码器在下游任务上微调,如 DDI(药物间的相互作用)、DTI(药物于蛋白质之间的相互作用)和 MPP(药物性质预测) 等。
整个流程沿袭了大模型的思路。现有的一些大规模语言模型,如 Bert 和 ChatGPT 等,已在自然语言领域展现出了惊人的效果,但将其直接应用到生物制药领域将会面临一些新的挑战,比如,如何应对生物领域的非欧结构数据,如何解决图神经网络中的过平滑问题,如何解决数据标签稀缺问题,如何在模型中融入领域知识,如何解决大模型的工程问题。
在生物领域,数据往往呈现出排列不整齐的非欧式结构,无法使用常规的欧式结构算法进行处理。我们可以采用图神经网络,如 GCN、GAT、GraphSAGE 和 GIN 等,通过消息传递机制聚合自身与邻居节点的特征,来更新该节点的特征,挖掘实体之间的关联信息,最终得到节点或图的特征表示。在图神经网络训练过程中,随着网络层数的加深,会引起过平滑问题。通过使用「图+Transformer」机制,在Transformer 架构上引入图结构信息,可以解决过平滑问题。另外,也可以用跳过链接(Skip Connection),通过将浅层图嵌入添加到深层网络,以提高节点之间的区分度,有效提升最终的表达能力,避免过平滑。
生物制药领域普遍存在数据标签稀缺的问题,这是因为很多数据需要领域内经验丰富的专家进行人工标注,其成本非常昂贵。我们可以采用一些无监督的预训练策略,如自编码策略(Autoencoding)、自回归策略(Autoregressive Modeling)、掩码策略(Masked Components Modeling)、上下文预测策略(Context Prediction Modeling)等策略,来人为的构造有标签的数据。
