ECCV 2020 Oral | GC:一行代码加速训练并提升泛化能力
点击上方“CVer”,选择加"星标"置顶
重磅干货,第一时间送达

本文转载自:晓飞的算法工程笔记
梯度中心化GC对权值梯度进行零均值化,能够使得网络的训练更加稳定,并且能提高网络的泛化能力,算法思路简单,论文的理论分析十分充分,能够很好地解释GC的作用原理
论文: Gradient Centralization: A New Optimization Technique for Deep Neural Networks

-
论文地址:https://arxiv.org/abs/2004.01461 -
论文代码:https://github.com/Yonghongwei/Gradient-Centralization
Introduction
优化器(Optimizer)对于深度神经网络在大型数据集上的训练是十分重要的,如SGD和SGDM,优化器的目标有两个:加速训练过程和提高模型的泛化能力。目前,很多工作研究如何提高如SGD等优化器的性能,如克服训练中的梯度消失和梯度爆炸问题,有效的trick有权值初始化、激活函数、梯度裁剪以及自适应学习率等。而一些工作则从统计的角度对权值和特征值进行标准化来让训练更稳定,比如特征图标准化方法BN以及权值标准化方法WN。。
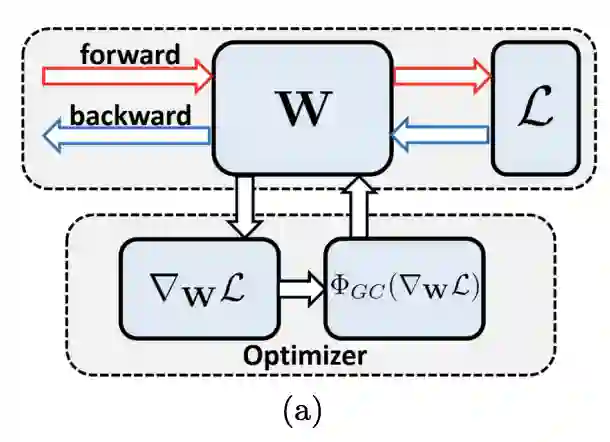
