复旦大学张军平:人类那么容易犯错,为何会成为世界主宰

机器会犯错,其错要么是因为数据集太少,无法涵盖数据形成的样本空间;要么是由于训练太过精细,导致没办法对新来的样本或数据形成有效预计,俗称为过拟合;要么是模型本身的能力低,结果对样本的刻画能力不足;要么是硬件条件受限,无法完全相关任务。不管哪种错,总是多少能找到原因的。
而智能体尤其是人类的犯错,却有很多缺乏明晰的解释。人类会在很多方面犯错,产生错误的判断,视觉上、听觉上、距离上、认知上、情绪上,甚至人类发育的基础,基因上,都有。为什么这样一种错误频出的智能体,却能凌驾于其他生命成为地球的主宰呢?这些犯错到底有什么用呢?了解这些犯错,说不定能从中找出一些有用的线索,来重新思考人工智能的发展方向。
今天聊聊人类在视觉上的犯错表现。这种犯错常被称为光学错觉,英文叫Optical illusion。
一、视觉倒像
先从光学成像说起吧,第一个还没得到完全认识、但却又是最基本的,是视觉倒像问题。小孔成像原理告诉我们,要观测的目标通过瞳孔的凸透镜原理映射至视网膜上,是一个标准的倒像。如果是机器,则可以通过光学变换还原成正常的影像。而智能体似乎并没有光学变换的能力,从视网膜往后联就是视神经元了。人类的视网膜上位于中间位置(俗称中央凹,fovea)的视锥神经和周边的视杆神经主要承担感受光强、颜色和运动状态的功能,似乎没有自动翻转的能力。
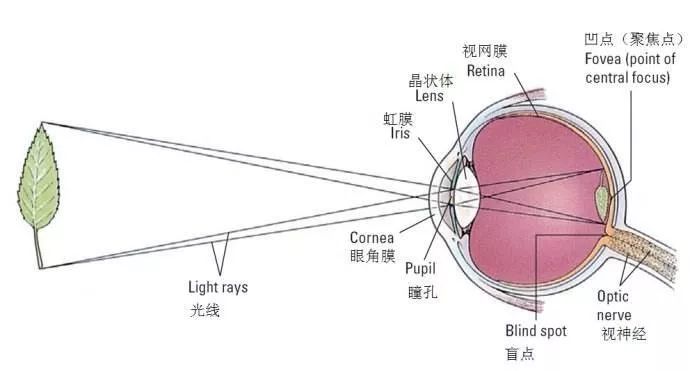
图1:眼睛的小孔成像原理
假如没有自动翻转成正常或倒着看世界会如何呢?金庸的书籍《射雕英雄传》谈到过。西毒欧阳锋为了学习从黄蓉那弄来的、假的《九阴真经》,将全身经脉逆转,结果走火入魔,变成手当足、脚当手来倒立走路。经过一段时间后,他似乎已经习惯这种颠倒的世界。
当然,这是小说中的虚构。但从历史来看,还真有科学家做过这样的尝试。1897年,美国心理学家George Stratton发表了“视网膜没有逆转视觉”的论文。在论文中,他详细介绍了关于视网膜倒像的实验。他给自己戴了一幅凸透镜,并把其中一只眼完全遮住。在前四天,本已被凸透镜纠正过来的正像,他看到的却始终是倒的。结果,以平时经验去拿东西都很失败和别扭。因为影像是倒过来的,而手势什么却还是按正常的方向去行动,想拿地上的物品手会往上伸,想拿架子上的手却往下放。不过到第五天后,他的视觉奇怪地、自发地变成正像了,好象视觉神经已经适应了,他肢体的动作也与再次世界协调了。但再取掉凸透镜后,他发现世界竟然都是巅倒的,之前的正像要再过一段时间才能恢复。换一只眼执行此实验,情况依旧。因此,他断定人的视网膜并没有把倒像颠倒过来,其功能是在视觉神经的后端实现的。即,视网膜感受的颠倒信号,是在通过视神经传导到大脑皮层的视觉中枢后,在视觉中枢实现自动翻转的。这也是目前学术界的共识。

图2 视觉倒像实验[Wiki]
其实还有个简单的办法可以检验视觉在视网膜位置是倒像的。你读到这里的时候,不妨把手放到下眼皮底下,用手把下眼皮慢慢往上推。你应该能看到一整块模糊掉的字和图往下走,而不是往上。视觉能力强的,说不定在下眼皮遮挡眼睛的过程中,看到上方会出现一块黑斑。这些恰恰就是因为光学视觉倒像造成的。
