技术动态 | 清华大学开源OpenKE:知识表示学习平台
本文转载自公众号机器之心,选自 THUNLP。
清华大学自然语言处理实验室近日发布了 OpenKE 平台,整合了 TransE、TransH、TransR、TransD、RESCAL、DistMult、HolE、ComplEx 等算法的统一接口高效实现,以及面向 WikiData 和 Freebase 预训练知识表示模型。该项目旨在为开发者与研究人员提供便利。
项目链接:http://openke.thunlp.org
GitHub:https://github.com/thunlp/OpenKE
OpenKE 是一个开源的知识表示学习平台,由 THUNLP 基于 TensorFlow 工具包开发。在 OpenKE 中,我们提供了快速和稳定的工具包,包括最流行的知识表示学习(knowledge representation learning,KRL)方法。该框架具有容易拓展和便于设计新的知识表示学习模型的特点。
该框架有如下特征:
拥有配置多种训练环境和经典模型的简易接口;
对高性能 GPU 训练进行加速和内存优化;
高效轻量级的 C++实现,用于快速部署和多线程加速;
现有大规模知识图谱的预训练嵌入,可用于多种相关任务;
长期维护以修复 bug,满足新需求。
基准测试
一些数据集如 FB15K、FB13、WN18 和 WN11 通常用于知识表示学习的基准测试。我们以 FB15K 和为 WN18 为例介绍我们的框架的输入文件的格式。
数据集有以下五种格式:
train.txt:训练文件,每行以 (e1, e2, rel) 格式书写,第一行是三元组的数量;
valid.txt:验证文件,和 train.txt 格式一样;
test.txt:测试文件,和 train.txt 格式一样;
entity.txt:所有的实体和对应的 id,每行一个实体及其 id;
relation2id.txt:所有的关系和对应的 id,每行一个关系及其 id。
还可以从以下地址下载原始数据:
FB15K、WN18:https://everest.hds.utc.fr/doku.php?id=en:transe
相关论文:Translating Embeddings for Modeling Multi-relational Data(2013)
FB13、WN11:http://cs.stanford.edu/~danqi/data/nips13-dataset.tar.bz2
相关论文:Reasoning With Neural Tensor Networks for Knowledge Base Completion
工具包
我们提供了多个知识表示学习的工具包,包括以下四个资源库:
OpenKE
这是一个基于 TensorFlow 的知识表示学习(KRL)的高效实现。我们使用 C++实现了一些基础操作,如数据预处理和负采样。每一个特定的模型都用 TensorFlow 和 Python 接口实现,因此能方便地在 GPU 上运行模型。
OpenKE 提供了训练和测试多种 KRL 模型的简易接口,无需在冗余数据处理和内存控制上花费太多功夫。OpenKE 实现了一些经典和高效的模型用于支持知识表示学习,这些模型包括:
TransE
http://papers.nips.cc/paper/5071-translating-embeddings-for-modeling-multi-relational-data.pdf
TransH
https://www.aaai.org/ocs/index.php/AAAI/AAAI14/paper/viewFile/8531/8546
TransR
https://www.aaai.org/ocs/index.php/AAAI/AAAI15/paper/viewFile/9571/9523/
TransD
http://anthology.aclweb.org/P/P15/P15-1067.pdf
RESCAL
http://www.icml-2011.org/papers/438_icmlpaper.pdf
DistMult
https://arxiv.org/pdf/1412.6575.pdf
HolE
https://www.aaai.org/ocs/index.php/AAAI/AAAI16/paper/viewFile/12484/11828
ComplEx
http://proceedings.mlr.press/v48/trouillon16.pdf
