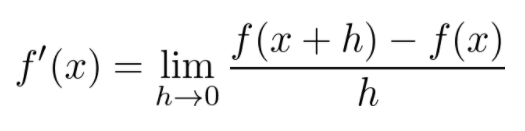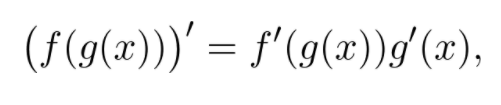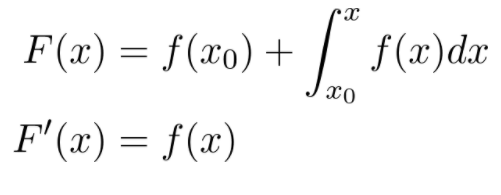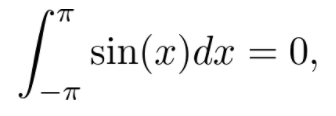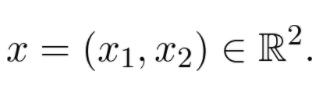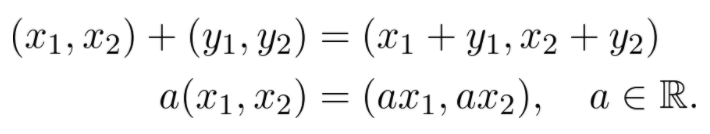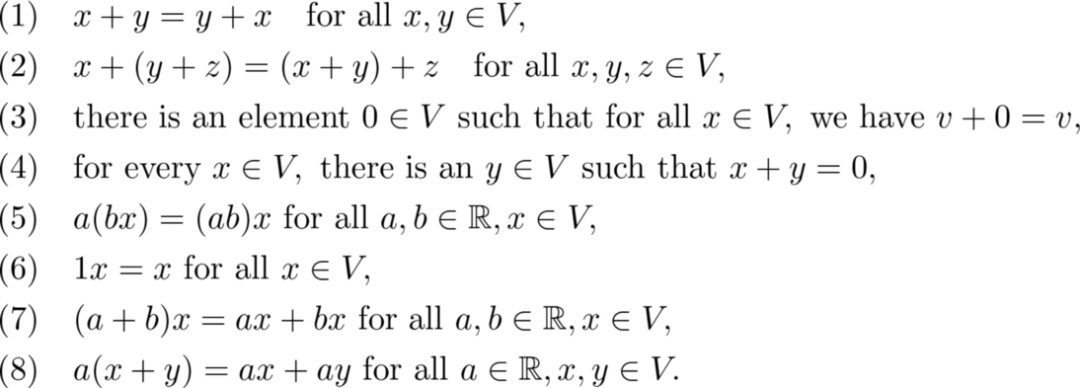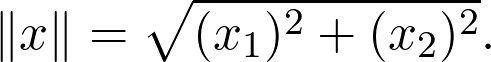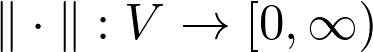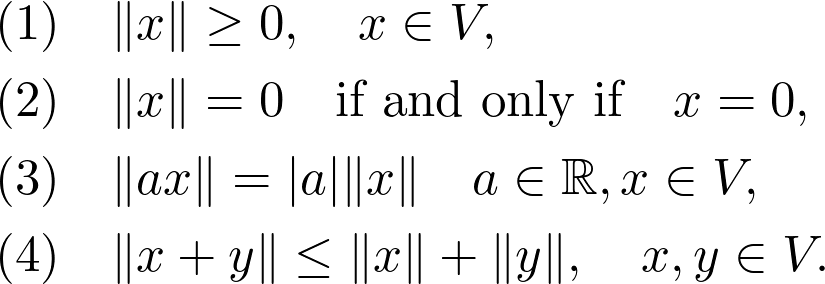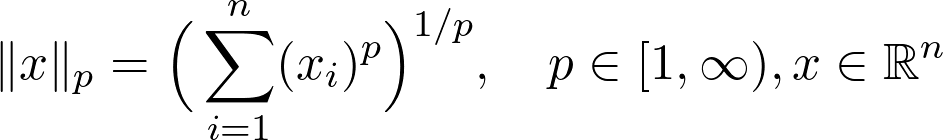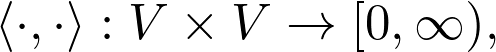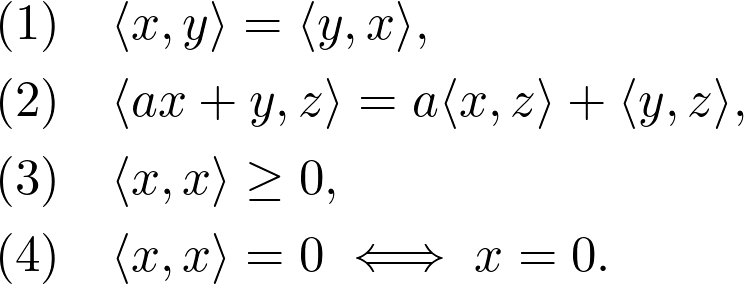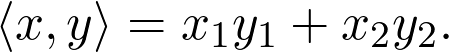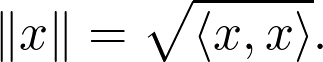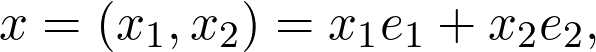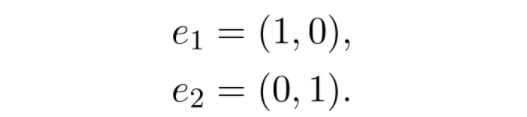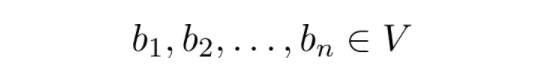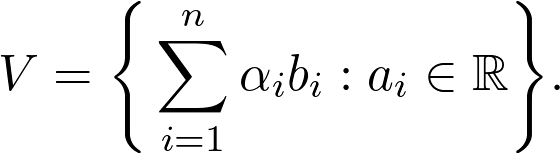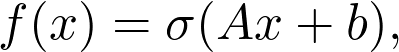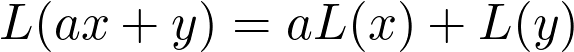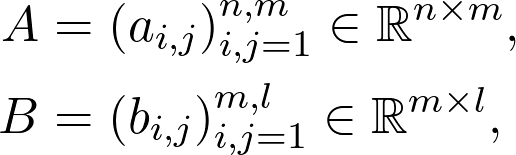