与在权值和特征值进行标准化方法不同,论文提出作用于权值梯度的高性能网络优化算法梯度中心化(GC, gradient centralization),能够加速网络训练,提高泛化能力以及兼容模型fine-tune。如图a所示,GC的思想很简单,零均值化梯度向量,能够轻松地嵌入各种优化器中。论文主要贡献如下:
-
提出新的通用网络优化方法,梯度中心化(GC),不仅能平滑和加速训练过程,还能提高模型的泛化能力。 -
分析了GC的理论属性,表明GC能够约束损失函数,标准化权值空间和特征值空间,提升模型的泛化能力。另外,约束的损失函数有更好的Lipschitzness(抗扰动能力,函数斜率恒定小于一个Lipschitze常数),让训练更稳定、更高效。
Gradient Centralization
Motivation
BN和WS使用Z-score标准化分别操作于特征值和权重,实际是间接地对权值的梯度进行约束,从而提高优化时损失函数的Lipschitz属性。受此启发,论文直接对梯度操作,首先尝试了Z-score标准化,但实验发现并没有提升训练的稳定性。之后,尝试计算梯度向量的均值,对梯度向量进行零均值化,实验发现能够有效地提高损失函数的Lipschitz属性,使网络训练更稳定、更具泛化能力,得到梯度中心化(GC)算法。
Notations
定义一些基础符号,使用 统一表示全连接层的权值矩阵 和卷积层的权值张量, 为权值矩阵 的第 列, 为目标函数, 和 为 对 和 的梯度, 与 的大小一样。定义 为输入特征图,则 为输出特征图, 为 位单位向量(unit vector), 为单位矩阵(identity matrix)。
Formulation of GC
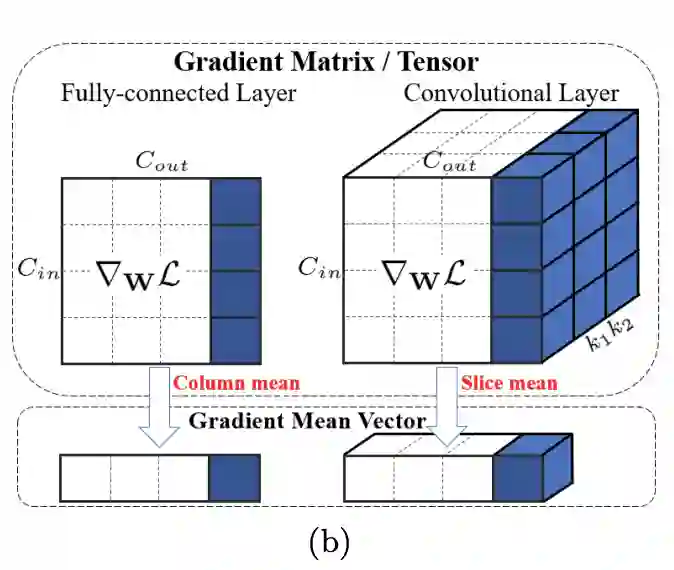
