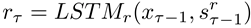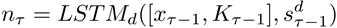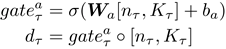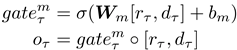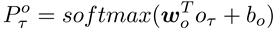本文介绍的是 IJCAI-2020论文《DAM: Deliberation,Abandon and Memory Networks for Generating Detailed and Non-repetitiveResponses in Visual Dialogue》,该论文由中科院信工所于静老师指导,由来自中科院信工所、北京航空航天大学、阿德莱德大学的作者(蒋萧泽、于静、孙雅静、秦曾昌、朱梓豪、胡玥、吴琦)共同合作完成。
![]()
代码链接:
https://github.com/JXZe/DAM
近年来,跨模态研究引发了广泛关注并取得显著进展,综合分析语言和视觉等不同模态的信息对模拟现实社会中人类对于信息的认知过程具有重要意义。视觉对话是跨模态理解领域重要的任务之一,与视觉问答任务不同,视觉对话需要根据图像、对话历史来回答当前问题。视觉对话任务中现有的方法按照解码方式的不同可以分为判别式(discriminative)方法和生成式(generative)方法,判别式方法从候选答案集合中选择最合适的答案作为当前问题的回复,而生成式方法则根据输入的信息基于词表生成一个答案回复。
人工构建的候选答案集合保证了句子语法的准确性,使得判别式方法更为简单,但是在现实应用中判别式方法往往会受到设备存储库容量的限制;生成式方法虽然更为复杂和困难,但却有着更为广泛的应用价值,也更符合“人的智能”。
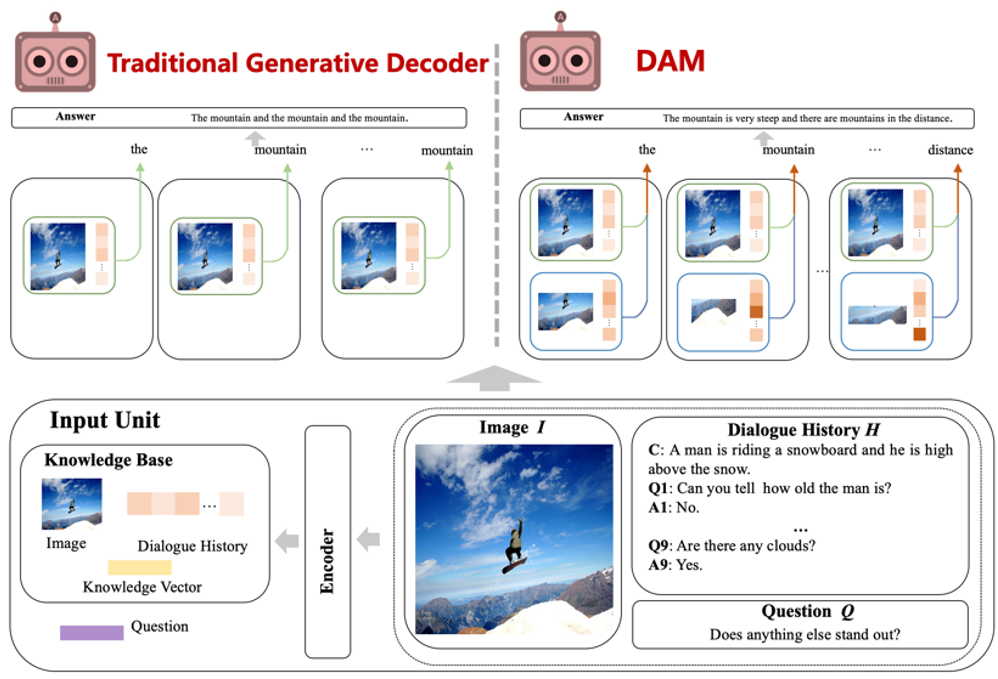
如图1所示,传统的生成式视觉对话系统采用编码器-解码器(encoder-decoder)框架。给定外界输入的图像I、对话历史H和当前问题Q,编码器端旨在捕捉输入端的语义信息,并将编码后输入端整体的语义信息送入解码器进行解码。
