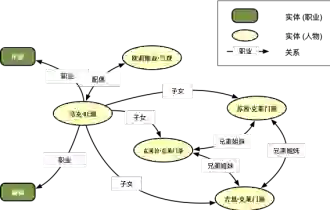
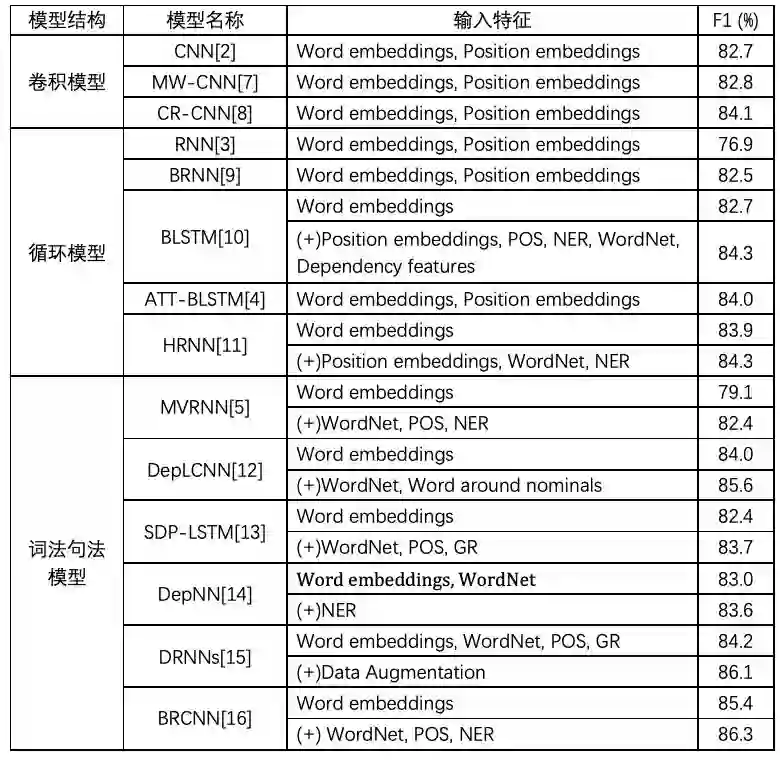
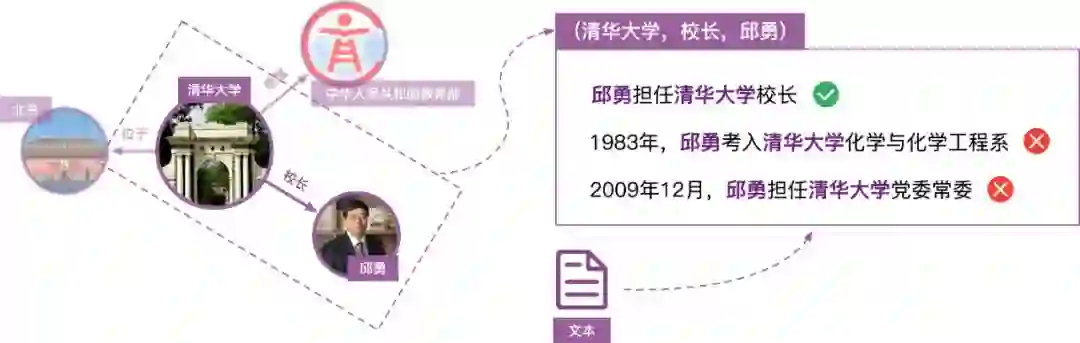
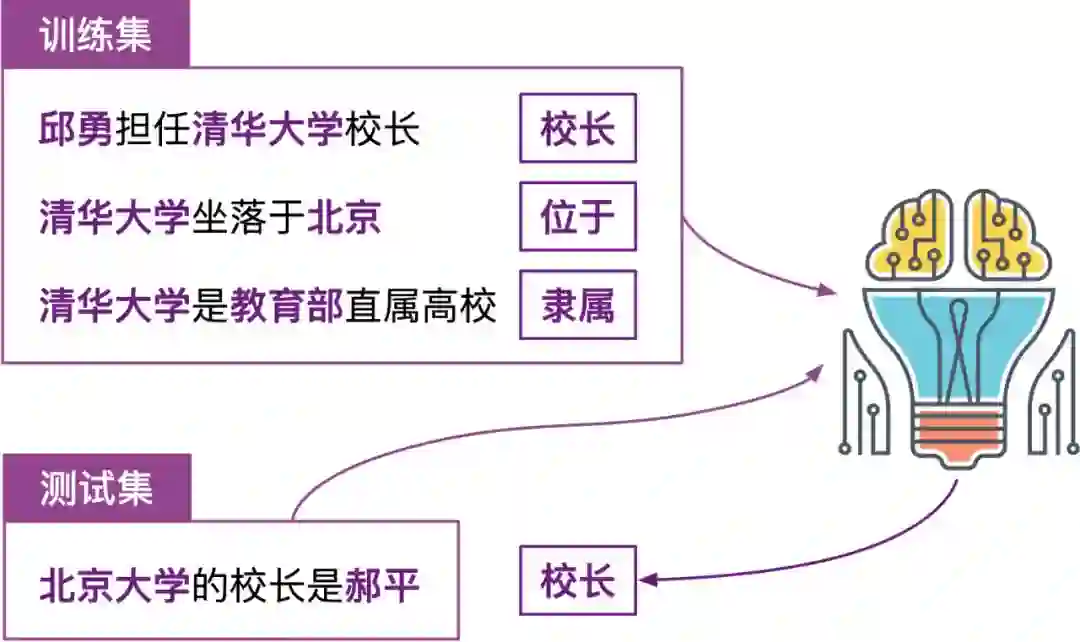
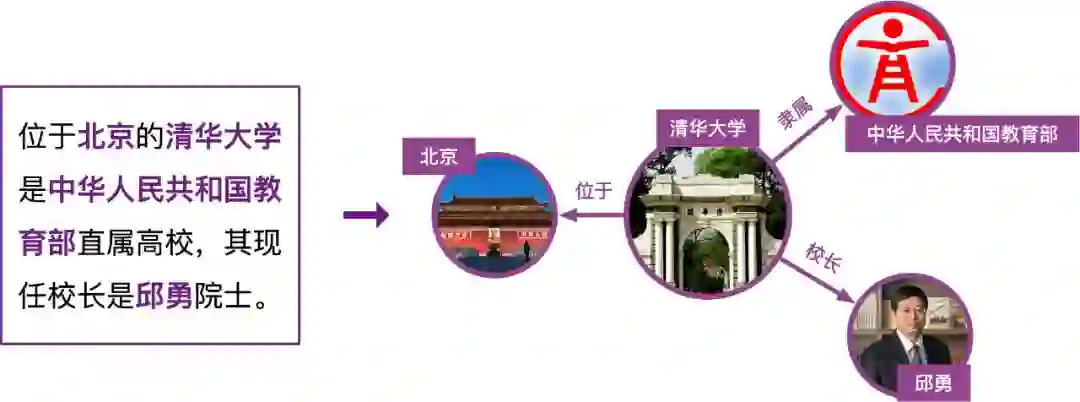
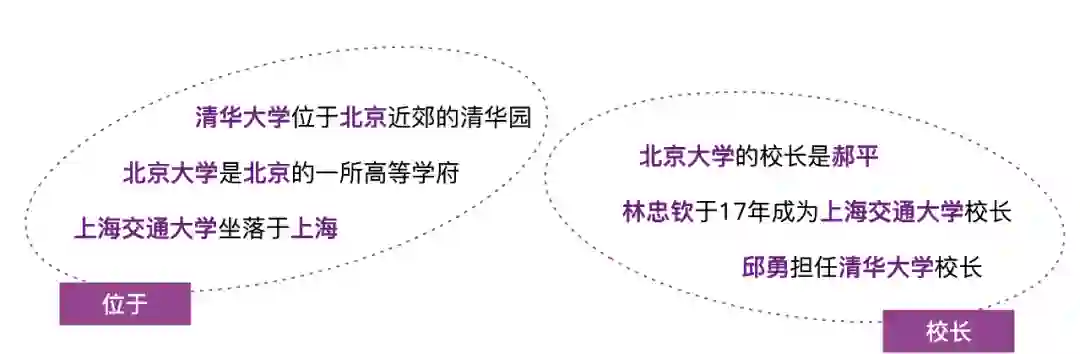
上下滑动查看
参考文献:
[1] ChunYang Liu, WenBo Sun, WenHan Chao, Wanxiang Che. Convolution Neural Network for Relation Extraction. The 9th International Conference on Advanced Data Mining and Applications (ADMA 2013).