科学领域和计算机领域存在着明显的知识鸿沟,目前的交叉研究往往采用简单的建模方式,缺少对科学领域内前沿研究成果的结合。我们需要在模型中融入领域知识来提高模型在特定领域的表现。不同于计算机视觉领域中图像分类问题,只需要人类常识性的知识就可以判别。生物制药领域需要引入更专业的知识,比如结合分子的轨道理论、表面静电势、自旋密度等值面等。最后,我们还需要解决大模型的工程问题。大规模图数据中存在百万节点和上亿边,这对设备的计算和存储提出了更高的要求,特别是从存储到计算过程中,如何减少 IO 开销来加速模型的训练速度,面临非常大的挑战。另外,如何做到负载均衡,如何解决模型 Loss 下降不稳定,如何快速更新梯度来加快收敛,这些工程问题都是非常大的挑战。
团队相关研究进展
接下来,简单介绍一下我们团队在这个领域做的一些布局。
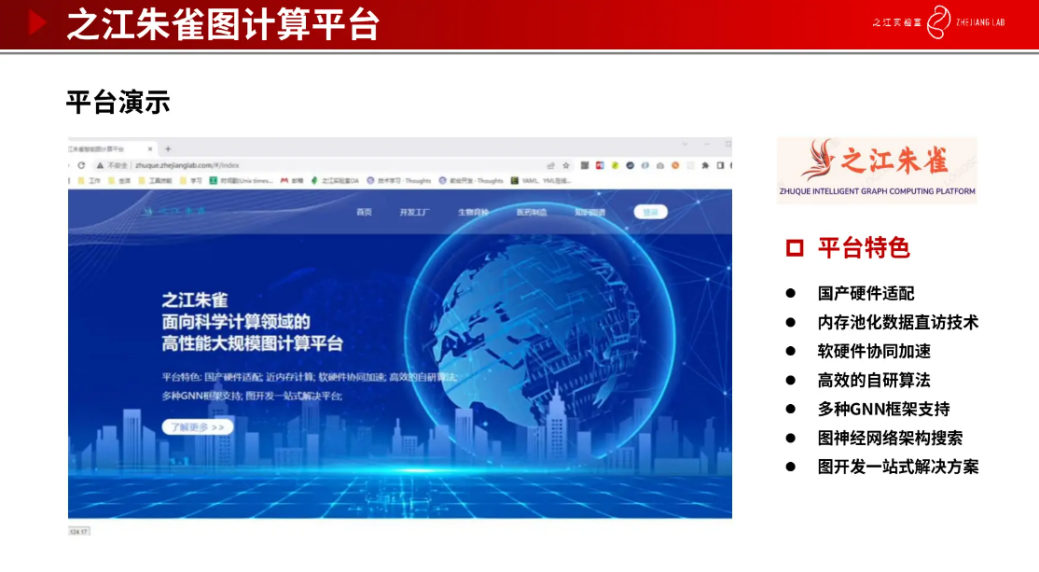
这是我们团队研发的朱雀图计算平台,集成了很多传统的图深度学习方法,包括利用分布式的存储策略等。也做了很好的国产硬件适配,包括华为的昇腾和鲲鹏。在平台上面我们可以做很多下游的任务,包括分子的生成等。其中也集成了我们自研的一些图学习算法,例如去年登榜 OGB 的孪生图神经网络 PSG 算法,通过多次中继路径采样生成多条中继路径感知的药物间最短反应路径距离的边特征张量,融合孪生图神经网络进行图表示学习和图对比学习,最终在药物-药物反应关系任务上获得 92.84% 的预测准确度,相比原冠军模型提升 2%,大幅提升了算法稳定性。比如得了新冠后,同时服用多种药物可能会产生副作用,利用我们研发的 PSG 算法就能很好的给出药物服用的建议,避免产生多种药物间的副作用。
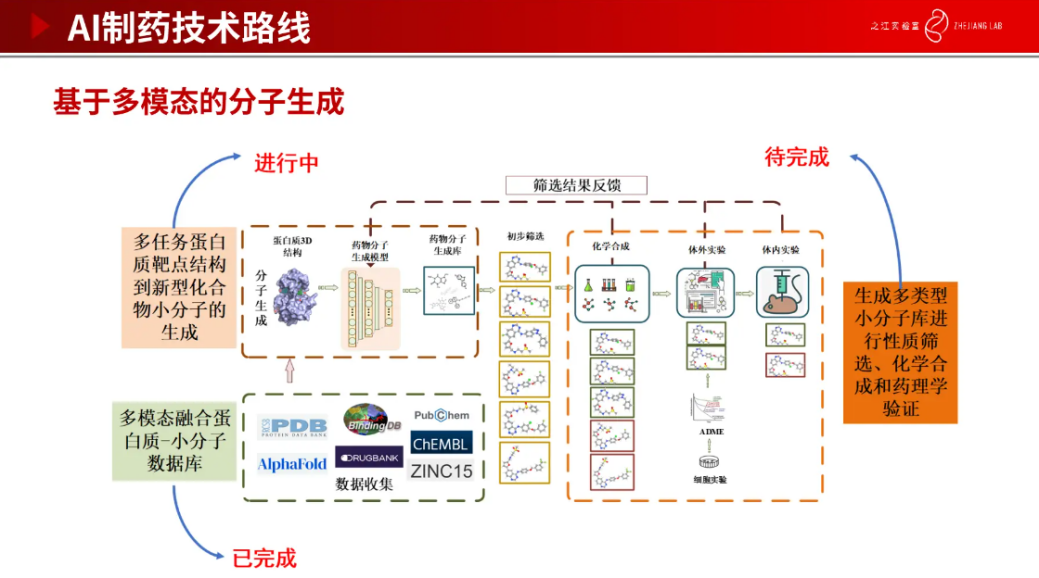