后期有很多科学家想重复他的实验,不过比较遗憾地是,没有人观察到过倒像还能适应后翻转的现象,更多地是表示能够适应巅倒过来的世界。
不过也有科学家在尝试中发现,如果戴那种会导致变形的眼镜时,类似哈哈镜那种,有些人的视觉会自动将一些没注意到的变形的位置纠正。而取下眼镜后,看到的世界反而变得扭曲了。这似乎表明大脑确实能自适应地纠正一些扭曲。
现实生活中,也有一些人会故意去阅读一些倒过来的书本,他们将其视为提高阅读速度和能力的一种秘技。还有科学家说,通过这种方式,可以刺激大脑形成新细胞,防止衰老。其实大家稍微练练,也不难做到。所以,以后看到倒着看报纸、读书的人或新闻照片时,不要马上就嘲笑喔,说不定他们真的能这样读的,哈哈。


图3 大师辜鸿铭”把报纸倒过来读”的轶事【摘自2018年1月《博爱》】
另外,作为感官元件,眼睛和其它感觉器官还有点不一样。它是在大脑发育过程中,从大脑细胞中分裂出来的。如果把从眼球到视觉中枢的连接看成是一个深度学习模型,也许可以将这种视频倒像的纠正,理解为大脑处理的端到端表现。
但倒像纠正具体是何时发生的,George Stratton没有给出研究结论。现有的文献也是说法不一。有说初生儿开始感知的世界是颠倒的,随着大脑发育的逐步完善而慢慢实现的。因为有报道说,有些两三岁的小孩可能喜欢会倒拿玩具,倒读连环画的,并猜测这可能和正视发育未完全有关。还有些人,据说天生就有空间定向现象(spatialorientation phenomenon),看的世界都是颠倒的。也有说倒视能力是与生俱来的,毕竟前者的例子还是很鲜见。

图4 患有“空间定向障碍”的塞尔维亚女子,眼中世界完全颠倒
不管怎么说,这个看似极其简单的问题,仍然没有找到统一圆满的答案,不论是它的成因还是发生时间上。
二、颠倒的视界
光学倒像这一简单的现象,在何时纠正和如何完成上,还没有形成统一和完美答案的。除此以外,以下三种情况的颠倒视界也会影响人的判断,导致错判或判断障碍,甚至产生光学幻觉。
一、人脸翻转效应(Face Inversion Effect)
图5是网络上经常能看到的。左图是一个老太太。但如果把图像颠倒过来后,却能看到一位戴着皇冠的美女。类似的颠倒错觉图还有不少。这类图产生两义性的结果,主要缘于人的视觉系统具有整体结构观和依赖人的先验知识或以往经验。
观看一张人脸图时,人们会自然地把眼睛下面的结构按鼻子、嘴巴、脖子的次序依次排序去联想和匹配,而眼睛上方的结构则往头发、头饰去想像。很少人会不按这样的结构次序来反向思维。它表明,如果忽略了与生活常识中次序相反的细节结构,就有可能产生颠倒错觉。当然,如果你有倒过来阅读习惯的,其实也能从老太太的图上直接看到倒过来的美女。

图5 颠倒错觉中的老太太与美女画像
更有意思的是,某些图像,尤其是人脸,即使只是简单地翻转,也可能导致认知障碍。
1969年,科学家Yin第一个在文献中报道了:翻转脸对于识别的影响要大于其它范畴的图像[1]。自此以后,很多科学家开始研究人脸翻转效应,并试图给出合理的解释。