[2] Daojian Zeng, Kang Liu, Siwei Lai, Guangyou Zhou, Jun Zhao. Relation Classification via Convolutional Deep Neural Network. The 25th International Conference on Computational Linguistics (COLING 2014).
[3] Dongxu Zhang, Dong Wang. Relation Classification via Recurrent Neural Network. arXiv preprint arXiv:1508.01006 (2015).
[4] Peng Zhou, Wei Shi, Jun Tian, Zhenyu Qi, Bingchen Li, Hongwei Hao, Bo Xu. Attention-Based Bidirectional Long Short-Term Memory Networks for Relation Classification. The 54th Annual Meeting of the Association for Computational Linguistics (ACL 2016).
[5] Richard Socher, Brody Huval, Christopher D. Manning, Andrew Y. Ng. Semantic Compositionality through Recursive Matrix-Vector Spaces. The 2012 Joint Conference on Empirical Methods in Natural Language Processing and Computational Natural Language Learning (EMNLP-CoNLL 2012).
[6] Iris Hendrickx, Su Nam Kim, Zornitsa Kozareva, Preslav Nakov, Diarmuid Ó Séaghdha, Sebastian Padó, Marco Pennacchiotti, Lorenza Romano, Stan Szpakowicz. SemEval-2010 Task 8: Multi-Way Classification of Semantic Relations between Pairs of Nominals. The 5th International Workshop on Semantic Evaluation (SEMEVAL 2010).
[7] Thien Huu Nguyen, Ralph Grishman. Relation Extraction: Perspective from Convolutional Neural Networks. The 1st Workshop on Vector Space Modeling for Natural Language Processing (LatentVar 2015).
[8] Cícero dos Santos, Bing Xiang, Bowen Zhou. Classifying Relations by Ranking with Convolutional Neural Networks. The 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (ACL-IJCNLP 2015).
[9] Shu Zhang, Dequan Zheng, Xinchen Hu, Ming Yang. Bidirectional Long Short-Term Memory Networks for Relation Classification. The 29th Pacific Asia Conference on Language, Information and Computation (PACLIC 2015).
[10] Minguang Xiao, Cong Liu. Semantic Relation Classification via Hierarchical Recurrent Neural Network with Attention. The 26th International Conference on Computational Linguistics (COLING 2016).
[11] Kun Xu, Yansong Feng, Songfang Huang, Dongyan Zhao. Semantic Relation Classification via Convolutional Neural Networks with Simple Negative Sampling. The 2015 Conference on Empirical Methods in Natural Language Processing (EMNLP 2015).
[12] Yan Xu, Lili Mou, Ge Li, Yunchuan Chen, Hao Peng, Zhi Jin. Classifying Relations via Long Short Term Memory Networks along Shortest Dependency Paths. The 2015 Conference on Empirical Methods in Natural Language Processing (EMNLP 2015).
[13] Yang Liu, Furu Wei, Sujian Li, Heng Ji, Ming Zhou, Houfeng Wang. A Dependency-Based Neural Network for Relation Classification. The 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing (ACL-IJCNLP 2015).
[14] Yan Xu, Ran Jia, Lili Mou, Ge Li, Yunchuan Chen, Yangyang Lu, Zhi Jin. Improved Relation Classification by Deep Recurrent Neural Networks with Data Augmentation. The 26th International Conference on Computational Linguistics (COLING 2016).
[15] Rui Cai, Xiaodong Zhang, Houfeng Wang. Bidirectional Recurrent Convolutional Neural Network for Relation Classification. The 54th Annual Meeting of the Association for Computational Linguistics (ACL 2016).
[16] Mike Mintz, Steven Bills, Rion Snow, Daniel Jurafsky. Distant Supervision for Relation Extraction without Labeled Data. The 47th Annual Meeting of the Association for Computational Linguistics and the 4th International Joint Conference on Natural Language Processing (ACL-IJCNLP 2009).
[17] Daojian Zeng, Kang Liu, Yubo Chen, Jun Zhao. Distant Supervision for Relation Extraction via Piecewise Convolutional Neural Networks. The 2015 Conference on Empirical Methods in Natural Language Processing (EMNLP 2015).
[18] Yankai Lin, Shiqi Shen, Zhiyuan Liu, Huanbo Luan, Maosong Sun. Neural Relation Extraction with Selective Attention over Instances. The 54th Annual Meeting of the Association for Computational Linguistics (ACL 2016).