在药物发现过程中,分子生成是非常重要的一环。我们收集了大量的数据集,从而构建多模态融合蛋白质-小分子数据库。基于数据预测蛋白质 3D 结构,再通过药物分子生成模型,生成我们所需要的分子构成药物分子生成库,并对其进行初步筛选得到我们认为真正有用的药物分子。最后还需要通过湿实验对筛选分子进行验证,包括化学合成、体内实验和体外实验。找到真正有药效的小分子是非常困难的,也是非常复杂的。我们通过研发这样的模型,可以在短时间内生成大量的分子供药物学家进行筛选,加快筛选到有效的小分子。
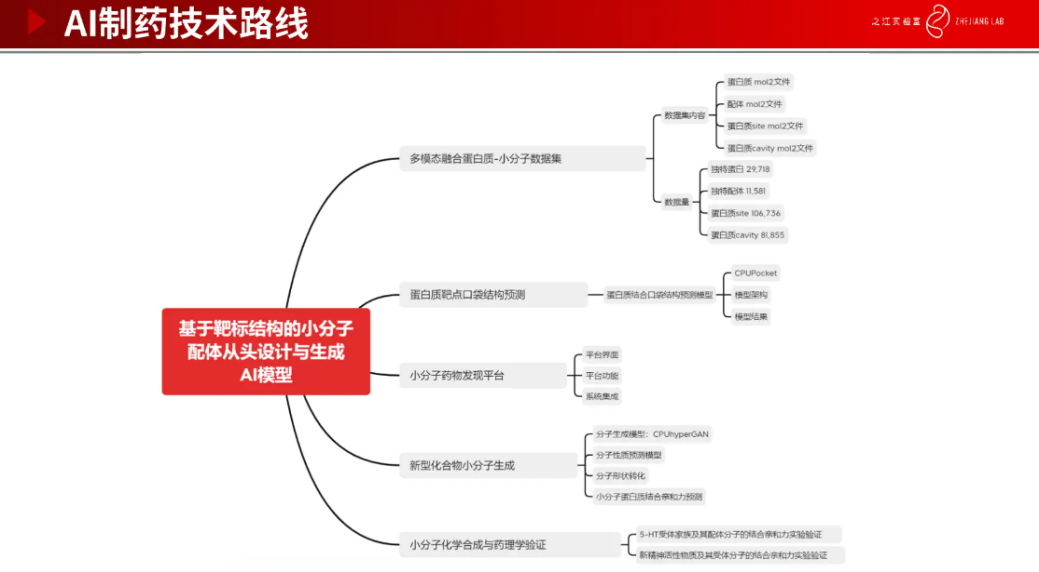
下图是基于靶标结构的小分子配体从头设计与生成 AI 模型的流程,包括构建多模态融合蛋白质-小分子数据集,蛋白质靶点结构预测、小分子药物发现平台设计、新型化合物小分子生成及小分子化学合成与药理学验证。
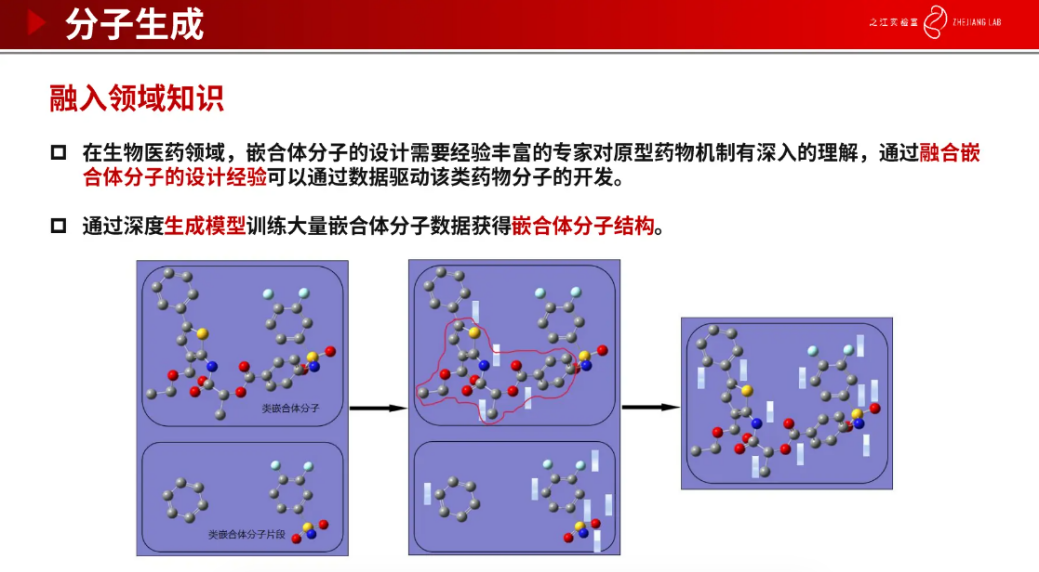
在药物分子生成之前,需要做靶点口袋结构的预测,涉及原子坐标的生成和转化。有了蛋白质口袋的预测结果后,我们要开始进行契合口袋的药物分子生成。我们团队正在开展分子生成相关的研究,其中包括基于扩散模型(Difussion)和融入领域知识等分子生成算法。我们首先介绍基于 Difussion 的分子生成算法,训练数据是原子特征和三维坐标信息,刚开始是是由随机噪声生成的初始分子图,这时候的分子并没有实际的生物意义,经过迭代一步步去除噪声,不断生成与真实分子非常接近的小分子。接下来介绍融合了领域知识的分子生成方法。传统方法需要经验丰富的专家通过对原型药物机制有深入的理解之后,融合嵌合体分子设计经验,才能生成这样的嵌合分子结构。现在有了我们这样的模型之后,可以通过深度生成模型训练大量嵌合体分子数据获得嵌合体分子结构。通过我们算法生成的分子和参考分子相差非常小,说明算法的有效性非常好。
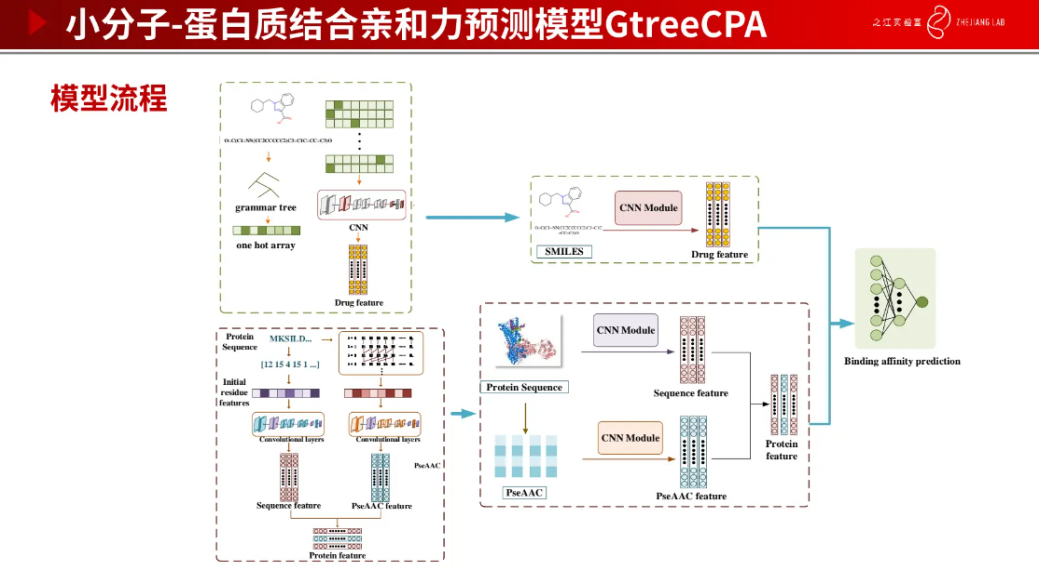