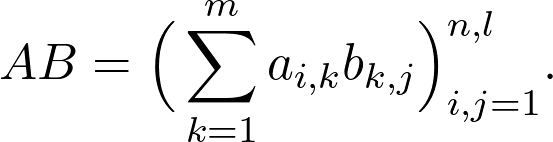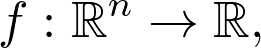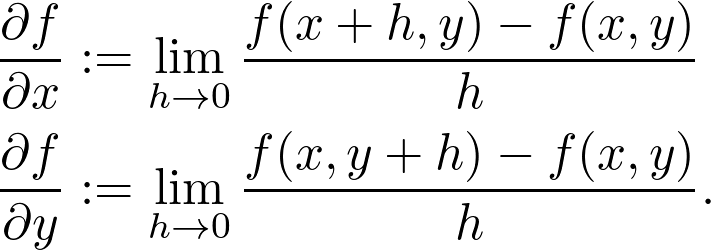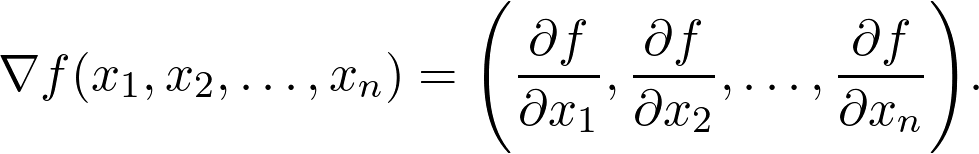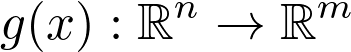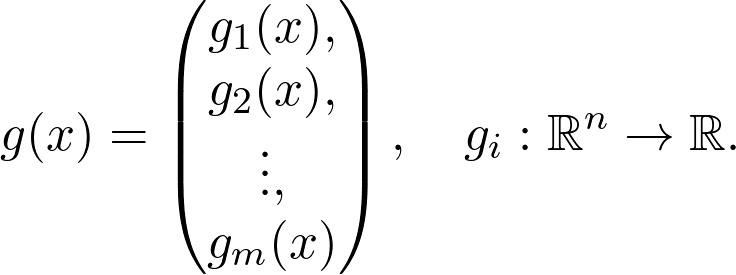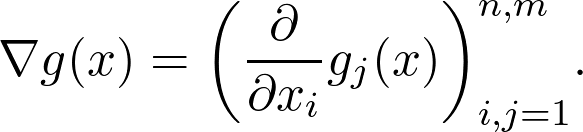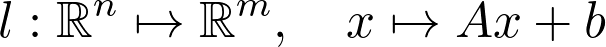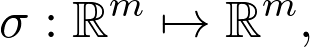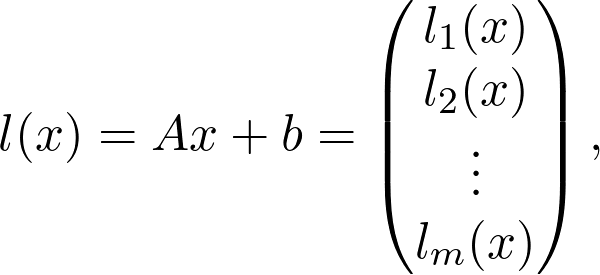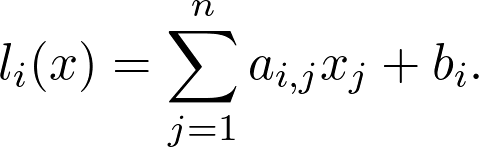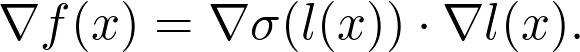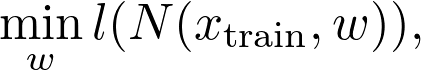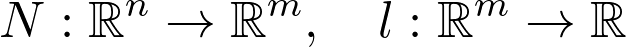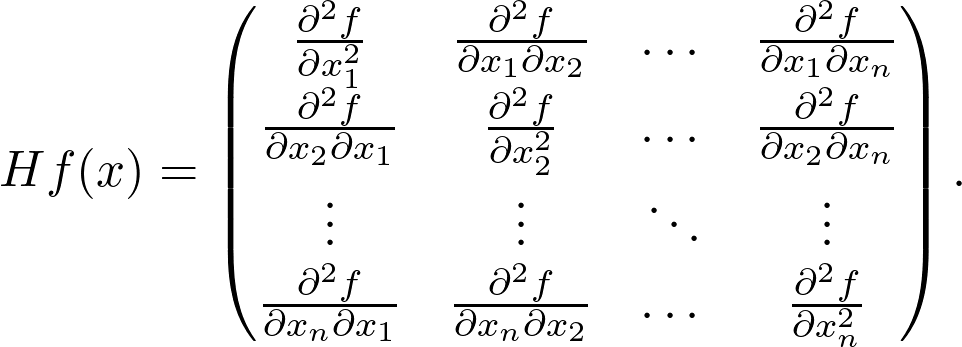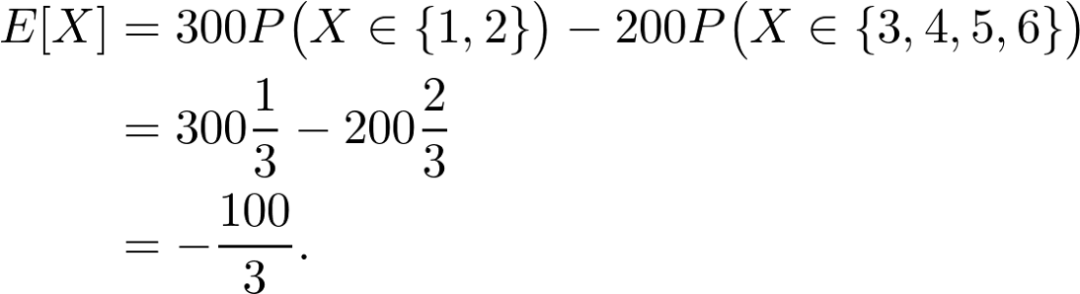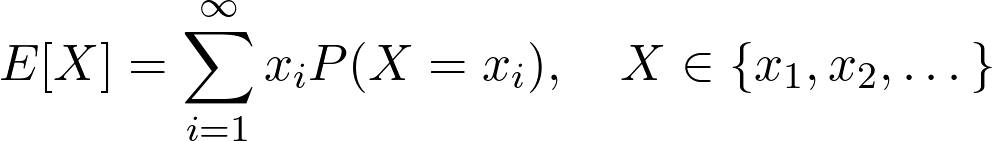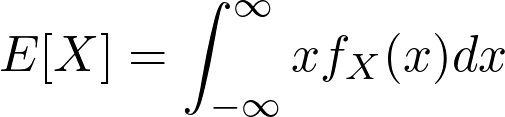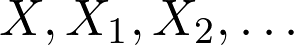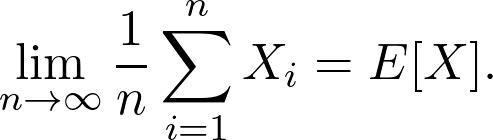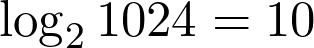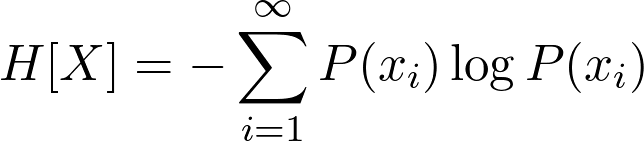