ECCV 2018 | 如何让RNN神经元拥有基础通用的注意力能力

编者按:循环神经网络(RNNs)是序列建模中被广泛使用的网络结构,它通过控制当前信息以及历史信息的贡献大小来实现序列信息的积累。RNN神经元将当前时刻的输入向量作为一个整体,通过门设计控制其信息载入到模型的信息量。然而,输入向量中的不同元素通常具有不同的重要性,RNNs忽略了对此重要属性的探索及利用以加强网络能力。
为此,微软亚洲研究院和西安交通大学合作,提出了通过对RNN层加入一个简单有效的元素注意力门,使得RNN神经元自身拥有基础通用的注意力能力,对不同的元素自适应地赋予不同的重要性来更加细粒度地控制输入信息流。该注意力门设计简单,并且通用于不同的RNN结构以及不同的任务。
循环神经网络(Recurrent Neural Networks, 缩写RNNs),例如标准RNN、LSTM、GRU等,已经被广泛用于对时间序列数据的处理和建模,来解决许多应用问题,例如行为识别、机器翻译、手写识别等。RNN在对时域动态特性建模以及特征学习上具有强大的能力。如图1所示,在每个时间步,RNN神经元通过当前时刻的输入x_t和前一时刻的隐状态信息h_(t-1)来更新当前时刻的隐状态h_t,从而具有对历史信息的记忆性。
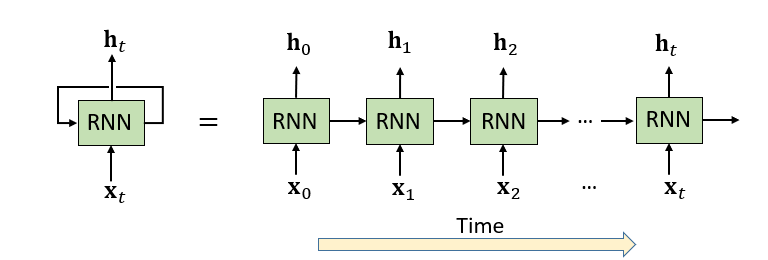
图1 RNN结构示意图及沿时域的展开表示
标准(Standard)RNN存在梯度消失的问题,因此在对长时(Long Range)依赖性建模中性能并不理想。LSTM(Long Short-Term Memory)、GRU(Gated Recurrent Unit)通过引入门(Gate)设计一定程度上减轻了梯度消失问题。门结构根据当前输入和隐状态信息来控制着对历史信息遗忘量,以及对当前输入信息接纳量,从而实现对历史和当前信息的有效利用。
对于一个RNN神经元,门可以视为一个整体的开关(标量)在控制当前或历史信息的流通。以某个LSTM神经元为例,在时刻t,内部单元的响应计算如下:
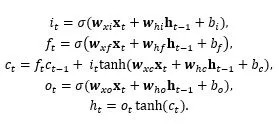
其中,x_t表示当前时刻t的输入向量,h_(t-1)表示t-1时刻的隐状态向量。i_t、f_t、o_t、c_t、h_t分别表示该LSTM神经元中的输入门、遗忘门、输出门、记忆单元和隐状态(输出)。w_aβ,b_β为模型参数,σ为Sigmoid激活函数。可以看到,遗忘门f_t影响着对历史信息,即存储在记忆单元c_(t-1)里的信息的保留程度。输入门i_t则影响着当前时刻信息x_t存储到记忆单元的量。
输入门作为当前时刻信息载入的开关(标量值),它并不能对当前时刻输入向量的不同元素进行自适应地调控,尽管输入向量的不同元素在许多任务中常有不同的重要性。因此现有LSTM缺少自我注意能力。同样的,标准RNN、GRU等其它RNN结构均存在相同的问题。