加拿大安大略省女王大学(Queen’s University)的三位研究人员Freire等曾在2000年展开深入研究[2]。他们首先将多个人脸图像进行统计平均,以形成平均脸。基于对图6平均人脸的研究实验,他们分析了人脸逆转效应(Face Inverse Effect)。
他们注意到,在正脸情况下,如果从整体结构或构型(configural)的角度出发,人能够以81%的精度区分人脸。当人脸被翻转后,就只有55%的识别精度了。而如果要求测试者辨识人脸上的特征,如眼睛、眉毛、鼻子之类的,那么翻转的影响就很轻微。正常脸的识别精度是91%,翻转了也有90%的精度。如果考虑延迟的影响,他们发现隔1到10秒,让测试者重新去识别,不管是正脸还是翻转脸,在构型上或特征上的差异都能正确识别,人脸逆转效应似乎消失了。从这些实验,他们推断,人脸逆转效应中起主要作用的是构型,即整体结构对识别的影响更大。但这也可以算作构型编码的一个缺陷,比如双胞胎就很难通过构型编码来区分。
由于在时间上识别率上的差异极细微,他们还推断,这种构型缺陷主要发生在人脸处理的编码阶段,而不是后面的人脸存储阶段。这与图5中我们不容易发现老人图像中隐藏的美女的情况是吻合的。
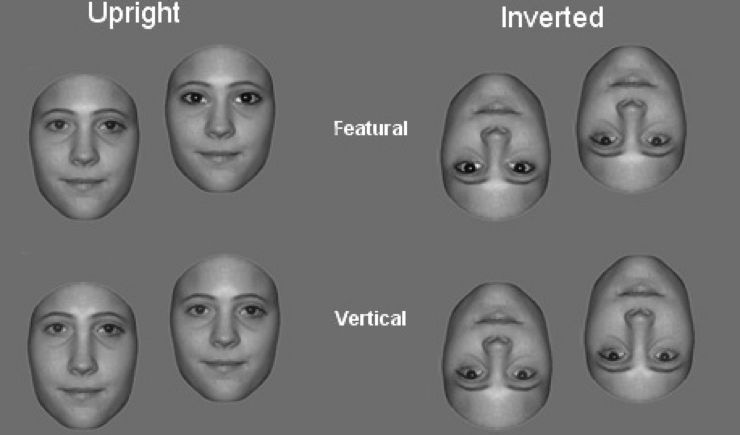
图6 人脸逆转效应,左边,正脸(Upright),右边,颠倒脸(Inverted);中间的字Featural表示“基于特征的”[2]。第二行表明人脸构型上的垂直(Vertical)距离在翻转后会被错判。
另外,科学家Carbon和Leder[3]在研究中发现,正脸比翻转后的脸的全局信息能更快获得,而在翻转脸后,特征的提取则要先于整体信息进行处理。而要在短时间(如26毫秒)处理局部特征信息,则具有上下文信息的整体结构处理是必要的。
总的来说,翻转效应影响了人对人脸的空间关系,即人脸构型的认知[4]。但是,人脸翻转效应还没有一个终结者的解释。有兴趣的朋友可以在网络上搜索”Face Inverse Effect”,应该可以查到不少最近的相关文献。
相反,现有的人工智能技术是不用担心翻转对识别性能的影响,尤其在现在引入生成式对抗网络和数据增广技术后。翻转被作为丰富人脸训练数据集的手段之一,因此,不会损害人脸识别算法的预测性能。
但从认知的角度看,这是否意味着我们在提高预测能力的同时,有可能损失了“拟人”的某些认知功能呢?也许可以推断,人脸翻转效应表明,现有的人工智能技术在人脸识别的处理方法上和人在人脸的认知上存在根本的不同。理解这些差异,也许是通向“强”人工智能和混合智能方向的线索之一。
二、正片负片的人脸识别
不仅在图像方向上的翻转会引起认知障碍,甚至对图像做简单的强度翻转也会让原来人脸识别变得更困难。
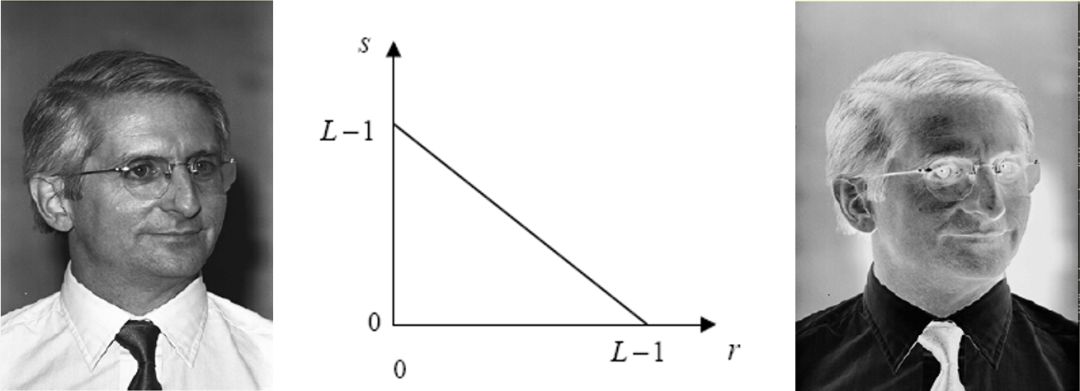
图7 人脸图像的正片(左)和负片(右),以及变换公式(中)。中间图里,横坐标可以认为是输入的图像强度,纵坐标是变换后的强度。斜线是正负片的翻转方式,即白变黑,黑变白。