对于卷积层或全连接层的权值向量 ,通过反向传播得到其梯度 ,然后如图b所示计算其均值,GC操作 定义如下:
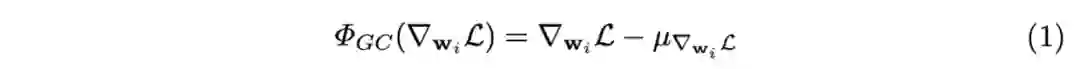
也可以将公式1转换为矩阵形式:
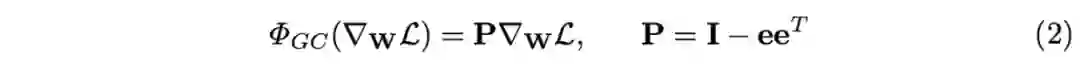
由单位矩阵以及单位向量形成矩阵构成,分别负责保留原值以及求均值。
Embedding of GC to SGDM/Adam
GC能够简单地嵌入当前的主流网络优化算法中,如SGDM和Adam,直接使用零均值化的梯度 进行权值的更新。

算法1和算法2分别展示了将GC嵌入到SGDM和Adam中,基本上不需要对原优化器算法进行修改,仅需加入一行梯度零均值化计算即可,大约仅需0.6sec。
Properties of GC
下面从理论的角度分析GC为何能提高模型的泛化能力以及加速训练。
Improving Generalization Performance
GC有一个很重要的优点是提高模型的泛化能力,主要得益于权值空间正则化和特征值空间正则化。
-
Weight space regularization
首先介绍 的物理意义,经过推算可以得到:

即 可以看作映射矩阵,将 映射到空间向量中法向量为 的超平面, 为映射梯度。
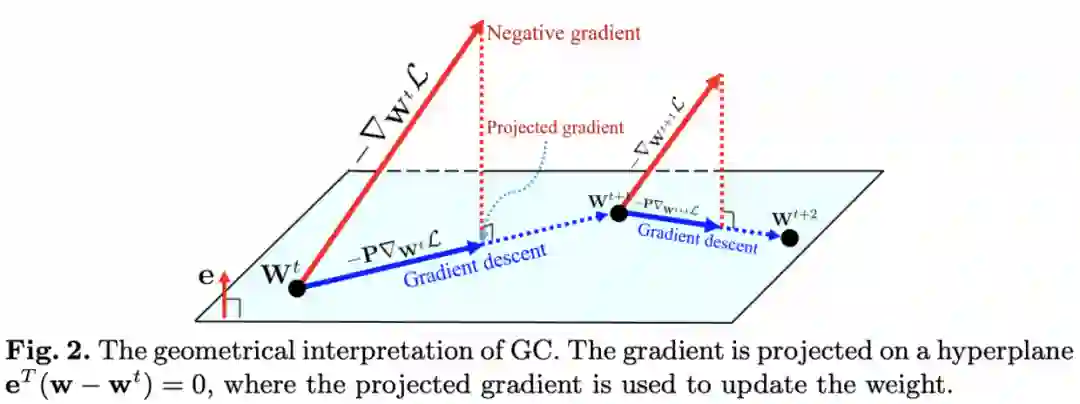
以SGD优化为例,权值梯度的映射能够将权值空间约束在一个超平面或黎曼流形(Riemannian manifold)中,如图2所示,梯度首先映射到 的超平面中,然后跟随映射梯度 的方向进行更新。从 可以得到 ,目标函数实际变为:
