在数据采集器中用TensorFlow进行实时机器学习
极市平台是专业的视觉算法开发和分发平台,加入极市专业CV交流群,与6000+来自腾讯,华为,百度,北大,清华,中科院等名企名校视觉开发者互动交流!更有机会与李开复老师等大牛群内互动!
同时提供每月大咖直播分享、真实项目需求对接、干货资讯汇总,行业技术交流。点击文末“阅读原文”立刻申请入群~
来源:云栖社区
译者:Mags,审校:袁虎
导读:本文学习如何通过发布的最新TensorFlow Evaluator版本使用TensorFlow(TF)模型进行预测和分类。
最新DataOps平台的真正价值,只有在业务用户和应用程序能够从各种数据源来访问原始数据和聚合数据,并且及时地产生数据驱动的认识时,才能够实现。利用机器学习(Machine Learning),分析师和数据科学家可以利用历史数据,以及实时地使用类似TensorFlow(TF)这样的技术,以做出更好的数据驱动业务的线下决策。
在本文中,你将学习如何利用TensorFlow模型在StreamSets Data Collector3.5.0和StreamSets Data Collector Edge中最新发布的TensorFlow Evaluator*进行预测和分类。
在深入讨论细节之前,我们来看一些基本概念。
机器学习(Machine Learning)
亚瑟·塞缪尔把它描述为:“不需要明确地编写程序而使计算机有能力学习的研究领域。”随着机器学习领域的最新发展,计算机现在有能力做出预测,甚至比人类做的还要好,并且感觉可以解决任何问题。让我们先回顾一下机器学习都解决了什么样的问题吧。
通常来说,机器学习被分为两大类:
监督学习(Supervised Learning)
“监督学习是学习一个函数的机器学习任务,该函数基于输入-输出的实例,将输入映射到输出。”—维基百科(Wikipedia)。
它涉及到构建一个精准的模型,当历史数据被标记为一些结果的时候,模型就可以预测出结果了。
用监督学习解决的常见业务问题:
二元分类(学习预测一个分类值)
顾客会购买一个特定产品吗?
癌症是恶性的还是良性的?
多级分类(学习预测一个分类值)
给定的一段文本是否带有病毒、恐吓或淫秽内容?
这是山鸢尾、蓝旗鸢尾还是北美鸢尾的物种?
回归(学习预测一个连续值)
一个代售房子的预测价格是多少?
明天旧金山的气温是多少?
无监督学习
无监督学习允许我们在知道很少,或是完全不知道输出应该是什么样子的情况下处理问题。它涉及在之前数据上的标签是不可用的情况下创建模型。在这类的问题中,通过对基于数据中变量之间的关系进行数据聚类来导出结构。
无监督学习的两种常见方法是K-均值聚类(K-means clustering)和DBSCAN。
注意:Data Collector和Data Collector Edge中的TensorFlow Evaluator目前仅支持监督学习模型。
神经网络与深度学习
神经网络是机器学习算法的一种,可以学习和使用受人脑结构启发而来的计算模型。与其它机器学习算法,如决策树、逻辑回归等相比,神经网络具有较高的准确性。
Andrew Ng在传统人工神经网络的背景下对深度学习进行了描述。在题为“深度学习、自我学习与无监督特征学习”的演讲中,他把深度学习的思想描述为:
“利用了大脑结构的模仿, 希望:
让学习算法更好地、更容易地使用;
在机器学习和人工智能领域取得革命性的进展;