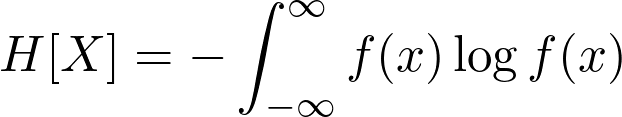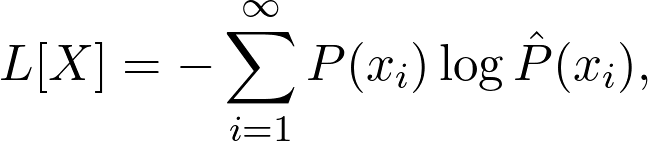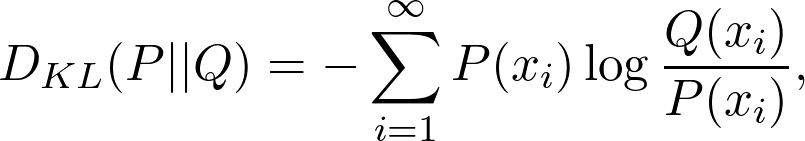点击上方“计算机视觉life”,选择“星标”
快速获得最新干货
本文转自机器之心
大学时期学的数学现在可能派上用场了,机器学习背后的原理涉及许多数学知识。深入挖掘一下,你会发现,线性代数、微积分和概率论等都和机器学习背后的算法息息相关。
![]()
机器学习算法背后的数学知识你了解吗?在构建模型的过程中,如果想超越其基准性能,那么熟悉基本细节可能会大有帮助,尤其是在想要打破 SOTA 性能时,尤其如此。
机器学习背后的原理往往涉及高等数学。例如,随机梯度下降算法建立在多变量微积分和概率论的基础上。因此掌握基础的数学理论对于理解机器学习模型很重要。但如果你是没有数学基础的初学者,这里有一份学习路线图,带你从零开始深入理解神经网络的数学原理。
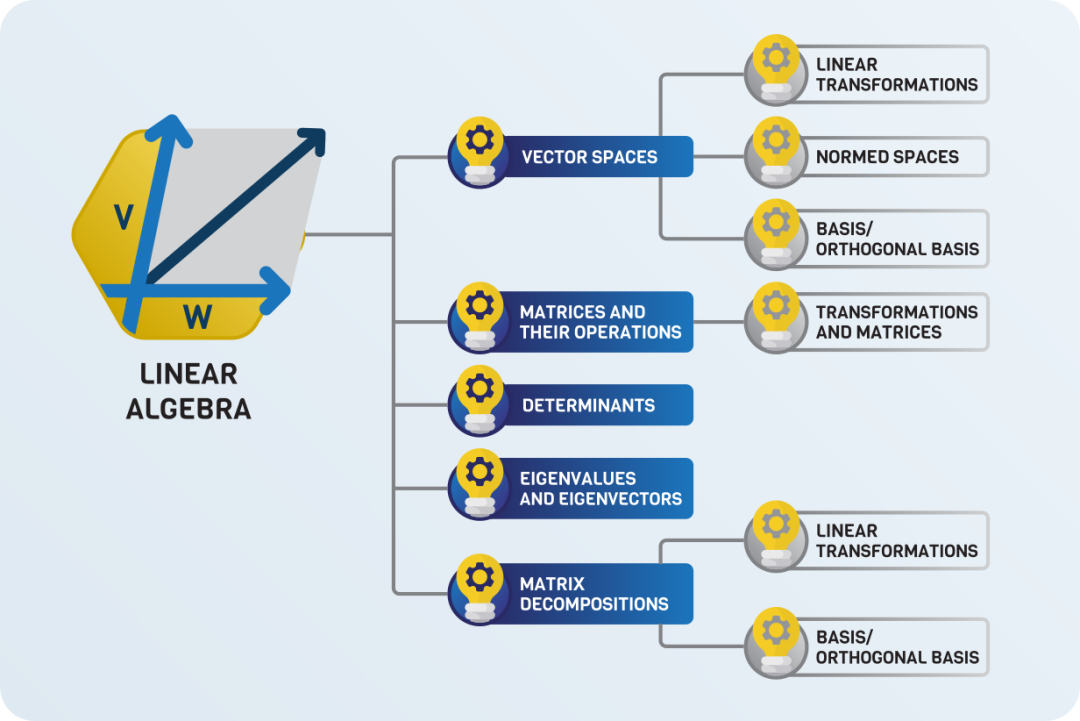
大多数机器学习都建立在三种数学理论的基础上:线性代数、微积分和概率论,其中概率论的理论又基于线性代数和微积分
。
![]()
微积分包括函数的微分和积分。神经网络本质上是一个可微函数,因此微积分是训练神经网络的基本工具。
![]()
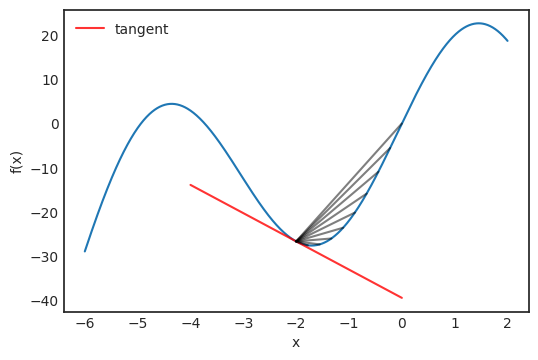
在极限定理中,这也是点 x 处切线的斜率。下图说明了这个概念:
![]()
微分可以用来优化函数:导数在局部极大值和极小值处为零。(也有例外,例如:f(x) = x³,x=0),导数为零的点称为临界点。临界点是最小值还是最大值可以通过查看二阶导数来确定:
![]()
求导存在一些基本法则,其中最重要的可能是链式求导法则:
![]()
![]()
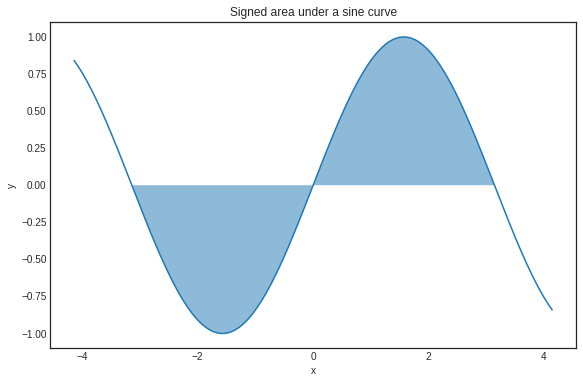
