![]()
泛日志(Log/Trace/Metric)是大数据的重要组成,伴随着每一年业务峰值的新脉冲,日志数据量在快速增长。同时,业务数字化运营、软件可观测性等浪潮又在对日志的存储、计算提出更高的要求。
从时效性角度看日志计算引擎:数仓覆盖 T + 1 日志处理,准实时系统(搜索引擎、OLAP) 瞄准交互式场景,实时需求则加速了 Flink 等流引擎的发展。
再回到用户场景角度,各式各样的数据呼唤多种计算模式,例如本文要讨论的日志搜索场景:
顾名思义,Scan 模式过数据硬算,给人第一印象是慢。近些年随着新技术的应用,Scan 模式的性能表现在今天已经得到较大提升:
另外,schema-on-read 技术对 non-schema 有很大的包容性,无需复杂的前期业务规划,其应用的典型场景有:数据湖,日志搜索、分析。
ELK 是老牌的日志套件 ,Elasticsearch 基于 Lucene 构建倒排索引、DocValue 分别提供搜索、分析能力,性能表现不错,但存储膨胀比例高。
阿里云日志服务(SLS) 为 Log/Metric/Trace 等数据提供大规模、低成本、实时的平台化服务,是目前国内领先的日志套件产品。
SLS 在为公共云数十万客户提供日志服务,并支撑阿里、蚂蚁集团日志基础设施的多年来,通过高性能的索引技术为用户提供亿级秒查能力。
“增效降本”是软件服务的长期价值,也是当前企业客户的客观需求:
从数据特性上看,日志打印格式较难统一(尤其是程序日志)。例如,在一个日志文件里出现多个模块的日志内容,有些行包括 a/b/c 三个字段,另一些行是 b/d/e/f/g 五个字段,甚至一些行的内容字段无法确定。面对如此弱 schema 日志,基于字段索引方案,很难在一开始把所有的索引 key 枚举完整,导致在查询时找不到数据。
注:虽然 SLS 提供索引重建功能,这一过程较耗时也花费成本,应对 schema 不确定的情况时,频繁索引操作是一种运维负担。
一些日志是写多查少的,数据量很大,从业务上判断可能每周只查一两次。使用者优化日志费用的手段是:在全量索引基础上去掉 50% 不常用的字段索引,达到费用下降近半、高频字段保留低延迟搜索功能的效果。但对于低频字段数据的偶尔查询,没有高效的办法。