注意力(Attention)机制旨在有选择性地关注数据的不同部分,从而优化系统性能。在许多任务,例如机器翻译、自然语言处理、语音识别、图像描述生成等,已经显示了其有效性。注意力机制和人的感知机理比较一致。人在感知和理解世界时,并不是对每个细节都同等重要地去处理,而是通过关注某些显著性部分来实现效率的最大化。例如在嘈杂的环境下,人能通过听觉的注意力机制分辨出自己熟知的人的声音而忽略掉一些不关心的人的谈话。这是人类进化过程中形成的生存机制,能够利用有限的注意力资源从大量信息中筛选出高价值信息的手段。
针对不同的任务,人们设计了各种各样的注意力模型来提升系统的能力。在机器翻译中,通过注意力模型来利用邻近词上下文更好地对当前词进行翻译,即对邻域词及当前词做权重平均后作为RNN翻译网络当前时刻的输入。在图像描述任务中,图像被均匀地分成L部分,每一部分由提取的特征向量描述。为了使网络有选择性地、序列化地关注于一些对应语义部分来生成对应的描述,在每个时间步,注意力模型对L个部分赋予不同的权重以获得权重平均作为LSTM的输入。
在上述的这些工作中,注意力模型作为RNN额外的子网络,需要针对具体的任务来设计,目前并没有一种通用的设计,使RNN层自身具有注意力能力。近年来也有些对RNN结构设计的通用的改进,例如为了降低RNN网络训练的难度,Independently RNN(INdRNN)解除掉RNN同一层中的神经元之间的依赖性。
本文中,我们研究如何赋予一个通用的RNN层拥有细粒度注意力能力。对于一个RNN层,我们通过加入一个元素注意力门Element-wise-Attention Gate(EleAttG),使其对输入向量x_t的不同元素赋予不同的注意力权重。我们将带有EleAttG的RNN称为元素注意力RNN。如图2所示,元素注意力门根据当前时刻输入向量x_t和前一时刻隐状态h_(t-1)来决定输入向量不同元素的重要程度(Attention)a_t,并调制输入获得调制后的新输入(x_t) ̃ = a_t⨀x_t。
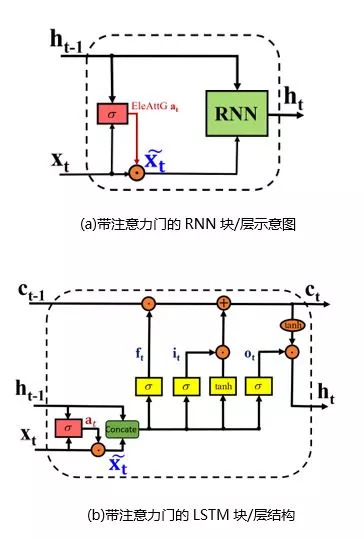
图2 拥有自注意能力的元素注意力RNN块/层的结构示意图。红色模块表示新加的元素注意力门。(a)展示了注意力门结构在RNN上的示意图,此RNN可以是标准RNN、LSTM或GRU;(b)给出了具体的带注意力门的LSTM层结构。注:一个RNN块/层可以由若干RNN神经元组成,例如N个。隐状态h_t的维度等于该层的神经元个数,即N。
以LSTM层为例,在时刻t,对于一个LSTM神经元内部单元的响应计算更新如下:
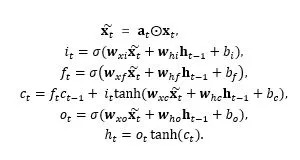