我相信这是我们朝着真正的人工智能前进的最好办法。”
常见的神经网络和深度学习应用包括:
计算机视觉/图像识别/目标检测
语言识别/自然语言处理(NLP)
推荐系统(产品、婚介等)
异常检测(网络安全等)
TensorFlow
TensorFlow是为深度神经网络设计的开源机器学习框架,由Google Brain Team开发的。TensorFlow支持在Windows和Mac操作系统上的可伸缩和便携式的训练,包括CPU、GPU和TPU。迄今为止,它是GitHub上最流行的和最活跃的机器学习项目。
Data Collector中的TensorFlow
随着TensorFlow Evaluator的引入,你现在能够创建管道(pipelines),以获取数据或特征,并在一个可控的环境中生成预测结果或分类,而不必发起对作为Web服务而提供和公布的机器学习模型的HTTP或REST API的调用。例如,Data Collector管道现在可以实时地检测欺诈交易或在文本上执行自然语言处理,因为数据在被存储到最终目的地之前,为了进一步的处理或做决策,正在经过各个阶段。
另外,使用Data Collector Edge,你可以在Raspberry Pi和其它运行在所支持的平台上的设备上运行已经启用了的TensorFlow机器学习管道。例如,在高风险地区检测洪水等自然灾害发生的概率,以防止对人们财产的破坏。
乳腺癌分类
让我们考虑将乳腺癌肿瘤分类成恶性还是良性的例子。乳腺癌是一个经典的数据集,可以作为scikit-learn的一部分。要了解如何在Python中使用该数据集训练和导出一个简单的TensorFlow模型,请查看我在GitHub上的代码。正如你将要看到的那样,模型创建和训练被保持在最小范围,并且非常简单,只有几个隐藏层。最需要注意的重要方面是如何使用TensorFlow SavedModelBuilder*来导出和保存模型。
*注意:要在Data Collector或Data Collector Edge中使用TensorFlow模型,首先应该在你选择支持的开发语言里,如Python,和交互式环境中,如Jupiter Notebook,使用TensorFlow的SavedModelBuilder导出和保存模型。
一旦使用TensorFlow的SavedModelBuilder训练并导出了模型,那么在数据流管道中使用它进行预测或分类就非常简单了 — 只要模型保存在Data Collector或Data Collector Edge可访问的位置上即可。
管道概述
在深入了解细节之前,可以看下管道是什么样的:

管道细节
目录源:
- 这将从.csv文件中加载乳腺癌的记录数据(注意:这个输入数据源可以非常简单地替换为其它的来源,包括Kafka、AWS S3、MySQL等等);
字段转换器:
- 这个处理器将转换供模型所使用的所有输入的乳腺癌记录特征数据,从String类型转换到Float类型
