CCKS 2019 | 百度CTO王海峰详解知识图谱与语义理解
机器之心发布
机器之心编辑部
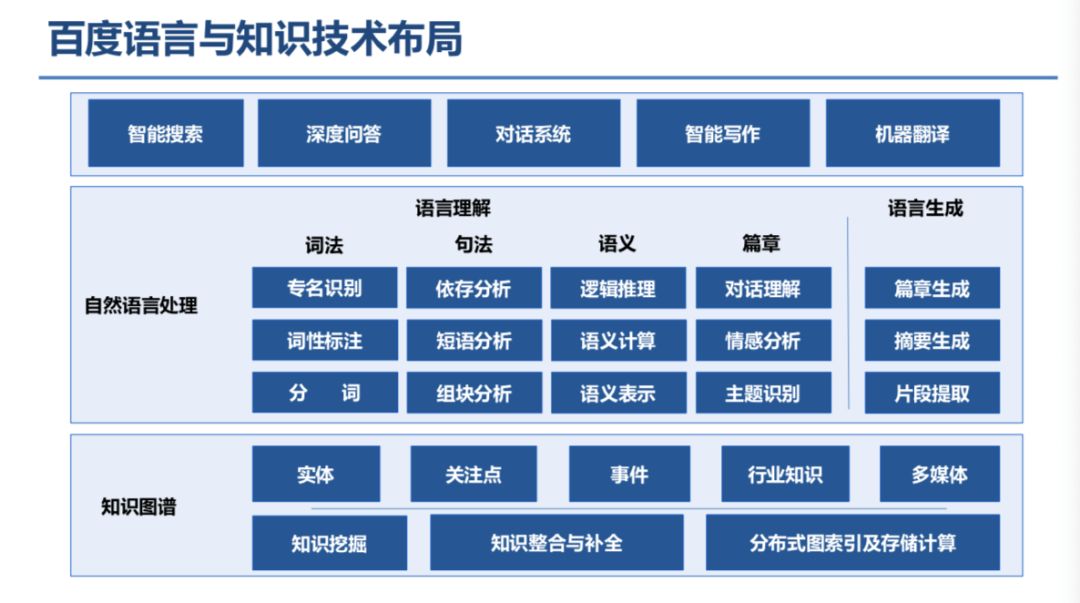
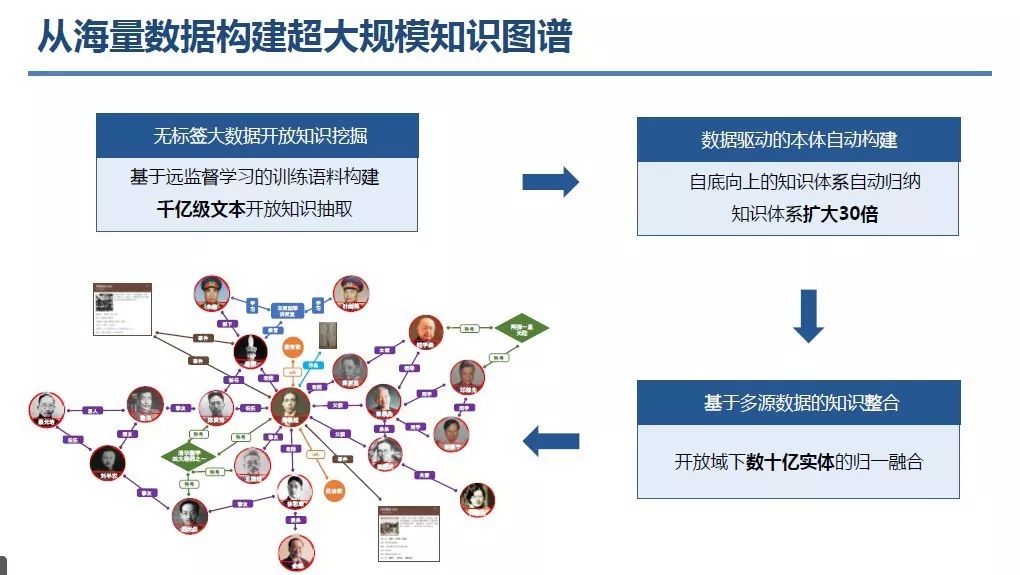
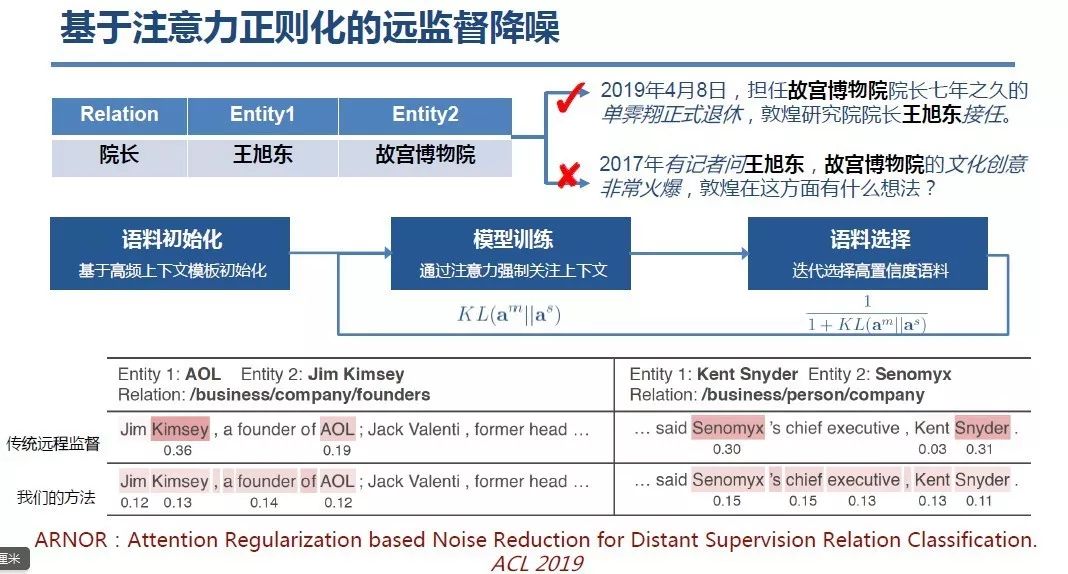
