自然语言处理领军人刘兵:没有终身学习,机器不可能智能 | 新智元专访
新智元原创
作者:闻菲
【新智元导读】在深度学习推动图像、语音快速向前的今天,自然语言处理依然有很多问题。新智元日前对 ACM、AAAI & IEEE 三院会士(Fellow)、伊利诺伊大学计算机科学教授刘兵进行了专访。刘兵认为当前的自然语言处理要取得突破,需要研究范式的改变,还需要将语言、图像、视频和语音等不同模式的数据相结合。刘兵现在研究的终身机器学习能将知识积累下来,他相信终身学习是 AI 和机器学习的一个必要步骤,没有它,机器不太可能有真正的智能。

将一块石子投向水中会发生什么?
这个问题对人而言简单,对计算机却很难,因为答案有太多——可能是溅起水花,激起波纹,也可能惊动水中的鱼,击中池边的花……还可能是上面所有这些乃至更多。因此,计算机无无法作答。
“语言是不精确的,字面意思背后还有太多太多。”美国伊利诺伊大学芝加哥分校的计算机科学教授刘兵说。这也是为什么相较有着一对一表征的图像和语音,自然语言处理是一个如此艰巨的问题。
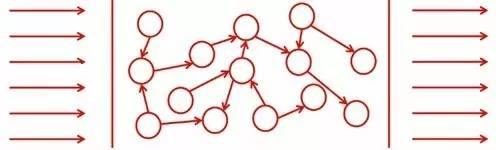
人类理解语言是将左边的感受(sensation)转化为右边的行动(action),而中间有一个表征。自然语言与图像和语音不同的地方在于,中间表征并非一一对应。换句话说,语言是不精确的。
要让计算机理解人类的语言,现在一般有两条路。一是从形式语言入手,将文本切割为单词、标点这些没有意义的 token,把知识“硬编码”给计算机。研究者会把各种 token 组合起来手动地创造表征(representation),然后为这些表征赋予意义并使用它们构建模型。另一方面,也有人从神经网络或深度学习的角度入手,让计算机“学习”文本。在这条路上,词汇被表示为一个个的向量(word2vec),这些向量再进一步表示句子,然后回答问题。要走完这条路,研究人员必须开发算法,让计算机能像人一样学习语言。
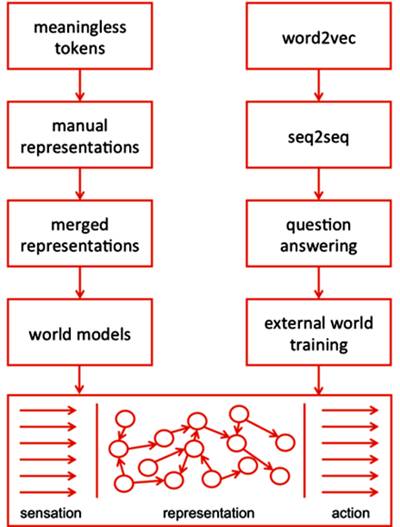
但是,刘兵认为光有这些还不够,当前的自然语言处理要取得突破,需要研究范式的改变,还需要将语言、图像、视频和语音等不同模式的数据相结合。他很怀疑现在的深度学习——用不断的函数逼近能得出真正的智能。
刘兵是 ACM、AAAI & IEEE 的会士(Fellow)。尽管对应用和研究都感兴趣,但为了能自由创新,自 2002 年进入伊利诺伊大学芝加哥分校以来,刘兵一直留校任教至今。他最著名的是对情感分析(或叫观点挖掘)和揭示虚假观点的研究。刘兵在 Web 数据提取和数据挖掘方面卓有建树,2013 年当选为 ACM 数据挖掘特别兴趣组 SIGKDD 主席。他在 KDD-1998 和 KDD-2004 发表的两篇论文分别在 2014 年和 2015 年获得了 KDD 经典奖(Test-of-Time award)。
日前,来北京对北京大数据研究院自然语言处理与认知智能实验室进行交流访问的刘兵接受了新智元专访,就深度学习、自然语言处理发展以及如何做好原创性研究分享了他的看法。7 月 23 日,刘兵将作为特邀讲者,出席中国计算机学会和中国中文信息学会共同主办的第二届“语言与智能高峰论坛”,发表演讲《让自然语言处理更上一层楼:终身机器学习》。
新智元:您认为接下来自然语言处理最大的突破可能来自哪里?