它适用于任何可积函数 f(x)。函数的积分也可以看作是曲线下的有符号面积。例如:
![]()
![]()
在 -π到π的区间内,正弦函数曲线下的有符号面积。
推荐一些比较好的学习资源,麻省理工学院的单变量微积分课程和 Gilbert Strang 的教科书。
![]()
神经网络本质上是函数,它是用微积分工具训练的。然而,又涉及线性代数,如矩阵乘法。线性代数是一门涉及机器学习许多方面的庞大学科,因此这将是一个重要的部分。
为了更好地理解线性代数,建议从向量空间开始。首先介绍一个特例,把平面上的每个点看作一个元组:
![]()
这些本质上是从零指向(x₁,x2)的向量。向量之间可以相加,向量也可与标量相乘:
![]()
这是向量空间的原型模型。一般来说,如果可以将向量相加并将向量与实数相乘,那么这组向量 V 就是实数上的向量空间,那么以下属性成立:
![]()
这些保证了向量可以相加和缩放。当考虑向量空间时,如果你在心里把它们建模为 R^2 会很有帮助。
如果你很了解向量空间,下一步就是理解怎样测量向量的大小。在默认情况下,向量空间本身并没有提供这样的工具。但我们有:
![]()
这是一种特殊的范数,通常,如果存在函数,则向量空间 V 是范数的:
![]()
![]()
但这是一个简单而基本的概念,有很多范数存在,但最重要的是 p 范数家族:
![]()
![]()
有时,例如对于 p = 2,范数来自所谓的内积,即双线性函数。
![]()
![]()
具有内积的向量空间称为内积空间。经典的是欧几里得积。
![]()
![]()
虽然向量空间是无穷的(在本文的例子中),你可以找到一个有限的向量集,用来表示空间中的所有向量。例如,在平面上,我们有:
![]()
![]()
这是基和正交基的一个特例。一般来说,基(basis)是向量的最小集合:
![]()
![]()
任何向量空间都存在一个基(它可能不是一个有限集,但这里不必关心)。毫无疑问,在讨论线性空间时,基大大简化了问题。