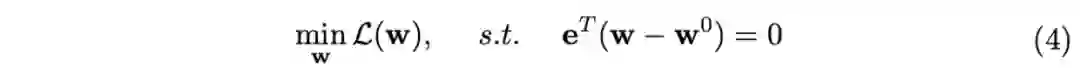
这是一个权值空间
的约束优化问题,正则化
的解空间,降低了过拟合的可能性(过拟合通常是学习了复杂的权值来适应训练数据),能够提升网络的泛化能力,特别是当训练样本较少的情况下。
WS对权值进行
的约束,当初始权值不满足约束时,会直接修改权值来满足约束条件。假设进行fine-tune训练,WS则会完全丢弃预训练模型的优势,而GC可以适应任何初始权值
。
-
Output feature space regularization
以SGD优化方法为例,权值更新 ,可以推导得到。对于任何输入特征向量 ,有以下定理:
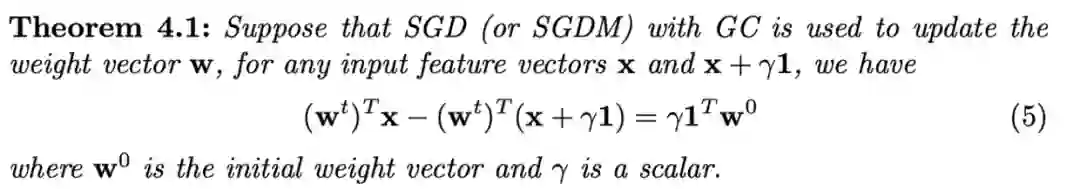
相关证明可以看原文附录,定理4.1表明输入特征的常量变化会造成输出的变化,而输出的变化量仅与标量 和 相关,与当前权值 无关。 为初始化权值向量缩放后的均值,假设 接近0,则输入特征值的常量变化将几乎不会改变输出特征值,意味着输出特征空间对训练样本的变化更鲁棒。
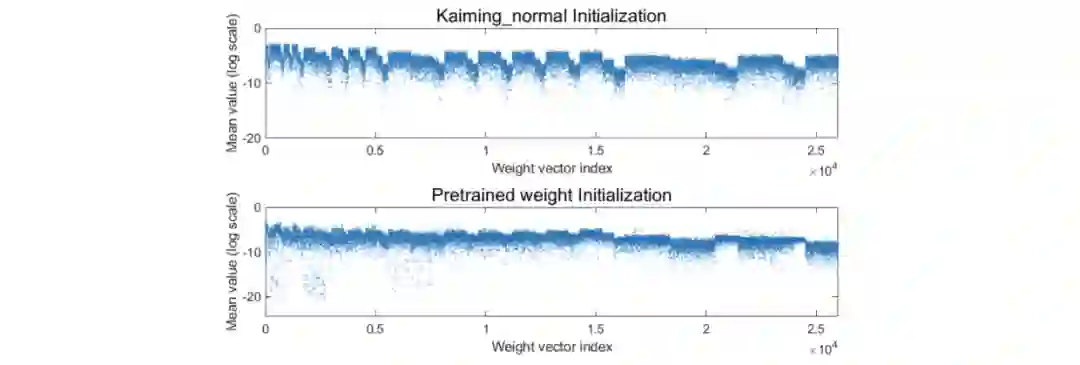
对ResNet50的不同初始权值进行可视化,可以看到权值都非常小(小于 ),这说明如果使用GC来训练,输出特征不会对输入特征的变化过于敏感。这个属性正则化输出特征空间,并且提升网络训练的泛化能力。
Accelerating Training Process
-