SLS 新推出 Scan 功能,让未索引的字段也支持搜索(硬扫描模式),节省全量索引产生的构建和存储费用,同时 Scan 的运行时计算模式对于杂乱结构的日志数据有更好的适配,帮助企业客户实现数字化增效、IT 支出降本的目标。
Grafana Loki 在 2019 年提出区别于 ES 的日志查询方案,是 Scan 方式实现日志搜索和低频分析的优秀代表。其发展至今存储 schema 已经演化至 v11,目前仍存在一些影响大规模生产部署的设计限制:
Label cardinality 问题:Label 是要做索引的,如果值的基数过大,索引膨胀不可避免,麻烦的是会引起来一系列不可用问题,例如数据无法写入,查询失败(默认 500 series)。
Label Index 对场景适应性:Label 过滤可以通过索引加速,但设置不灵活且有限制,按非 Label 字段搜索时可能从 chunk 里读取大量数据,对于对象存储的带宽要求很高。
读取全量结果很困难:Loki 的计算过程是通过 Label index 做布尔运算命中 chunk 文件列表,将所有 chunk 读取到内存计算排序输出,限制一次查询结果条数截断 5000,这个限制无法通过翻页绕过,因其没有存储上实现细粒度 offset 机制。
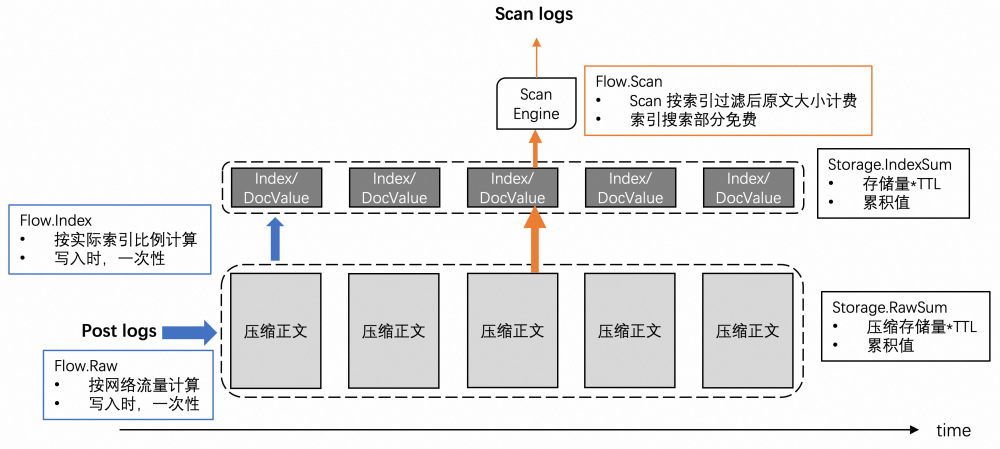
回到 SLS 上,目前广泛采用的索引可以理解为一种类似 Elasticsearch 的自研高性能实现。数据如果未建索引,“民间”的 Scan 解决方案是“SLS + Consumer”,比如这个 Consumer 是 Flink,客户付出 SLS 读数据的网络流量、Flink 集群计算 CU 的成本,也可以进行 Scan(因缺少存储下推支持,大数据量下耗时)。
SLS 原生 Scan 能力设计的首要原则是补齐短板并继续发挥长处:
SLS 是日志中枢,对接了丰富的数据源(写入支持友好:端多、吞吐大、schema 灵活)和下游系统(数据开放)。Scan 专注在计算上,补齐未索引字段不能搜索的短板,不能引入类似 Loki 的写入限制。
SLS 全索引技术在过去提供 O(1) 的复杂度高性能查询,而 Scan 依赖高带宽数据流转(可能 99.9% 在运算后被过滤掉)。Scan 与 SLS 索引做结合则带来好处:少量索引为 Scan 提供存储下推能力,并且可以灵活选择哪些字段做索引。
