一文看尽2018全年计算机视觉大突破
来源:人工智能前沿讲习班

2018,仍是AI领域激动人心的一年。
计算机视觉领域同样精彩纷呈,与四年前相比GAN生成的假脸逼真到让人不敢相信;新工具、新框架的出现,也让这个领域的明天特别让人期待……
近日,Analytics Vidhya发布了一份2018人工智能技术总结与2019趋势预测报告,原文作者PRANAV DAR。这份报告总结和梳理了全年主要AI技术领域的重大进展,同时也给出了相关的资源地址,以便大家更好的使用、查询。
重点为大家介绍这份报告中的两个部分:
计算机视觉
工具和库
下面,我们就逐一来盘点和展望,嘿喂狗~
计算机视觉
今年,无论是图像还是视频方向都有大量新研究问世,有三大研究曾在CV圈掀起了集体波澜。
BigGAN
今年9月,当搭载BigGAN的双盲评审中的ICLR 2019论文现身,行家们就沸腾了:简直看不出这是GAN自己生成的。


在计算机图像研究史上,BigGAN的效果比前人进步了一大截。比如在ImageNet上进行128×128分辨率的训练后,它的Inception Score(IS)得分166.3,是之前最佳得分52.52分3倍。
除了搞定128×128小图之外,BigGAN还能直接在256×256、512×512的ImageNet数据上训练,生成更让人信服的样本。

在论文中研究人员揭秘,BigGAN的惊人效果背后,真的付出了金钱的代价,最多要用512个TPU训练,费用可达11万美元,合人民币76万元。
不止是模型参数多,训练规模也是有GAN以来最大的。它的参数是前人的2-4倍,批次大小是前人的8倍。
研究论文:
https://openreview.net/pdf?id=B1xsqj09Fm
Fast.ai 18分钟训练整个ImageNet
在完整的ImageNet上训练一个模型需要多久?各大公司不断下血本刷新着记录。
不过,也有不那么烧计算资源的平民版。
今年8月,在线深度学习课程Fast.ai的创始人Jeremy Howard和自己的学生,用租来的亚马逊AWS的云计算资源,18分钟在ImageNet上将图像分类模型训练到了93%的准确率。

前前后后,Fast.ai团队只用了16个AWS云实例,每个实例搭载8块英伟达V100 GPU,结果比Google用TPU Pod在斯坦福DAWNBench测试上达到的速度还要快40%。
这样拔群的成绩,成本价只需要40美元,Fast.ai在博客中将其称作人人可实现。

Fast.ai博客介绍:
https://www.fast.ai/2018/08/10/fastai-diu-imagenet/
vid2vid技术
今年8月,英伟达和MIT的研究团队高出一个超逼真高清视频生成AI。
只要一幅动态的语义地图,就可获得和真实世界几乎一模一样的视频。换句话说,只要把你心中的场景勾勒出来,无需实拍,电影级的视频就可以自动P出来:

除了街景,人脸也可生成:
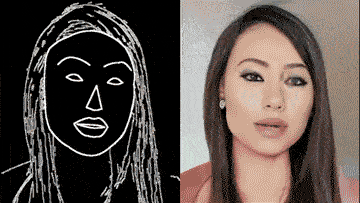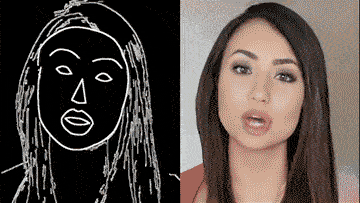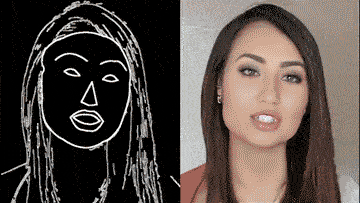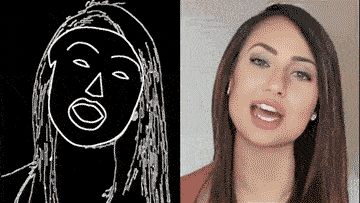
这背后的vid2vid技术,是一种在生成对抗性学习框架下的新方法:精心设计的生成器和鉴别器架构,再加上时空对抗目标。
这种方法可以在分割蒙版、素描草图、人体姿势等多种输入格式上,实现高分辨率、逼真、时间相干的视频效果。
好消息,vid2vid现已被英伟达开源。
研究论文:
https://tcwang0509.github.io/vid2vid/paper_vid2vid.pdf
GitHub地址:
https://github.com/NVIDIA/vid2vid
2019趋势展望
Analytics Vidhya预计,明年在计算机视觉领域,对现有方法的改进和增强的研究可能多于创造新方法。
在美国,政府对无人机的限令可能会稍微“松绑”,开放程度可能增加。而今年大火的自监督学习明年可能会应用到更多研究中。
Analytics Vidhya对视觉领域也有一些期待,目前来看,在CVPR和ICML等国际顶会上公布最新研究成果,在工业界的应用情况还不乐观。他希望在2019年,能看到更多的研究在实际场景中落地。
Analytics Vidhya预计,视觉问答(Visual Question Answering,VQA)技术和视觉对话系统可能会在各种实际应用中首次亮相。