当基中的向量相互正交时,我们称之为正交基(orthogonal basis)。如果每个正交向量的范数在正交基础上均为 1,则我们说它是正交的。
与向量空间非常相关的是线性变换(linear transformation)。如果你之前了解神经网络,就应该知道其基本的构建基块是以下形式的层:
![]()
其中,A 为矩阵,b 和 x 为向量,σ为 sigmoid 函数(或是其他激活函数)。Ax 是线性变换的一部分,则函数:
![]()
![]()
对于 V 中的所有 x、y 值都成立,而且都是实数。
矩阵最重要的运算是矩阵乘积。通常,矩阵 A、B 以及乘积 AB 表示为:
![]()
![]()
![]()
矩阵乘法是线性变换的组合。如果你想了解更多,这里有一篇很棒的文章:https://towardsdatascience.com/why-is-linear-algebra-taught-so-badly-5c215710ca2c
![]()
行列式是线性代数中最具挑战性的概念之一。要了解这一概念,请观看下面的视频。
总而言之,矩阵的行列式描述了在相应的线性变换下,对象的体积是如何缩放的。如果变换改变方向,行列式的符号为负。
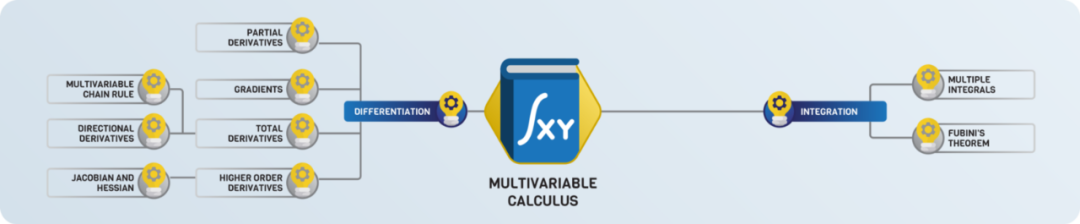
标准的线性代数课程通常以特征值 / 特征向量和一些特殊的矩阵分解(如奇异值分解)结束。假设我们有一个矩阵 A,并且如果有一个向量 x(称为特征向量),那么λ就是矩阵 A 的特征值:
![]()
换句话说,由 A 表示的线性变换对向量 x 进行一个λ缩放,这个概念在线性代数中起着重要作用(实际上在广泛使用线性代数的每个领域都是如此)。
你需要熟悉矩阵分解,从计算的角度来看,对角矩阵是最好的选择,如果一个线性变换有一个对角矩阵,那么计算它在任意向量上的值是很简单的。
![]()
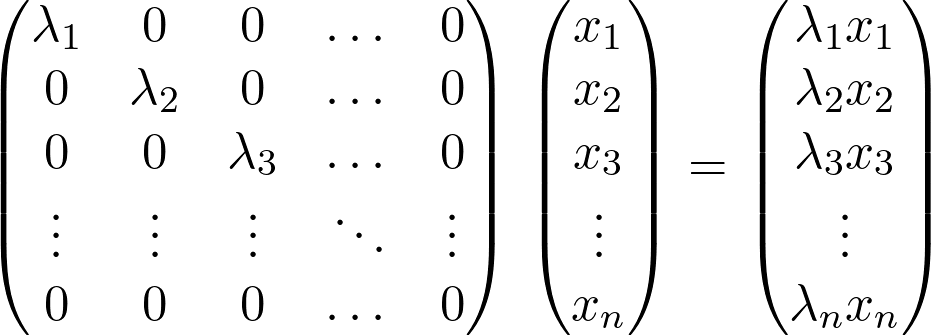
大多数特殊形式的目的是将矩阵 A 分解为矩阵乘积,矩阵分解后最好有一个是对角矩阵。奇异值分解(SVD),是指有一个特殊的矩阵 U 和一个对角矩阵Σ,使得:
![]()
U 和 V 是酉矩阵,是一个特殊的矩阵族。奇异值分解(SVD)也被用来进行主成分分析,这是最简单和最著名的降维方法之一。
线性代数有许多教授方法,本文列出的学习路径是受 Sheldon Axler 教材《Linear Algebra Done Right》的启发。对于在线讲座,MIT 的网络公开课值得推荐。
![]()
多变量运算中将线性代数和微积分结合在一起,为训练神经网络的主要工具奠定了基础。从数学上讲,神经网络只是多个变量的函数(尽管变量数量可达数百万)。
与单变量运算相似,两个重点是微分和积分。假设存在映射:
![]()
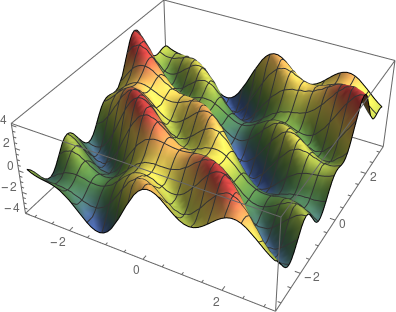
将向量映射到实数。在二维(即 n=2)的情况下,可以将其图象想象为一个曲面(由于人类生活在三维世界,因此很难将具有两个以上变量的函数可视化)。
![]()
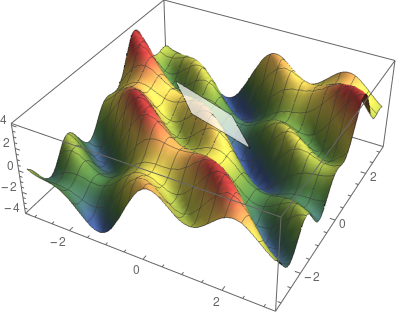
在单变量中,导数是切线的斜率。那么在此应该如何定义切线呢?表面上的一个点处不只有一条切线,而是多条。这些切线中有两条特殊的切线:分别为平行于 x-z 平面的切线和平行于 y-z 平面的切线。
![]()
![]()
![]()
梯度始终指向增加最快的方向,因此沿这个方向前进一小步,高度上的增加相对于其他方向是最大的。这就是梯度下降的基本思想,它是让函数最大化的算法。其步骤如下:
计算当前位置 x_0 处的梯度。
在梯度方向上走一小步即可到达点 x_1(步长称为学习率)。
返回步骤 1,重复该过程,直至收敛为止。
当然,这种算法也存在一些缺陷,多年来这些缺陷也得到了一些改善。基于现代梯度下降的优化器采用了许多技巧,例如自适应步长、动量等。
在实践中计算梯度是一件很困难的事,函数经常由其他函数的组成部分构成。例如,线性层:
![]()
其中 A 是矩阵,b 和 x 是矢量,σ是 sigmoid 函数(当然还有其他激活函数)。如何计算梯度?
