新浪微博从 Kafka 到 Pulsar 的演变

新浪公司是一家服务于中国及全球华人社群的领先网络媒体公司。其业务涵盖新浪媒体、微博和新浪金融。新浪通过门户网站新浪网、新浪移动、新浪财经以及社交媒体平台微博组成的数字媒体网络,帮助广大用户获得专业媒体、机构和个人创作的多媒体内容并与他人进行兴趣分享和社交互动。
其中,微博是人们在线创作、分享和发现内容的中国领先社交媒体平台。新浪微博于 2009 年上线,是中国头部、流行的社交媒体平台,提供在线创作、分享和发现优质内容的服务。据微博 2022 年第一季度财报,微博月活跃用户为 5.82 亿,日活跃用户为 2.52 亿,平台日均处理万亿级消息。
新浪现有 Kafka 集群主要处理来自新浪新闻、微博等的数据,数据类型包括特征日志、订单数据、广告曝光、埋点 / 监控 / 服务日志等。这些数据经过 Kafka 在线集群、广告专用集群、日志集群、离线集群和机器学习训练等集群的处理后,会用于推荐训练、HDFS 落地、离线数仓、实时监控、数据报表和实时分析等生产目的。
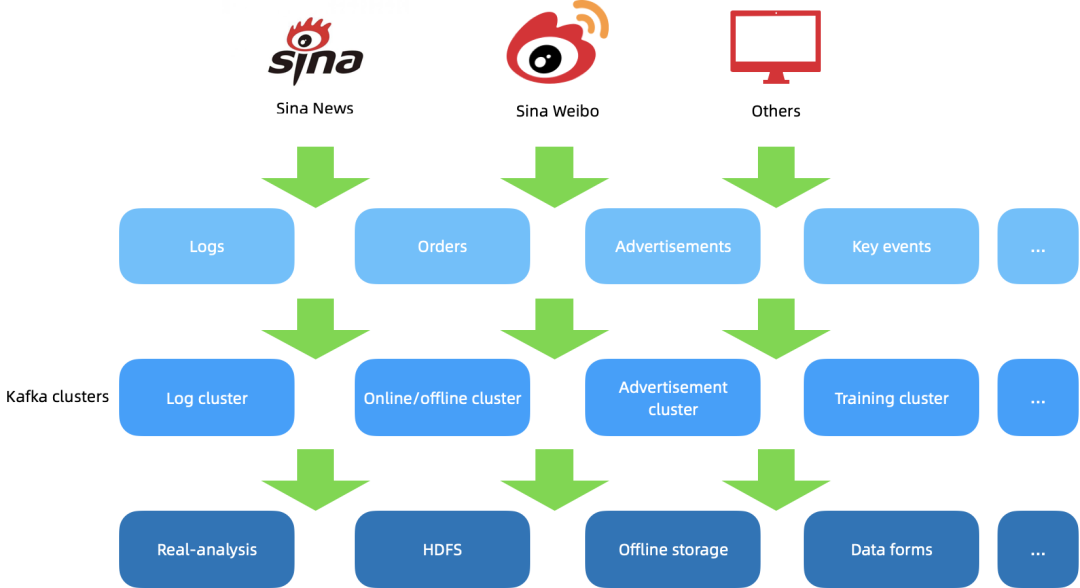
新浪在使用和运维 Kafka 集群的过程中,遇到的痛点有:
Kafka 运维较困难,突发热点事件时扩容节点无法自动均衡。在高流量峰值场景下,经常遇到了磁盘和 broker 达到瓶颈的情况。Kafka 可以轻松扩容 broker,然而集群扩容时新增 broker 无法自动承载流量,需要较为复杂的人工运维操作。
磁盘数据分布不均,topic 分区流量分布不均。随着业务波动,一些承载较大流量的 topic 下线后,其所在 broker 的流量和磁盘数据存储也会下降,类似情况多次发生后 topic 分区流量和磁盘数据分布就会失衡,需要人工干预来 rebalance 流量。
迁移分区带来数据移动,容易造成问题。流量 rebalance 需要迁移分区,相当于增加副本,在热点事件爆发、资源紧张时会造成更严重的后果。
新浪单集群每日有万亿级以上消息写入,涉及到非常多的业务方与多语言客户端,因此迁移到其他消息队列较为困难。