传统的生成式解码器采用LSTM对输入的全局语义信息进行解码,但由于全局语义缺少刻画输入图像和对话历史的细节信息且全局语义随着LSTM解码的行进几乎不发生改变,这就导致了生成的回复中包含了大量的重复的单词且缺少输入端的细节信息,严重影响了生成式视觉对话系统的用户体验。如何减少回复中重复的单词并包含更多细节信息是视觉对话任务的挑战之一。
![]()
图1 传统的生成式解码器(左)和论文提出的生成式解码框架DAM(右),其中绿色框线代表整体级别的全局语义信息、蓝色框线代表词级别的局部语义信息。
在视觉对话领域中,大量的前人工作都集中在如何更好的编码输入的多模态信息,这是从信息输入的角度对输入的多模态信息进行理解;而对于句子的生成,显然是怎样更好的解码信息更加重要,由此作者从信息输出的角度对编码的多模态信息进行更好的语义表达和文本输出。如前文所述,传统的视觉对话生成式解码器仅仅是对输入的全局语义信息进行解码,导致回复中包含了大量的重复单词。如图1所示,作者提出了一种新颖的层次化的解码框架DAM,即在解码的过程中综合的考虑整体级别的全局语义(response-level semantics)和单词级别的局部语义(word-level semantics)。全局语义负责保证生成回复的整体语义的连贯性和准确性,局部语义负责捕获当前生成的词的特有的语义信息。模型的构建突出表现出了以下三个方面的优势:
(2)模块化的结构设
计:推敲模块
(Deliberation Unit)、放弃模块(Abandon Unit)和记忆模块(Memory Unit);
(3)统一的生成式解码器框架:DAM可与现有的视觉编码器进行自适应的结合,以提高模型整体的生成能力。
生成式视觉对话任务:根据给定的图像I,图像描述C和t-1轮的对话历史Ht={C,(Q1,A1),…,(Qt-1,At-1)},以及当轮问题Qt,生成针对当轮问题Qt的最佳答案。
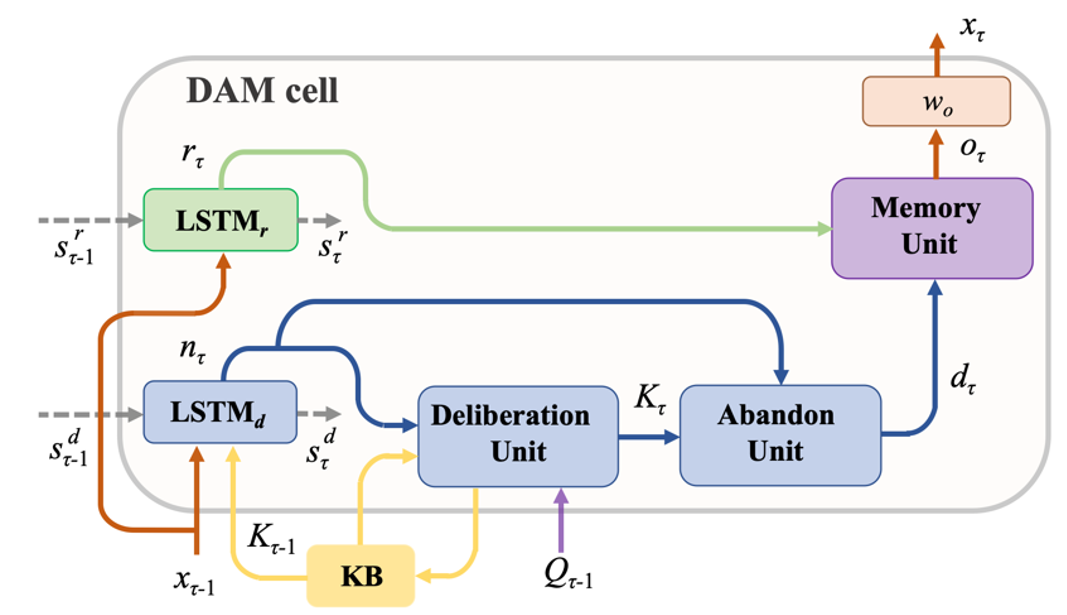
作者提出的生成式解码器框架如图2所示,主要包含全局语义解码层(绿色部分)、局部语义解码层(蓝色部分)以及层次化信息融合模块(紫色部分)。本文以解码第τ个词为例介绍模型的各部分设计。
![]()
全局语义解码层(图2中绿色区域)捕获输入信息的整体语义信息,保证生成回复的整体语义连贯性和语义正确性。全局语义解码层由单向LSTM组成(编码器输出的全局知识向量K作为初始隐状态),输入上一时刻生成的单词xτ-1和隐状态s,输出解码当前词的全局语义信息rτ:
