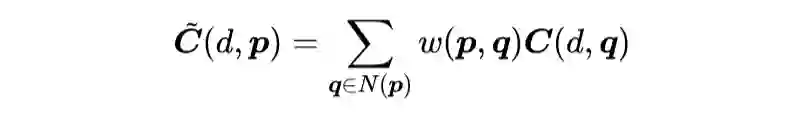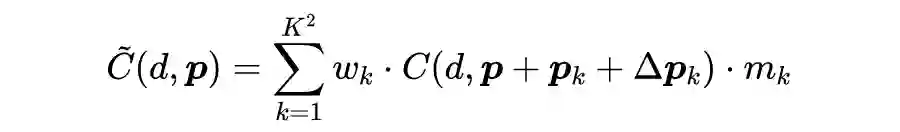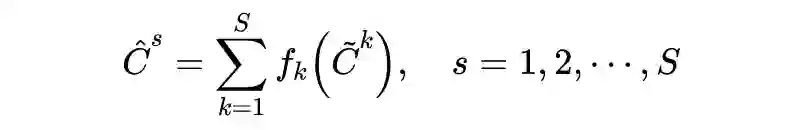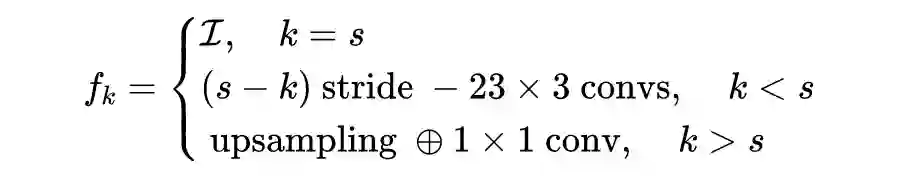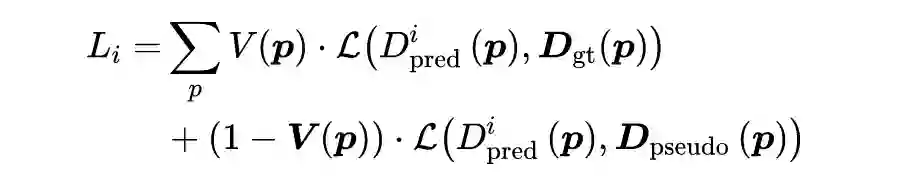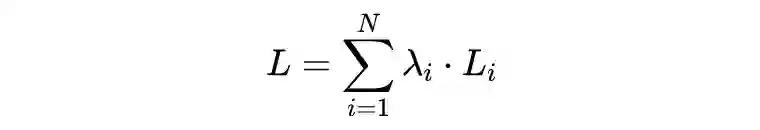©PaperWeekly 原创 · 作者|张承灏
单位|中科院自动化所硕士生
研究方向|双目深度估计
本文介绍的是中科大团队在 CVPR 2020 上提出的一种高效立体匹配网络——自适应聚合网络 AANet,它由两个模块组成:同尺度聚合模块(ISA)和跨尺度聚合模块(CSA)。AANet 可用来代替基于匹配代价体(cost volume)的 3D 卷积,在加快推理速度的同时保持较高的准确率。
论文标题: AANet: Adaptive Aggregation Network for Efficient Stereo Matching
论文地址: https://arxiv.org/abs/2004.09548v1
开源代码: https://github.com/haofeixu/aanet
Introduction
在基于深度学习的立体匹配方法中,以 GC-Net
[1]
为代表的基于 3D 卷积的方法逐渐成为主流,它是由左右图的特征经过 cancat 得到一个 4D 的 cost volume,之后利用 3D 卷积进行代价聚合得到最终的视差图。
近两年来以此框架为基础的模型在 KITTI 等数据集上成为新的 state-of-the-art,例如 PSMNet
[2]
,GA-Net
[3]
等。
这些方法估计的视差虽然准确率高,但是存在两个参数量和内存占用量高的地方,
cost volume 是一个 H×W×D×C 的 4D 张量,具有较高的参数量;
利用 3D 卷积进行代价聚合,计算量较大;
AANet 主要用来解决上述两个方面,从而提升深度立体匹配网络的效率。
Methods
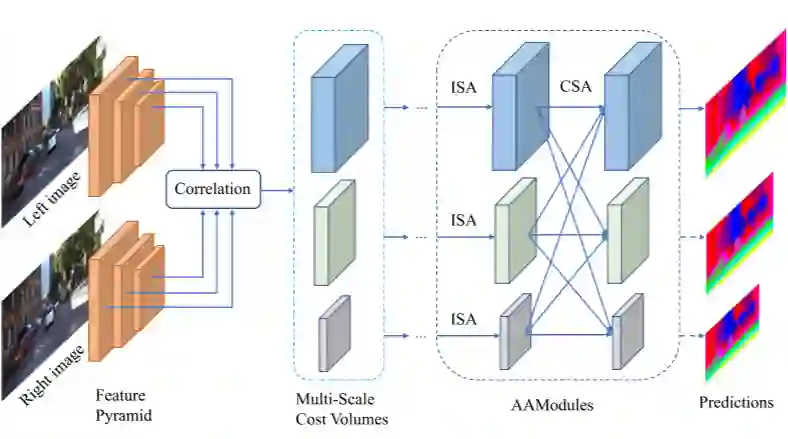
上图是 AANet 的整体框架图。给定一对双目图像,首先通过共享特征金字塔网络(类似 ResNet+FPN)提取 1/3,1/6 和 1/12 分辨率的特征,之后对三种分辨率的左右图特征分别经过correlation操作,得到多尺度的 3D 匹配代价。
接着经过 6 个堆叠的 AAModules 进行代价聚合,最后利用 soft argmin 操作回归视差图。AANet 可以得到三个尺度的输出,在上采样为原图尺度时还采样了 StereoDRNet
[4]
中的精修模块。
这里,AAModules 由 3 个同尺度聚合模块(ISA)和一个跨尺度聚合模块(CSA)组成,下面重点介绍这两个模块。
2.1 Adaptive Intra-Scale Aggregation (ISA)
同尺度聚合指的是只对相同分辨率的 cost volume 进代价聚合,来源于传统立体匹配方法中的局部代价聚合:
其中
是在像素点 q 处,视差为 d 的经过聚合的匹配代价,像素点 q 属于p点的邻接像素点;
而
是在像素点 q 处,视差为 d 的原始匹配代价,
是聚合权重。
传统的局部代价聚合不能处理视差不连续的情况,容易造成物体边缘和细微结构的粗大边缘问题(edge-fattening)。尽管基于深度学习的方法能够自动地学习权重 w,但是它们也还是采用固定窗口的规则卷积,并不能自适应地进行特征采样。
