昨日,第十八届中国计算语言大会(CCL 2019)在昆明落幕,大会公布了最佳论文、最佳报告展示奖等多个奖项。
10 月 18 日-20 日,第十八届中国计算语言学大会(The Eighteenth China National Conference on Computational Linguistics,以下简称「CCL 2019」)在昆明举行。会议以「中国境内各类语言的计算处理」为主题,吸引了众多领域内专家和业界人士前来参会。
CCL 大会是国内自然语言处理领域的高水平会议,每年都会有 NLP 领域的专家汇聚一堂。本次大会主办单位为中文信息学会,组织方为清华大学人工智能研究院。开幕式上,中国中文信息学会名誉理事长李生教授、昆明理工大学副校长杨斌、清华大学孙茂松教授、复旦大学黄萱菁教授做了致辞。
CCL 会议创办于 1991 年,由中国中文信息学会计算语言学专业委员会主办,是国内自然语言处理领域权威性最高、规模和影响最大的学术会议之一,会议内容主要聚焦于中国境内各类语言的智能计算和信息处理,包括特邀报告、论文展示、系统展示、技术评测、前沿技术讲习班、国际前沿动态综述等形式,为研讨和传播计算语言学最新的学术和技术成果提供了交流平台。
近三年来,CCL 累计有 16 篇优秀录用论文成功推荐至《中国科学》、《清华大学学报》(自然科学版)发表。据了解,这 16 篇优秀录用论文近六年的累计网络下载量高达 42.4 万次,呈现出较大的学术影响力。
据 CCL 2019 官网显示,本次会议共收到论文投稿 371 篇(包括中文 237 篇,英文 134 篇);最终录用 146 篇论文(中文 90 篇,英文 56 篇)。总体录用率达到 39.35%。其中,中文论文录用率 37.87%,英文论文录用率 41.79%。
CCL 2019 论文录用列表:http://www.cips-cl.org/static/CCL2019/paper-accepted.html
据悉,本届大会允许论文作者平行投稿——即可以将投稿论文同时投到其他 NLP 大会上,只要另一会议也有类似的平行投稿政策,这无疑在吸收了优秀论文的同时,使这些论文可以更好地推向海外研究圈。
除了设立最佳论文奖(同时遵循宁缺毋滥的原则)之外,自 2017 年开始,CCL 大会还增设了「最佳张贴报告展示奖」和「最佳系统展示奖」。
本次大会共设立了三个奖项,分别是「最佳论文奖」、「最佳张贴报告展示奖」和「最佳系统展示奖」,大会还宣布了最佳博士学位论文的获奖情况。
最佳论文奖共有两篇获奖论文。包括复旦大学邱锡鹏等关于 BERT 微调用于文本分类任务的论文,以及福州大学等机构研究者提出的重建选项的观点型阅读理解任务模型。