![]()
局部语义解码层(图2中蓝色区域)将重要且独特的输入信息(图像、对话历史、问题)加入到生成的词中,来强化词粒度上的局部语义信息,对生成的词进行更好的审视和理解。局部语义解码层首先通过一个单向LSTM来获得当前词的中间表示nτ,LSTM的输入为上一时刻生成的单词xτ-1和上一时刻更新后的知识向量Kτ-1的联合表示以及上一时刻的隐状态s:
![]()
随后,局部语义解码层通过推敲模块和放弃模块获取词粒度下的局部语义信息。
(1)推敲模块(Deliberation Unit)
视觉对话领域大量的工作在编码器端已经对输入的信息进行了全面的分析和理解,在可以预见的未来编码器端还会出现更多、更强大的信息理解模式。为了使DAM更好的适应视觉对话领域在编码器端多样的信息理解和选择模型,推敲模块旨在自适应地根据编码器端对于信息选择的模式来获取和当前词相关的视觉和文本信息。整体来讲,推敲模块输入为当前词nτ,输出为与当前词相关的知识信息Kτ。
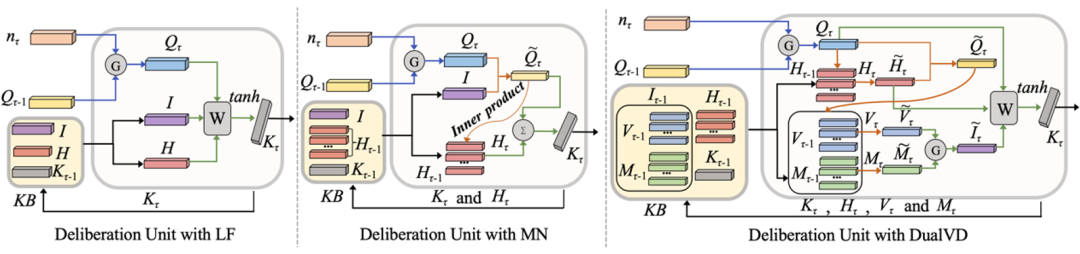
推敲模块随着编码器端结构的变化而变化,作者选取三个常见的编码器作为其基础模型来验证方法的有效性,分别为Late Fusion(LF)[1]、Memory Network(MN)[1]和Dual-coding Visual Dialogue(DualVD)[2]。三个编码器侧重点各有不同但又相互补充,LF侧重于信息的融合过程,MN侧重于对于对话历史信息的建模,而DualVD侧重于对图像信息的深度理解。如图3所示,推敲模块主要由三个信息选择的步骤组成:
步骤1在与各种编码器结合时都相同,步骤2和步骤3根据编码器的不同而不同。具体来说,和LF结合时,因LF注重信息的融合没有信息选择的过程,所以推敲模块省略
步骤2;和MN结合时,步骤2对历史信息进行了选择和更新;和DualVD结合时,步骤2依据深度视觉信息理解的模式,进一步对图像信息进行了更新和选择。
![]()
图3 推敲模块(
自适应编码器端结构),其中V为对图像理解的视觉表示,M为对图像理解的语义表示
。
