小型深度学习框架 | TinyGrad,不到1K行代码(附代码下载)




最近,天才黑客 George Hotz 开源了一个小型深度学习框架 tinygrad,兼具 PyTorch 和 micrograd 的功能。tinygrad 的代码数量不到 1000 行,目前该项目获得了 GitHub 1400 星。
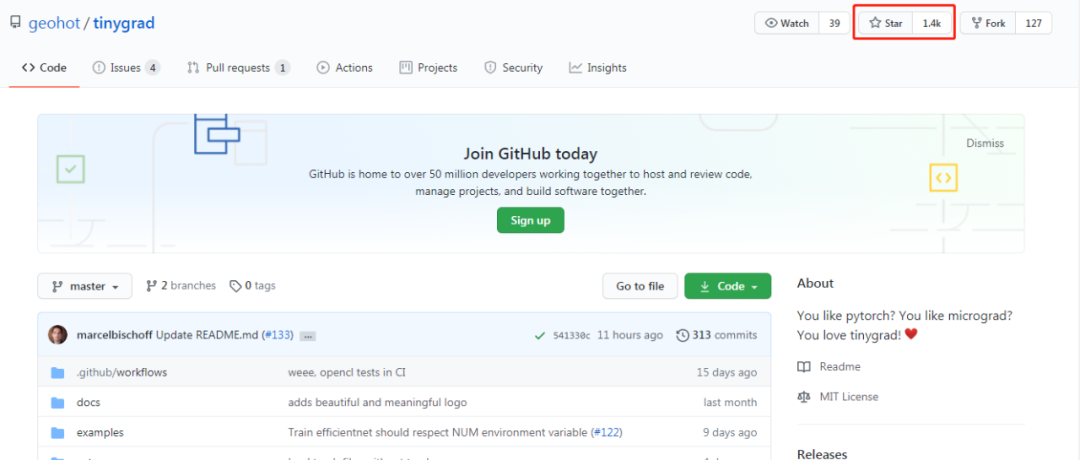
视频地址:https://www.youtube.com/channel/UCwgKmJM4ZJQRJ-U5NjvR2dg
tinygrad 的安装与使用
「tinygrad 可能不是最好的深度学习框架,但它确实是深度学习框架。」
George 在项目中保证,tinygrad 代码量会永远小于 1000 行。
pip3 install tinygrad --upgradefrom tinygrad.tensor import Tensorx = Tensor.eye(3)y = Tensor([[2.0,0,-2.0]])z = y.matmul(x).sum()z.backward()print(x.grad) # dz/dxprint(y.grad) # dz/dy
使用 torch 的代码如下:
import torchx = torch.eye(3, requires_grad=True)y = torch.tensor([[2.0,0,-2.0]], requires_grad=True)z = y.matmul(x).sum()z.backward()print(x.grad) # dz/dxprint(y.grad) # dz/dy
满足对神经网络的需求
一个不错的autograd张量库可以满足你对神经网络 90%的需求。从 tinygrad.optim 添加优化器(SGD、RMSprop、Adam),再编写一些 minibatching 样板代码,就可以实现你的需求。
示例如下:
from tinygrad.tensor import Tensorimport tinygrad.optim as optimfrom tinygrad.utils import layer_init_uniformclass TinyBobNet:def __init__(self):self.l1 = Tensor(layer_init_uniform(784, 128))self.l2 = Tensor(layer_init_uniform(128, 10))def forward(self, x):return x.dot(self.l1).relu().dot(self.l2).logsoftmax()model = TinyBobNet()optim = optim.SGD([model.l1, model.l2], lr=0.001)# ... and complete like pytorch, with (x,y) dataout = model.forward(x)loss = out.mul(y).mean()loss.backward()optim.step()
from tinygrad.tensor import Tensor(Tensor.ones(4,4).cuda() + Tensor.ones(4,4).cuda()).cpu()
ipython3 examples/efficientnet.py https://upload.wikimedia.org/wikipedia/commons/4/41/Chicken.jpg如果你安装了 webcam 和 cv2,则可以使用以下代码:
ipython3 examples/efficientnet.py webcampython -m pytestTODO
Train an EfficientNet on ImageNet
Make broadcasting work on the backward pass (simple please)
EfficientNet backward pass
Tensors on GPU (a few more backward)
Add a language model. BERT?
Add a detection model. EfficientDet?
Reduce code
Increase speed
Add features
/End.
后台回复“TinyGrad”
获取源码下载地址

登录查看更多
相关内容

Arxiv
0+阅读 · 2021年1月26日




相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2021年1月26日