一些重要业务有很多作者不详的重要老代码,源码因故丢失,难以处理、迁移和改造。
团队希望能有一个消息队列可以解决 Kafka 存在的这些问题,同时业务方只需简单修改配置,替换 Kafka 的 broker list 即可迁移。基于这样的背景,团队调研了存算分离架构的 Apache Pulsar,可以很好地解决上述挑战。Pulsar 的 bookie 和 broker 是分离的,而扩容时 bookie 可以自动承接新流量;broker 只承担一些元数据的计算工作,所以需要做 rebalance 时速度很快,无需数据移动。
在调研 Pulsar 的过程中团队发现了 KoP 这个开源项目。KoP 是开源项目 Kafka-on-Pulsar 的缩写,Kafka 用户可借助 KoP 插件无缝迁移到 Pulsar,充分利用 Pulsar 的诸多功能特性,以降低迁移成本(GitHub 地址:https://github.com/streamnative/kop)。KoP 实质上就是用 Pulsar 提供的 Protocol Handler 机制来对接 Kafka 数据。当 Kafka 集群写入数据时,通过基于 Kafka Protocol Handler 来操作。KoP 复用了 Pulsar 的 topic lookup 机制和抽象的 Managed Ledger 存储层,将数据通过 bookie client 直接发送到 bookie 集群中,如下图:
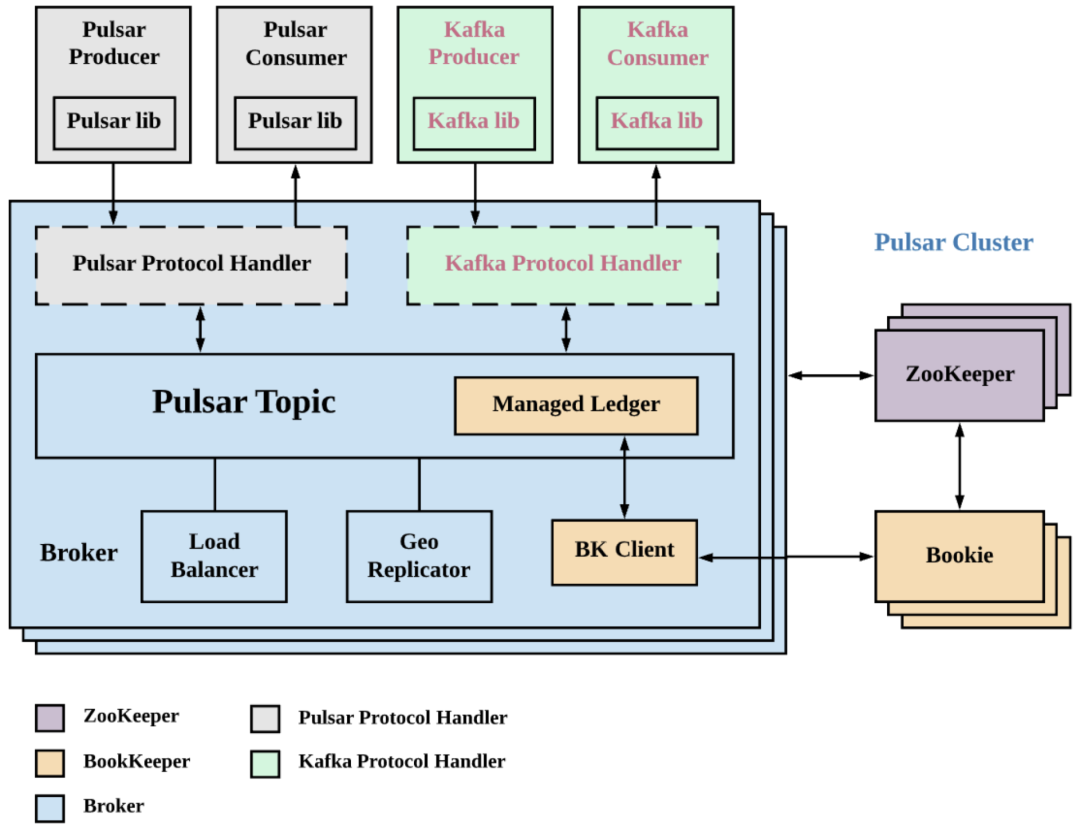
通过 KoP 协议可以落地 Pulsar 并原生支持新浪现有的 Kafka 客户端,也可以解决新浪 Kafka 团队在 Kafka 上的运维痛点。于是团队开始调研和实践 KoP 组件。在此过程中,团队也遇到了一些问题,其中一个主要挑战就是 KoP 低版本兼容性问题。
新浪 Kafka 集群中一些较重要的集群仍在使用较老的 Kafka 版本(如 0.10),因此在调研与实践中需要兼容较老版本的客户端。KoP 只支持 1.0 及以后的版本。经过总结,团队发现了以下细节问题并给出对应解决方案。