由于在生成每一个单词时都会对知识库(KB)中的信息进行更新,由推敲模块输出的知识信息Kτ中会包含与之前时刻生成的词相关的信息。放弃模块旨在过滤掉Kτ中的冗余信息,使最后生成的局部语义信息对于当前生成的词来说是特有的,能够更加捕获词粒度上的信息。放弃模块本质上是一个信息选择的过程,作者采用gate的方式获得最后的局部语义信息:
![]()
层次化信息融合(图2中紫色区域)采用记忆模块(Memory Unit)综合地考虑全局和局部的语义信息来解码单词,是一种信息选择的过程,作者同样采用gate的方式来实现层次化的信息融合:
![]()
最后将记忆模块的输出oτ通过线性层映射到词表的大小,并返回概率最大的单词作为当前词的输出,词表中单词的概率分布计算公式为:
![]()
作者在视觉对话最新发布的数据集VisDial v1.0上做了大量的实验验证了模型的有效性。
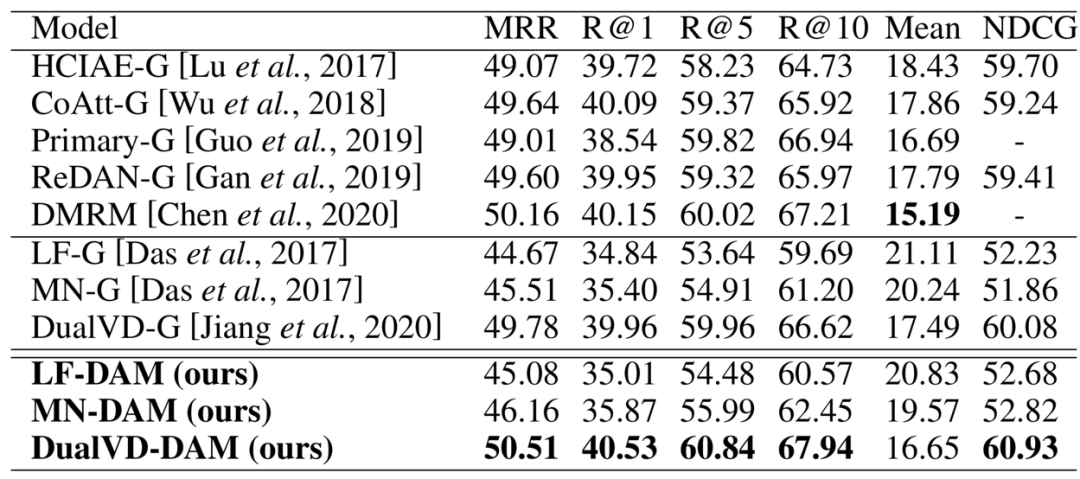
实验的总体结果如表1所示,LF-G、MN-G和DualVD-G是作者采用的基础模型(G代表对应的编码器和传统的生成式解码器搭配),LF-DAM、MN-DAM和DualVD-DAM是本文提出的模型。通过对表1的数据的分析可知:将传统的生成式解码器更换为DAM后,三个模型的表现均获得了提升;DualVD-DAM在大多数指标上达到了当前最好的结果。
表1 在VisDialv1.0 validation数据集上的结果比较
消融实验主要为了验证各个模块、层次化解码框架以及在推敲模块中采用的自适应的信息选择模式的有效性。
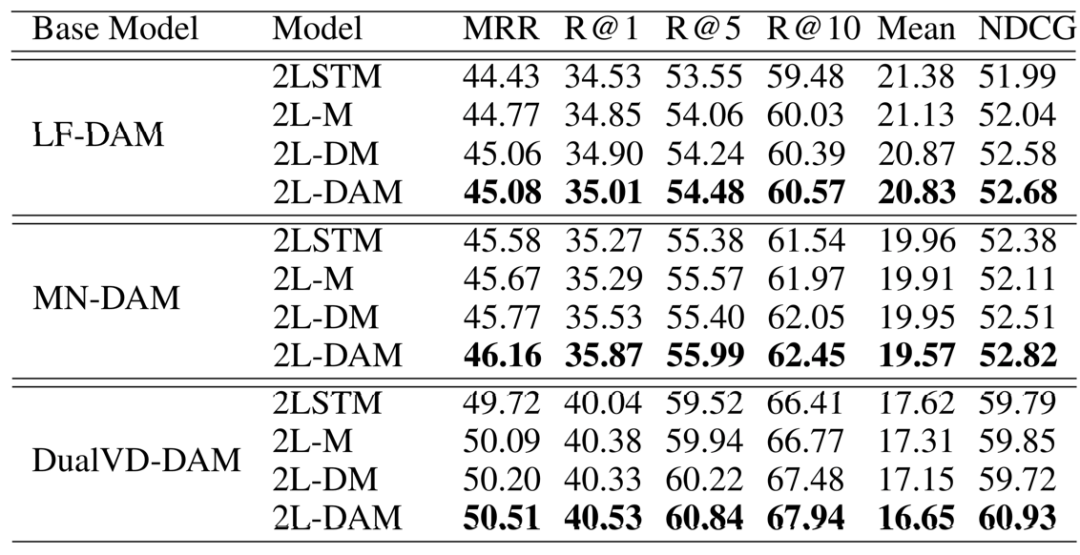
如表2所示,作者对三个模型均做了相同的消融实验来验证各个模块的有效性。其中1)2L-DAM:整体模型;2)2L-DM:整体模型w/o放弃模块;3)2L-M:2L-DMw/o 推敲模块;4)2LSTM:2L-Mw/o 记忆模块。通过对表2的数据分析可知:在引入每个模块后,模型效果均有提升;提升的趋势在三个模型中趋势均类似,因此在接下来的实验中,作者以DualVD-DAM为例做分析。
表2 关于各模块有效性的消融实验在VisDialv1.0 validation上的结果
在层次化解码框架的有效性部分,主要验证全局语义解码层和局部语义解码层的互补优势以及层次化的信息融合模式。
