本文约2500字,建议阅读10分钟
本文通过介绍Apache Spark在Python中的应用来讲解如何利用PySpark包执行常用函
数来进行数据处理工作。
![]()
Apache Spark是一个对开发者提供完备的库和API的集群计算系统,并且支持多种语言,包括Java,Python,R和Scala。SparkSQL相当于Apache Spark的一个模块,在DataFrame API的帮助下可用来处理非结构化数据。
通过名为PySpark的Spark Python API,Python实现了处理结构化数据的Spark编程模型。
这篇文章的目标是展示如何通过PySpark运行Spark并执行常用函数。
Python编程语言要求一个安装好的IDE。最简单的方式是通过Anaconda使用Python,因其安装了足够的IDE包,并附带了其他重要的包。
通过这个链接,你可以下载Anaconda。你可以在Windows,macOS和Linux操作系统以及64位/32位图形安装程序类型间选择。我们推荐安装Python的最新版本。
![]()
Anaconda的安装页面(https://www.anaconda.com/distribution/)
下载好合适的Anaconda版本后,点击它来进行安装,安装步骤在Anaconda Documentation中有详细的说明。
安装完成时,Anaconda导航主页(
Navigator Homepage
)会打开。因为只是使用Python,仅需点击“Notebook”模块中的“Launch”按钮。
![]()
为了能在Anaconda中使用Spark,请遵循以下软件包安装步骤。
第一步:从你的电脑打开“Anaconda Prompt”终端。
第二步:在Anaconda Prompt终端中输入“conda install pyspark”并回车来安装PySpark包。
第三步:在Anaconda Prompt终端中输入“conda install pyarrow”并回车来安装PyArrow包。
当PySpark和PyArrow包安装完成后,仅需关闭终端,回到Jupyter Notebook,并在你代码的最顶部导入要求的包。
import pandas as pd
from pyspark.sql import SparkSession
from pyspark.context import SparkContext
from pyspark.sql.functions
import *from pyspark.sql.types
import *from datetime import date, timedelta, datetime
import time
首先需要初始化一个Spark会话(SparkSession)。通过SparkSession帮助可以创建DataFrame,并以表格的形式注册。其次,可以执行SQL表格,缓存表格,可以阅读parquet/json/csv/avro数据格式的文档。
sc = SparkSession.builder.appName("PysparkExample")\
.config ("spark.sql.shuffle.partitions", "50")\
.config("spark.driver.maxResultSize","5g")\
.config ("spark.sql.execution.arrow.enabled", "true")\
想了解SparkSession每个参数的详细解释,请访问
pyspark.sql.SparkSession
。
一个DataFrame可被认为是一个每列有标题的分布式列表集合,与关系数据库的一个表格类似。在这篇文章中,处理数据集时我们将会使用在PySpark API中的DataFrame操作。
你可以从https://www.kaggle.com/cmenca/new-york-times-hardcover-fiction-best-sellers中下载Kaggle数据集。
DataFrame可以通过读txt,csv,json和parquet文件格式来创建。在本文的例子中,我们将使用.json格式的文件,你也可以使用如下列举的相关读取函数来寻找并读取text,csv,parquet文件格式。
#Creates a spark data frame called as raw_data.