图7左图是一张正常的人脸,如果对其用中间图的函数做翻转变换,即白变黑,黑变白的简单翻转,则有了右图的负片图像。虽然人在识别和记忆左图人脸时,是不太需要费脑筋的。虽然用的函数变换也很简单,但对于右图,如果没有左图做参照,人可能很难联想其真实的相貌,更不用说做有效识别了。这种差异也许是由于日常生活缺乏负片学习造成的,因为人的视网膜细胞只是感光细胞,只能接受正能量。也许是由于智能体缺乏这一类数学计算的能力,没有演化出有效的办法,可以在大脑自动将中图的简单函数求反,尽管智能体可以实现前一篇中所讲述的、光学倒像的自动纠正。
三、正负倒影

图8 耶酥光学幻觉
除了以上两种颠倒,人的视觉还有翻转颜色的“特异功能”。如图8所示,如果你盯着这张图中间的四个点静看30秒,再去看一面白色的墙或屏幕的空白处,或不停的眨眼,你的眼前便会浮现出耶酥的影子。这个影子看上去就像是由图上黑色背景内部的部分,通过黑变白,白变黑互补所形成的图像。
至于为什么会有这样的结果,也是众说纷纭。比较靠谱的解释是,这是一种图像烙印(burn-in)或持续性记忆现象。当一个非常明亮的目标处在视野的关注焦点时,会在视网膜上短暂地打上烙印。如果随后闭眼或者重复性地眨眼,这个烙印仍然还会持续一段时间。
也有观点说,人的眼睛是由视锥和视杆细胞组成。其中,视锥细胞主要负责环顾四周。如果长期只盯着同一目标看的话,那视锥细胞就容易工作过度,导致快速疲劳。结果,如果离开盯着的目标后,疲劳的视锥细胞不会迅速反馈新看到的颜色到大脑,比如新看到的白色墙壁。而大脑还需要对老的信息进行解释,因为它并没有收到强的、新的信号。
还有观点将其称为视觉后效(Aftereffects in Visual)。即连续注视相同图形之后,会导致感知被影响,随后影响感受到的图形结果。这种知觉现象最早于1925年由E.H.维尔霍夫发现,后来很多科学家都对这一现象进行了系统的研究[5]。
这些观点都认同,随着视网膜神经细胞功能的恢复,这个现象会逐渐消退。因为这种现象能带来很多奇特的视觉效果,所以,这或多或少可以解释,为什么大多数艺术馆里都是以白墙来装饰的。
不管怎么说,人眼的这些错觉现象表明,人内在的认知行为,可能比我们现在人工智能所能实现或理解的功能要复杂,需要做更多的探索。
三、看不见的萨摩耶
家附近曾经有只白色的萨摩耶,大约十二岁,挺安静温顺的,基本不怎么吠叫。听说主人身体不好,有人瘫痪在家,于是就放任其在外乱逛。他虽然个头不小,马路什么都过的好好的。可今年某天他过人行横道的时候,一辆左转的车辆速度和它过马路的速度一致,导致它进入了驾驶员的A柱盲区。等萨摩耶反应过来时,车已经对着它冲了过来,左前轮压了一次,左后轮又压了一次……它躺在车后,无助地颤抖着、哀嚎着。两旁的行人呆呆地看着,我也是……车主坐在车里,没开窗没下车,不知道是何反应。过了一会,狗用力翻身站了起来,摇摇晃晃走起来了,准备回家。大家松了一口气,有人笑着说狗没事了。车主也顺便一溜烟开车跑了。可是,狗没走到200米,便慢了下来,实在是走不动了。它的左眼珠早已被汽车压得爆了出来,满嘴的鲜血……于是,它便安静地躺在人行道上,还像平日逛街一样,一声不吭……希望它下辈子,不要走得这么悲惨。