Optimization landscape smoothing
前面提到BN和WS都间接地对权值梯度进行约束,使损失函数满足Lipschitz属性, 和 ( 的Hessian矩阵)都有上界。GC直接对梯度进行约束,也有类似于BN和WS的属性,对比原损失函数满足以下定理:
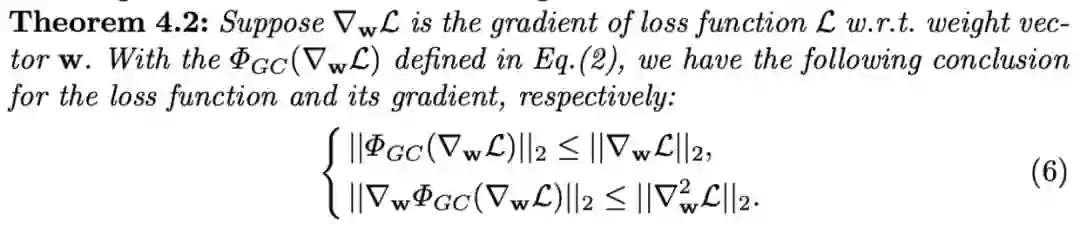
相关证明可以看原文附录,定理4.2表明GC比原函数有更好的Lipschitzness,更好的Lipschitzness意味着梯度更加稳定,优化过程也更加平滑,能够类似于BN和WS那样加速训练过程。
-
Gradient explosion suppression
GC的另一个优点是防止梯度爆炸,使得训练更加稳定,作用原理类似于梯度裁剪。过大的梯度会导致损失严重震荡,难以收敛,而梯度裁剪能够抑制大梯度,使得训练更稳定、更快。
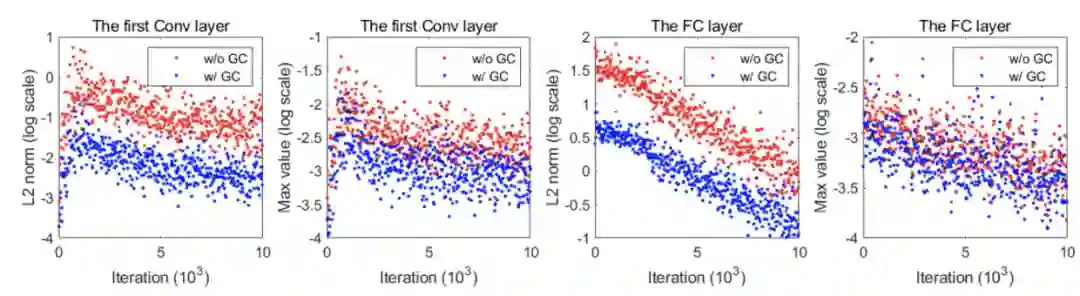
对梯度的 norm和最大值进行了可视化,可以看到使用GC后的值均比原函数要小,这也与定理4.2一致,GC能够让训练过程更平滑、更快。
Experiment
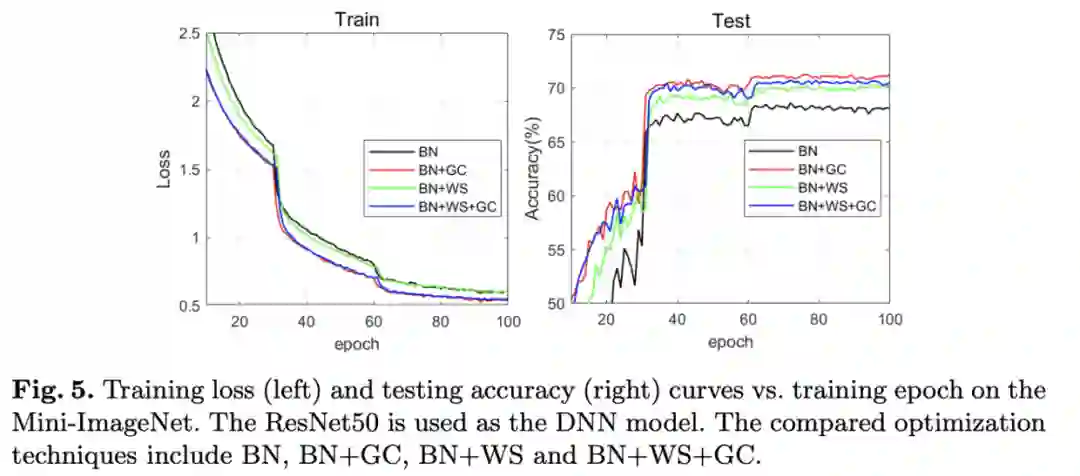
与BN和WS结合的性能对比。
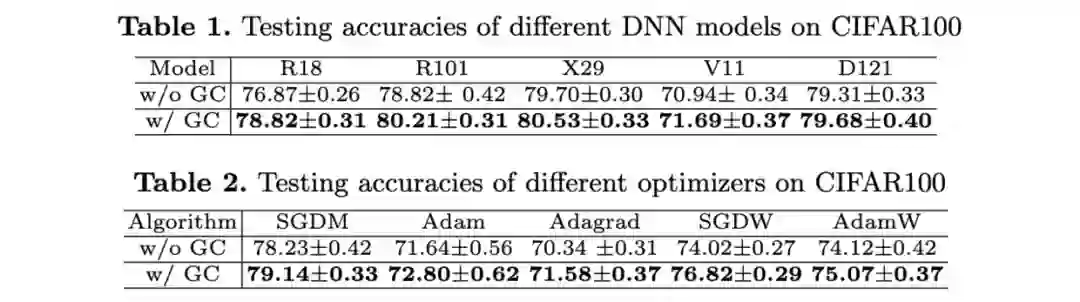
Mini-ImageNet上的对比实验。
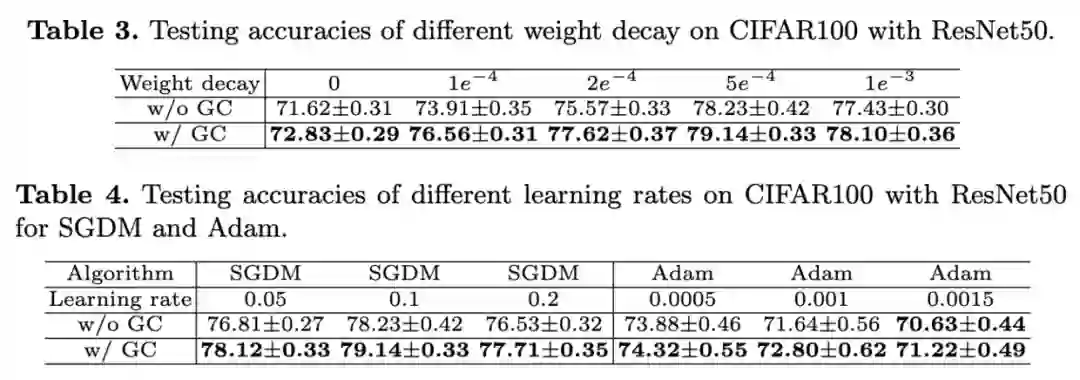
CIFAR100上的对比实验。