为了解决上述问题,作者提出采用基于稀疏点的特征表示能够更高效地进行代价聚合,并借鉴可变形卷积来改进代价聚合,提出了自适应的同尺度聚合模块(ISA):
其中
是聚合后的代价,
是采样点的数量(K=3),
是第 k 个点的聚合权重,
是像素点的固定偏置,而
是学习的附加正则化偏置。
类似可变形卷积的调制机制,用来调整聚合权重
。
和
可以由单独的卷积层实现,整个 ISA 模块由 3 个卷积和一个残差模块组成,类似 ResNet 中的 bottlemneck,三层分别是 1×1,3×3 和 1×1,其中 3×3 是可变形卷积。
上图是两个区域(绿色)的采样点(红色)分布情况,(a)在边缘处采样集中在相似的视差区域,(b)在大块无纹理区域,采样点成散落状分布。这表明了自适应聚合的优势。
2.2 Adaptive Cross-Scale Aggregation(CSA)
对于无纹理或者弱纹理区域,利用下采样得到的粗糙尺度更能提取具有判别性的特征,但是对于一些细节特征,又需要较高分辨率的视差预测,因此多尺度聚合是一种常用的聚合方法。
其中
S 是经过跨尺度聚合后的 cost volume,而
是在第 k 个尺度经过 ISA 聚合后的 cost volume,
是使得 cost volume 能够自适应地在多个尺度聚合的通用函数表示形式。
作者将
以 HRNet
[5]
的形式实现(HRNet 是用于姿态估计的模型),其具体构成为:
其中
表示恒等映射函数,
用来和
下采样分辨率保持一致,而
表示双线性上采样到相同分辨率,之后接 1×1 卷积对齐特征通道。
这一整套构成了 CAS 模块,具体的可视化连接方式可以参考 HRNet,简单来说是每个尺度特征都收到来自其他各层的特征,并统一到该层的分辨率融合。
2.3 Loss Function
和以往直接采用预测视差和视差 GT 作 smooth L1 loss 不同,作者认为像 KITTI 这样的数据集只提供了稀疏的标签,可以使用已经训练好的模型先进行伪标签标注,从而得到密集的标签信息,用来弥补真实标签没有标注的地方。
作者采用 GA-Net 进行伪标签标注,第 i 层的损失函数为:
其中
为第 i 层的视差输出,
为 ground truth 视差,
为 GA-Net 标注的伪标签,
是一个二值掩码,用来标记有效像素点。
即 GT 标注的视差用 GT,GT 没有标注的视差用伪标签。
Experiments
作者采用了 KITTI 2012、KITTI 2015 和 SceneFlow 数据集进行实验。
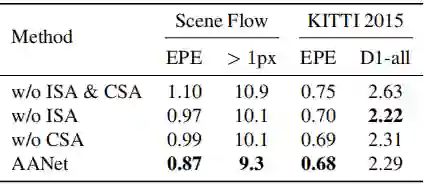
3.1 Ablation Study
首先作者做了消融分析,验证 ISA 和 CSA 模块的有效性。
由上表可以看出,结合了 ISA 和 CSA 的 AANet 在两个数据集上表现最佳。
从上图的定性可视化看,在弱纹理区域能够得到更锐化和细致的结果。
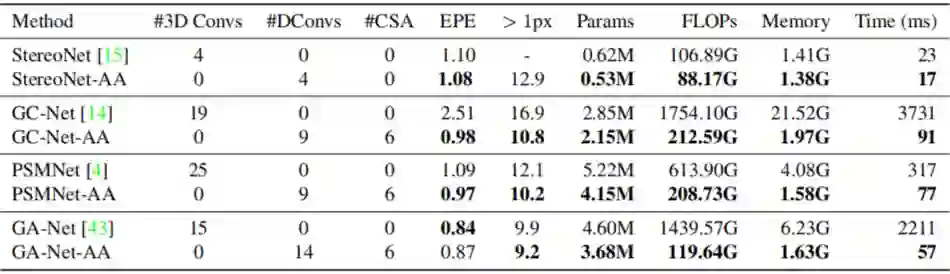
3.2 Comparison with 3D Convolutions
作者和有代表性的 4 个模型进行了比较,其他 4 个模型都采用了 3D 卷积。将这 4 个模型的 backbone 换成一样,再将 3D 卷积换成 AANet 的 ISA 和 CSA 模块,构成 XX-AA 模型。