SLS Scan 应提供完整结果获取能力,单次的 Scan 维护在 Shard 存储的计算点位,多个 Shard 间处理进度做协同来进行翻页。
最后,Scan 功能的加入不能打破云服务对比自建开源软件的一贯优势:Serverelss(按量付费)、全托管(免运维)。
![]()
综上,Scan 是在 SLS 存储、生态这颗树上发展出来的新能力。
![]()
计算是解耦于统一存储( Log/Metric/Trace)之上的一层,SLS 上应用最多的是强 schema 模型做快速计算,Scan 模式是新增的选项,无论使用与否不应与其它组件冲突。
一是场景分层:Query 规格 Logstore 面向程序日志搜索、短周期存储,在相同的费用下可开启更多的索引字段;Standard Logstore 支持搜索以及高性能的统计分析。Scan 支持了全部这两种规格的 Logstore。
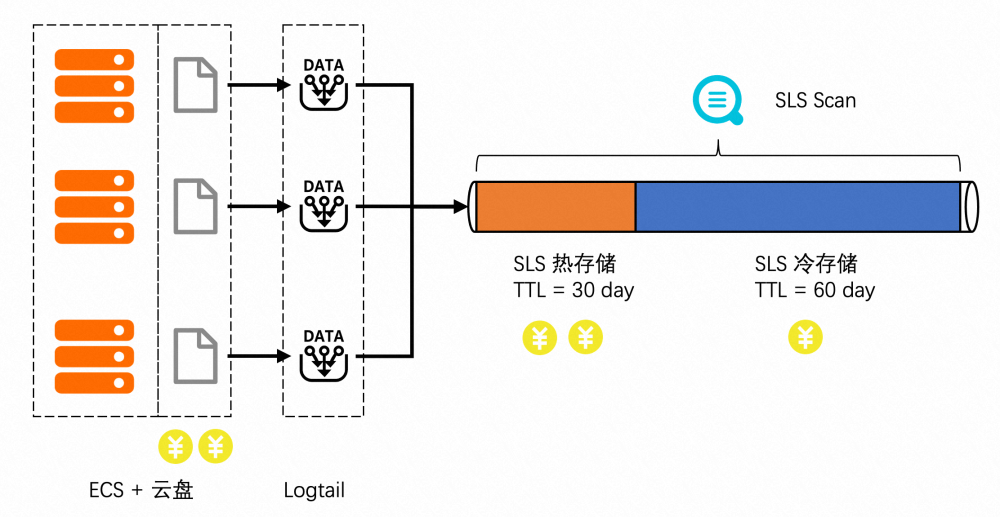
另一个是冷热分层:存储周期超过 30 天的冷存储可以转为冷存降低 56% 存储费用,而无论是热存或冷存,提供同样的 Scan 性能表现。
SLS 在 pub/sub 场景下支持的是 receive_time 存储模型,即按照数据到达服务端时间顺序存储、消费计算。在搜索、分析场景,按业务时间(event_time)处理是天然的需求。试想日志到达服务端迟到的场景,通过 receive_time 模型获取完整结果引入更大的代价(读取放大)。Loki 基于 event_time 模型构建 chunk 分段,对过期很久的日志写入支持是不足的,依赖 LSM tree、后台合并等机制。
SLS Scan 选择与索引(支持 10+MB/s 单 Shard 写入能力)相结合的设计,通过索引下推、协程化 IO、分页处理使用户享受到 event_time 模型的带来的便利性,同时在性能表现上取得平衡。
![]()
Scan 语法定义为两段式:{Index Query} | {Scan Query: where <bool_expression>},管道符后是 SQL 语法 where 子句。