论文 1:How to Fine-Tune BERT for Text Classification?
摘要
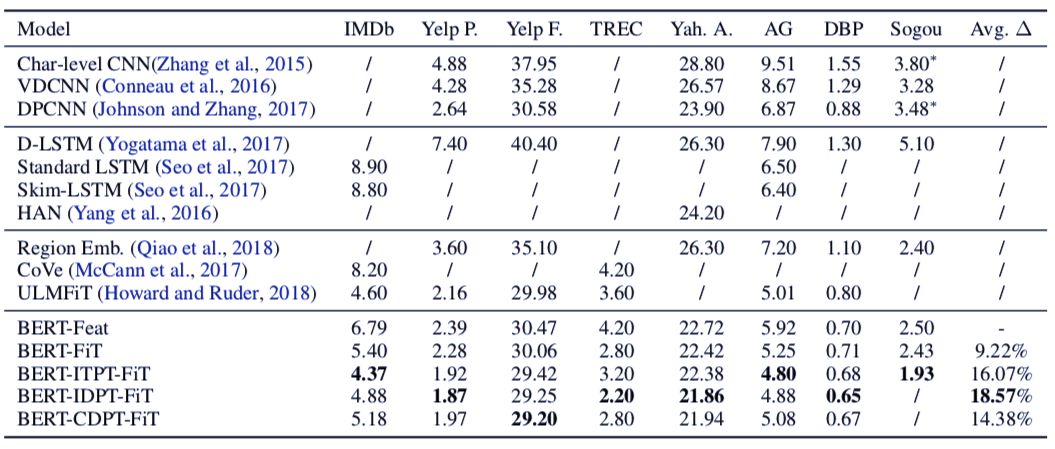
:预训练语言模型已经在学习通用语言表示上证明了存在的价值。作为一个 SOTA 预训练语言模型,BERT(基于 Transformer 的双向编码表示)在许多语言理解任务上取得了惊人的结果。在本文中,研究者进行了一项费时费力的实验,用于探索在 BERT 上进行各种微调方法,以使其用于文本分类任务上。最终,研究者提出了一个通用的 BERT 微调方法。论文提出的方法在 8 个常见的文本分类数据集上取得了新的 SOTA 结果。
![]()
图 1:三种通用的 BERT 微调方法(用不同颜色的箭头标出)。
表 6:在 8 个数据集上,微调后的 BERT 模型的测试错误率。
![]()
论文 2:Reconstructed Option Rereading Network for Opinion Questions Reading Comprehension
作者:Delai Qiu、Liang Bao、Zhixing Tian、Yuanzhe Zhang、Kang Liu、Jun Zhao、Xiangwen Liao
机构:福州大学、中国科学院大学、中国科学院自动化所
论文链接(可在 11 月 16 日前免费下载):https://link.springer.com/chapter/10.1007%2F978-3-030-32381-3_8
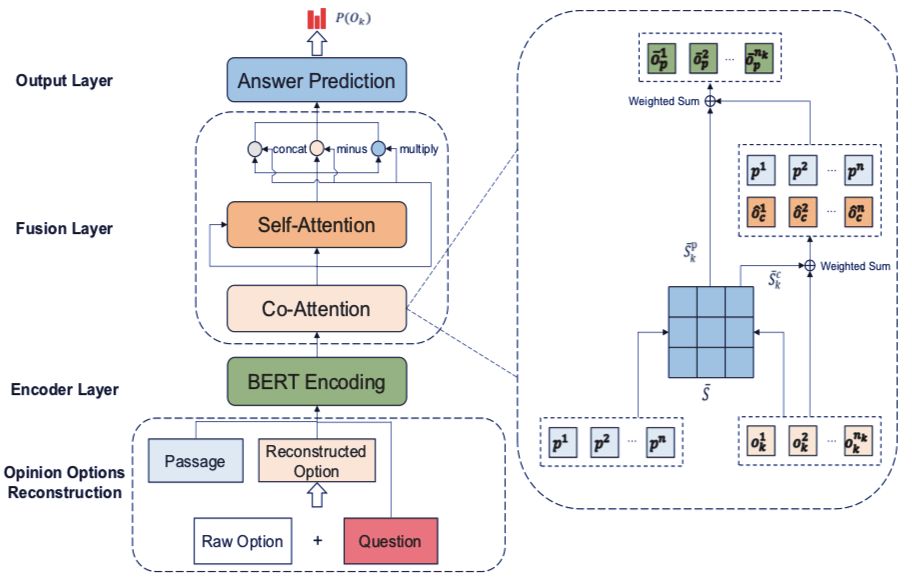
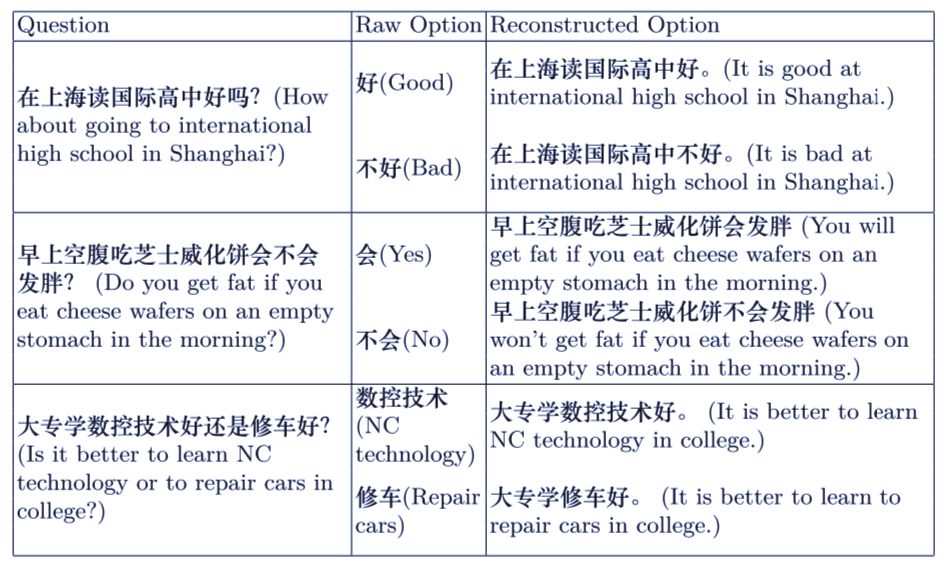
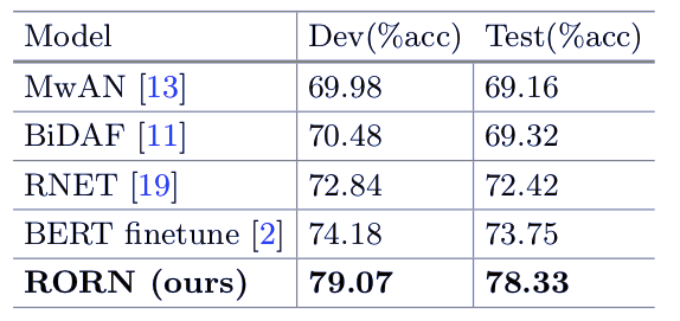
阅读理解单选题任务近来逐渐受到关注。这一任务要求极其能够根据和问题相关的文本,从一些选项中选出正确的答案。之前的研究工作主要集中于陈述性的事实问题,而忽略了观点型的问题。在观点型问题中,观点经常以情绪短语,如「好」或者「坏」来表现。这使得之前的工作无法对文本中的交互信息进行建模。因此,研究者提出了一个名为 RORN(Reconstructed Option Rereading Network)的模型。模型可以基于问题首先重建选项。然后,模型利用重建的选项生成其表示。最后,将信息输入到最大池化层中,对每个观点进行排序打分。实验说明,这一模型在中文观点问题机器阅读理解比赛中取得了 SOTA 的性能表现。
![]()
表 3:模型的性能表现对比。
使用了 https://challenger.ai/competition/oqmrc2018 提供的数据集。