客户端需要通过认证才可以访问新浪的认证集群,与服务端交互。在 Kafka 1.0 版本之前,客户端与服务端的认证交互是通过 V0 版本的 SaslHandshakeRequest 请求完成的,之后的 token 信息由 SASL tokens(不需要 Kafka request headers)包装,这是一些不透明的数据包。所以团队需要在 KoP 中手动处理这些数据包才能完成认证工作。
在 Kafka 1.0 版本之后,认证交互通过 V1 版本的 SaslHandshakeRequest 请求完成,token 信息则由 SaslAuthenticateRequest 请求封装。KoP 处理时会直接解析 token 的协议头。KoP 的低版本认证不兼容问题主要出现在 token 信息这个层面,团队需要通过重构来避免 KoP 直接解析令牌的协议头,从而顺利处理旧版本的不透明数据包。详细代码参见 GitHub。(https://github.com/streamnative/kop/pull/676)。
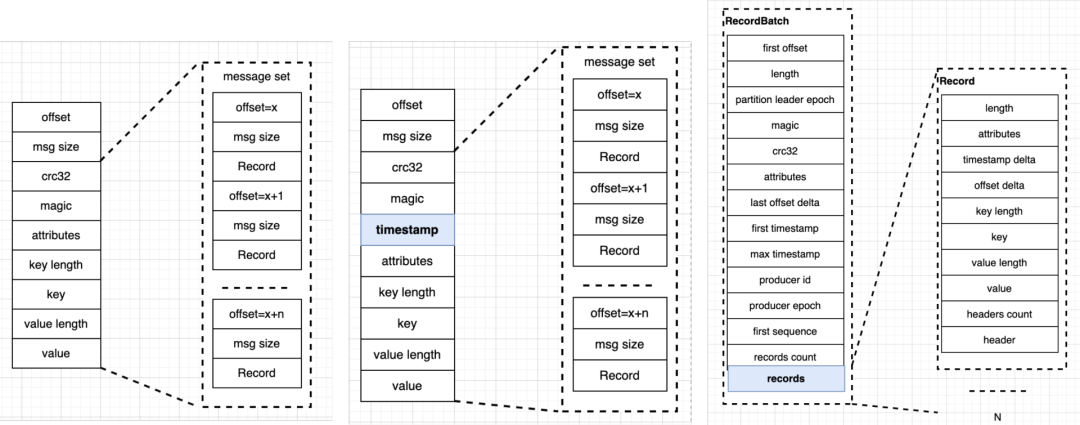
以上是 Kafka 消息协议的几个版本示意,从左至右分别为 V0、V1、V2。Kafka 0.10 版本之前使用 V0 版消息协议,0.10 版本改用 V1 版,0.11 之后改用 V2 版。V1 版本相比 V0 版本新增了时间戳;V2 版本改动较大,从 message set 变成了 RecordBatch,后者内部还封装了很多 Record。上图中各个方框内都是协议中的关键字段。V2 版本开始内部消息都使用相对位移,RecordBatch 的元数据部分只需放置起始的绝对位移。
于是不同版本之间生产消费时就会存在日志协议兼容性问题。例如一个高版本的生产者生产消息后,低版本的消费者是无法解析新版日志协议的,自然只会报错而无法消费。为此需要引入跨版本消息转换功能,才能让低版本读取高版本的消息。但如果生产者是低版本,消费者是高版本,由于协议是向下兼容的,所以数据消费不会存在问题,不需要转换。