![]()
![]()
g 的梯度由矩阵定义,该矩阵的第 k 行是第 k 个分量的梯度
![]()
![]()
![]()
![]()
定义中用到了单变量 sigmoid 分量。将函数进一步分解为从 n 维向量空间映射到实数空间的 m 个函数:
![]()
![]()
![]()
这是多元函数的链式规则,具有通用性。没有它就没有简单的方法来计算神经网络的梯度。而神经网络是许多函数的组合。
与单变量的情况类似,梯度和导数在确定空间中的给定点是局部极小值还是极大值方面(或者两者都不是)也起作用。
举一个具体的例子,训练神经网络等效于最小化参数训练数据上的损失函数。这就是找到最佳参数配置 w 的目的:
![]()
![]()
对于 n 个变量的通用可微分矢量 - 标量函数,存在 n^2 个二阶导数。形成 Hessian 矩阵。
![]()
在多变量的情况下,Hessian 的行列式充当二阶导数的角色。类似地,它还可以用来判断临界点(即所有导数均为零的情况)是最小值、最大值、鞍点中的哪一种。
![]()
概率论是将机率数学化的学科,它是所有科学领域的理论基础。
假设掷硬币,有 50%的概率(或 0.5 的概率)为正面。重复实验 10 次后,得到多少个正面?如果你回答了 5,你就错了。正面概率为 0.5 并不能保证每两次投掷都有一面是正面。相反,这意味着如果你重复实验 n 次,其中 n 是一个非常大的数字,那么正面的数量将非常接近 n/2。
为了更好的掌握概率论,推荐一篇文章:https://towardsdatascience.com/the-mathematical-foundations-of-probability-beb8d8426651
![]()
除了基础知识之外,你还需要了解一些高阶知识,首先是期望值和熵。
假设你和朋友玩游戏。你掷一个经典的六边形骰子,如果结果是 1 或 2,你将赢得 300 美元。否则,你就输 200 美元。如果你玩这个游戏的时间够长,你每轮的平均收入是多少?你应该玩这个游戏吗?
那么,你有 1/3 的概率赢 300 美元,2/3 的概率输 200 美元。也就是说,如果 X 是编码掷骰子结果的随机变量,那么:
![]()
通常来说,当用于离散型随机变量时,期望值定义如下:
![]()
![]()
在机器学习中,训练神经网络所用的损失函数在某种程度上是期望值。
人们常常错误地把某些现象归因于大数定律。例如,那些连输的赌徒相信,根据大数定律,他们很快就会赢。这是完全错误的。让我们看看这到底是什么。假如:
![]()
是代表同一实验中独立重复的随机变量 (例如,掷骰子或扔硬币)。
![]()
给出的一种解释是,如果一个随机事件重复了很多次,则单个结果可能无关紧要。因此,如果你在赌场玩一个期望值为负的游戏,那么偶尔也会赢。但大数定律意味着你会赔钱。
让我们玩个游戏。玩家心理想着 1-1024 的任意数字,然后你来猜。你可以问问题,但你的目标是使用尽可能少的问题。你需要多少问题?