作为智能体,人的视觉和现在的机器视觉是有区别的。其中一个非常特别的区别是,人会根据情况或上下文有意无意地忽略眼中看到的目标。
1999年两位权威心理学专家克里斯托弗·查布里斯(Christopher F.Chabris)和丹尼尔·西蒙斯(Daniel J.Simons)曾做过一次“看不见的大猩猩”的实验。
因为这个传说中心理学史上最强大的“大猩猩实验”,两人因此荣获了2004年的“搞笑诺贝尔奖”。播放的视频中,几个人一起打篮球,要求测试者统计投进篮框的球的数量。当视频播放完,要测试者报告进球数,基本都答对了。但问他们有没有注意到视频中有只人扮的大猩猩从视频中走过,却有不少人没能回想起来。
类似的实验,英国赫特神德大学的心理学怪才、理查德·怀德曼教授(Richard Wiseman)也做过,叫变色纸牌游戏。
两个人在摄像机前表演玩牌的魔术。表演的过程中,身上的衣服、背景、桌布都被换掉了。但由于摄像机关注焦点的变化,观测者只注意了两位“魔术师”手中扑克牌的变化,而视频中已经换掉的材料却压根就没发现。
如果让计算机或利用人工智能算法来跟踪并区分变化内容,会很快发现其中的区别。因为计算机在检测目标时,会考虑像素位置上的强度变化。所以,当视频中出现大猩猩,或者变换桌布、背景、衣服时,都意味着视频帧与帧之间出现了大面积的像素变化。这种变化,很容易超过图像变化程度的阈值, 导致被检测和发现。值得指出的是,检测这类变化也是现在做视频摘要、视频关键内容提取的基本手段之一。
反观人类,人却容易出现忽略目标的情况。其原因在于,当人关注某个目标时,目标将成像于视网膜的焦点即中央凹区域,而目标周围的内容则分布在中央凹的周边,由视杆细胞来负责感知。而视杆细胞主要负责运动,对具体细节不敏感,所以,大猩猩在这一前提下就被大脑视觉中枢视为没有多大意义的像素点运动,甚至被篮球的运动所掩盖。换衣服、桌布等也是类似的原因。
除此以外,也许是因为人类其实是一种能偷懒就会偷懒的智能体。如果能够在不经过缜密思维就能保证大部分判断成功的话,人类会倾向于优先采用更简易的判断,而不是进行过多的细致分析。就像平时走路一样,我们也没有像机器人一样去区分路面的高低差异、纹理差异、光强差异,但却能非常有效和快速的形成决策。即使存在例外,那也是极个别的情况。
这种现象,在日常生活中,是比较危险的。比如交通中,在一个平时很少有人经过的十字路口,驾驶员的关注焦点将是行驶的汽车,其关注点以避让汽车为主。在成年人经常走过的人行横道附近,则驾驶员的关注视角会以成人为主。前者的情况会导致,某天突然出现非机动车或行人时,司机会注意不到,不容易形成应急反应;后者则可能会忽略对矮小目标的关注。
能避免吗?有心理学家指出,如果关注的焦点不变,这种定式思维会一直存在,且很难避免。结果,当驾驶员发现危险来临时,已经缺乏足够的反应时间,极易形成交通事故 。
那如何解决呢?最简单的办法就是不要在经常经过的这些路口形成定式思维。但凡碰到这类路线时,不妨想想,这里可能有条看不见的萨摩耶。不妨多变化下关注的视野,如转下头、变换下关注的视野,最大程度地避免这类事故的发生。