那么 KoP 是如何处理生产者请求的呢?Kafka 客户端发来生产者请求时,KoP 解析请求后,Handler 线程会调用 ReplicaManager 主键,追加 Kafka 的 Records。这个主键与 Kafka 中的副本管理器是对应的,做了映射。
io.streamnative.pulsar.handlers.kop.storage.ReplicaManager#appendRecords每个分区对应一个 PartitionLog,映射了 Kafka 里面的 loggingScala 类对应,每一个 KoP broker 中都有一个 PartitionLogManager 来管理 PartitionLog。要将 Kafka Records 处理为消息写入 Bookie,这里的问题就是如何从 Records 编码成 Messages。
io.streamnative.pulsar.handlers.kop.storage.PartitionLog#appendRecords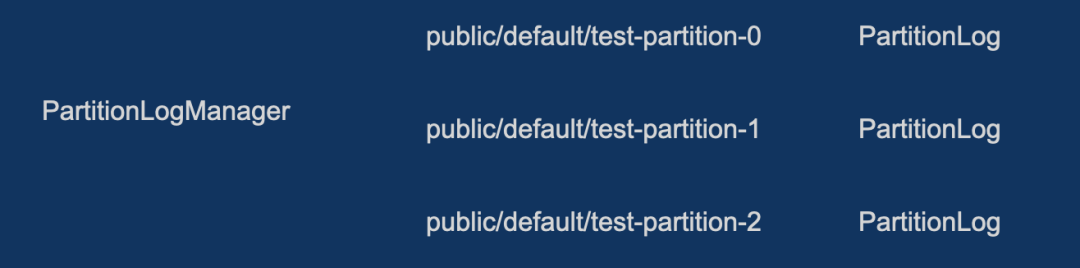
PartitionLog 在追加 Kafka 的 Records 时,会执行 EntryFormatter 的 encode 过程 io.streamnative.pulsar.handlers.kop.format.EntryFormatter#encode。编码之后会通过 Pulsar broker 的 Persistenttopic 组件 org.apache.pulsar.broker.service.persistent.PersistentTopic#publishMessage来 publishMessage。在 EntryFormat 过程中将 Kafka Records 转换为 Pulsar 消息。然后用存储层 ManagedLedger 将消息发布为 Bookie 可识别的 entry 写入 Bookie。这里的关键就是 EntryFormat 编码过程。下图引据了 entryFormat 的官网介绍,可以看到其取值可选 kafka、mixed_kafka 和 pulsar,默认为 Pulsar。