刘兵:在应用方面的发展应该都不错,比如机器翻译、知识抽取、观点分析、人机对话……都可能会有很大的进展。但是,要做到理解那一步,还差得很远。因为自然语言与计算机视觉和语音不同,视觉和语音还是一对一的映射,这是什么,我讲的是什么,说那几个字找出来就好。自然语言不止是字面上的几个字,后面还有很多东西,你可以对一句话产生很多联想。
我曾经举过例子,我丢一块石头到水里,那有波浪、有溅起的浪花、水什么颜色、池塘的风貌、有没有鱼在水中跳……你可以想象很多东西,而自然语言就那么一句话——“我丢了一块石头到水里”。你问计算机的话,计算机怎么回答?现在的自然语言对机器而言就是硬猜,通过字的多少,通过统计规律等等来反推,就像“中文房间”那样。所以,我认为自然语言要突破,用现在的方法还早,我认为需要范式上的改变。
新智元:您能举一个自然语言最近范式转变的例子吗,因为这一技术或方法的出现,领域得到重大进展?
刘兵:我认为 Word to Vector 起了很大的作用,把表征转换为相关性。深度学习对自然语言的效果没有图像、语音好,这有很多原因,但 Word2Vect 的出现让领域有了明显的进步。
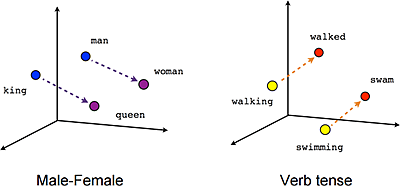
Word2vec 2013 年由 Tomas Mikolov 在谷歌率领团队提出(Mikolov 在 2014 年去了 Facebook),是一种对单词的向量表征进行运算的方法,能将文本转换为深度神经网络能够理解的数值形式。Word2vec 接收文本语料做输入,输出则是一组向量,这种向量通常有几百个维度,构成一个向量空间。在这个空间里,每个词都有一个对应的向量。其中,语义相近的词会在分布上彼此靠近,形成一个个“词簇”(word cluster)。 Word2vec 使用分布式的数值形式对词向量进行表征。分布式表征这一概念最早由 Hinton 在 1986 年提出,其基本思想是通过训练,将每个词映射为 K 维实数向量(K 为模型中的超参数),通过词之间的距离判断其在语义上的相似度。使用这种方法,就能捕捉单词之间在多个不同维度上的相似度。 Word2vec 不需要标签来创造有意义的表征。这一点很关键,因为真实世界的数据也都没有标签。当训练数据足够多(常常高达几十上百亿单词)时,Word2vec 能对词的意义进行高度准确的预测,并且得出一些非常有趣的结果。一个著名的例子是“国王-男人+女人=女王”。 这样的预测结果可以用于建立一个词与其他词之间的联系,或者将文档聚类并按主题分类。这些聚类结果是搜索、情感分析和推荐算法的基础,广泛应用于科研、调查取证、电子商务、客户关系管理等领域。Word2vec 的应用不止于解析自然语言,还可以用于基因组、代码、社交媒体图像等其他语言或符号序列,同样能够有效识别其中存在的模式。因为这些数据都处于与词语相似的离散状。 |
新智元:您怎么看自然语言领域深度学习和语言学的对立?
刘兵:自然语言离不开语言学,不过,人学语言学跟机器学的还不一样。人学习语言是从很小的单元学起来的,爸爸、妈妈……不是从一整句话或者一篇长文来学,有一个课程(curriculum)一样的东西,从简单到复杂。现在机器学习的办法就是输入整个对话、整篇文章,然后让计算机自己猜去。
自然语言处理,我倒不认为一定需要做语义的人来做,我自己有过一些经验,做纯语言学的人,他们做的东西还是让人去理解,所以对机器来说,他们的帮助很小,他们的发现无法“运算化”(operationalize)。
新智元:有一个笑话说,做机器翻译,每开除一个语言学家,正确率就上升百分之几。
刘兵:这可能有点过分(笑)。不过,语言学家对计算机的帮助确实不是特别大。这个问题可能需要重新考虑,因为人的语言学跟机器的语言学是不一样的。而且,人类的语言学讲的,归类呀分析啊,是假设你懂这门语言。但是现在的计算语言学就是从计算机的角度,以机器为中心来考虑语言学。
而且,光是语言学还不够——语言学还是讲语义,而语义是有很多东西在后面的。比如说人,你看不见、听不见,只能触摸的话,能知道多少?人活在世界上,随时都在看在听,在同时接收多种信息并且得到反馈,所以能够学到很多东西。计算机也需要这样反馈的系统。
新智元:结合图像、语音等不同模式的数据对自然语言处理会带来什么好处呢?