dataframe = sc.read.json('dataset/nyt2.json')
dataframe_txt = sc.read.text('text_data.txt')
dataframe_csv = sc.read.csv('csv_data.csv')
dataframe_parquet = sc.read.load('parquet_data.parquet')
表格中的重复值可以使用dropDuplicates()函数来消除。
dataframe = sc.read.json('dataset/nyt2.json')
![]()
使用dropDuplicates()函数后,我们可观察到重复值已从数据集中被移除。
dataframe_dropdup = dataframe.dropDuplicates() dataframe_dropdup.show(10)
![]()
查询操作可被用于多种目的,比如用“select”选择列中子集,用“when”添加条件,用“like”筛选列内容。接下来将举例一些最常用的操作。完整的查询操作列表请看Apache Spark文档。
可以通过属性(“author”)或索引(dataframe[‘author’])来获取列。
#Show all entries in title column
dataframe.select("author").show(10)
#Show all entries in title, author, rank, price columns
dataframe.select("author", "title", "rank", "price").show(10)
![]()
第一个结果表格展示了“author”列的查询结果,第二个结果表格展示多列查询。
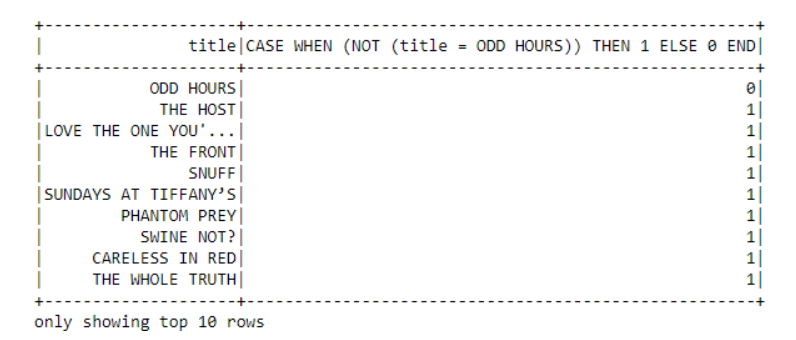
在第一个例子中,“title”列被选中并添加了一个“when”条件。
# Show title and assign 0 or 1 depending on title
dataframe.select("title",when(dataframe.title != 'ODD HOURS',
1).otherwise(0)).show(10)
![]()
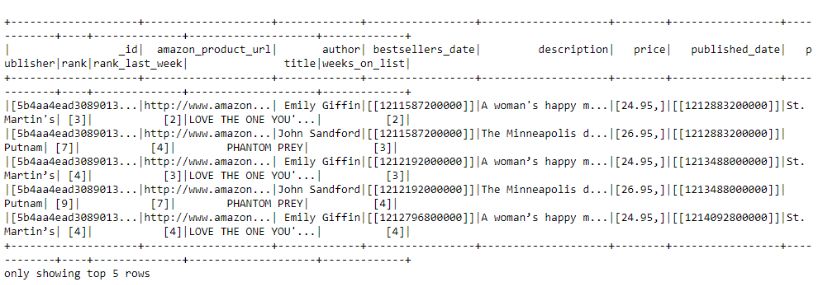
在第二个例子中,应用“isin”操作而不是“when”,它也可用于定义一些针对行的条件。
# Show rows with specified authors if in the given options
dataframe [dataframe.author.isin("John Sandford",
![]()
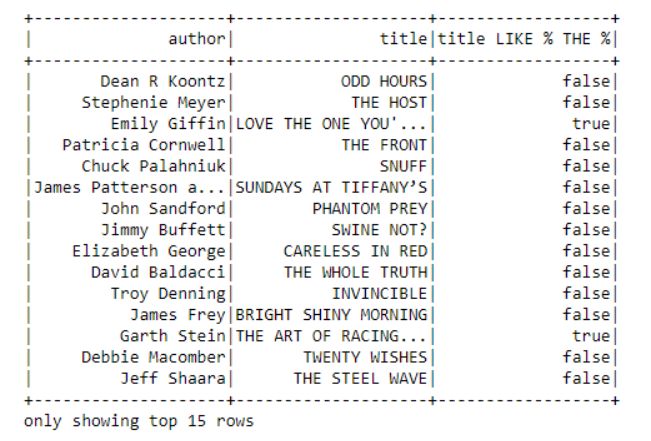
在“Like”函数括号中,%操作符用来筛选出所有含有单词“THE”的标题。如果我们寻求的这个条件是精确匹配的,则不应使用%算符。
# Show author and title is TRUE if title has " THE " word in titles
dataframe.select("author", "title",
dataframe.title.like("% THE %")).show(15)
![]()
5.4、“startswith”-“endswith”
StartsWith指定从括号中特定的单词/内容的位置开始扫描。类似的,EndsWith指定了到某处单词/内容结束。两个函数都是区分大小写的。
dataframe.select("author", "title",