在了解转换过程之前还需了解 Pulsar Message 协议。协议中一部分信息专注于元数据,message payload 字段中包含实际数据,每个 message 中有多条消息,与 RecordBatch 类似。单条消息还有自己的元数据。
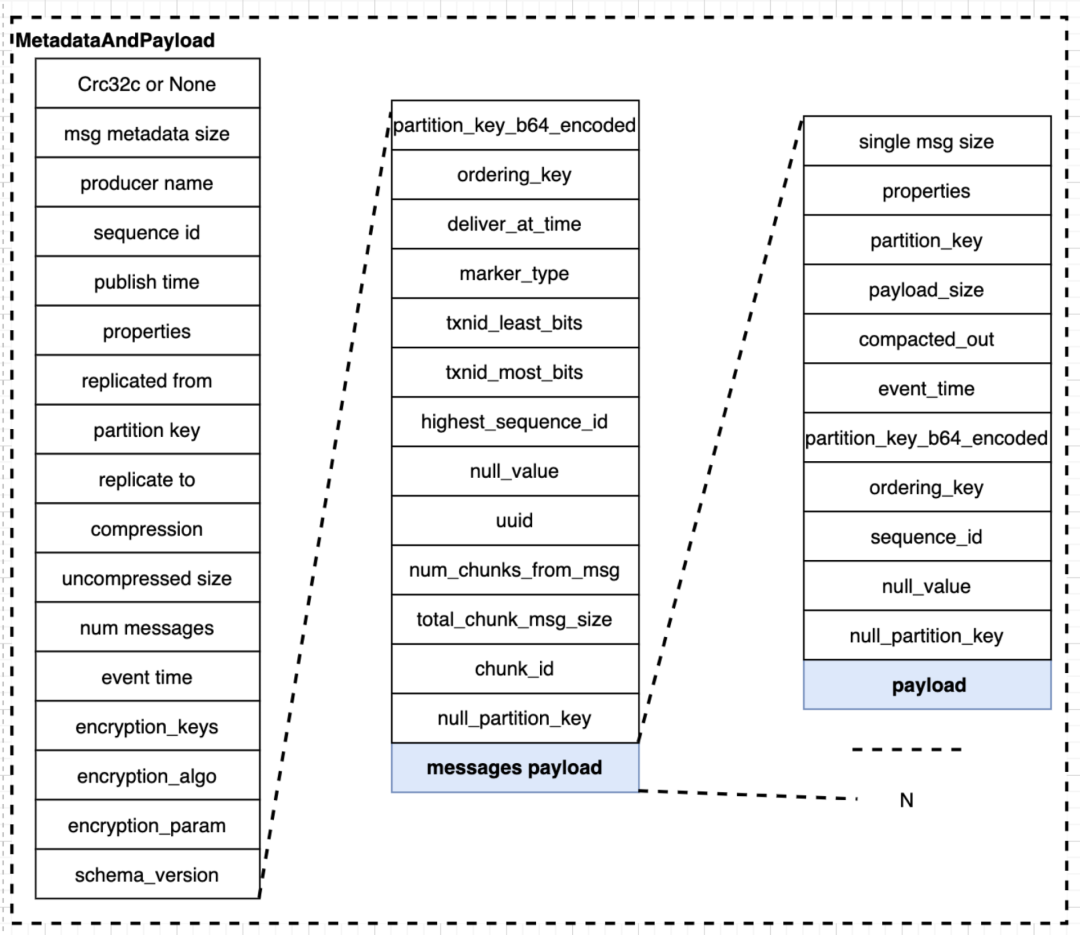
从 Kafka 请求转换为 Pulsar 消息要做协议转换。当 entryFormat=kafka(取值为 kafka) 时,主要会设置 publish time、num messages、properties(标识 message 的 entryFormat 类型,解码阶段需要),最后 payload 部分就是将整个 RecordBatch 通过 Persistent Topic 组件发送到 Broker。这里 Pulsar 的客户端无法识别解析 RecordBatch。
如果要用 KoP 将 Kafka 集群数据迁移到 Pulsar,就需要用到 entryFormat=pulsar。它会遍历 Kafka 的 RecordBatch 和内部的 Record 信息一一对应设置能够对应的 Message Metadata 和 Single Message Metadata,从而转换为 Pulsar 消息发布到 bookie。
要解决兼容性问题就要专注于 EntryFormat,根据生产者和消费者的版本情况进行消息的转换。转换会出现性能损耗,此处注意消费者版本较高时可以将转换过程交给消费者处理来节省性能。

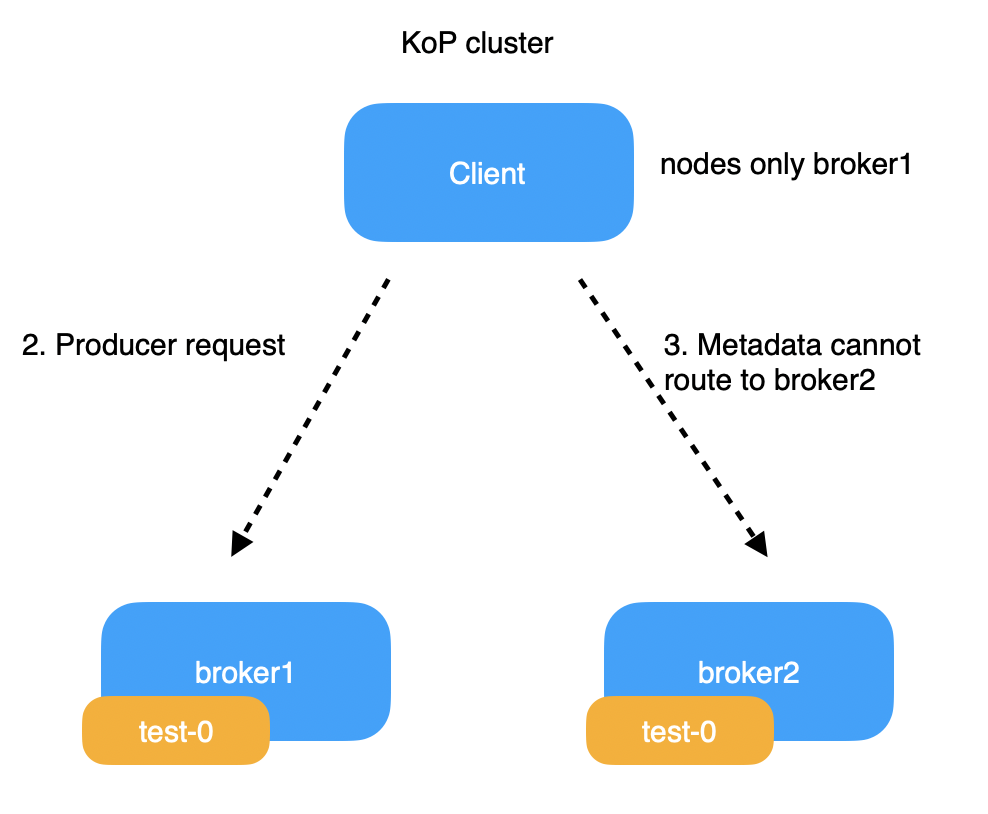