一、看不见的盲点
人的视觉不仅有视而不见的特点,也有弥补先天不足的能力。我们的视神经感受周围环境后,还需要将信号送到大脑。送的方式挺聪明,大脑将输送信号的神经元像头发一样扎成一股,左边一股,右边一股,在每个眼球视网膜中央凹偏外约20度处集中起来,向大脑输送信号。于是,这个位置就没有感光细胞,形成了生理性盲点,如图9所示。
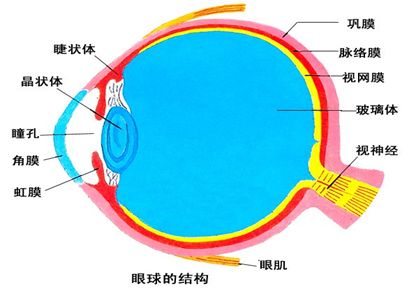
图9 人眼构造,视神经传输位置没有感光细胞
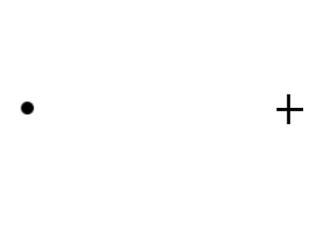
图10 生理性盲点测试图
要检测盲点的具体位置,不妨试试图10这个经典的盲点测试图。首先,捂住左眼,用右眼盯着图上的圆点,将手机逐渐拉远或拉近,会发现在某个位置时十字会消失。这个位置,对应于你的右眼盲点。类似的,捂住右眼,用左眼盯着右边的十字形,移动手机远近,会发现圆点在某个位置消失了。它对应于左眼的盲点位置。
虽然有盲点,所幸人是双目视觉,所以两只眼睛的盲区会通过双目视觉来相互弥补。结果,日常生活中,人是感觉不到盲点的存在。不过,如果单眼存在眼疾,如患上白内障,那盲点的影响就比较大了,毕竟有个位置的信息是缺失的,这就需要通过多调整视角来消解这个困扰。
二、看不见的笔 -- 单眼与复眼
除了盲点外,还有种情况,人也会对目标视而不见。各位不妨试着拿起一支笔,竖直放在左眼前面。 一开始,你会感受到笔对视野造成的遮挡。再将眼睛盯着远处某目标,将笔缓慢远离眼睛,你将会发现这只笔并没有对你看远处的景像形成任何障碍,笔似乎凭空消失了。显然,这并非是生理性盲点造成的。它和人的视网膜结构有关。换句话说,它可以从单眼与复眼的关系来解释。
众所周知,人有两只眼睛,而昆虫则是由非常多的小眼睛组成的,俗称复眼,如蜻蜓、苍蝇都有复眼。如果是昆虫的复眼,那么笔是不会对想观测的目标形成遮挡的。因为昆虫的整体视觉是可以通过小眼睛的视角拼接而成,少数几只眼睛的被遮挡不影响全局。可是人是双目视觉,为什么也会有类似的情况呢?实际上,人的视网膜上的感光细胞数量众多,每个细胞都分担了一部分的视觉检测。在处理笔遮挡的任务时,也会通过感光细胞间的相互填充,实现类似复眼的功能。
但要注意的是,人是不可能像昆虫那样演化出复眼的。因为复眼上的每只眼睛,管的视角和频率都很窄。如果要在人的头部形成如同昆虫一样具有全角度检测能力的复眼,著名物理学家费恩曼曾经做过初略的计算,他的结论是复眼的大小可能会超过现在人类头部的尺寸,结果头很可能承受不了眼睛的重量。
当然,除了这些情况看不见外,人过于关注某些人或事情时会对周围情形视而不见, 人不关注某些人或事情时也会视而不见,或熟视无睹。这些依赖于情感和心灵的视而不见和熟视无睹,比起单从视觉上发生的,就要复杂多了,也是人工智能目前还完全找不到北的问题之一。
看得见的斑点狗
先看张图。大家看看图11里面,有什么东西呢?一群杂乱无章的黑点块,还是其他?如果我说,里面有一条低垂着头的斑点狗,可能还有一棵长着茂密树叶的树,你都能看见吗?