即(x_t) ̃取代原始输入x_t参与到RNN的循环运算。元素注意力门的响应向量由输入和隐状态决定:
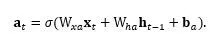
过去许多注意力设计工作中采用Softmax作为激活函数,从而使得注意力值的和为1。这样,在同一时刻,某个元素上的注意力值大小会受到其它元素上注意力值的影响。例如,沿着时间注意力稳定的一个元素因此会由于其他元素的改变而其稳定性被破坏。我们放宽了该限制,通过采用Sigmoid激活函数,保证了输入向量中某个元素的重要性不会由于其他元素的重要性值的改变而被迫改变,从而有更大优化空间。实验中我们发现放宽该约束可以显著地提升3D行为识别的性能。
元素注意力门的加入,使得RNN神经元拥有了注意能力。理论上讲,每个RNN神经元可以拥有自己的元素注意力门。为了减少计算复杂度和参数量,在我们的设计中,同一RNN层中的所有RNN神经元共享元素注意力门参数。
为了检验元素注意力RNN的高效性,我们在基于3D骨架(3D skeleton)数据的行为识别,以及基于RGB的行为识别上分别做了实验。
在基于3D骨架的人类行为识别的任务上,我们使用3个RNN层和一个全连层来搭建基准分类网络。每个RNN层由100个RNN神经元组成。作为比较,我们的方案将3个RNN层替换为3个元素注意力RNN层。
我们主要在NTU RGB+D数据库(简称NTU数据库)上进行实验分析。NTU是目前最大的Kinect采集的用于3D行为识别的数据库,包含56880个序列,由60类日常行为组成。骨架数据中,每个人由25个关节点组成。
在基于RGB帧的行为识别任务上,对于一个RGB帧,我们将CNN提出的特征向量作为RNN网络的一个时刻的输入来利用空时信息进行序列分类。类似地,作为比较,对比方案中将RNN层替换为了元素注意力RNN。
元素注意力门的有效性
我们在NTU数据库上通过基于3D骨架的行为识别任务来分析元素注意门的效率。如图3所示,对于3层GRU网络,当第一层GRU被换为元素注意力GRU后,识别精度在Cross-Subject和Cross-View的设置下分别提升了3.5%和3.4%。随着替换层数的增加,性能也随之增加。当三层均被替换为元素注意力GRU后,识别精度较之于基准网络实现了4.6%和5.6%提升。元素注意力RNN层作为通用的设计,可以用在RNN网络的任何一层。
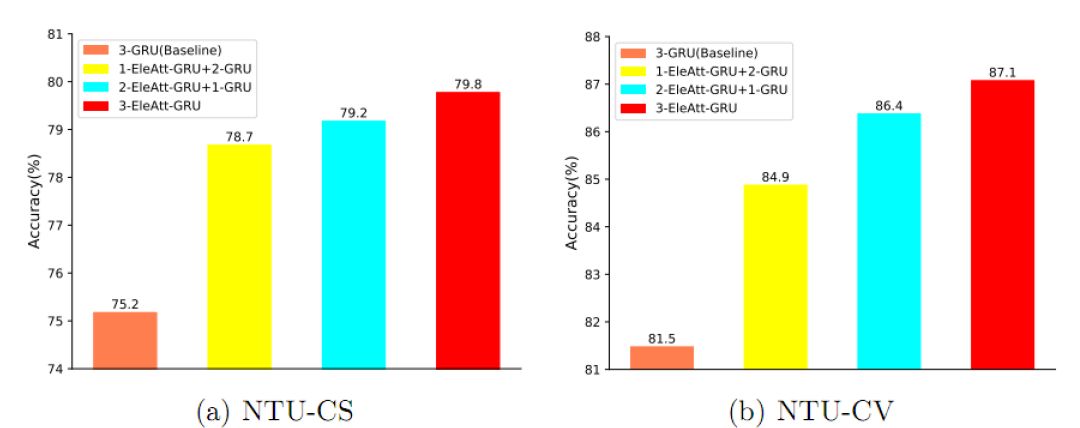
图3 对提出的元素注意力门在三层GRU网络上的性能分析(分类精度%)。m-EleAtt-GRU+n-GRU”表示前m层是提出的元素注意力GRU层,其余n层为原始GRU层。“3-GRU(Baseline)”是原始GRU构成的基准网络。该实验在基于3D骨架的行为识别任务上的NTU数据库的Cross-Subject(CS)和Cross-View(CV)设置下完成。