上图是一个两节点的 KoP 集群,客户端生产的 topic 的分区 0,位于 broker1 中。客户端的引导地址是 broker1 和 broker2。现在客户端要发送元数据请求给 broker2,broker2 会响应 metadata response。在 KoP 之前的处理逻辑中复用了 Topic lookup 机制,broker2 返回的 response 中不会包含自身的信息,只有分区所在的 broker1 的信息。然后客户端会向 broker1 分区的 leader 节点发送生产者请求。
Broker1 挂掉后,分区 0 会容错到 Broker2 上。于是 broker2 成为分区 0 的 owner。这时客户端向 broker1 发送元数据请求失败,又因为自身没有 broker2 的处理逻辑,所以元数据就无法路由到 broker2 上,出现元数据超时问题。
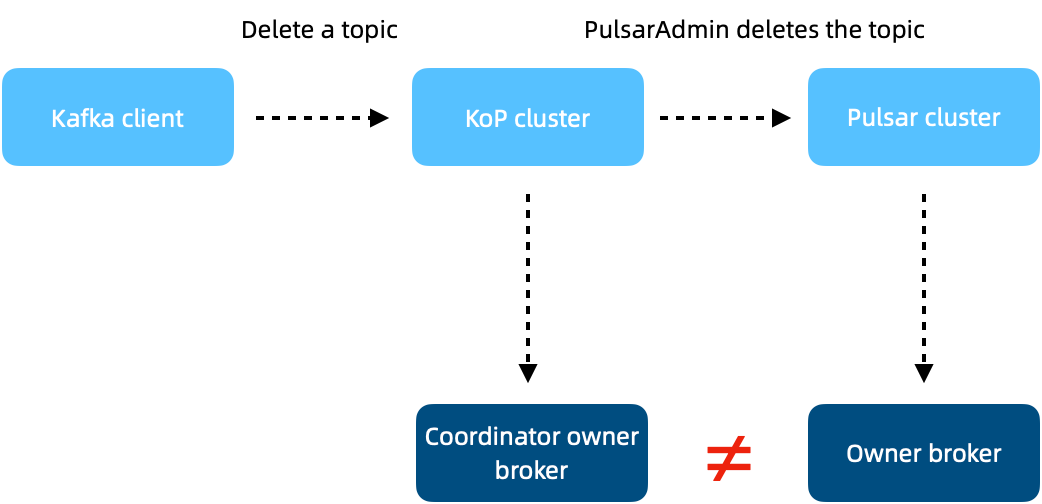
如上图,通过 KoP 消费 topic 时,消费的组元数据信息都会记到 coordinator 中,用 ./bin/kafka-consumer-groups.sh --bootstrap-server localhost:9092 --group my-group --describe可以看到描述的消费信息。当 topic 下线并删除时(./bin/kafka-topics.sh --bootstrap-server localhost:9092 —topic test —delete),再去描述组信息就会返回原数据超时异常。因为 admin 客户端执行删除命令时,请求到达 KoP Cluster,KoP broker 会通过 PulsarAdmin 删除 topic。Pulsar Cluster 处理删除请求时,会发送到所有分区的 owner broker 上,后者负责删除 topic 信息并移除 topic。
但因为 Group 元数据信息位于 coordinator 中,其 owner broker 和 topic owner broker 不在一起,所以删除后者时无法清除前者,就会出现残留。问题发生原因是 Group Coordinator 里面有 Group 元数据信息记录了消费分区,客户端在获取分区时 commit offset 会记录 Lag 值,Kafka 当前生产的消息位移。之后获取 topic 信息,但是由于 topic 已经删除,因此会一直返回 onload partition 错误。命令工具不断重复尝试获取元数据直到 Request Timeout 超时并暴露超时。