dataframe.title.startswith("THE")).show(5)
dataframe.select("author", "title",
dataframe.title.endswith("NT")).show(5)
![]()
对5行数据进行startsWith操作和endsWith操作的结果。
Substring的功能是将具体索引中间的文本提取出来。在接下来的例子中,文本从索引号(1,3),(3,6)和(1,6)间被提取出来。
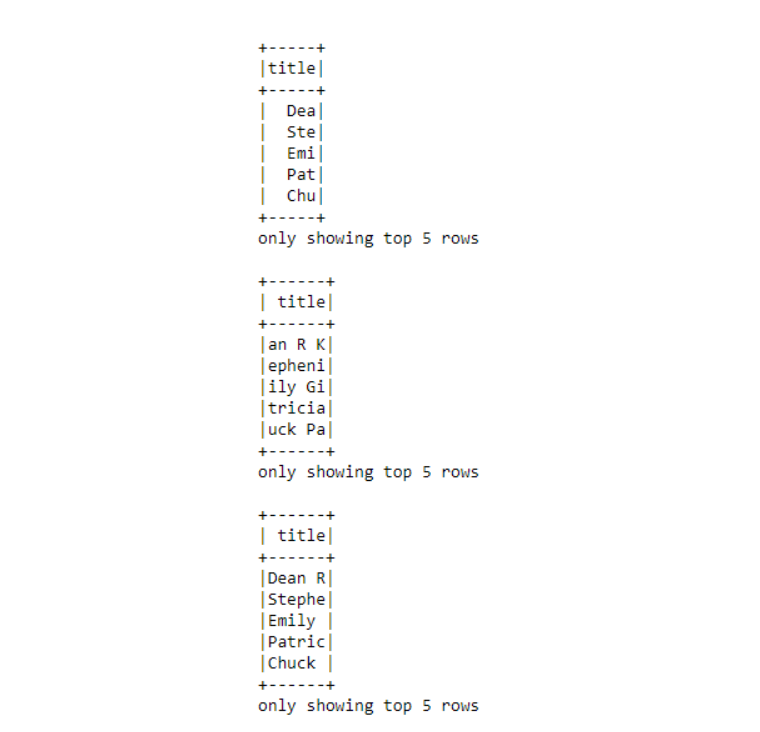
dataframe.select(dataframe.author.substr(1
, 3).alias("title")).show(5)
dataframe.select(dataframe.author.substr(3
, 6).alias("title")).show(5)
dataframe.select(dataframe.author.substr(1
, 6).alias("title")).show(5)
![]()
分别显示子字符串为(1,3),(3,6),(1,6)的结果
在DataFrame API中同样有数据处理函数。接下来,你可以找到增加/修改/删除列操作的例子。
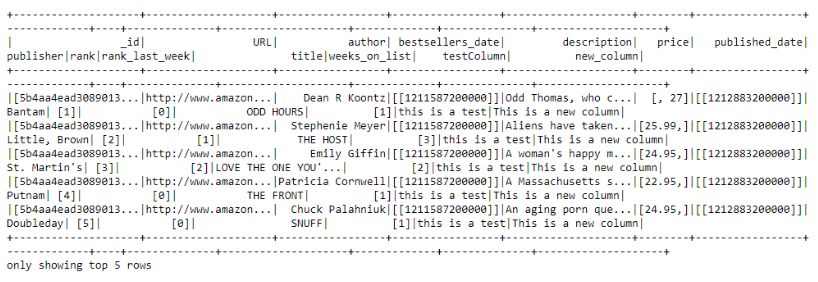
# Lit() is required while we are creating columns with exact
dataframe = dataframe.withColumn('new_column',
F.lit('This is a new column'))
![]()
对于新版DataFrame API,withColumnRenamed()函数通过两个参数使用。
# Update column 'amazon_product_url' with 'URL'
dataframe = dataframe.withColumnRenamed('amazon_product_url', 'URL')
![]()
“Amazon_Product_URL”列名修改为“URL”
列的删除可通过两种方式实现:在drop()函数中添加一个组列名,或在drop函数中指出具体的列。两个例子展示如下。
dataframe_remove = dataframe.drop("publisher",
"published_date").show(5)
dataframe_remove2=dataframe \
.drop(dataframe.publisher).drop(dataframe.published_date).show(5)
![]()
“publisher”和“published_date”列用两种不同的方法移除。
存在几种类型的函数来进行数据审阅。接下来,你可以找到一些常用函数。想了解更多则需访问Apache Spark doc。
# Returns dataframe column names and data types
# Displays the content of dataframe
# Computes summary statistics
dataframe.describe().show()
# Returns columns of dataframe
# Counts the number of rows in dataframe
# Counts the number of distinct rows in dataframe
dataframe.distinct().count()