(mean_radius,mean_texture,mean_perimeter,mean_area,mean_smoothness,mean_compactness,mean_concavity,mean_concave_points,mean_symmetry,mean_fractal_dimension,radius_error,texture_error,perimeter_error,area_error,smoothness_error,compactness_error,concavity_error,concave_points_error,symmetry_error,fractal_dimension_error,worst_radius,worst_texture,worst_perimeter,worst_area,worst_smoothness,worst_compactness,worst_concavity,worst_concave_points,worst_symmetry,worst_fractal_dimension) ;
TensorFlow Evaluator*:
模型的保存路径:指定要使用的预训练的TensorFlow模型的位置;
模型标签:设置为“serve”,因为元图(在我们导出的模型中)要用于服务中。有关详细信息,请参见tag_constants.py和相关的TensorFlow API documentation;
输入配置:指定在训练和导出模型期间配置的输入张量信息(请见Train model and save/export it using TensorFlow SavedModelBuilder部分);
输出配置:指定在训练和导出模型期间配置的输出张量信息(请见Train model and save/export it using TensorFlow SavedModelBuilder部分);
输出字段:我们想保存分类值的输出记录字段;
Expression Evaluator:
该处理器评估模型输出或分类值为0或1(存储在输出的字段TF_Model_Classification之中) ,并用Benign或Malignantrespectively这两个值创建一个新的记录字段“Condition”;
Stream Selector:
该处理器评估癌症状况(良性或恶性)并发送记录到各自的Kafka生产者;
Kafka Producers:
输入记录以及模型的输出或者分类值被有条件地发送给两个Kafka生产者以获得进一步地处理和分析;
*TensorFlow Evaluator配置
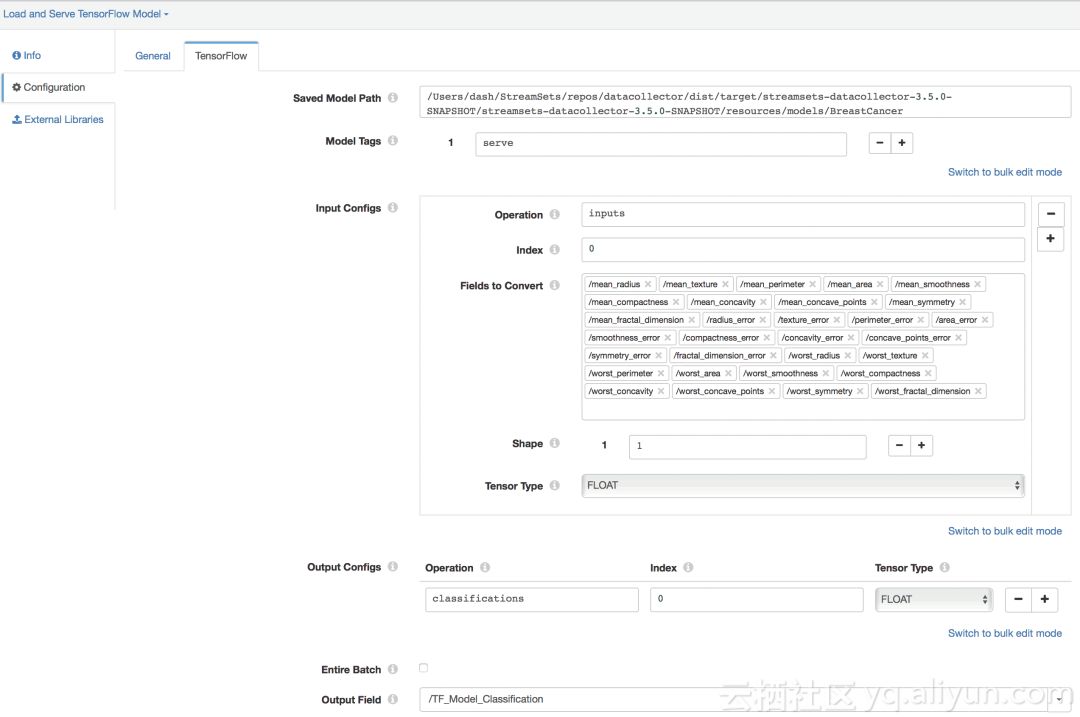
注意:一旦TensorFlow Evaluator产生了模型输出结果,本实例中采用的管道阶段是可选的,并且可以根据用例的需要与其它处理器和目标进行互换。
管道执行
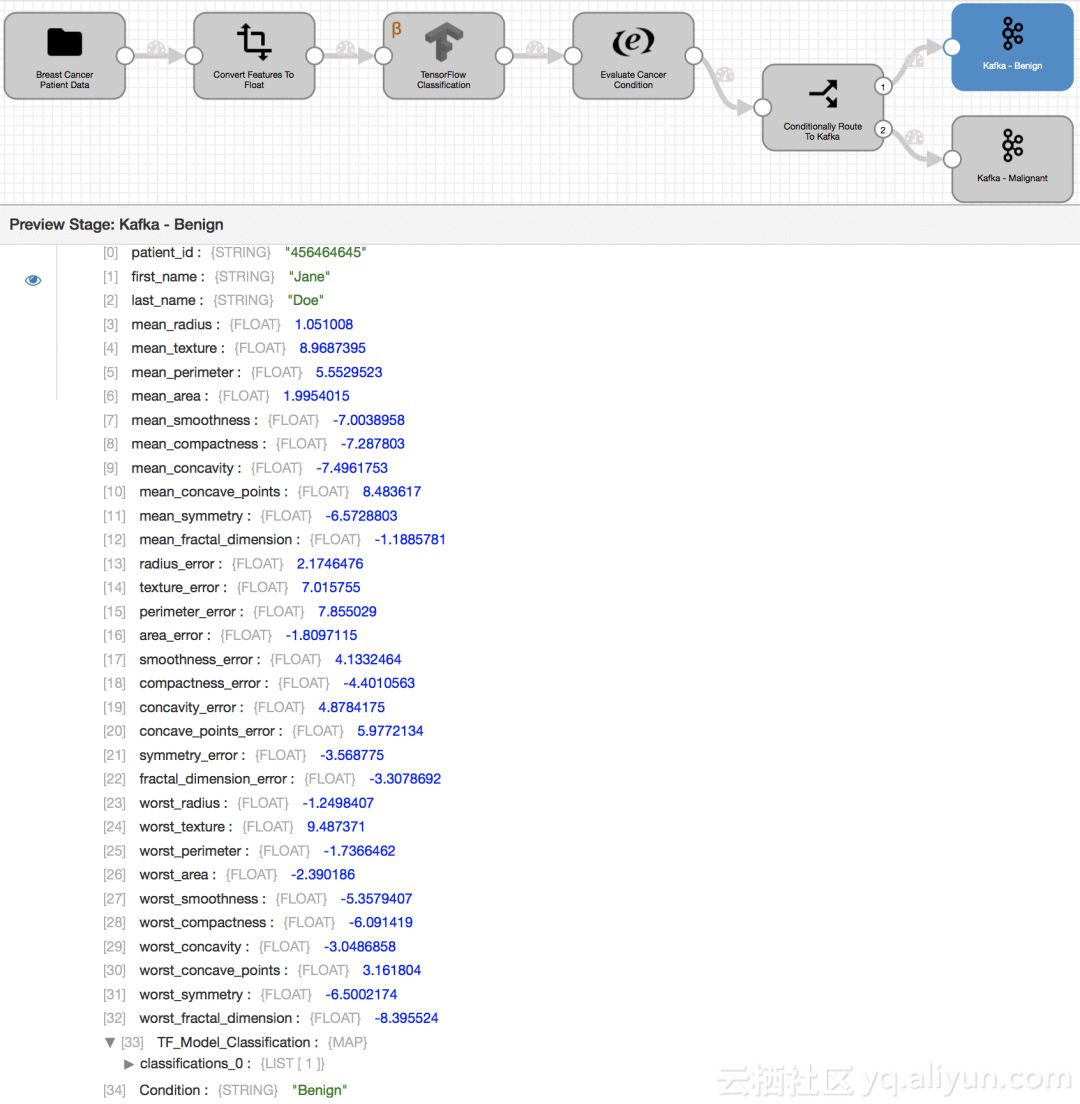
在预览管道上,乳腺癌数据记录的输入通过了上面所述的数据流管道过程,包括服务于我们的TensorFlow模型。发送给Kafka生产者的最终输出记录数据(如上所示)包括用于分类的模型所使用的乳腺癌特征,在用户定义的字段TF_Model_Classification中模型输出值为0或1,以及由Expression Evaluator创建的Condition字段中表示相应的癌症状况是良性或恶性。
总结
本文说明了在Data Collector 3.5.0中使用最新发布的TensorFlow Evaluator。一般来说,这个评估器将允许你提供预训练的TensorFlow模型,用于生成预测结果和分类结果,而无需编写任何自己的代码。
*推荐阅读*