8 月 24 日至 27 日在杭州召开的 2019 年全国知识图谱与语义计算大会(CCKS 2019)上,百度 CTO 王海峰发表了题为《知识图谱与语义理解》的演讲。
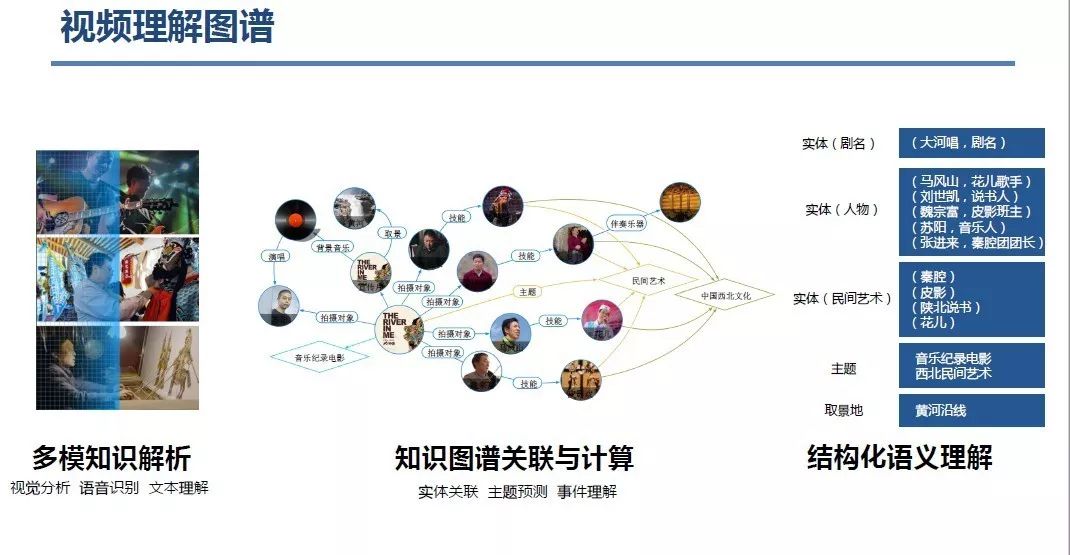
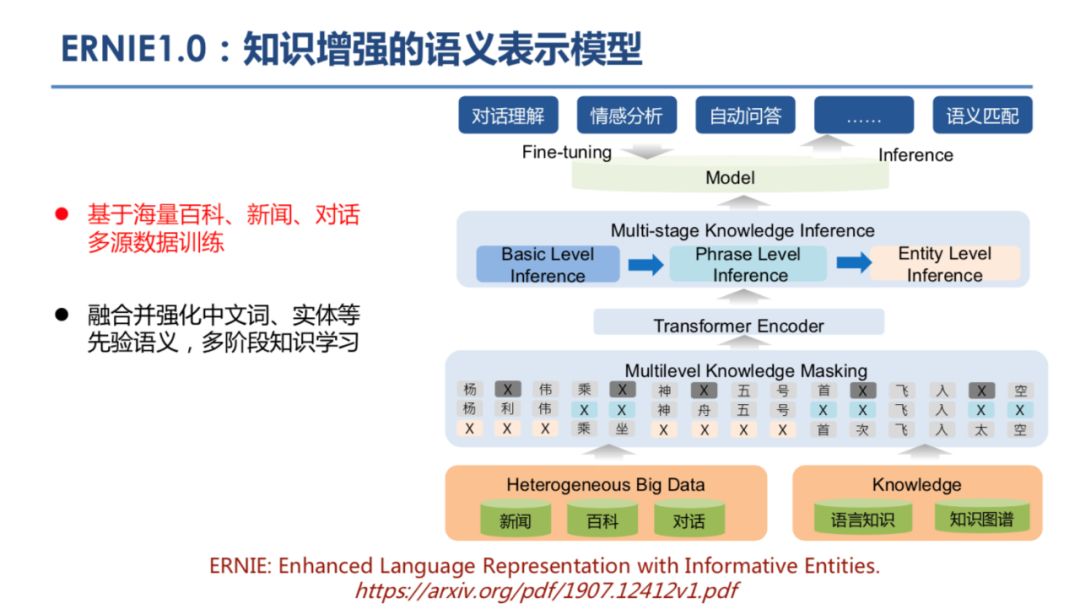
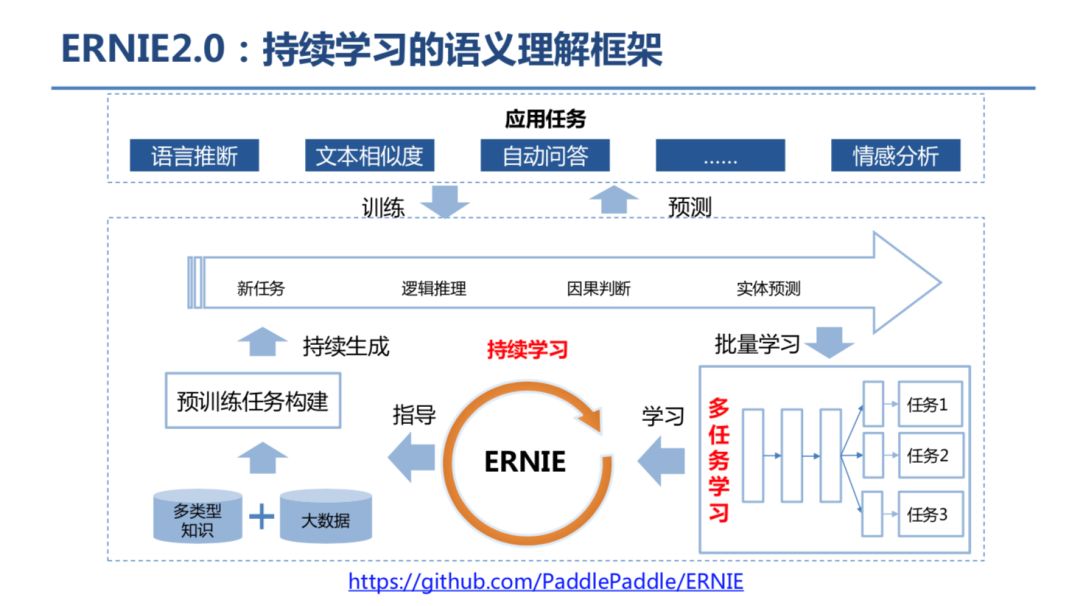