最佳论文(中文)
![]()
摘要:现有的基于深度学习的情感原因发现方法往往缺乏对文本子句之间关系的建模,且存在学习过 程不易控制、可解释性差和对高质量标注数据依赖的不足。针对以上问题,本文提出了一种结合规则蒸馏 的情感原因发现方法。该方法使用层次结构的双向门限循环单元 (Bi-GRU) 捕获词级的序列特征和子句之间 的潜层语义关系,并应用注意力机制学习子句与情感关键词之间的相互联系,同时结合相对位置信息和残 差结构得到子句的最终表示。在此基础上,通过知识蒸馏技术引入逻辑规则,从而使该模型具有一定的可 控性,最终实现结合逻辑规则的情感原因发现。在中文情感原因发现数据集上的实验结果显示,该方法达到了目前已知的最优结果,F1 值提升约 2 个百分点。
论文 2:汉语复合名词短语语义关系知识库构建与自动识别研究
摘要:汉语复合名词短语因其使用范围广泛、结构独特、内部语义复杂的特点,一直是语言学分析和中文信息处理领域的 重要研究对象。国内关于复合名词短语的语言资源极其匮乏,且现有知识库只研究名名复合形式的短语,包含动词的复合名词短 语的知识库构建仍处于空白阶段,同时现有的复合名词短语知识库大部分脱离了语境,没有句子级别的信息。
针对这一现状,该文从多个领域搜集语料,建立了一套新的语义关系体系标注,构建了一个具有相当规模的带有句子信息的复合名词语义关系知识库。该库的标注重点是标注句子中复合名词短语的边界以及短语内部成分之间的语义关系,总共收录 27007 条句子。该文对标注后的知识库做了详细的计量统计分析。最后基于标注得到的知识库,该文使用基线模型对复合名词短语进行了自动定界和语义分类实验,并对实验结果和未来可能的改进方向做了总结分析。
其他获奖情况
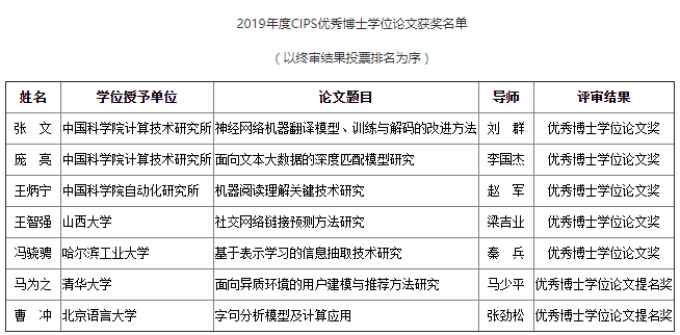
本次大会还公布了中国中文信息学会(CIPS)最佳博士学位论文获奖和提名奖的情况,包括中科院计算所、自动化所,以及山西大学、哈工大、清华、北京语言大学等机构的博士生论文获奖或获得了提名。
![]()
此外,CCL 2019「最佳张贴报告展示奖」和「最佳系统展示奖」的获奖论文情况也在 20 日下午的会议上进行了公布。其中,清华大学构建的「九歌」诗歌创作系统获得了最佳系统展示奖。只需要输入关键字或句子等信息,该系统就能直接生成绝句、藏头诗、律诗、词等创作文体。
http://www.cips-cl.org/static/CCL2019/index.html
华为云近期推出精编实战公开课,涵盖机器学习、大数据、运维实战等多项系列课程,由华为云资深工程师倾情讲授,完成理论学习+实践内容还有精美礼品相赠。点击
阅读原文,选择课程,免费报名。
![]()