# Prints plans including physical and logical
通过GroupBy()函数,将数据列根据指定函数进行聚合。
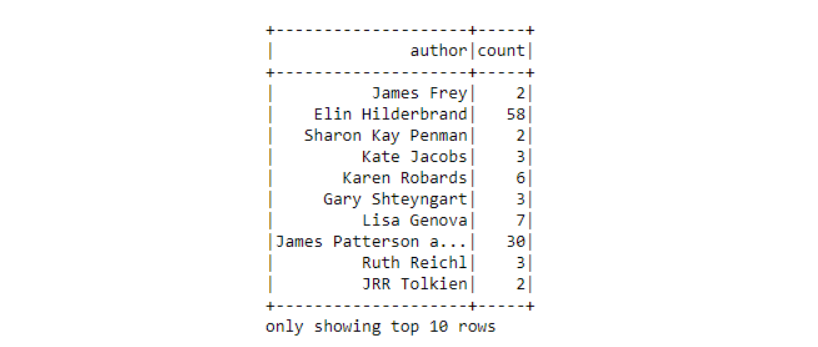
# Group by author, count the books of the authors in the groups
dataframe.groupBy("author").count().show(10)
![]()
通过使用filter()函数,在函数内添加条件参数应用筛选。这个函数区分大小写。
# Filtering entries of title
# Only keeps records having value 'THE HOST'
dataframe.filter(dataframe["title"] == 'THE HOST').show(5)
![]()
标题列经筛选后仅存在有“THE HOST”的内容,并显示5个结果。
对每个数据集,经常需要在数据预处理阶段将已存在的值替换,丢弃不必要的列,并填充缺失值。
pyspark.sql.DataFrameNaFunction
库帮助我们在这一方面处理数据。举例如下。
dataFrameNaFunctions.fill()
# Returning new dataframe restricting rows with null valuesdataframe.na.drop()
dataFrameNaFunctions.drop()
# Return new dataframe replacing one value with another
dataframe.na.replace(5, 15)
dataFrameNaFunctions.replace()
在RDD(弹性分布数据集)中增加或减少现有分区的级别是可行的。使用repartition(self,numPartitions)可以实现分区增加,这使得新的RDD获得相同/更高的分区数。分区缩减可以用coalesce(self, numPartitions, shuffle=False)函数进行处理,这使得新的RDD有一个减少了的分区数(它是一个确定的值)。请访问
Apache Spark doc
获得更多信息。
# Dataframe with 10 partitions
dataframe.repartition(10).rdd.getNumPartitions()
# Dataframe with 1 partition
dataframe.coalesce(1).rdd.getNumPartitions()
原始SQL查询也可通过在我们SparkSession中的“sql”操作来使用,这种SQL查询的运行是嵌入式的,返回一个DataFrame格式的结果集。请访问
Apache Spark doc
获得更详细的信息。
dataframe.registerTempTable("df")
sc.sql("select * from df").show(3)
CASE WHEN description LIKE '%love%' THEN 'Love_Theme' \
WHEN description LIKE '%hate%' THEN 'Hate_Theme' \
WHEN description LIKE '%happy%' THEN 'Happiness_Theme' \
WHEN description LIKE '%anger%' THEN 'Anger_Theme' \
WHEN description LIKE '%horror%' THEN 'Horror_Theme' \