[19] Yi Wu, David Bamman, Stuart Russell. Adversarial Training for Relation Extraction. The 2017 Conference on Empirical Methods in Natural Language Processing (EMNLP 2017).
[20] Jun Feng, Minlie Huang, Li Zhao, Yang Yang, Xiaoyan Zhu. Reinforcement Learning for Relation Classification from Noisy Data. The 32th AAAI Conference on Artificial Intelligence (AAAI 2018).
[21] Xu Han, Hao Zhu, Pengfei Yu, Ziyun Wang, Yuan Yao, Zhiyuan Liu, Maosong Sun. FewRel: A Large-Scale Supervised Few-Shot Relation Classification Dataset with State-of-the-Art Evaluation. The 2018 Conference on Empirical Methods in Natural Language Processing (EMNLP 2018).
[22] Tianyu Gao, Xu Han, Zhiyuan Liu, Maosong Sun. Hybrid Attention-based Prototypical Networks for Noisy Few-Shot Relation Classification. The 33th AAAI Conference on Artificial Intelligence (AAAI 2019).
[23] Zhi-Xiu Ye, Zhen-Hua Ling. Multi-Level Matching and Aggregation Network for Few-Shot Relation Classification. The 57th Annual Meeting of the Association for Computational Linguistics (ACL 2019).
[24] Livio Baldini Soares, Nicholas FitzGerald, Jeffrey Ling, Tom Kwiatkowski. Matching the Blanks: Distributional Similarity for Relation Learning. The 57th Annual Meeting of the Association for Computational Linguistics (ACL 2019).
[25] Tianyu Gao, Xu Han, Hao Zhu, Zhiyuan Liu, Peng Li, Maosong Sun, Jie Zhou. FewRel 2.0: Towards More Challenging Few-Shot Relation Classification. 2019 Conference on Empirical Methods in Natural Language Processing and 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP 2019).
[26] Chris Quirk, Hoifung Poon. Distant Supervision for Relation Extraction beyond the Sentence Boundary. The 15th Conference of the European Chapter of the Association for Computational Linguistics (EACL 2017).
[27] Nanyun Peng, Hoifung Poon, Chris Quirk, Kristina Toutanova, Wen-tau Yih. Cross-Sentence N-ary Relation Extraction with Graph LSTMs. Transactions of the Association for Computational Linguistics (TACL 2017).
[28] Chih-Hsuan Wei, Yifan Peng, Robert Leaman, Allan Peter Davis, Carolyn J. Mattingly, Jiao Li, Thomas C. Wiegers, Zhiyong Lu. Overview of the BioCreative V Chemical Disease Relation (CDR) Task. The 5th BioCreative Challenge Evaluation Workshop (BioC 2015).
[29] Omer Levy, Minjoon Seo, Eunsol Choi, Luke Zettlemoyer. Zero-Shot Relation Extraction via Reading Comprehension. The 21st Conference on Computational Natural Language Learning (CoNLL 2017).
[30] Yuan Yao, Deming Ye, Peng Li, Xu Han, Yankai Lin, Zhenghao Liu, Zhiyuan Liu, Lixin Huang, Jie Zhou, Maosong Sun. DocRED: A Large-Scale Document-Level Relation Extraction Dataset. The 57th Annual Meeting of the Association for Computational Linguistics (ACL 2019).
[31] Ruidong Wu, Yuan Yao, Xu Han, Ruobing Xie, Zhiyuan Liu, Fen Lin, Leyu Lin, Maosong Sun. Open Relation Extraction: Relational Knowledge Transfer from Supervised Data to Unsupervised Data. 2019 Conference on Empirical Methods in Natural Language Processing and 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP 2019).
[32] Tianyu Gao, Xu Han, Ruobing Xie, Zhiyuan Liu, Fen Lin, Leyu Lin, Maosong Sun. Neural Snowball for Few-Shot Relation Learning. The 34th AAAI Conference on Artificial Intelligence (AAAI 2020).
[33] Xu Han, Tianyu Gao, Yuan Yao, Deming Ye, Zhiyuan Liu, Maosong Sun. OpenNRE: An Open and Extensible Toolkit for Neural Relation Extraction. The Conference on Empirical Methods in Natural Language Processing (EMNLP 2019).