最后,我们还需要判断生成分子与靶标结合的效果如何,这也是非常关键的一环。可以通过使用亲和力预测模型来验证生成分子的有效性,亲和力越高说明生成分子与靶标结合效果越好,药物越有效。下图是模型架构。我们也在数据集上做了测试,得出的效果也都非常好。
关于大模型加速我们也做了尝试,包括图分割策略、并行策略、训练策略及算子库优化策略等。在图分割策略中,我们探索高效的图分割算法来减少跨节点通信,降低存储及计算复杂度,并通过求多节点异步执行策略来减少通信等待时延,加快模型训练。在并行策略中,我们融合了数据并行、算子级模型并行的分布式并行模式,通过动态规划,双递归等搜索策略,自动建立代价模型,找到训练时间较短的并行策略。在训练策略中,我们使用模型压缩和自动网络架构搜索来减少模型规模及参数,使用梯度求和方式和降维训练加快模型收敛速度。在算子库优化策略中,我们通过融合算子将多个可重用计算单元合并为一个计算核心,减少中间数据的 IO 传输;通过拆分复杂算子为基础算子,只需适配少量的基础算子,就可以完成对复杂算子的支持,同时优化少量简单算子就可以实现复杂算子的优化。
未来展望
之江实验室是国家级科研机构,我们希望通过产学研合作的方式,加速打造一款我们自己的生物 GPT,提升药物相互作用、分子生成和分子性质预测等任务的效果,助力药物研发。我们有充足的算力,丰富的数据和自研的算法,欢迎感兴趣的同仁们一起合作研发垂直领域专用的 GPT。我们将会在之江朱雀平台上开放模型接口、算法、数据、算力,提供一个一站式的平台,供大家开展相关领域的科学研究,谢谢大家!
人工智能 × [ 生物 神经科学 数学 物理 化学 材料 ]
「ScienceAI」关注人工智能与其他前沿技术及基础科学的交叉研究与融合发展。
欢迎关注标星,并点击右下角点赞和在看。
点击阅读原文,加入专业从业者社区,以获得更多交流合作机会及服务。