图11 树旁的斑点狗
也许能,也许不能,因为不是每个人都见过斑点狗的姿态。但这只看不见的“斑点狗”却引出了一个人工智能的话题,一个关于“机器”图像分割和“心理”图像分割的话题,一个客观与主观图像分割的话题。
图像分割,简而言之,就是把图像中的(多个)目标和背景分离开来。它是计算机视觉和图像处理领域的经典研究方向,但至今仍未得到圆满解决。对于人工智能而言,它也是重要的基石。因为它的性能优劣决定了多数人工智能应用的有效性。比如智能驾驶,人、车、交通标志、路面、建筑物如果不能有效从监控的视频中进行准确分离,那么智能驾驶就无法实用。比如视频摘要和图像理解,如果不能把图像或视频中的目标及目标关系提取出来,也会碰到类似的问题。再比如智能服务机器人,如果不能将待服务的主人或顾客从视频中识别出来,那也就无法提供有效的服务。
不管用何种方法提取目标或背景,有标签的监督学习、或无标签的非监督学习也好,基于每个目标或类别中心的方法也好,把图像看成节点和连接边组成的图模型的方法也好,基于类似新华字典的视觉词包(Bag of visual words)方法也好,基于深度学习的图像分割也好,对目标的结构假设基本上是一致的。一般都假设了目标内部是同质地的、空洞是比较少的,目标与背景之间的边界是明显的、少锯齿状、尽量光滑的。图2就是一个标准的图像分割示例。


图12 上图:彗星;下图:经过图像分割后的慧星,白色:慧核;蓝色:离子慧尾;红色:尘埃慧尾
另外,衡量图像分割质量优劣,有两类标准。要么是人为先把真正的分割结果标记好,再通过图像相似性或信噪比指数来客观评判;要么是视觉上根据个人经验做主观分析和比较。前者与人感知的图像分割存在一定偏差,有偏好选择定量好但视觉效果差的图像分割结果的风险;后者则容易陷入“公说公有理、婆说婆有理”的尴尬局面,让人对图像分割质量的好坏没什么底。因为有可能某些图的分割效果好,但某些图效果又很不好,难以验证其可推广性。
除此以外,图像分割还具有多义性。如图13中花瓶与人、ABC和12, 13, 14中的B与13、人脸正面和侧面的图。这些图都反映了主观意识和上下文在图像分割中的重要性,也表明了图像分割并非像字面意义那么简单好处理。



图13 上:花瓶与人;中:13与B; 下:正脸/侧脸?