元素注意力RNN可用于建模其它信号
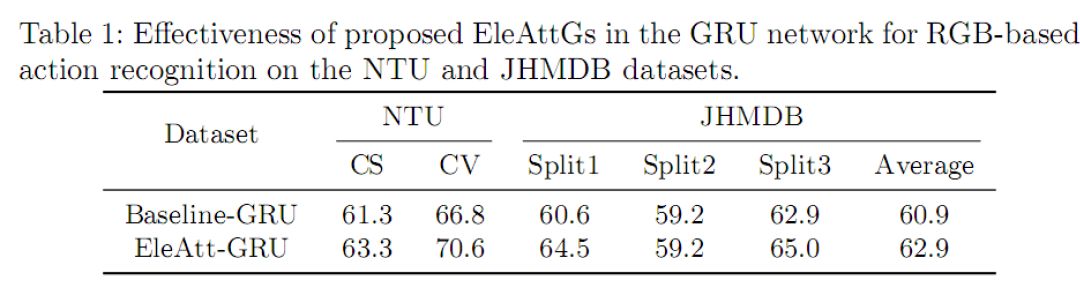
元素注意力RNN层作为一个通用设计,除了3D骨架数据,也可以被用于处理其它数据。在这里,我们通过使用CNN在RGB帧提取的特征作为RNN网络的输入,来验证该注意力机制在CNN特征上仍然有效。表1比较了元素注意力GRU(EleAtt-GRU)和原始GRU (Baseline-GRU)在基于RGB的视频行为识别上的性能,其显示元素注意力GRU比原始GRU识别精度高2%-3.8%。
元素注意力门可用到不同RNN结构
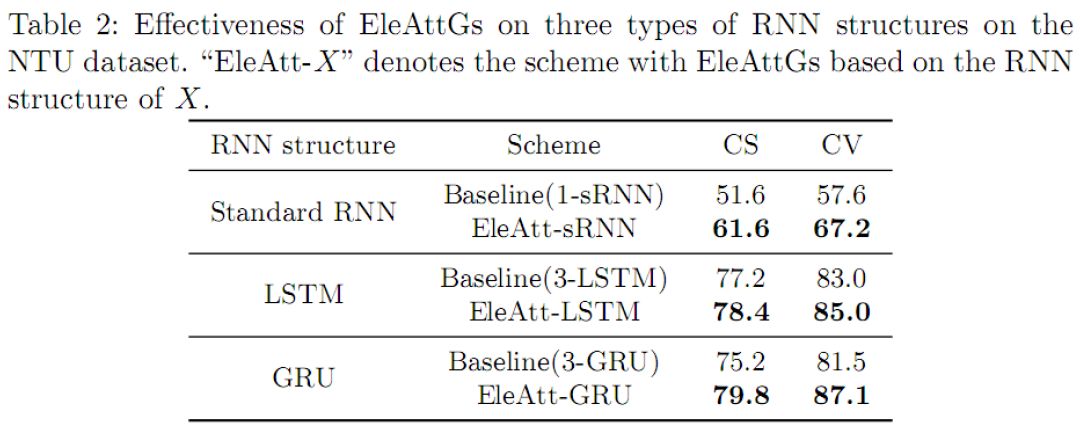
我们在三种代表性RNN结构上,即标准RNN、LSTM和GRU,分别验证设计的有效性。如表2所示,由于注意力门的引入,识别性能在三种结构上均实现了显著的提升。
元素注意力RNN加快了学习进程
图4展示了原始GRU和元素注意力GRU在训练过程的损失(Loss)变化曲线。可以看到,由于注意力门结构的引入,网络收敛比原始GRU更快了,并且最终的损失也降得更低了。对输入在元素上的自适应调制是一种更细粒度的信息流控制从而使得后续RNN神经元内部的学习更容易。

图4 训练时的损失曲线图。该实验分别在NTU数据库的Cross-Subject和Cross-View设置上进行来比较原始GRU(Baseline-GRU)和提出的元素注意力GRU(EleAtt-GRU)的收敛特性。实线表示训练集合上的结果,虚线表示验证集合上的结果。
可视化分析
为了更好地理解注意力机制是如何工作的,我们基于学到的第一层GRU的元素注意力门的响应进行了可视化,如图4所示。对于以3D骨架为输入的行为识别,RNN网络的第一层的输入为J个骨架节点的3D坐标,即维度为3J。在每个时刻,元素注意力门自适应地对每个元素乘上一个注意力权重值。图4用圆圈的大小来表示每个节点相对注意力值的大小(为了便于可视化,我们将一个节点的X、Y、Z坐标上的相对注意力值的和作为该节点的注意力相对值),圈越大表示相对注意力值越大。

图5 在基于3D骨架的人类行为识别任务上,根据第一层元素注意力GRU上注意力门响应值的大小在各个骨架节点上进行可视化。
对于第一行的“踢腿”行为,相对注意力值在对行为识别比较重要的脚节点上较大。对于第二行的“触摸脖子“行为,相对注意力值在手和头节点上比较大,而在不相关的脚节点上很小。这表明学到的注意力能关注于更有判别力的节点,和人的认知相符。
和其它先进方法的比较
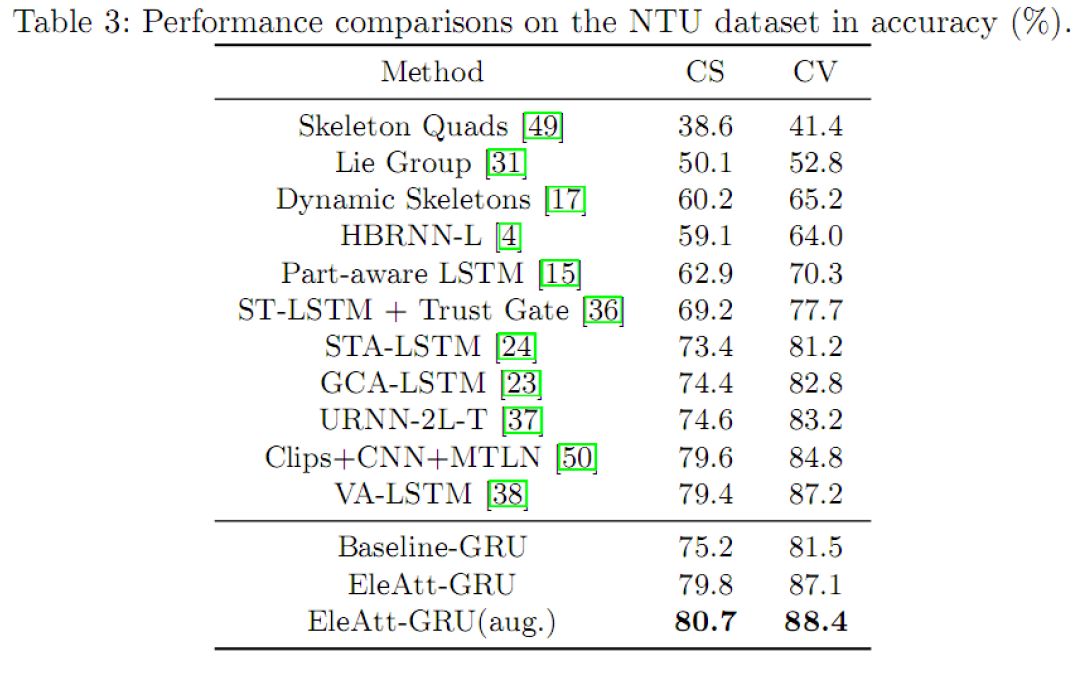
