【论文笔记】阿里DMR:融合Match中协同过滤思想的深度排序模型

本文是由阿里在AAAI2020发表的一篇文章,题目为 [Deep Match to Rank Model for Personalized Click-Through Rate Prediction]
文章提出了一种网络结构,利用用户历史数据来「捕获 user 与 item 的相关性」,可以使点击率预测模型更加个性化且有效。「基于协同过滤的思想引入辅助任务」帮助训练网络,受 Transformer 的启发在「注意力机制中引入位置编码」,使近期行为对用户的时间兴趣有更大的贡献,最后在公共和工业数据集上进行了实验,与现有模型相比提出的网络有了「显着改进」。
背景
近年来,有人提出了几种模型来从诸如点击和购买之类的「行为数据中提取用户兴趣」,这对于推荐系统非常重要,因为在推荐系统中用户没有明确表示他们的兴趣。为了表示用户的兴趣,考虑了用户交互项与目标项之间的相关性,其中利用相关性的最出名的就是阿里提出的 [DIN][2] 模型。但是,这种模型主要侧重于用户表示而忽略了表示 user 与 item 的关联,这种关联直接衡量了 user 对 item 的个性化偏好。
因此,文章提出了一种新的模型,称为深度匹配排序(DMR),该模型将协同过滤的思想与匹配思想结合起来,利用深度模型建模 user 与 item 的关联并用于 CTR 预测中的排序任务,于此同时构建一个协同过滤的子任务用于辅助训练网络。文章提出两个子网络建模 user 和 item 的相关性,进行 CTR 预估任务。
网络结构
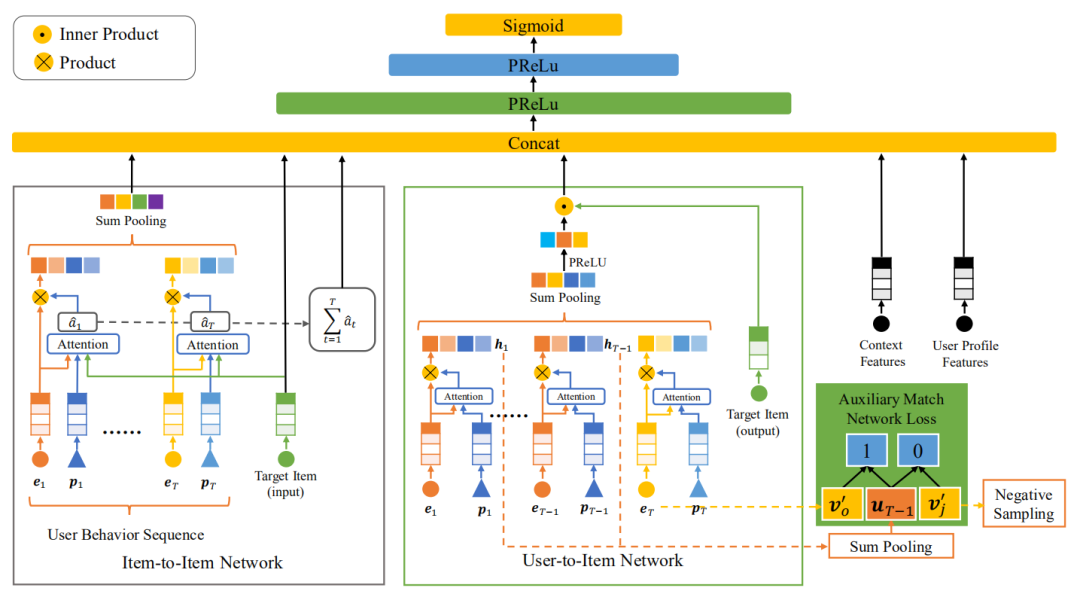
网络共包含两个子网络,分别是 item-to-item (I2I) 和 User-to-Item (U2I)。两个子网络的输出结果与其他特征亲姐,进入全连接层做最后的 CTR 预估。下面分别介绍一下两个子网络的思想和实现。
User-to-Item(U2I )
历史数据的组合可以表示用户的兴趣,最简单的做法就是对所有历史数据的 embedding 做加法,得到一个 embedding 用于表示用户的兴趣状态,这种做法的假设是每一个历史数据都有相同的贡献程度,这是一种最朴素的假设。我们还可以通过「设置一个 query 用于查找与目标相关的历史数据来表示兴趣状态」。因为 item 在历史数据中的位置体现了用户的兴趣随时间的变化情况,文中将位置编码作为 query 来匹配历史数据。