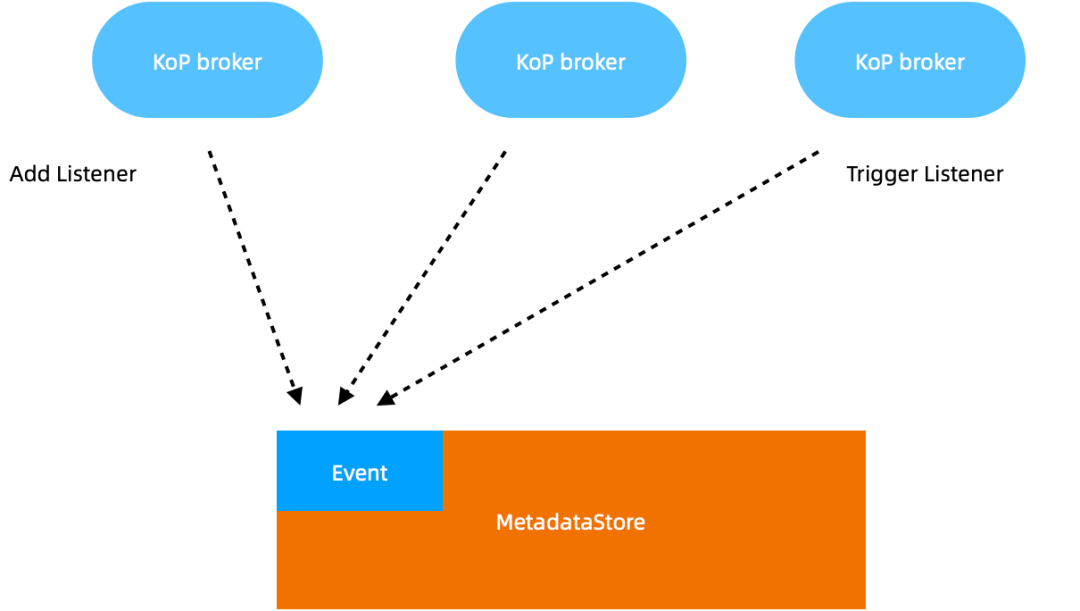
上述问题的核心原因在于 KoP Broker 属于无状态服务,一致性无法得到很好的保障,所以需要引入一个基于 MetadataStore 的元数据事件处理器, 对应的是 Pulsar ZooKeeper。Broker 上线时会触发 Listener 事件,其他 broker 会监听该事件并处理元数据变更。删除 topic 时会触发 topic 删除事件,其他 broker 会响应事件,coordinator 会将对应的元数据信息移除,解决残留问题。
本文介绍了新浪微博通过使用 KoP 落地 Pulsar 来解决大规模 Kafka 集群运维的痛点。新浪微博在 KoP 支持 Kafka 0.9 与 0.10 版本客户端,并引入元数据事件管理器解决版本兼容与日志协议兼容的问题。作为 KoP Maintainer,截至目前,沈文兵已给 KoP 提交 42 个 PR,合并 36 个。未来他会继续参与 KoP 的维护和开发工作。
目前 KoP 功能日趋完善,Kafka 的大部分功能都已经在 KoP 中得到实现。如果大家在工作中面对 Kafka 运维的痛点,非常推荐大家通过 KoP 组件搭建解决方案。
作者简介:
沈文兵,新浪微博数据平台研发工程师,主要负责 Kafka 和 Pulsar 的运维研发工作。开源项目爱好者,Apache Pulsar/BookKeeper/Kafka Contributor,KoP(Kafka-on-Pulsar)Maintainer。
阅读原文 ,关注 Apache Pulsar。
“华为 30 岁以下员工仅占 28%”上热搜;腾讯二季度净利润腰斩,员工减少超 5500 人;百度网盘回应人工审核用户照片|Q 资讯




