偷偷潜入大佬的技术交流群,冒死曝光三千字硬核聊天记录


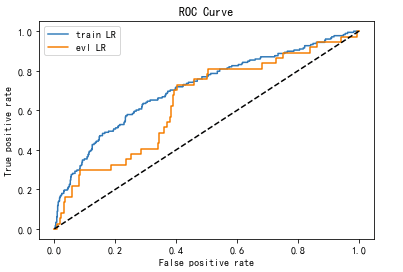
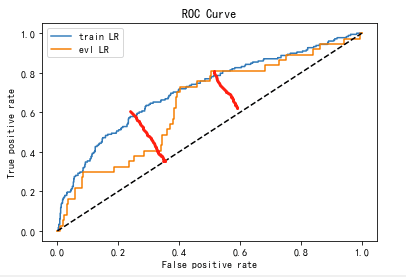

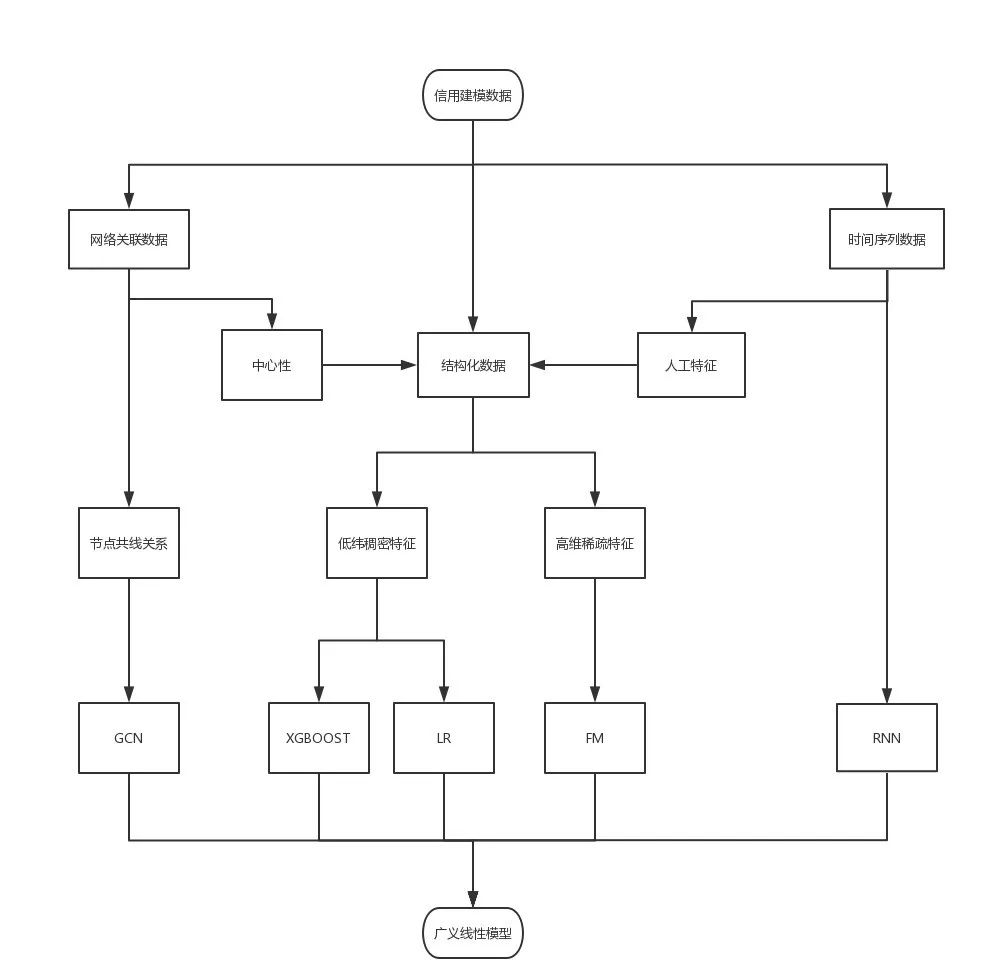
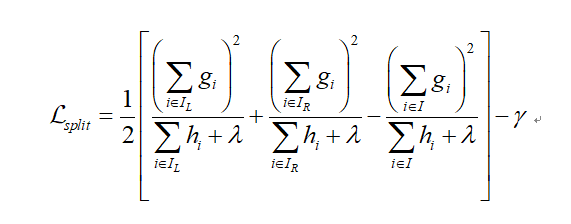






登录查看更多
相关内容
Arxiv
8+阅读 · 2019年11月4日


相关VIP内容
相关资讯
相关论文
Arxiv
8+阅读 · 2019年11月4日