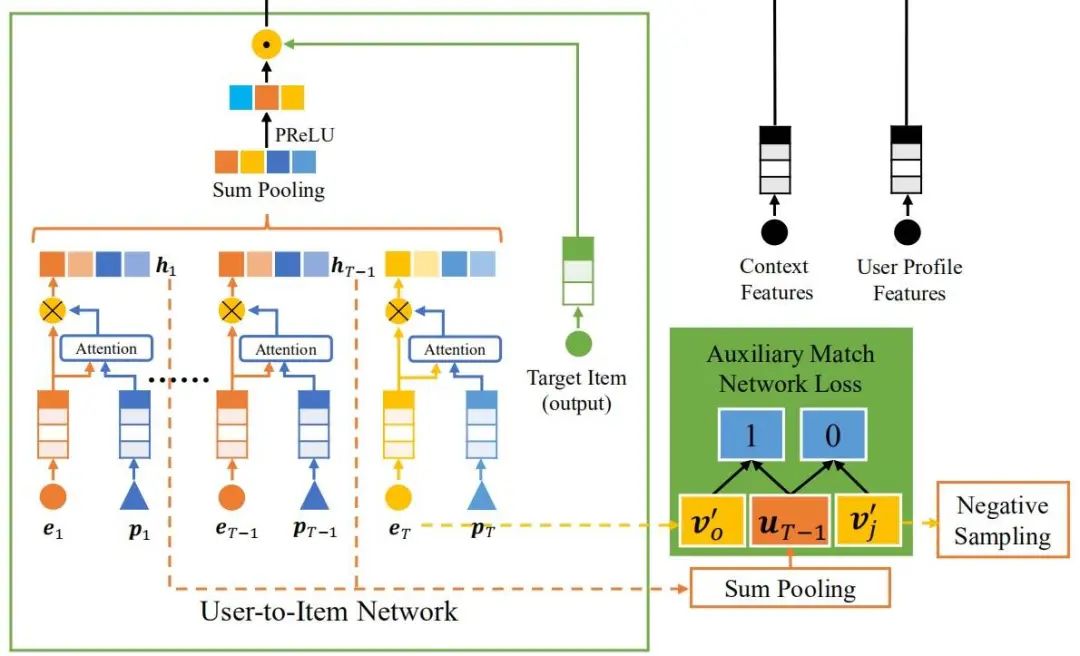
代表位置第 个位置的编码, 代表第 个位置的历史数据(例如浏览的商品), 分别是可训练参数, 代表了经过 softmax 归一化后的第 个位置的权重。最后用户 可以表示为所有行为的加权和:
代表非线性变换, 代表第 个加权后的行为。
除了位置编码之外,还可以将更多反映用户兴趣强度的上下文特征添加到注意力网络,例如, 行为类型,停留时间等。在这些特征中,位置在作者的应用场景中影响最大。这里作者提到的一个 trick 是以行为时间的倒序对位置进行编码,以确保最近的行为处于第一个位置,越近的时间影响越大,这一部分在我的源码解析 U2I 中有具体说明。
在得到用户表示 后,就要计算相关性了,文中使用用户 和目标 的内积 来表示相关性 。大的 值代表强相关性,对于最后的 CTR 预估是有帮助的,但是要注意的是 U2I 中的「目标 和历史数据虽然都属于同一类(例如商品id)但是没有使用同一个 embedding」。作者经过实验发现,在相同的参数量的情况下,使用不同的 embeeding 能提高模型性能。但是仅仅依靠 难以训练目标的 embedding,所以引入辅助网络帮助训练。
历史数据是一个 item 的序列,「辅助网络的任务就是基于序列中上一个 item 预测下一个 item」。这个过程就像是协同过滤,从所有的 item 中选出一个与上一个 item 相近的 item,但是基于所有的 item 做匹配的计算量太大,文中使用负采样抽取一部分负样本进行训练。辅助网络的匹配指标同样使用的是相关性 ,这样经过辅助网络的训练过后,目标的 embedding 会得到充分的训练,并且相关性得分也能充分表达用户和目标的相关性。更多这一部分的实现细节请参考源码解析。
Item-to-Item(I2I)
除了使用 U2I 直接建模用户与商品的相关性外,还使用 I2I 以间接方式表示相关性。具体方法是对历史数据与目标之间的相似性进行建模,然后「对所有历史数据与目标的相似性进行加和」,以获得另一种 user 与 item 的相关性。为了使相关性表示更具表达性,使用注意力机制而不是内积来对 I2I 相似性进行建模。
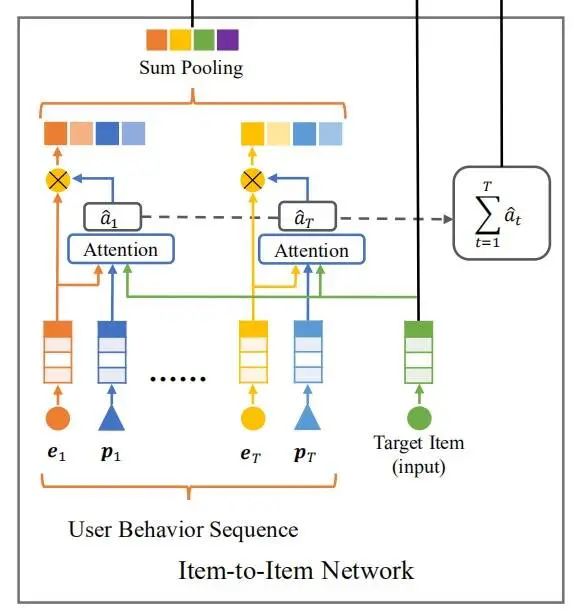
每一条历史数据都会结合 query 与目标计算相关性,得到的相关性系数一方面类似于 DIN 可以作为历史数据的加权系数得到用户兴趣的 embedding,另一方面将所有的相关性系数求和,可以得到用户兴趣与目标的相关系数。相关系数 :