为了验证全局语义解码层(RSL)和局部语义解码层(WDL)的互补优势,作者随机采样了100个样本,引入三个实验对象进行人工测评,其中M1表示生成的回复通过图灵测试的比例,M2表示生成的回复高于或等于人工生成的回复质量的比例,Repetition表示生成的回复出现重复性单词的比例,Richness表示生成的回复比人工生成的回复包含更多细节的比例。实验结果如表3所示,可以观察到同时采用两层语义信息进行解码的模型在绝大多数指标上取得了最好的效果,说明了全局语义和局部语义的互补优势。
表3 在VisDialv1.0 validation上人工测评的结果
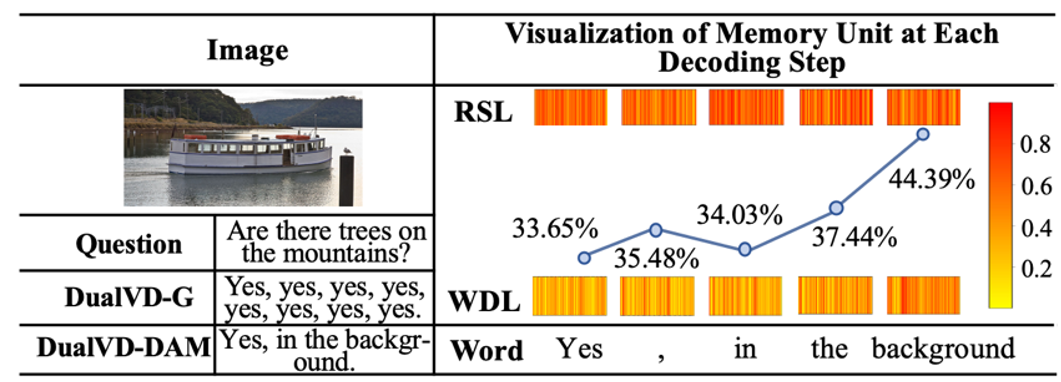
如图4所示,为了弄清楚全局语义(RSL)和局部语义(WDL)的层次化的信息融合模式,作者进一步可视化了记忆模块的门控值。根据图4的可视化结果和其他更多的案例分析,作者发现:在解码的过程中全局语义的门控值始终比局部语义的高,说明全局语义把握着回复生成的整体方向;在生成最后一个单词(比如图4中的background)的时候,局部语义的门控值有一个阶越的提升,这就像一个信号来告知模型全部的语义已经表达完成可以停止当前的生成过程,这说明局部语义确实捕捉到了词粒度的信息。
![]()
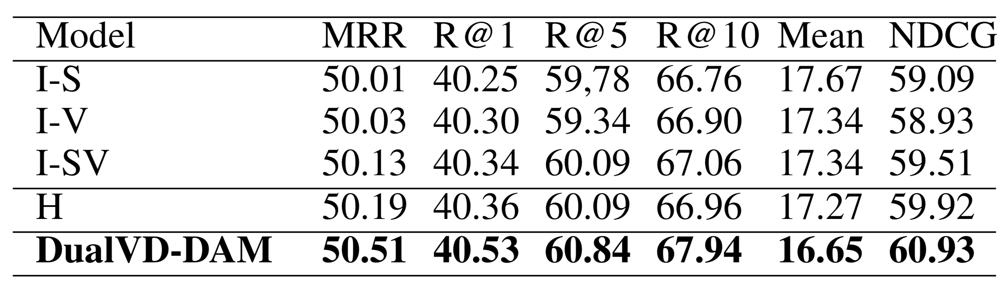
为了验证推敲模块所采用的信息选择模式的有效性,作者进一步做了消融实验。如表4所示,1)I-S:仅用图像语义信息进行信息更新和选择;2)I-V:仅用图像视觉信息进行信息更新和选择;3)I-SV:用图像语义信息和视觉信息进行更新和选择;4)H:仅用历史信息进行更新和选择。通过对表4结果的分析,可以发现最终的模型达到了最好的效果,将编码器端的信息理解模型迁移到解码器端是有效的。
表4 关于推敲模块信息选择模式的消融实验在VisDialv1.0validation上的结果
![]()
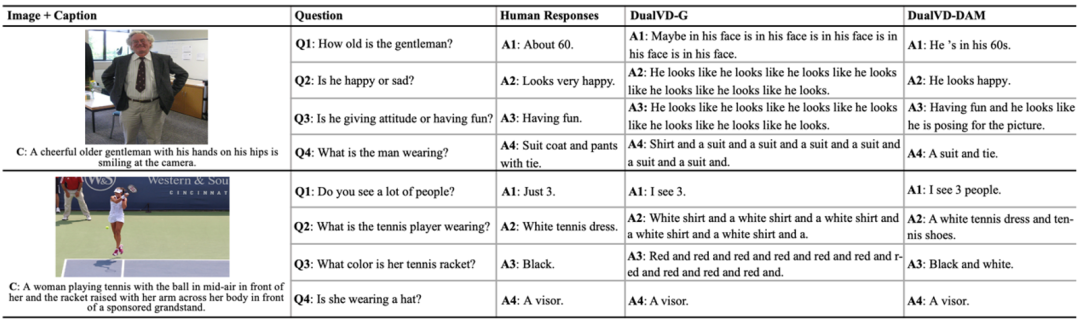
