一行代码,Pandas秒变分布式,快速处理TB级数据
夏乙 发自 凹非寺
量子位 出品 | 公众号 QbitAI
刚刚在Pandas上为十几KB的数据做好了测试写好了处理脚本,上百TB的同类大型数据集摆到了面前。这时候,你可能面临着一个两难的选择:
继续用Pandas?可能会相当慢,上百TB数据不是它的菜。
(ಥ_ಥ) 然而,Spark啊分布式啊什么的,学习曲线好陡峭哦~在Pandas里写的处理脚本都作废了好桑心哦~
别灰心,你可能真的不需要Spark了。
加州大学伯克利分校RiseLab最近在研究的Pandas on Ray,就是为了让Pandas运行得更快,能搞定TB级数据而生的。这个DataFrame库想要满足现有Pandas用户不换API,就提升性能、速度、可扩展性的需求。
研究团队说,只需要替换一行代码,8核机器上的Pandas查询速度就可以提高4倍。
其实也就是用一个API替换了Pandas中的部分函数,这个API基于Ray运行。Ray是伯克利年初推出的分布式AI框架,能用几行代码,将家用电脑上的原型算法转换成适合大规模部署的分布式计算应用。
Pandas on Ray的性能虽说比不上另一个分布式DataFrame库Dask,但更容易上手,用起来和Pandas几乎没有差别。用户不需要懂分布式计算,也不用学一个新的API。
与Dask不同的是,Ray使用了Apache Arrow里的共享内存对象存储,不需要对数据进行序列化和复制,就能跨进程通讯。
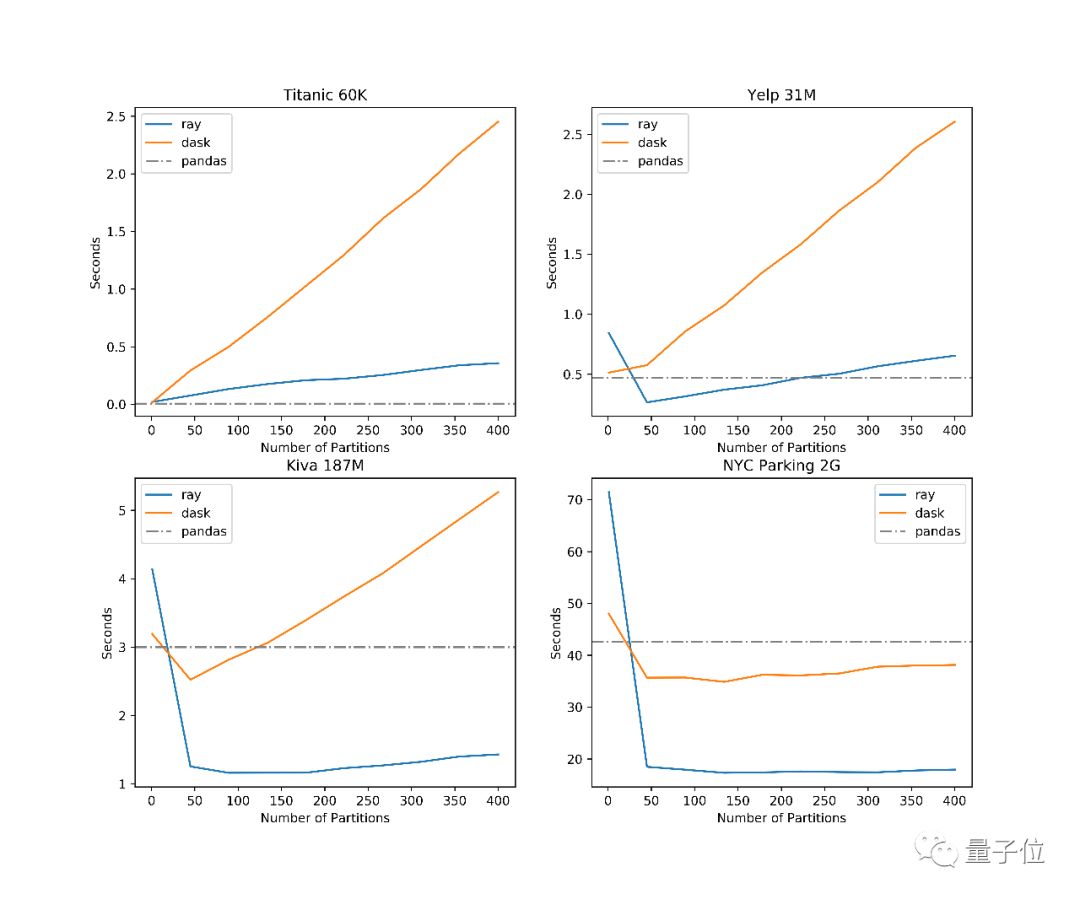
△ 在8核32G内存的AWS m5.2xlarge实例上,Ray、Dask和Pandas读取csv的性能对比
它将Pandas包裹起来并透明地把数据和计算分布出去。用户不需要知道他们的系统或者集群有多少核,也不用指定如何分配数据,可以继续用之前的Pandas notebook。
前面说过,使用Pandas on Ray需要替换一行代码,其实就是换掉导入语句。
# import pandas as pd
import ray.dataframe as pd这时候你应该看到:
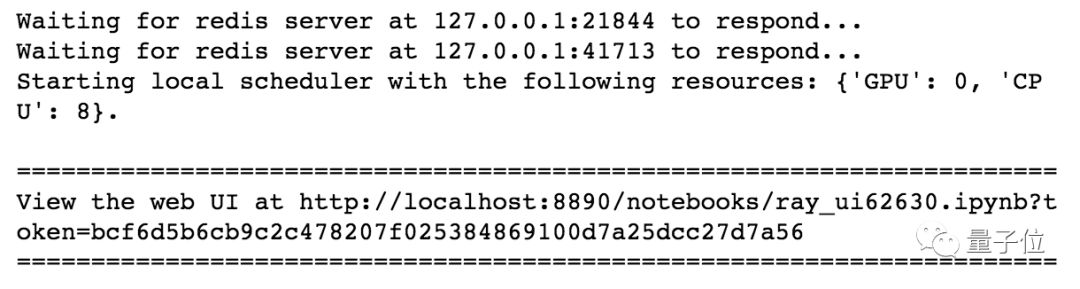
初始化完成,Ray自动识别了你机器上可用的核心,接下来的用法,就和Pandas一样了。