如果你玩得很聪明,则可以使用二分搜索方法处理问题。首先你可能会问:这个数字在 1 和 512 之间吗?这样一来,搜索空间就减少了一半。使用此策略,你可以在
![]()
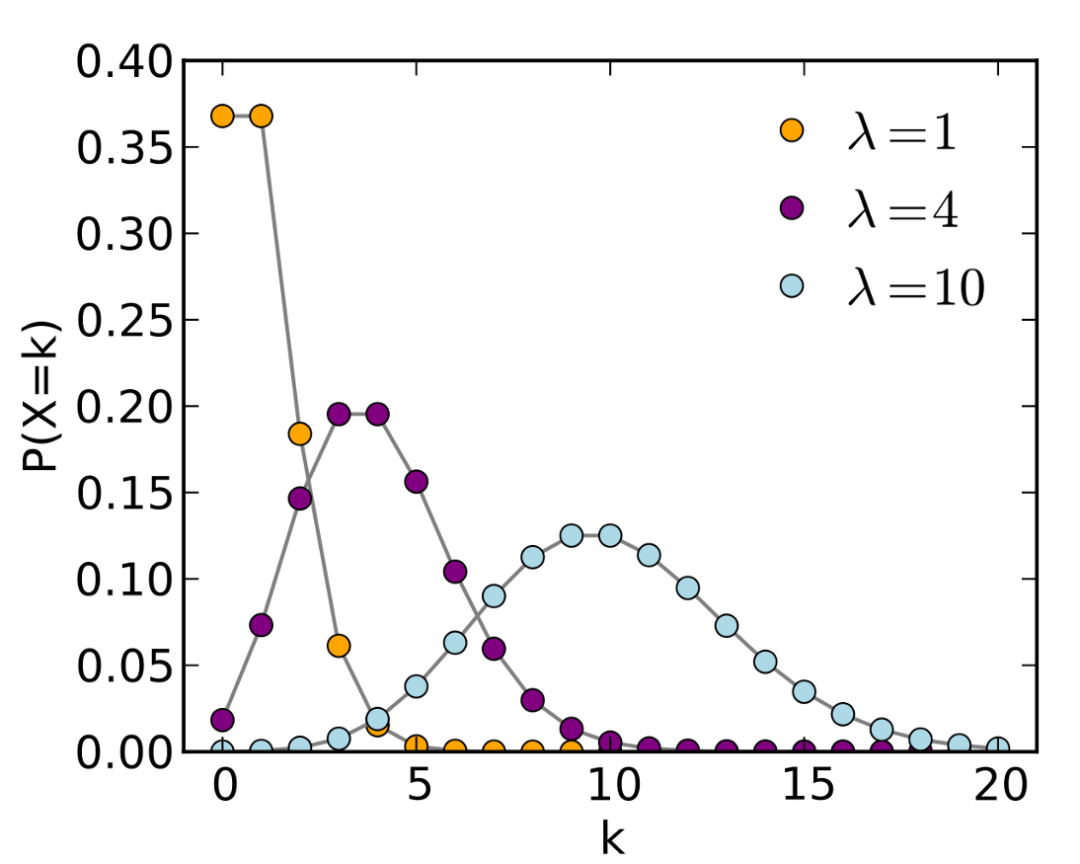
但是如果在选数字时没有使用均匀分布呢?例如,可以用泊松分布。
![]()
泊松分布的概率质量函数。图源:https://en.wikipedia.org/wiki/Poisson_distribution
使用泊松分布可能需要较少的问题,因为分布往往集中在特定的点上(这取决于参数)。
在极端情况下,当分布集中在一个数字上时,你不需要任何问题来猜它。一般来说,问题的数量取决于分布所携带的信息。均匀分布包含的信息量最少,而奇异分布是纯信息。
熵是一种量化的方法。当用于离散随机变量时,定义如下:
![]()
![]()
如果你以前使用过分类模型,可能会遇到交叉熵损失,定义如下:
![]()
其中 P 是真实值(集中到单个类的分布),而 P^ 表示类预测。这衡量了预测与实际情况相比有多少信息。当预测相匹配时,交叉熵损失为零。
另一个常用量是 Kullback-Leibler 散度(KL 散度),定义为:
![]()
其中 P 和 Q 是两个概率分布。这本质上是交叉熵减去熵,熵可以被认为是对两个分布的不同程度的量化。例如,在训练生成式对抗网络时,这是很有用的。最小化 KL 散度可以保证两个分布是相似的。
Pattern Recognition and Machine Learning by Christopher Bishop
The Elements of Statistical Learning by Trevor Hastie, Robert Tibshirani, and Jerome Friedman
基于此,我们回顾了理解神经网络所必需的数学知识。但是要真正理解神经网络是如何工作的,你还必须学习一些优化和数理统计。这些科目建立在数学的基础之上,在这就不进行介绍了。
原文链接:https://towardsdatascience.com/the-roadmap-of-mathematics-for-deep-learning-357b3db8569b
专辑:计算机视觉方向简介
专辑:视觉SLAM入门
专辑:最新SLAM/三维视觉论文/开源
专辑:三维视觉/SLAM公开课
专辑:深度相机原理及应用
专辑:手机双摄头技术解析与应用
专辑:相机标定
专辑:全景相机
交流群
欢迎加入公众号读者群一起和同行交流,目前有SLAM、三维视觉、传感器、自动驾驶、计算摄影、检测、分割、识别、医学影像、GAN、算法竞赛等微信群(以后会逐渐细分),请扫描下面微信号加群,备注:”昵称+学校/公司+研究方向“,例如:”张三 + 上海交大 + 视觉SLAM“。请按照格式备注,否则不予通过。添加成功后会根据研究方向邀请进入相关微信群。请勿在群内发送广告,否则会请出群,谢谢理解~
投稿、合作也欢迎联系:simiter@126.com
![]()
扫描关注视频号,看最新技术落地及开源方案视频秀 ↓
![]()