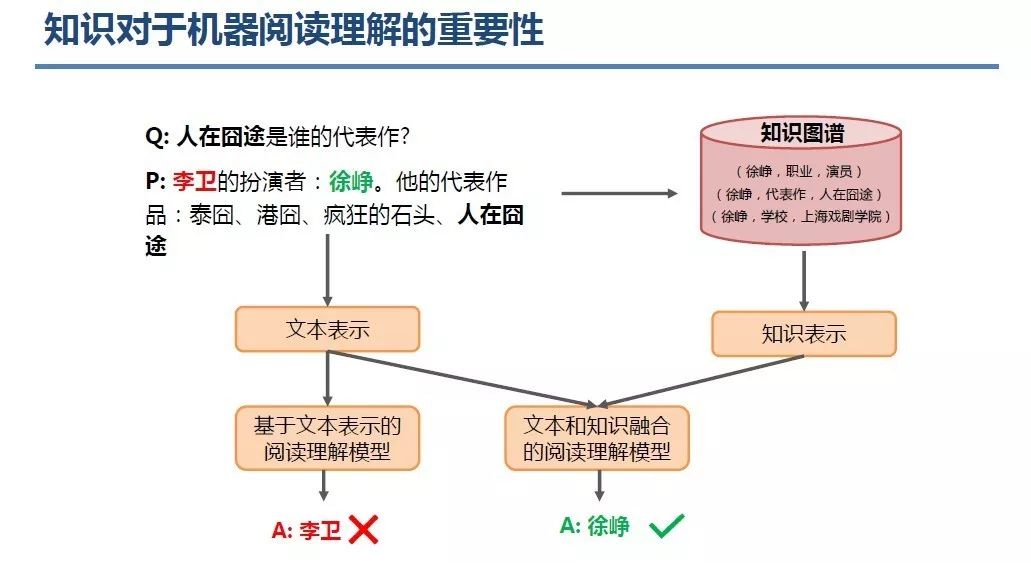
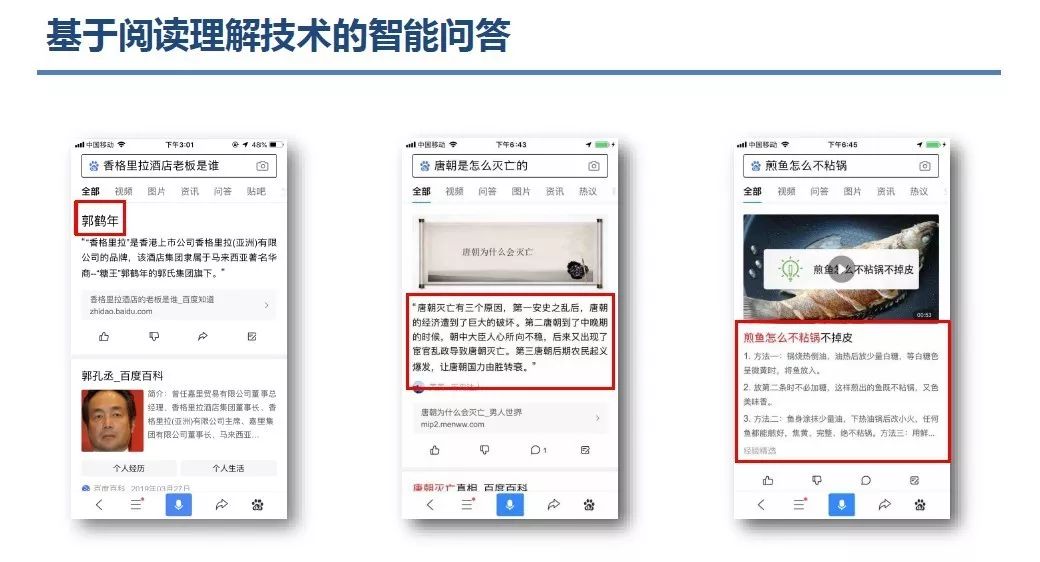
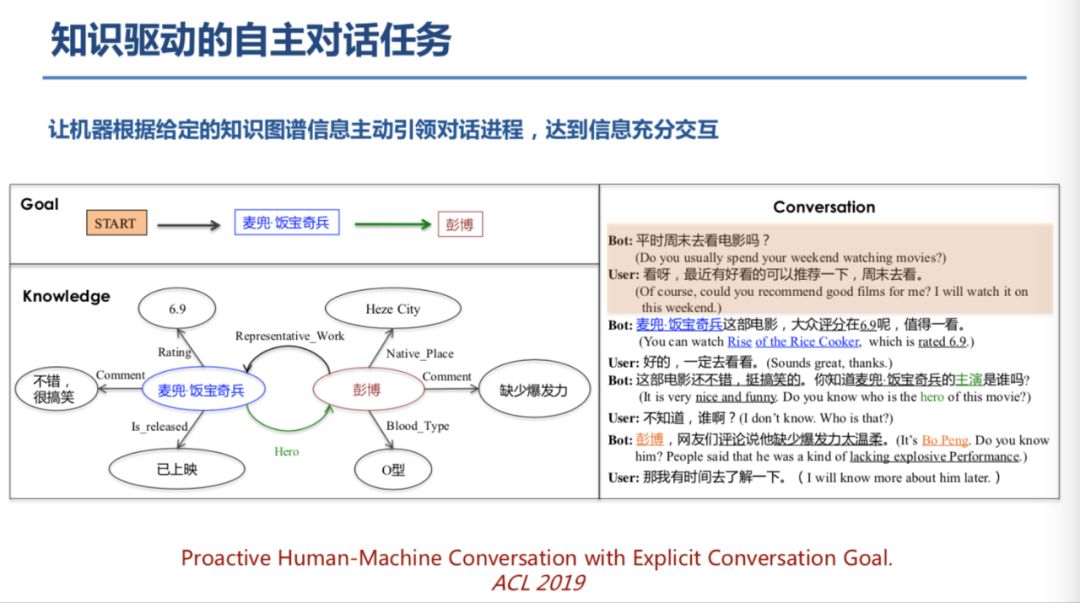
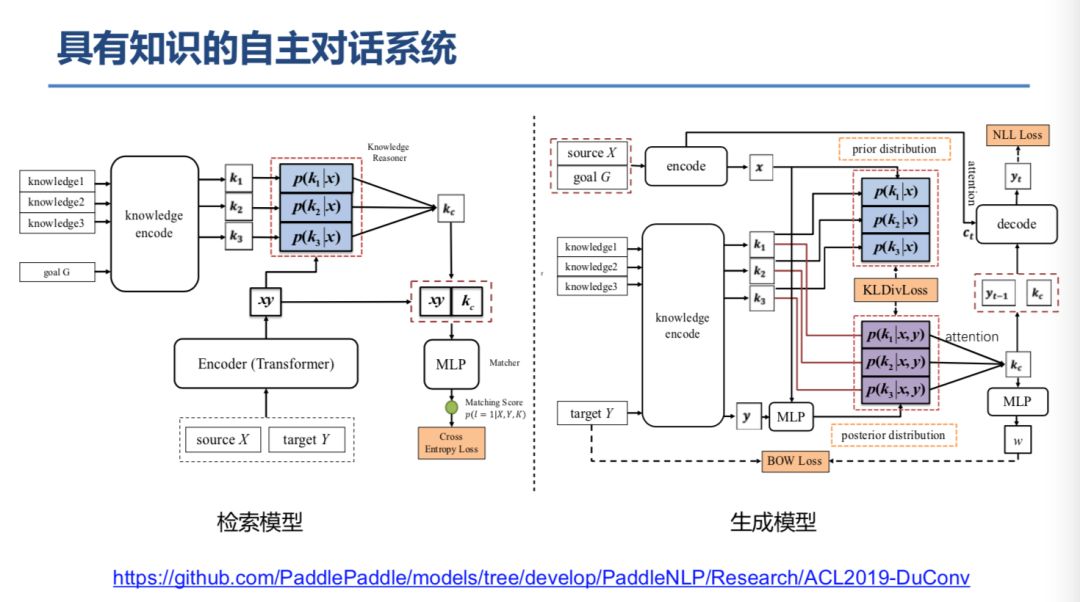
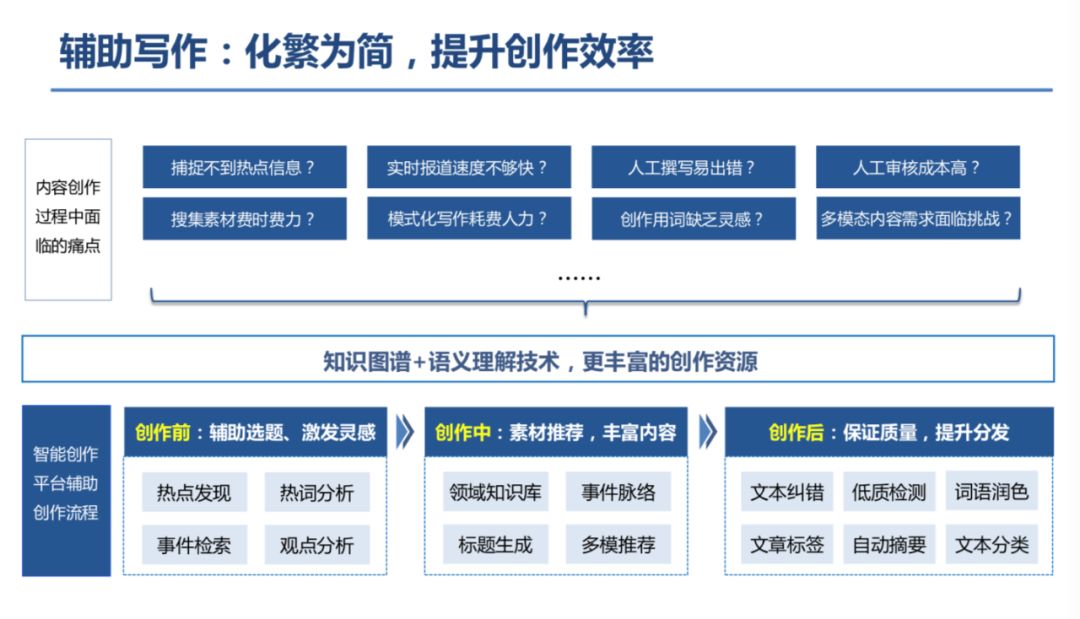