WHEN description LIKE '%death%' THEN 'Criminal_Theme' \
WHEN description LIKE '%detective%' THEN 'Mystery_Theme' \
ELSE 'Other_Themes' \ END Themes \
from df").groupBy('Themes').count().show()
DataFrame API以RDD作为基础,把SQL查询语句转换为低层的RDD函数。通过使用.rdd操作,一个数据框架可被转换为RDD,也可以把Spark Dataframe转换为RDD和Pandas格式的字符串同样可行。
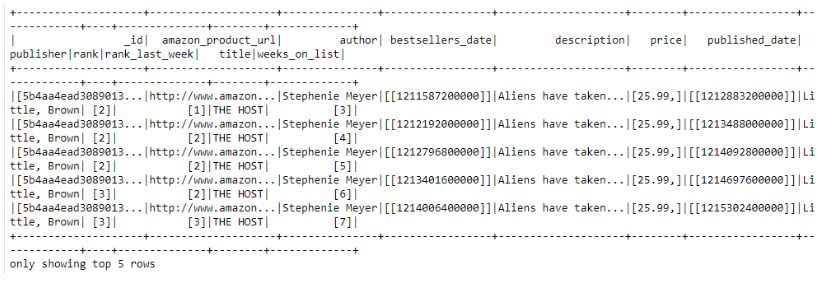
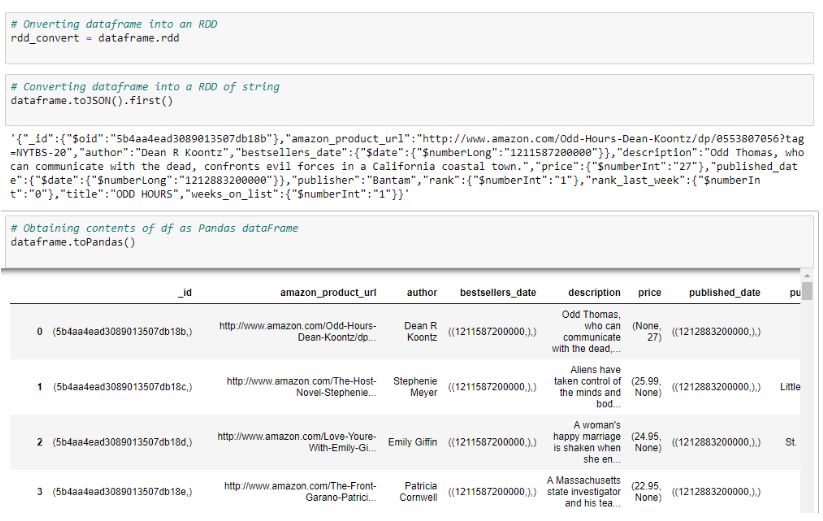
# Converting dataframe into an RDD
rdd_convert = dataframe.rdd
# Converting dataframe into a RDD of string
dataframe.toJSON().first()
# Obtaining contents of df as Pandas
dataFramedataframe.toPandas()
![]()
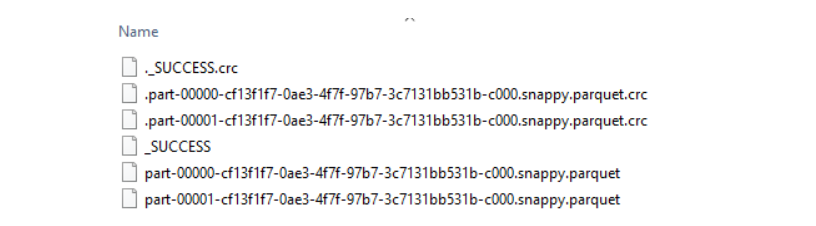
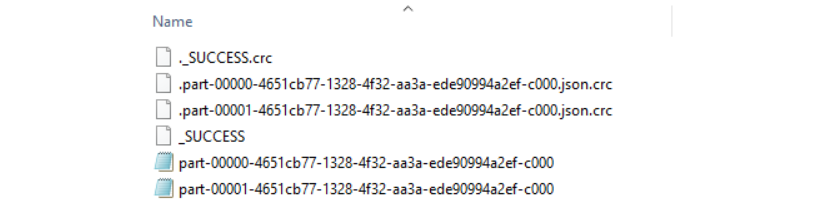
任何像数据框架一样可以加载进入我们代码的数据源类型都可以被轻易转换和保存在其他类型文件中,包括.parquet和.json。请访问Apache Spark doc寻求更多保存、加载、写函数的细节。
# Write & Save File in .parquet format
dataframe.select("author", "title", "rank", "description") \
.save("Rankings_Descriptions.parquet")
![]()
当.write.save()函数被处理时,可看到Parquet文件已创建。
# Write & Save File in .json format
dataframe.select("author", "title") \
.save("Authors_Titles.json",format="json")
![]()
当.write.save()函数被处理时,可看到JSON文件已创建。
Spark会话可以通过运行stop()函数被停止,如下。
代码和Jupyter Notebook可以在我的GitHub上找到。
1. http://spark.apache.org/docs/latest/
2. https://docs.anaconda.com/anaconda/
PySpark and SparkSQL Basics
How to implement Spark with Python Programming
https://towardsdatascience.com/pyspark-and-sparksql-basics-6cb4bf967e53
编辑:于腾凯
校对:洪舒越
孙韬淳,首都师范大学大四在读,主修遥感科学与技术。目前专注于基本知识的掌握和提升,期望在未来有机会探索数据科学在地学应用的众多可能性。爱好之一为翻译创作,在业余时间加入到THU数据派平台的翻译志愿者小组,希望能和大家一起交流分享,共同进步。
——END——
![]()
![]()