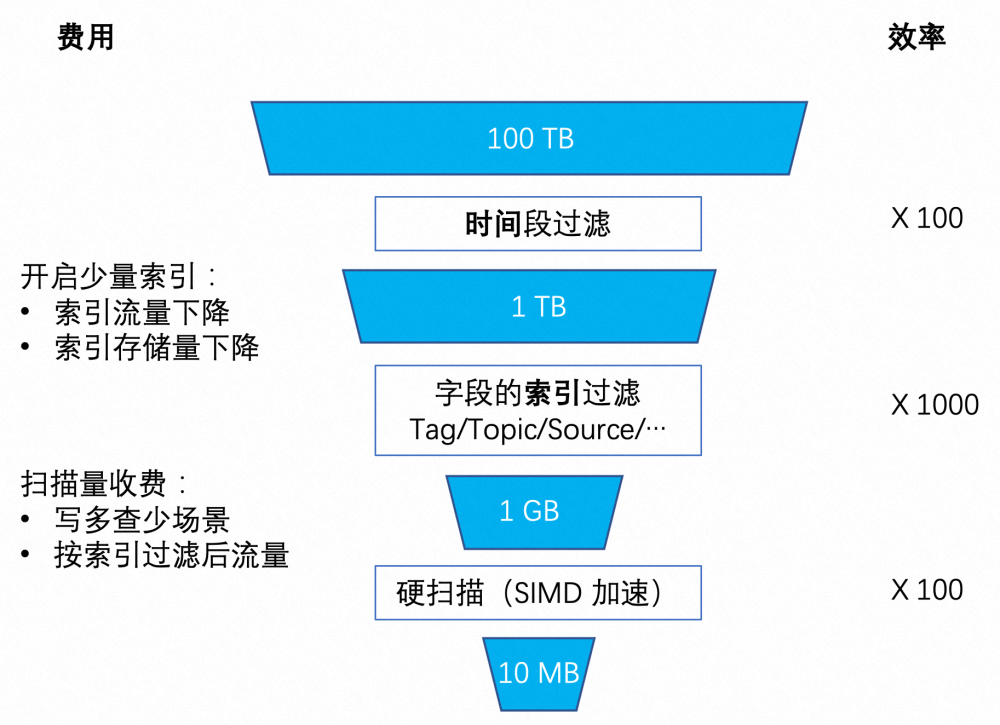
时间是天然的日志主键,例如存储周期 30 天 100 TB 的数据,查询时间窗口选择为最近 6 小时,则数据量缩减到 1 TB。且时间过滤只需要根据索引(时间字段引入的膨胀比低到可忽略)、meta skip 就可以快速完成。
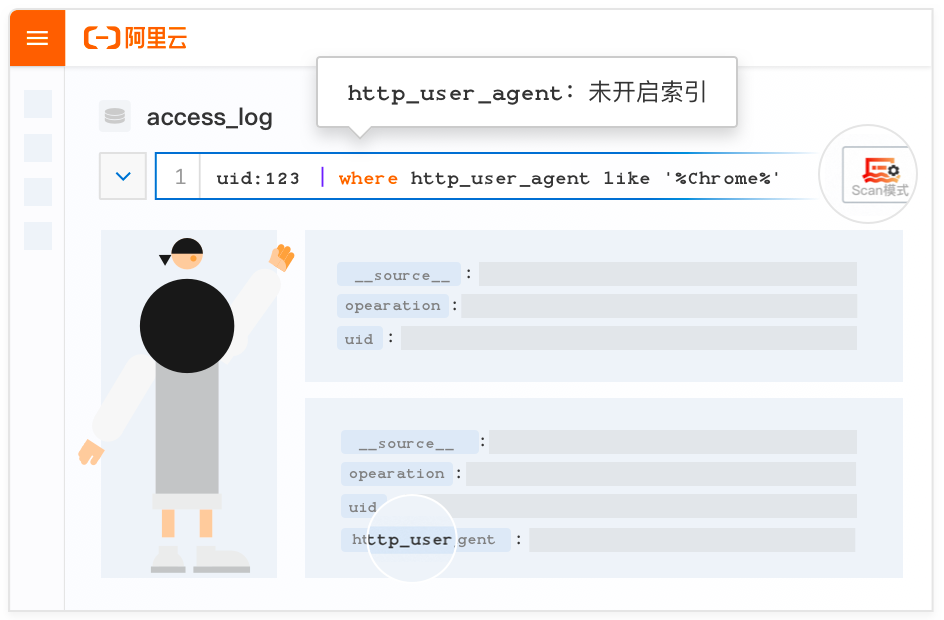
这里所说的业务字段可理解为 Loki 的 Label 概念,但更为灵活,可以在日志到达 SLS 之后再自由选择。一般是选择可缩小下一步搜索范围或是被高频访问的字段,例如 K8s 日志可以将 namespace、image、node hostname、log path 设置索引。能匹配业务查询需求的字段索引,将大大地降低需要硬扫描的数据量,降低扫描费用和响应延迟。
在索引命中的结果集上做最后的硬计算,SLS Scan 用 C++ 实现避免性能表现在数据规模上涨后衰减(Loki 受 GC 影响),部分高频算子做向量化加速。另外,SLS Scan 使用一个大的计算池(几百台 x86 多核服务器)来爆发算力,计算的并发度按照 Logstore(日志库)的 Shard(存储分片)数水平扩展。
如果对 Grafana Loki 和 ClickHouse 在日志方案上做一个对比,ClickHouse 短板之一是 UI 和使用习惯离日志工具距离比较远。用户需面对 SQL Editor 做输入,改语句做 offset/limit 翻页,看不到日志统计图,没有选取、跳转等交互支持,以上种种表明了日志查询工具 UI 对于工作效率的影响。
针对日志 Scan 场景,SLS 在 UI 新特性上的匹配包括:
独立开关表明当前的查询模式:新支持 schema-on-read 能力(无需预先构建索引),Scan 部分需按流量计费,查询延迟将会增加。
![]()
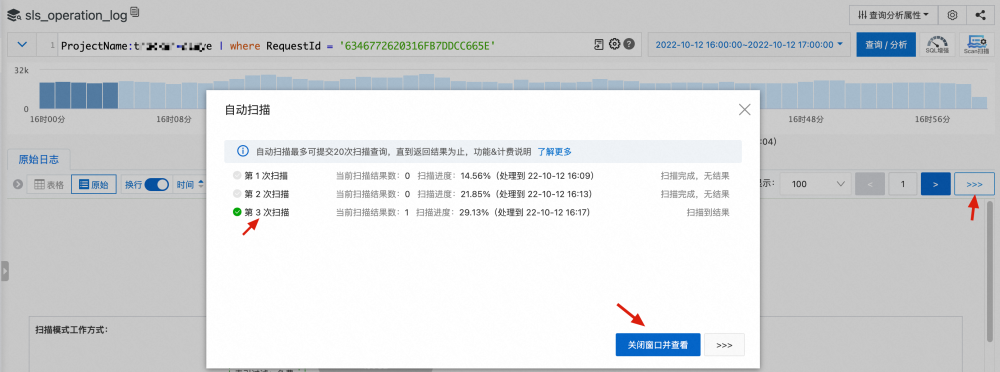
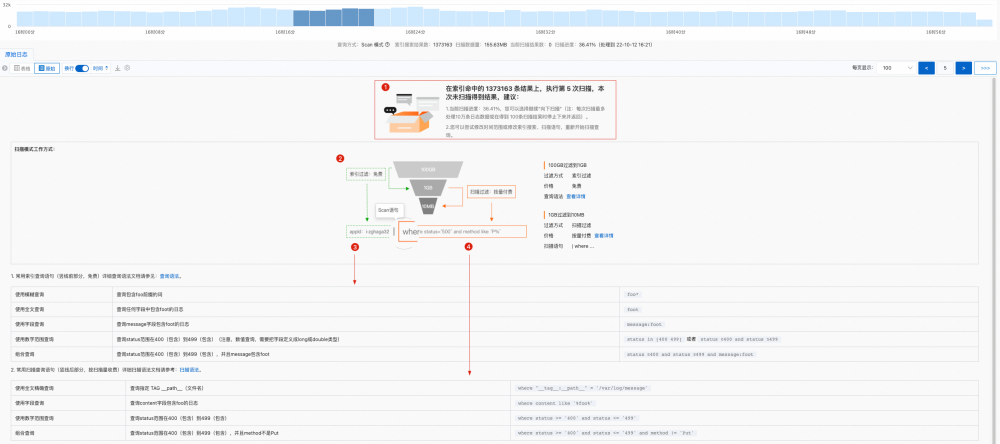
指定时间范围内如果命中大量日志,需通过翻页机制实现迭代获取,在柱状图上浅色部分是通过索引过滤后的候选结果,本次 Scan 翻页计算所覆盖的数据部分通过深色柱状图来展示,每一次翻页操作伴随着深色柱状图的平移。