通过人工测评(表3)和案例分析(图5),作者发现与传统的生成式解码器相比,DAM可以有效的避免生成重复的单词,同时可以包含更多的细节信息。如图5中第一个例子:当问到“Q3: Is he giving attitude or having fun?”,DualVD-G生成了大量的重复单词,而DualVD-DAM通过“having fun”不仅仅回答正确了问题,而且进一步捕捉到了更多的细节信息“he looks like he is posing for the picture”。
![]()
如图6所示,作者进一步通过可视化关键单词生成的过程中捕捉到的图像和历史的区域信息来验证模型信息选择的质量。以生成“backgrounds”为例,模型捕捉到了整个图像的背景区域,同时在对话历史中捕捉到了描绘背景天空以及天气情况的区域Q2A2。
![]()
作者提出了一种面向视觉对话的高质量回复生成框架DAM,该框架采用模块化的设计思路,极大程度上避免了传统生成框架生成回复的重复性。DAM具有良好的可扩展性,能将其自适应的应用于大多数视觉对话模型中,对构建更加智能的视觉对话系统具有较好的启示作用。
[1] Abhishek Das, SatwikKottur, Khushi Gupta, Avi Singh, Deshraj Yadav, Jose ́M. F. Moura, Devi Parikh,and Dhruv Batra. Visual dialog. In CVPR, pages 1080–1089, 2017.
[2] Xiaoze Jiang, JingYu, Zengchang Qin,Yingying Zhuang, Xingxing Zhang, Yue Hu, and Qi Wu. Dualvd:An adaptive dual encoding model for deep visual understanding in visualdialogue. In AAAI, 2020.
蒋萧泽:北京航空航天大学在读硕士研究生,在中科院信工所于静老师组开展研究,研究方向:视觉对话、自然语言处理,个人主页:https://jxze.github.io/。
![]()
ACL 2020原定于2020年7月5日至10日在美国华盛顿西雅图举行,因新冠肺炎疫情改为线上会议。为促进学术交流,方便国内师生提早了解自然语言处理(NLP)前沿研究,AI 科技评论将推出「ACL 实验室系列论文解读」内容,同时欢迎更多实验室参与分享,敬请期待!
点击"阅读原文",直达“ACL 交流小组”了解更多会议信息。