刘兵:自然语言处理的不纯粹是语言的问题。语言可能还要与视觉、听觉这些连在一起,让机器能够了解世界,至少有一个场景在里面,imagining something happened。语言没办法形容世界的所有,我们描述事情的时候,都有一个焦点(focus)。好比开车,我开车时并不需要知道世界的所有,盯住前面的红灯或看旁边有没有人就行了。但是,当我转换焦点,我就能描述其他事物,比如开车时路过的商店,我当时没注意。这样,就能给出一个比较全面的 representation,同时也能保证 focus。
还有,在现实生活中,我们沟通时往往只需要很少的信息,有大量的内容都是不会说出来的。你看电影台词,演员的对话,文字是很简洁乃至很单调,但配合上语气、演员的表情和背景音乐,我们立马就能感受到不同。要让机器学会与人交流,是不是也该将机器置于与人类类似的环境里?未来自然语言处理也需要融合图像、语音、视频等不同模式的数据。
新智元:现在学术顶会企业的参与越来越多。一个原因是很多研究都需要用到大的计算力,往往只有企业才能提供。您认为不在企业如何做好深度学习研究?
刘兵:企业参与多的现象一直有。这有两方面的原因,除了计算力,还有数据。人工智能不是简单的算法,还是需要大量的数据,人类学习也是这样,要整天看,整天读,整天听。没有大数据,智能是不可能的。这在工业界就有很大的优势。当然,计算力也一样。我目前还没有作需要那么大运算量的研究,但拘束仍然很明显——现在写文章需要早早做准备,[模型]一算就是好几天,不知道结果,发现不对还得重新修改。计算是个很大的问题。不过,像谷歌这样的公司还是支持很多研究的,他们也不是完全为了应用。因此,和工业界合作是一个好的办法。尤其是数据,学术界很难产生真实的数据,所以需要和工业界合作。
另一方面,你可以往前想,不一定要用现在的方法[解决现在的问题],还有更好、更新的方法。学术界本来就以前瞻、创新著称。举个例子,我现在正在做的终身机器学习,就不需要那么大的数据。终身机器学习的概念是,每次遇到的东西,不同领域的不同任务,学到的都可以慢慢地积累。这样,再遇到新的情况,就不需要那么多新的数据。好比人认识手机,不需要看一万个,看两三个就知道“手机”是什么了,因为我们以前见过手机的大部分功能和形状。这是一个解决办法。
新智元:您能具体介绍一下终身学习吗?
刘兵:现在,神经网络也好,其他算法也罢,实际上任何东西都记不住事情,都是在孤立地学习。现在的迁移学习也还不是连续的。现在的模型还无法积累信息,每当遇到一个新的问题都需要重头开始学习。我们想做的是像人类那样,让机器可以一直不停地学习。这个学习机制与现在的不同:一是要学,要记,还得能适应(adapt)——在新的情况下怎么利用你的知识;在新的情况下,不光是要用你学到的知识,还要发现新的问题,因为在真实世界你遇到的就是曾经学过的问题,这是不太可能的。
具体说,我们希望建立模型,这个模型能够识别自己该干的事情,而且还能知道那些事情是它没有见过的。如果做到了这一点,那么遇到新的东西,我们就能够接着学习。举个简单的例子,假设我要建一个机器人,在旅馆门口迎宾“say Hello”,它必须知道已经住在旅馆里的人,还要会分辨新来的人,遇见新来的人就主动问询,还可以拍照和学习……这样下次再见到,就能跟这个人说上次如何如何。
通用智能就是要发现世界,而且在工作中还可以学。例如,建立一个模型,我要发现这个模型有的地方能用,有的地方不能用,不是说世界全是这个模型 cover 了;还有,在使用的过程中发现有没有地方能提升,好比老师教了你数学,你懂了,你在做题的时候仍然是在学着的。
我相信终身学习是人工智能和机器学习的一个必要步骤。没有它,机器不太可能有真正的智能。我的博士生和我 2016 年年底写了一本书叫《终身机器学习》。如果你有兴趣,可以看一看 (https://www.cs.uic.edu/~liub/lifelong-machine-learning-draft.pdf)。
☞ 新智元相关报道:【首届北美计算机华人学者年会】伊利诺伊大学刘兵:终身机器学习(45PPT)
新智元:您认为深度学习将如何影响自然语言处理?