![]()
Scan 计算结合多种因素(单次扫描费用可预估、近交互式体验)考虑设计了停止条件,当计算超时或命中预设结果数量或扫描超过预设数据量后,将结束本次 Scan 扫描,此时可能无结果返回。
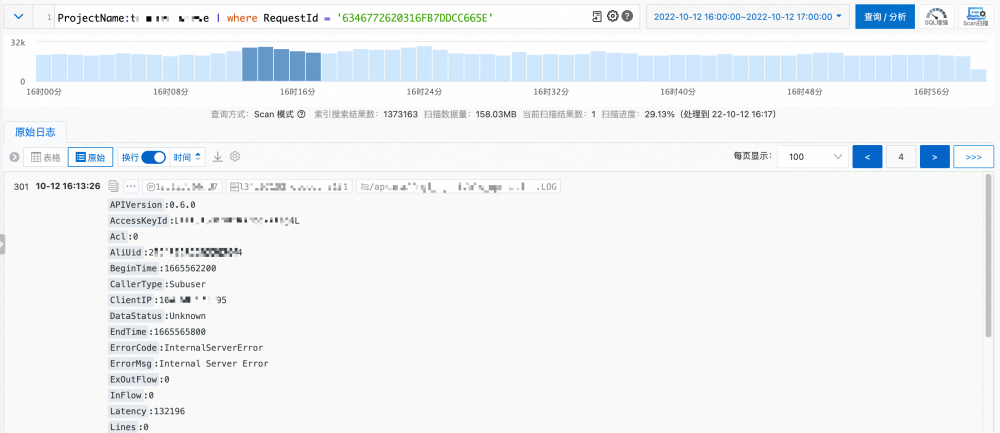
一次 Scan 未查到结果,不能代表整个时间段内没有数据(尤其是大规模数据下的稀疏命中场景,例如查询 RequestId),SLS 提供一个快进按钮 >>> 帮助快速跳过空结果的 Scan 翻页。
![]()
![]()
无结果命中的情况(展示:进度、工作机制、语法 tips):
![]()
Scan 的搜索(过滤)能力相较于经典的搜索语句(布尔组合、等于、不等于、前缀),扩展了更多的
算子支持
。
JSON 字段提取:一整条日志是一个 json 结构,可以通过 json_extract_scalar 函数解析做特定节点值匹配。
字符串函数、正则函数:通过各类函数预处理得到一个临时结果字符串做匹配。
模糊匹配:%算子可以支持任意的前缀、后缀等匹配模式。
-
类型转换:通过 cast 运算符可以对字符串类型做转换,例如基于两个字段转为 int 做加法后的结果筛选。
Scan 搜索过程是分页、交互式的,一是保证了单次扫描的响应延迟,模拟人看日志的习惯(grep | head -n {number}),二是减少不合理的查询语句消耗过多资源而产生费用的浪费的情况。
Scan 部分的计算消耗比索引要大得多,因此会有较高的延迟(单次秒级别),SLS 也将对扫描部分的流量收取费用。相比于 Loki 预留机器实例的成本,SLS Scan 按需对扫描流量计费更有利于写多读少场景。
![]()
功能、费用、性能三角是一个 trade-off,Scan 不是银弹,应合理使用。实践原则如下:
1. 如果数据已经建立了全文索引或对全部字段建立了索引:一般情况下不应再使用 Scan 模式,直接用索引即可(无资源消耗不收费,且更快)。
2. 费用上,应考虑数据读写比例:从流量看,建索引对比 Scan 的单价比是 7 比 1;同时需考虑建索引产生的额外存储费用,以及查询时少量索引下推可减少 Scan 流量。一般建议写对读(查询)流量比例大于 50:1 的数据可考虑使用 Scan 模式。