从上表结果可以看出,除了 GA-Net,其他具备 AANet 模块的模型准确率都高一些。并且从参数量,计算量和内存占用量以及运行时间上都有降低,可见 AANet 的确让立体匹配更加高效。
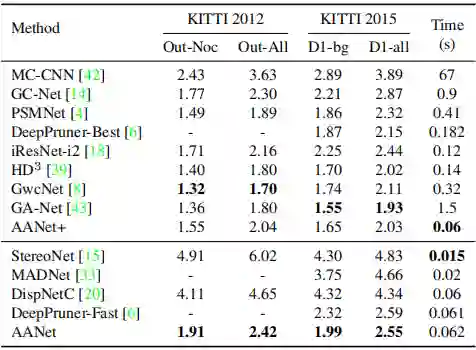
3.3 Benchmark Results
上表是在 KITTI 2012 和 KITTI 2015 上的结果,相比于精度高的模型,AANet 速度最快;相比于速度快的模型,AANet 精度最高,是一个不错的 trade-off。
Conclusion
3D 卷积的确是基于 cost volume 立体匹配方法的痛点,想要让立体匹配更高效,少用或者不用 3D 卷积是一个很好的解决思路。从立体匹配提速角度看,之后的研究可以从如何替代 3D 卷积,或者如何减少 3D 卷积的入手。
从其他相似领域角度看,如何将这种思路应用到高分辨率立体匹配,多视角立体视觉(MVS),光流估计,基于双目的 3D 检测等领域。
参考文献
[1] Alex Kendall, Hayk Martirosyan, Saumitro Dasgupta, Peter Henry, Ryan Kennedy, Abraham Bachrach, and Adam Bry. End-to-end learning of geometry and context for deep stereo regression. In CVPR 2017.
[2] Jia-Ren Chang and Yong-Sheng Chen. Pyramid stereo matching network. In CVPR 2018.
[3] Feihu Zhang, Victor Prisacariu, Ruigang Yang, and Philip HS Torr. Ga-net: Guided aggregation net for end-to-end stereo matching. In CVPR 2019.
[4] Rohan Chabra, Julian Straub, Christopher Sweeney, Richard Newcombe, and Henry Fuchs. Stereodrnet: Dilated residual stereonet. In CVPR 2019.
[5] Ke Sun, Bin Xiao, Dong Liu, and Jingdong Wang. Deep high-resolution representation learning for human pose estimation. In CVPR 2019.
点击以下标题查看更多往期内容:
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读 ,也可以是学习心得 或技术干货 。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品 ,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱: hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」 也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」 订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」 ,小助手将把你带入 PaperWeekly 的交流群里。