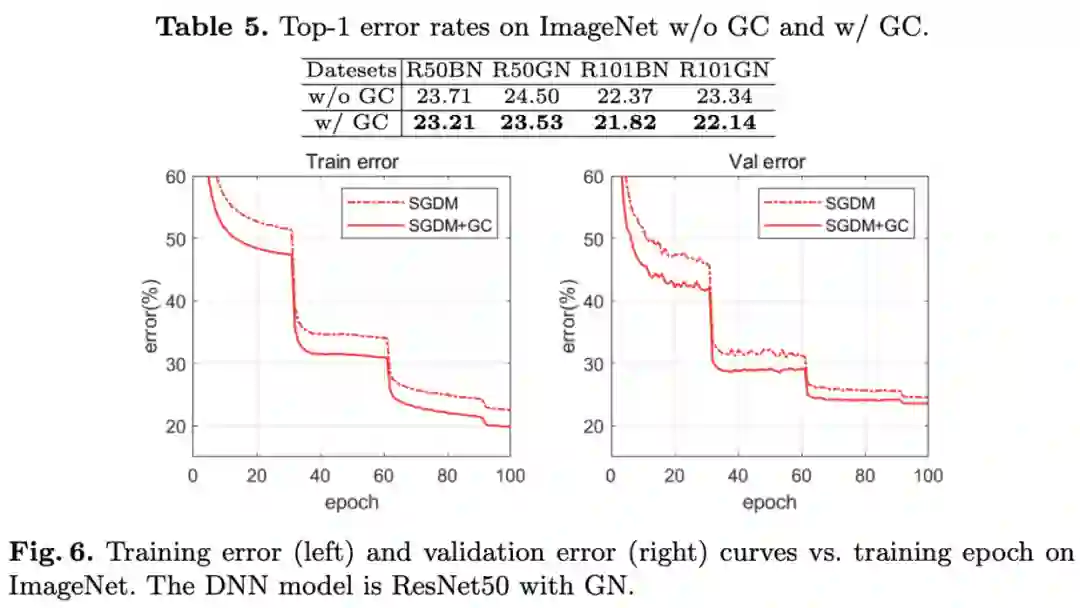
ImageNet上的对比实验。
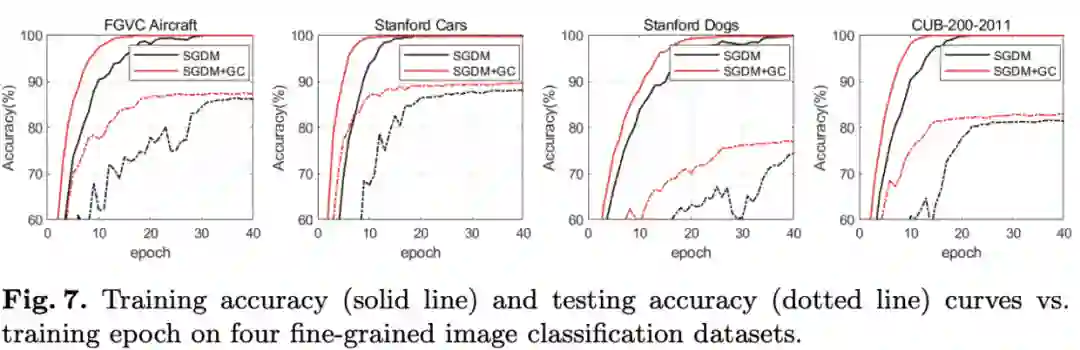
细粒度数据集上的性能对比。
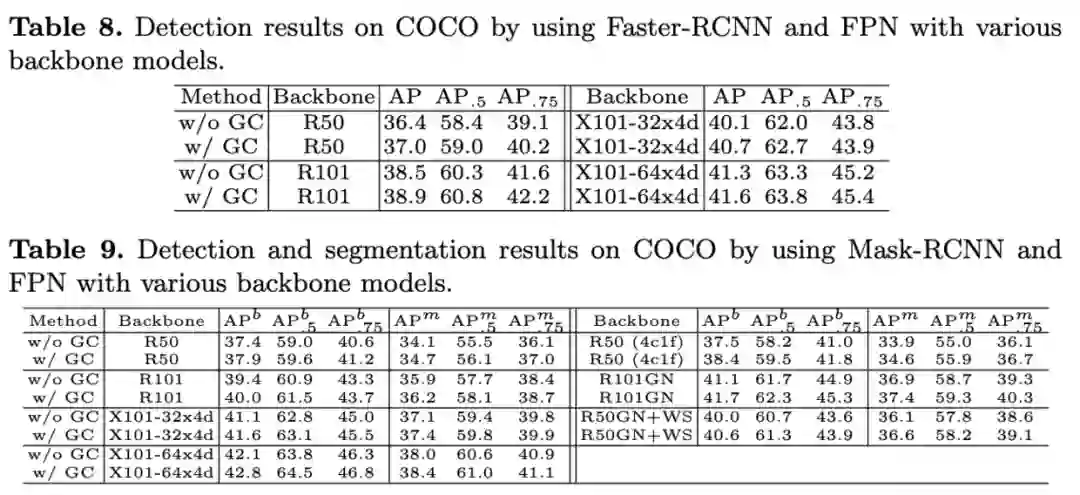
检测与分割任务上的性能对比。
Conclustion
梯度中心化GC对权值梯度进行零均值化,能够使得网络的训练更加稳定,并且能提高网络的泛化能力,算法思路简单,论文的理论分析十分充分,能够很好地解释GC的作用原理。
下载
在CVer公众号后回复:GC,即可下载论文和代码
下载1
在CVer公众号后台回复:PRML,即可下载758页《模式识别和机器学习》PRML电子书和源码。该书是机器学习领域中的第一本教科书,全面涵盖了该领域重要的知识点。本书适用于机器学习、计算机视觉、自然语言处理、统计学、计算机科学、信号处理等方向。

PRML
下载2
在CVer公众号后台回复:CVPR2020,即可下载CVPR2020 2020代码开源的论文合集
在CVer公众号后台回复:ECCV2020,即可下载ECCV 2020代码开源的论文合集
重磅!CVer-目标检测 微信交流群已成立
扫码添加CVer助手,可申请加入CVer-目标检测 微信交流群,目前已汇集4100人!涵盖2D/3D目标检测、小目标检测、遥感目标检测等。互相交流,一起进步!
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加群

▲长按关注我们
整理不易,请给CVer点赞和在看!