至于看不见的斑点狗,它涉及到另一层的“图像分割”---- 主观意识下的图像分割和目标提取。图像中本没有显明的斑点狗,可是当给予线索暗示后,人会根据提示,从自己先前的知识中,合成潜在的目标形状,并在图像中进行匹配、分割和形成最接近的目标结构。
为什么会有这样的情况出现呢?心理学中,有个叫格式塔(Gestalt)心理学的流派分析过这一现象,并将其归结为涌现(Emergence)。
在其框架下,感知到一只达尔马提亚狗(俗称斑点狗)正在茂盛的树下嗅着地面的过程称为涌现。但与常规的图像分割不同,人在辨识这只狗时,并不是通过先找到它的每个局部结构如腿、耳朵、鼻子、尾巴等,再将其拼成整体来推断狗的;而是将那些与斑点狗相关的黑点作为一个整体、一次性的感知成狗。然而,格式塔心理学也只是描述了这一现象,并没有解释这个涌现是如何在大脑中形成的。
有种解释是,人会根据自己习得的经验来分析图像,并尽可能与自己的经验去匹配。数学上,称这种经验为先验知识。尤其是当遇到毫无线索的图像时,人会优先根据先验知识或暗示来寻找最可能的答案。于是,你便可以从图1中看到一只“斑点狗”了。
根据先验知识或经验来形成对图像内容和自然界的景色进行想象和判断的例子不在少数。比如图14中的平远南台的卧佛山、桂林漓江的九马画山、甚至月球上的疑似外星人飞船等。



图14 上:平远南台卧佛;中:桂林九马画山;下:月球上的疑似飞船
但这种整体结构的形成又恰恰是“客观”图像分割很少能做到的。首先,人感知到的“斑点狗”并不符合图像分割的客观定义,如同质性、少洞性、边界光滑性和差异性。斑点狗与背景几乎是相同纹理的,斑点狗内部和外部的差异极小,边界也不清晰,甚至人也很难把其边界唯一的勾勒出来。其次,图像匹配的相似度也不高,因为只是形似,并非百分之九十的精确相似。在计算机视觉中,有可能第一时间就被判断成异常点或因为低于阈值而被排队。即使是将其视为认证任务(即:非此即彼)而非分类任务,识别算法也不见得能有多高的准确定位能力。第三,他能形成的联想会超出图像分割本身的范畴。图像分割的目的是纯粹的。而联想却是基于每个人长年耳濡目染构建的知识库。所以,才会“看到”图上的飞船,由其比例大小才会猜测非人力可为,进而联想到外星文明等。
这种上下文的联系表达,尽管已经有一些看图说话(image captioning)的研究成果,但目前的结果,从人工智能和计算机视觉角度来看,都还没法与人类抗衡。因为,他需要的知识库更为庞大,如果只靠枚举,很容易出现曾经流行的专家系统中的组合爆炸问题。
除了人的先验知识能影响对图像中目标的判断外,还有一个更为简单的因素,却能严重影响人对目标的判断,下回书表。
张军平教授简介

张军平,复旦大学计算机科学技术学院,教授、博士生导师,中国自动化学会混合智能专委会副主任。主要研究方向包括人工智能、机器学习、图像处理、生物认证及智能交通。
参考文献:
1.Yin R K. Looking atupside-down faces. Journal of Experimental Psychology. 1969, 81: 141 – 145
2.Freire A, Lee K, Symons LA. The face-inversion effect as adeficit in the encoding of configural information: direct evidence. Perception.2000;29(2):159-70
3.Carbon CC, Leder H. Whenfeature information comes first! Early processing of inverted faces. Perception.2005;34(9):1117-34
4.Rossion B, Gauthier I.How does the brain process upright and inverted faces. Behavioral and cognitiveneuroscience reviews. 2002, Mar; 1(1): 63-75.
5.http://www.baike.com/wiki/图形后效
6.克里斯托弗 · 查布利斯/丹尼尔 · 西蒙斯[著],段然[译]. 看不见的大猩猩. 北京大学出版社,2011年
7.费恩曼, 莱顿, 桑兹著. 郑永令, 华宏鸣, 吴子仪等译. 费恩曼物理学讲义(第1卷). 上海科学技术出版社, 2013年
8.Wikipedia. Gestalt Psychology. Retrieved from http://en.wikipedia.org/wiki/Gestalt_psychology. Last accessed on February 18th 2007.
9.Carlos Pedroza, Visual Perception: Gestalt Laws, College of Education, San Diego State University. Retrieved at April 8, 2007.


推荐阅读