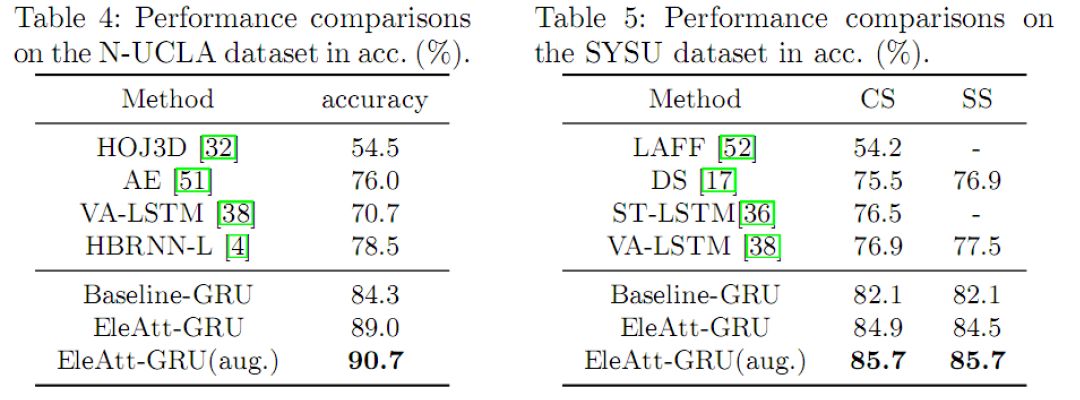
表3、4、5中对比了我们的方法和现有的方法在NTU、N-UCLA和SYSU 3D骨架行为识别数据库上的比较。由于有效的注意力机制设计,我们方法实现了最好的性能。
本文中,我们对RNN层的设计进行了改进,提出了通过对RNN层加入一个简单有效的元素注意力门,使RNN神经元自身拥有注意力能力。通过对不同的元素自适应地赋予不同的重要性来更加细粒度地控制输入信息流。该注意力门设计简单有效,可以用到各种各样的RNN结构中,及不同的任务中。
更多细节请参考论文
Pengfei Zhang, Jianru Xue, Cuiling Lan, Wenjun Zeng, Zhanning Gao, Nanning Zheng, “Adding attentiveness to the neurons in Recurrent Neuronal Networks”, ECCV‘18.
论文链接:https://arxiv.org/abs/1807.04445
参考文献:
[1] Luong, M.T., Pham, H., Manning, C.D.: Effective approaches to attention-based neural machine translation. arXiv preprint arXiv:1508.04025 (2015).
[2] Xu, K., Ba, J., Kiros, R., Cho, K., Courville, A.,Salakhudinov, R., Zemel, R., Bengio, Y.: Show, attend and tell: Neural image caption generation with visual attention. In: ICML. (2015) 2048-2057.
[3] Li, S., Li, W., Cook. C, Zhu, C., Gao, Y.: Independently recurrent neural network (IndRNN): building a longer and deeper RNN. In: CVPR.(2018).
作者简介

兰翠玲,微软亚洲研究院网络多媒体组研究员,从事计算机视觉、信号处理方面的研究。研究兴趣包括行为识别、姿态估计、深度学习、视频分析等,并在多个顶级会议、期刊上发表了20多篇论文。
你也许还想看:
● 专访ICIP 2017技术程序主席曾文军:新技术带来新数据,“旧瓶”装不了“新酒”

感谢你关注“微软研究院AI头条”,我们期待你的留言和投稿,共建交流平台。来稿请寄:msraai@microsoft.com。