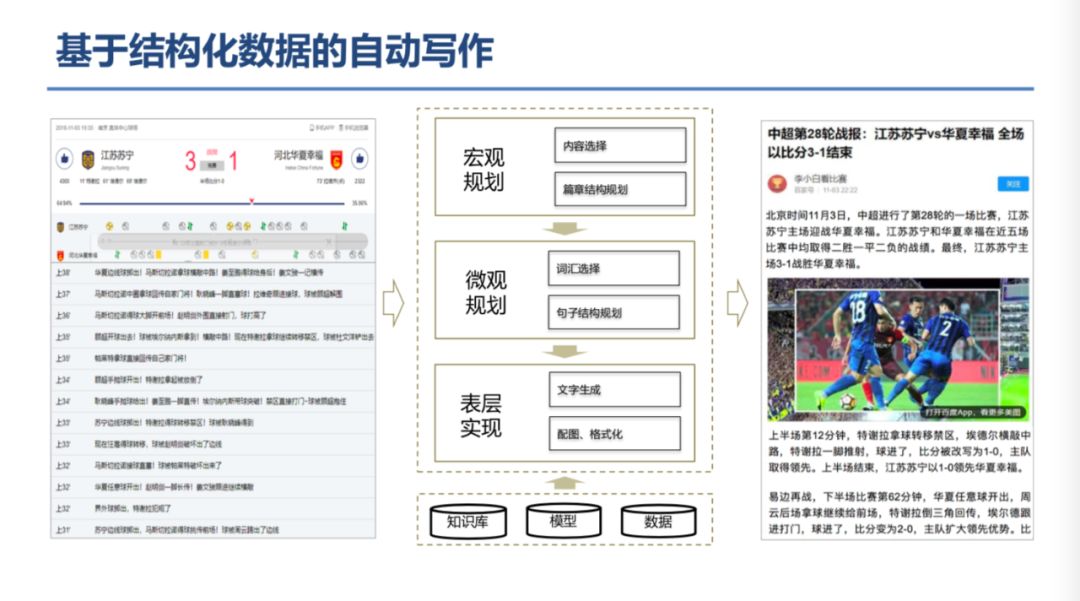
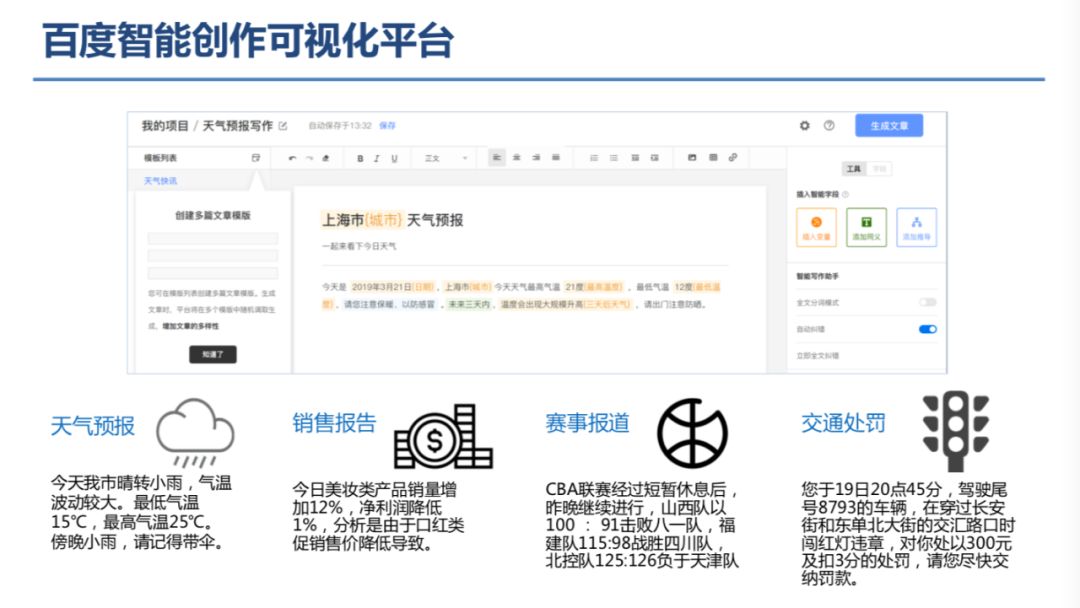
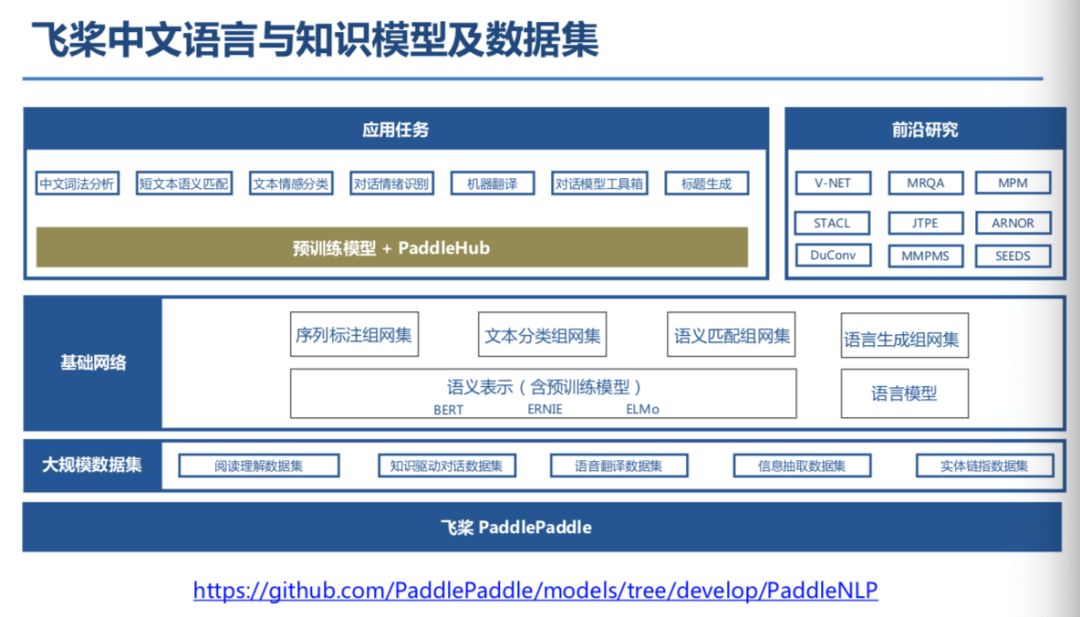
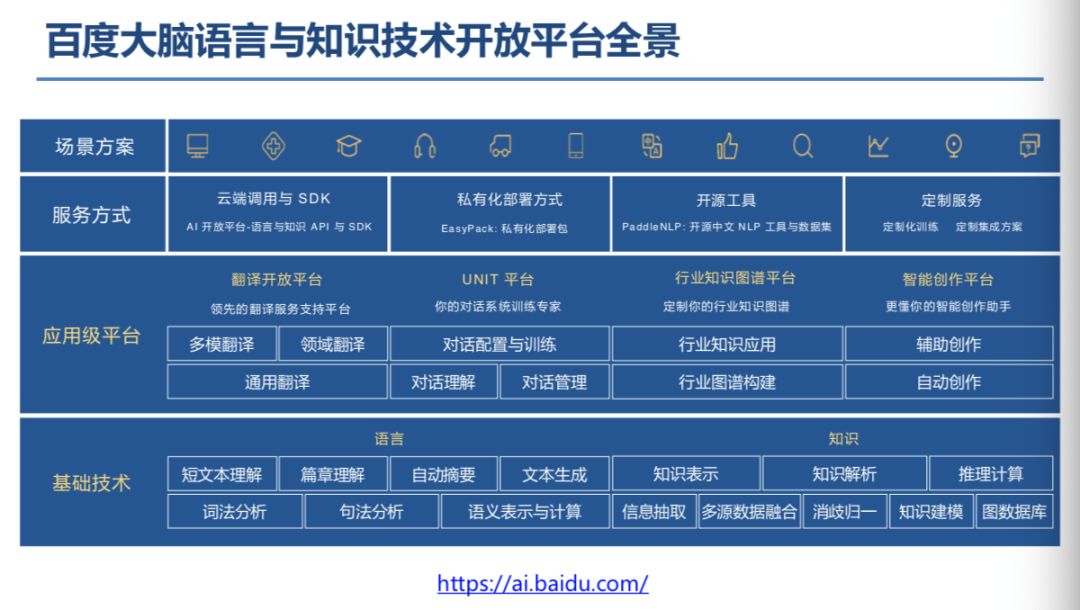
登录查看更多
相关内容