是目标, 是第 个位置的编码, 是第 个位置的历史数据, 是可训练参数。
将所有的历史数据与目标相似性的总和定义为另一种用户与目标的相似性 :
通过注意力机制的局部激活能力,相对于目标而言相关性高的历史行为权重将更高。对每一个相关性系数 做归一化得到 ,使用 对历史数据 做加权求和,就得到了用户的兴趣表示 :
实验对比
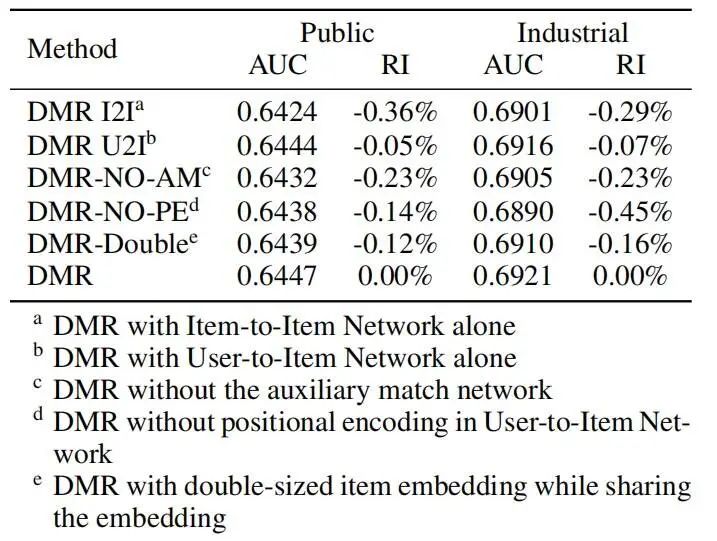
实验环节验证 DMR 在离线数据集和线上 AB 中的有效性,文章还通过消融实验证明了各个模块的有效性。
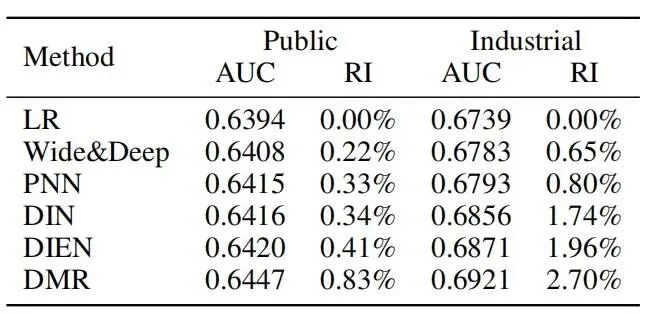
数据集效果对比
DMR 在两个数据集上的表现都要优于其他对比方法。
消融实验
作者通过去除网络部分结构,来验证模型各个模块的有效性,可以看到仅使用 U2I 模块就能达到与完整模型的类似结果,证明了 U2I 模块的有效性,去除位置编码和辅助任务都会对模型表现产生影响。
从上到下依次是:
-
仅使用 I2I 模块 -
仅使用 U2I 模块 -
没有使用辅助任务 -
U2I 模块中没有使用位置编码 -
共用目标和历史数据的 embedding -
完整的 DMR 模型
小结
文章共有两个子网络,各自会输出用户与目标的相关性得分,与其他特征拼接后送入全连接层用于分类。U2I 通过用户兴趣与目标 item 的内积直接建模相关性,I2I 通过 attention 机制建模历史数据与目标 item 的相关性,将相关性系数求和来间接表示相关性。在建模相关性的过程中使用了 query 筛选历史数据,文中采用的 query 是位置信息,也就是时间信息。为了辅助 U2I 网络训练目标的 embedding,引入一个辅助任务,该任务目标是通过用户历史数据不断的基于上一个行为预测下一个行为,类似于召回阶段,同时因为 item 总量可能过于庞大,采用负采样减少计算过程。
参考资料
推荐阅读
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
太赞了!Springer面向公众开放电子书籍,附65本数学、编程、机器学习、深度学习、数据挖掘、数据科学等书籍链接及打包下载
数学之美中盛赞的 Michael Collins 教授,他的NLP课程要不要收藏?
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。