刘兵:深度学习是否代表了一种算法,将智能包含在了里面,我现在还不敢肯定。我倾向于认为不是。深度学习还是一种函数逼近(function approximation)和映射(mapping),基本上通过一些例子,这些例子间有些关系,我来做一下近似。我现在更关心的终身机器学习还有“适应”相关的内容,[针对]遇上了没有见过的东西我该怎么办。但深度学习自己也在发展,热度也很高,大家都在关注,我现在还不敢肯定它将来的走向。我感觉“intelligence”还不是这样的算法,[深度学习]里面有太多的参数,但怎么将知识真正充实在算法里,将来稍微做小的变化就[能解决新的问题],我不知道深度学习能不能做到这一点,我现在感觉目前的深度学习似乎还没有做到。能够积累地学习,在不忘记过去的东西的同时学习新的东西,而且要用过去学到的知识帮我学得更快更好,这就是我现在想做的研究。
新智元:您说过相比工业界,您更喜欢做研究?
刘兵:是的。在工业界有任务,要赚钱,出产品,没有那么多自由的空间,去想象,做自己的研究。这并不是说我对实际应用没兴趣——我对人工智能的应用和研究都有兴趣,只是我认为不管做什么都需要有原创性思考,提出新的、有创意的想法。如果只是纯粹的应用,比如把某个算法做成某种功能,我就没什么兴趣了。当然,如果有创意,那么研究和应用我都感兴趣。
新智元:最近 Attention 这个机制在自然语言处理中得到了很多关注。
刘兵:实际上 Attention 这个概念很早就有了,只是现在用了“注意力”这个名字更好地抓住了人的想象力。取名字这件事比你想的更重要。我举个例子,中国常说现在微信很厉害,能干这个能干那个能干很多很多……但是,没有一个抽象的概念把它形容起来是没有意义的。Joseph Nye 提出了“soft power”这个词,一下子就把这个概念概括住了。要取一个精准形象的名字,把握事情的精髓,让大家一听“啊!”非常重要,也是一个很大的贡献。我做研究生的时候,我的老师说——这么多年,我唯一记住他这句话——你需要 Abstract。不能说我能干这个干那个干这个……要能抽象、代表、概括,abstract。
新智元:作为ACM、AAAI、IEEE 会士以及多篇经典论文的作者,您对研究者做出好的研究有什么建议?
刘兵:最主要的是创新。做什么事情胆子要大,做研究一定要胆子大——又不是跳悬崖。不要怕什么东西难,不要自己觉得不行。不要跟风跟得太厉害,不要为了写下一篇文章而写文章。要弄清楚 what is the big idea you want to push,那样自然就会有文章。如果整天看别人的文章,然后看到一个地方觉得“呀,这个地方我可以改进”就去改进一下——改进是可以的,但是要有大的改进。我接触一些国内非常聪明的学生,感觉胆子还是小。有时不是说好多东西没有想到,而是有想到但不敢去做,他觉得“哇,这个东西别人没做是不是太难还是没意义”。另外,不要觉得创新就那么难,如果别人往西走, 你就不去。你使劲想、仔细想,一定能想出些不同来。计算机科学完全是个想象的空间,一定要敢想,想与别人不同。也不要只想不同一点点,最起码要有个方向,伸出一个树枝来——种树不容易,但伸出一个新枝,这样的追求是要有的。
还有,做事情要有一个 abstract concept。中国人是很注重实用的民族,不像西方理论性那么强。特别是做研究,不要随时想着纯粹的应用,要想着 abstract idea,要有概括升华,提出概念,让人一听即懂,要形成知识。
最后,我希望年轻学者们能够多做原创、理论和基础性的贡献。
* 新智元原创报道
【号外】新智元正在进行新一轮招聘,飞往智能宇宙的最美飞船,还有N个座位
点击阅读原文可查看职位详情,期待你的加入~

点击阅读原文查看新智元招聘信息