我们提供了训练这些模型的教程:http://openke.thunlp.org/index/documentation。
此外,我们还使用一些简单的例子展示了如何基于 OpenKE 构建一个新模型。
Github 链接:https://github.com/thunlp/OpenKE
KB2E
KB2E 是一些知识嵌入模型的早期实现,我们之前的研究中使用了很多资源。这些代码将被逐渐纳入新框架 OpenKE。这是一个基础且稳定的知识图谱嵌入工具包,包括 TransE、TransH、TransR 和 PTransE。该工具包的实现遵循模型的原始文件设置,使其在研究实验中保持稳定。
GitHub 链接:https://github.com/thunlp/KB2E
Fast-TransX
这是 TransE 及其扩展模型用于知识表示学习的高效轻量级实现,包括 TransH、TransR、TransD、TranSparse 和 PTransE。整个框架的底层设计为实现加速作出改变,且该框架支持多线程训练。Fast-TransX 旨在使用 OpenKE 框架实现快速、简单的部署。
GitHub 链接:https://github.com/thunlp/Fast-TransX
TensorFlow-TransX
OpenKE 基于 TensorFlow 的简易版,包括 TransE、TransH、TransR 和 TransD。与 Fast-TransX 类似,TensorFlow-TransX 旨在避免使用 OpenKE 框架产生的复杂封装。
GitHub 链接:https://github.com/thunlp/TensorFlow-TransX
预训练嵌入
现有大规模知识图谱使用 OpenKE 对嵌入进行预训练(目前都通过 TransE 进行训练。必要时会介绍更多模型)。
知识图谱和嵌入包括以下五个文件:
实体的嵌入:知识图谱中每个实体的嵌入。数据是二进制格式,每一行有一个嵌入。每一行用大量连续浮点表示这一行的嵌入。
关系嵌入:知识图谱中每一个关系的嵌入。数据是二进制格式,每一行有一个嵌入。每一行用大量连续浮点表示这一行的嵌入。
Triple2id:知识图谱的知识三元组与对应序列号之间的映射。每一行有一个三元组和序列号,二者用一个 tab 隔开。
Entity2id:知识图谱的实体与对应序列号之间的映射。每一行有一个实体和序列号,二者用一个 tab 隔开。
Relation2id:知识图谱的关系与对应序列号之间的映射。每一行有一个关系和序列号,二者用一个 tab 隔开。
文件描述和下载链接:
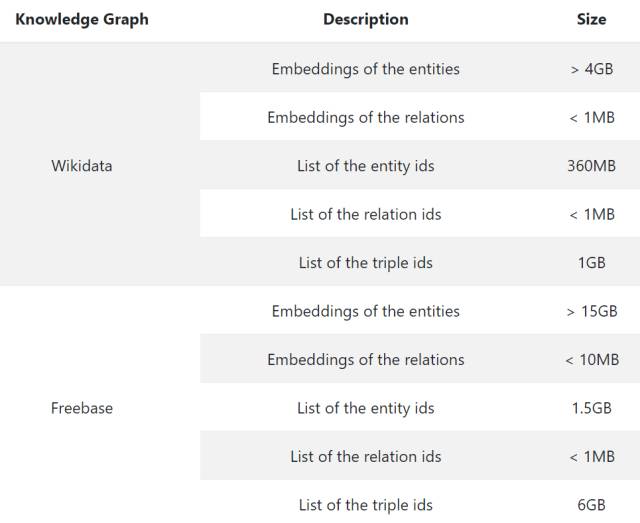
Wikidata:http://openke.thunlp.org/download/wikidata
Freebase:http://openke.thunlp.org/download/freebase
如何阅读二进制文件:
Python
#Python codes to read the binary files.
import numpy as np
vec = np.memmap(filename , dtype='float32', mode='r')
C/C++
//C(C++) codes to read the binary files.
#include <cstring>
#include <cstdio>
#include <cstdlib>
#include <sys/mman.h>
#include <fcntl.h>
#include <unistd.h>
#include <sys/stat.h>
struct stat statbuf;
int fd;
float* vec;
int main() {
if(stat(filename, &statbuf)!=-1) {
fd = open("relation2vec.bin", O_RDONLY);
vec = (float*)mmap(NULL, statbuf.st_size, PROT_READ, MAP_PRIVATE, fd, 0);
}
return 0;
}
本文为机器之心编译,转载请联系机器之心公众号获得授权。
OpenKG.CN
中文开放知识图谱(简称OpenKG.CN)旨在促进中文知识图谱数据的开放与互联,促进知识图谱和语义技术的普及和广泛应用。

点击阅读原文,进入 OpenKG 博客。