工具和框架
哪种工具最好?哪个框架代表了未来?这都是一个个能永远争论下去的话题。
没有异议的是,不管争辩的结果是什么,我们都需要掌握和了解最新的工具,否则就有可能被行业所抛弃。
今年,机器学习领域的工具和框架仍在快速的发展,下面就是这方面的总结和展望。
PyTorch 1.0

根据10月GitHub发布的2018年度报告,PyTorch在增长最快的开源项目排行上,名列第二。也是唯一入围的深度学习框架。
作为谷歌TensorFlow最大的“劲敌”,PyTorch其实是一个新兵,2017年1月19日才正式发布。2018年5月,PyTorch和Caffe2整合,成为新一代PyTorch 1.0,竞争力更进一步。
相较而言,PyTorch速度快而且非常灵活,在GitHub上有越来越多的开码都采用了PyTorch框架。可以预见,明年PyTorch会更加普及。
至于PyTorch和TensorFlow怎么选择?在我们之前发过的一篇报道里,不少大佬站PyTorch。
实际上,两个框架越来越像。前Google Brain深度学习研究员,Denny Britz认为,大多数情况下,选择哪一个深度学习框架,其实影响没那么大。
PyTorch官网:
https://pytorch.org/
AutoML
很多人将AutoML称为深度学习的新方式,认为它改变了整个系统。有了AutoML,我们就不再需要设计复杂的深度学习网络。
今年1月17日,谷歌推出Cloud AutoML服务,把自家的AutoML技术通过云平台对外发布,即便你不懂机器学习,也能训练出一个定制化的机器学习模型。
不过AutoML并不是谷歌的专利。过去几年,很多公司都在涉足这个领域,比方国外有RapidMiner、KNIME、DataRobot和H2O.ai等等。
除了这些公司的产品,还有一个开源库要介绍给大家:
Auto Keras!
这是一个用于执行AutoML任务的开源库,意在让更多人即便没有人工智能的专家背景,也能搞定机器学习这件事。

这个库的作者是美国德州农工大学(Texas A&M University)助理教授胡侠和他的两名博士生:金海峰、Qingquan Song。Auto Keras直击谷歌AutoML的三大缺陷:
第一,还得付钱。
第二,因为在云上,还得配置Docker容器和Kubernetes。
第三,服务商(Google)保证不了你数据安全和隐私。
官网:
https://autokeras.com/
GitHub:
https://github.com/jhfjhfj1/autokeras
TensorFlow.js
今年3月底的TensorFlow开发者会峰会2018上,TensorFlow.js正式发布。
这是一个面向JavaScript开发者的机器学习框架,可以完全在浏览器中定义和训练模型,也能导入离线训练的TensorFlow和Keras模型进行预测,还对WebGL实现无缝支持。
在浏览器中使用TensorFlow.js可以扩展更多的应用场景,包括展开交互式的机器学习、所有数据都保存在客户端的情况等。

实际上,这个新发布的TensorFlow.js,就是基于之前的deeplearn.js,只不过被整合进TensorFlow之中。
谷歌还给了几个TensorFlow.js的应用案例。比如借用你的摄像头,来玩经典游戏:吃豆人(Pac-Man)。
官网:
https://js.tensorflow.org/
2019趋势展望
在工具这个主题中,最受关注的就是AutoML。因为这是一个真正会改变游戏规则的核心技术。在此,引用H2O.ai的大神Marios Michailidis(KazAnova)对明年AutoML领域的展望。
以智能可视化、提供洞见等方式,帮助描述和理解数据
为数据集发现、构建、提取更好的特征
快速构建更强大、更智能的预测模型
通过机器学习可解释性,弥补黑盒建模带来的差距
推动这些模型的产生
☞ OpenPV平台发布在线的ParallelEye视觉任务挑战赛
☞【学界】OpenPV:中科院研究人员建立开源的平行视觉研究平台
☞【学界】ParallelEye:面向交通视觉研究构建的大规模虚拟图像集
☞【CFP】Virtual Images for Visual Artificial Intelligence
☞【最详尽的GAN介绍】王飞跃等:生成式对抗网络 GAN 的研究进展与展望
☞【智能自动化学科前沿讲习班第1期】王飞跃教授:生成式对抗网络GAN的研究进展与展望
☞【智能自动化学科前沿讲习班第1期】王坤峰副研究员:GAN与平行视觉
☞【重磅】平行将成为一种常态:从SimGAN获得CVPR 2017最佳论文奖说起
☞【学界】Ian Goodfellow等人提出对抗重编程,让神经网络执行其他任务
☞【学界】六种GAN评估指标的综合评估实验,迈向定量评估GAN的重要一步
☞【资源】T2T:利用StackGAN和ProGAN从文本生成人脸
☞【学界】 CVPR 2018最佳论文作者亲笔解读:研究视觉任务关联性的Taskonomy
☞【业界】英特尔OpenVINO™工具包为创新智能视觉提供更多可能
☞【学界】ECCV 2018: 对抗深度学习: 鱼 (模型准确性) 与熊掌 (模型鲁棒性) 能否兼得