3. 效率上,对于一些重型使用场景(例如工单排查,每天需数百次在亿级日志上搜索)推荐索引模式,业务功能选型都应以提效降本为出发点。
举例一种老业务场景:企业将日志文件做 logrotate,历史数据压缩放置在云盘(块存储)上,按等保要求留存几个月后定期删除;日志查询过程是找到目录(基于时间、业务)、文件名,执行 grep/zgrep 单机查找。
![]()
1. 通过高性能(10% CPU 处理 2~10 MB/s)采集器(Logtail)将日志实时采集到日志库存储,采集对业务无侵入,无需改造程序。
2. SLS 日志存储支持冷、热分层,超过 30 天后转为冷存,冷存单价是高效云盘的 50%。
3. SLS 日志存储支持按 TTL 自动删除旧数据,也支持数据转储 OSS 长周期存储,无需运维。
4. SLS Scan 支持对存储的热、冷分层数据进行硬扫描搜索,查找延迟大大低于单机形式的解压缩后 grep。
举例在程序日志查询、Debug 场景下:当前开启 SLS 100% 数量的索引字段,经过业务判断,字段使用上有明显的特征,99% 时候只用到其中 20% 的字段,希望合理使用降低一些日志的 IT 支出。
假设日志有 10 个字段(简化理解,每个字段的 key/value 长度相同),分别是 key_0/key_1/.../key_9,其中 key_0/key_1 是被经常使用到的,那么基于 Scan 方案可大幅降低使用成本。
4. key_2/.../key_9 是低频访问,假设每天索引过滤后 Scan 流量占原文流量 10%。
![]()
K8s 微服务多个应用的容器日志收集到一个日志库里。
业务升级后,程序日志字段发生变更。
通过自描述格式打印出来的日志,在日志产生时字段即不确定(例如 JSON 打印)。
程序在打印日志时,有 20 个字段是一定存在,还有 20 种字段是可选的。
-
以上情况发生时,通过固定 schema 方式查询、分析较为困难:
1. 业务上明确规划的日志字段、高频使用的日志字段设置索引,明确类型,查询、分析时基于索引、列存。
2. 其它的低频日志字段或不明确的字段,不配置索引,查询需求通过 Scan 在运行时完成计算。
![]()