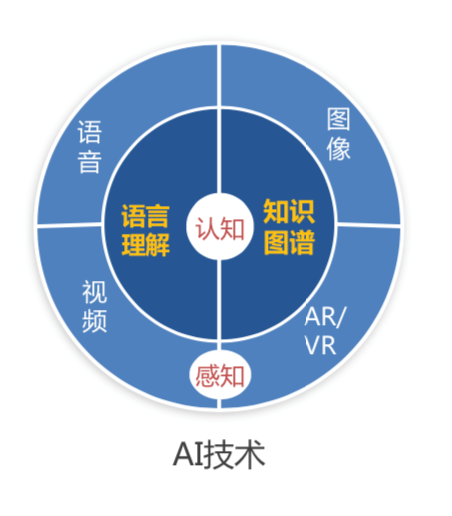
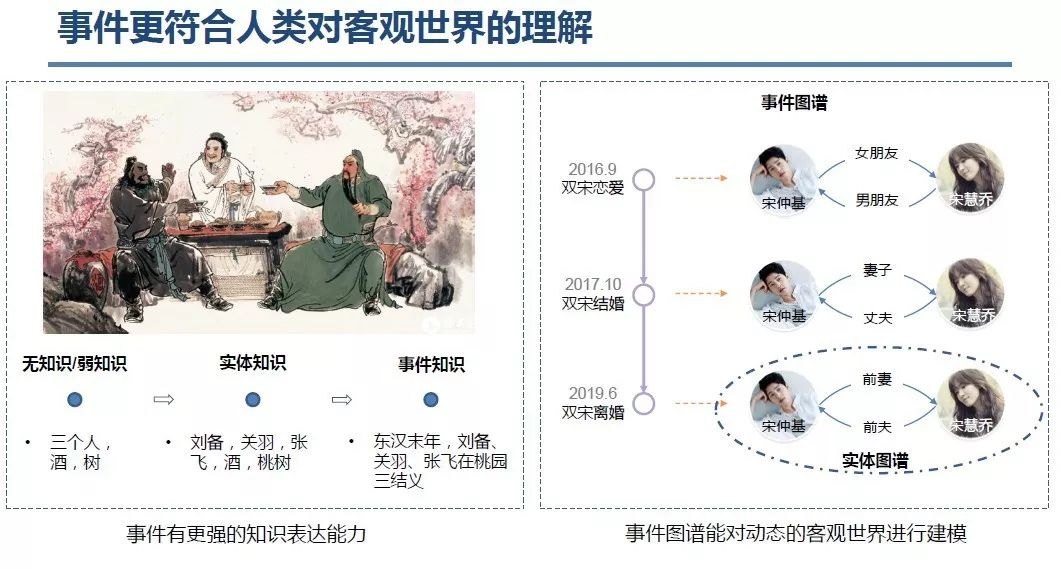
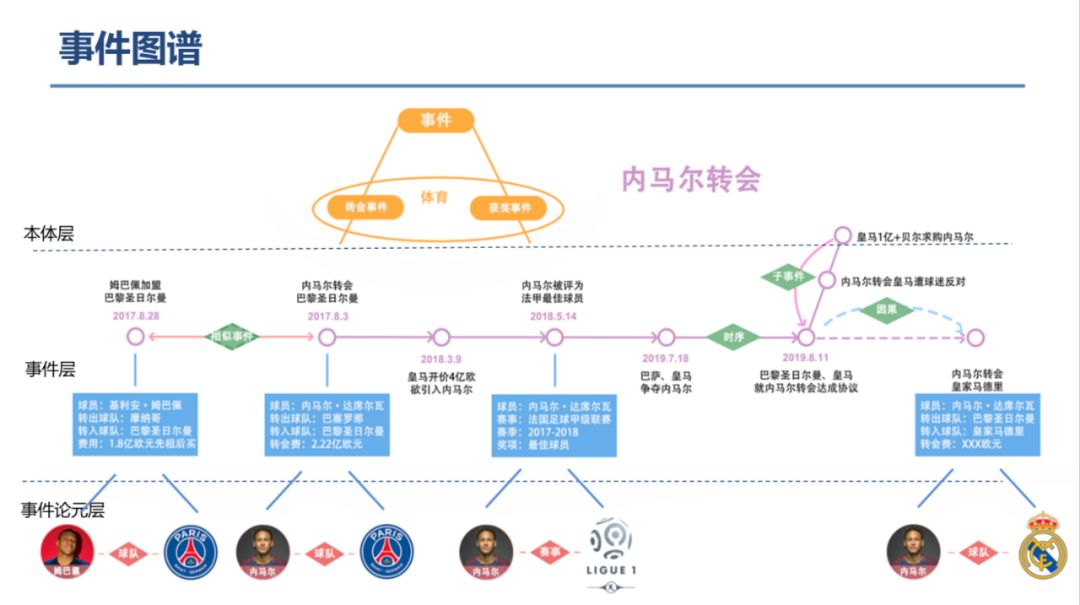
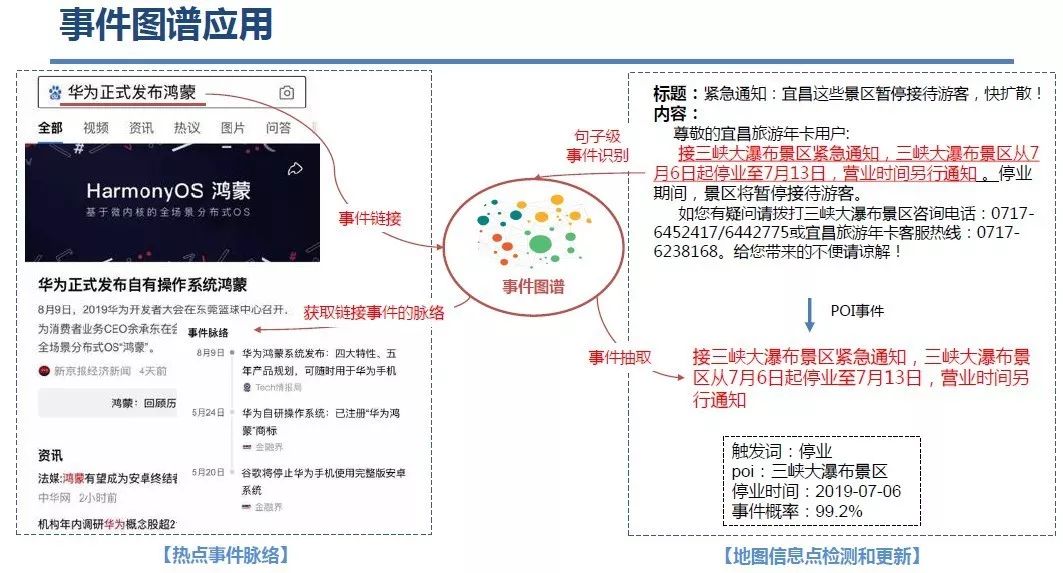
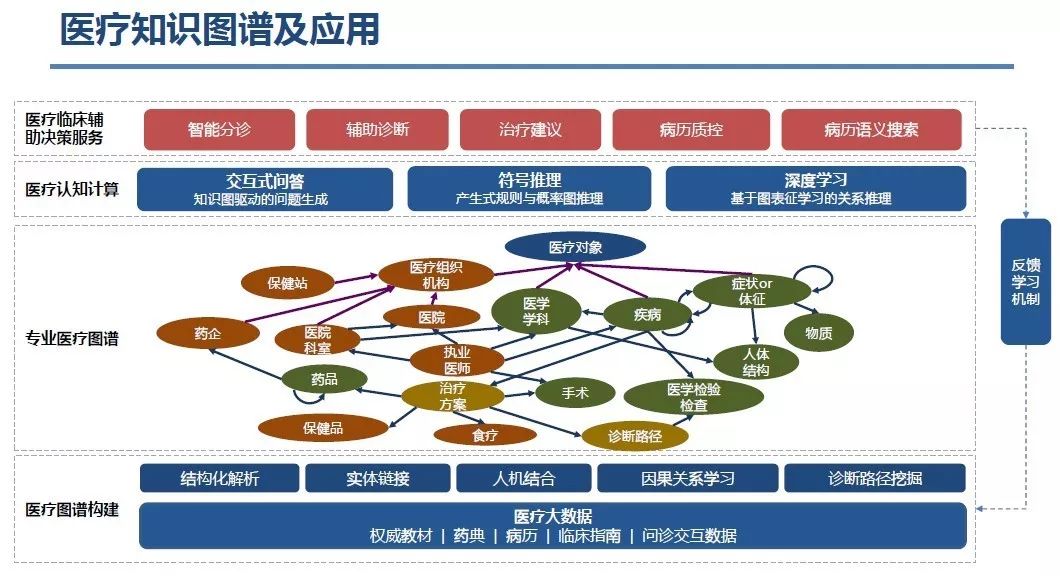
知识图谱(Knowledge Graph),在图书情报界称为知识域可视化或知识领域映射地图,是显示知识发展进程与结构关系的一系列各种不同的图形,用可视化技术描述知识资源及其载体,挖掘、分析、构建、绘制和显示知识及它们之间的相互联系。
知识图谱是通过将应用数学、图形学、信息可视化技术、信息科学等学科的理论与方法与计量学引文分析、共现分析等方法结合,并利用可视化的图谱形象地展示学科的核心结构、发展历史、前沿领域以及整体知识架构达到多学科融合目的的现代理论。它能为学科研究提供切实的、有价值的参考。
UniViLM: A Unified Video and Language Pre-Training Model for Multimodal Understanding and Generation
Arxiv
19+阅读 · 2020年2月15日
Arxiv
5+阅读 · 2017年12月7日





相关VIP内容
相关资讯
相关论文
UniViLM: A Unified Video and Language Pre-Training Model for Multimodal Understanding and Generation
Arxiv
19+阅读 · 2020年2月15日
Arxiv
5+阅读 · 2017年12月7日