Pandas on Ray目前还处于早期,实现了Pandas的一部分功能。以一个股票波动的数据集为例,它所支持的Pandas功能包括检查数据、查询上涨的天数、按日期索引、按日期查询、查询股票上涨的所有日期等等。
这个项目的最终目标是在Ray上完整实现Pandas API的功能,让用户可以在云上用Pandas。
目前,伯克利RiseLab的研究员们已经用45天时间,实现了Pandas DataFrame API的25%。

革命尚未成功,项目仍在继续。这些人都在为之努力:
Devin Petersohn, Robert Nishihara, Philipp Moritz, Simon Mo, Kunal Gosar, Helen Che, Harikaran Subbaraj, Peter Veerman, Rohan Singh, Joseph Gonzalez, Ion Stoica, Anthony Joseph
更深入地了解Pandas on Ray请看RiseLab博客原文:
https://rise.cs.berkeley.edu/blog/pandas-on-ray/
试用Pandas on Ray请参考这个文档:
https://rise.cs.berkeley.edu/blog/pandas-on-ray/
给Ray团队提要求请到GitHub开issue:
https://github.com/ray-project/ray/issues
如果对Ray感兴趣,可以读一读他们的论文:
https://arxiv.org/abs/1712.05889
— 完 —
加入社群
量子位AI社群15群开始招募啦,欢迎对AI感兴趣的同学,加小助手微信qbitbot6入群;
此外,量子位专业细分群(自动驾驶、CV、NLP、机器学习等)正在招募,面向正在从事相关领域的工程师及研究人员。
进群请加小助手微信号qbitbot6,并务必备注相应群的关键词~通过审核后我们将邀请进群。(专业群审核较严,敬请谅解)
诚挚招聘
量子位正在招募编辑/记者,工作地点在北京中关村。期待有才气、有热情的同学加入我们!相关细节,请在量子位公众号(QbitAI)对话界面,回复“招聘”两个字。

量子位 QbitAI · 头条号签约作者
վ'ᴗ' ի 追踪AI技术和产品新动态


