SMP2020微博情绪分类比赛总结
01 赛事介绍
情绪分类技术评测EWECT是由哈工大在SMP会议上发起的比赛,吸引了189个队伍的报名参与,其中包含腾讯、小米、好未来、清华、中科院、复旦等机构。情感分析(文本分类)技术一直是自然语言处理领域的研究重点并在实际中有着非常广泛的应用,因此本次比赛也得到了较多的关注。本次比赛的官网是 http://39.97.118.137/ ,其中包括了详细的比赛描述以及验证集/测试集的排行榜。
2020年,新冠肺炎疫情成为了全国人民关注的焦点,众多用户针对此次疫情在新浪微博等社交媒体平台上发表自己的看法,蕴含了非常丰富的情感信息。NLP技术可以帮助政府了解网民对各个事件的态度,及时发现人民的情绪波动,从而更有针对性地制定政策方针,具有重要的社会价值。
本次评测任务中,参赛成员不仅需要分析普通微博中的情绪,还要专门针对疫情相关微博进行情绪分析。
1.1 评测内容
评测任务概述
本届微博情绪分类评测任务一共包含两个测试集:第一个为通用微博数据集,其中的微博是随机收集的包含各种话题的数据;第二个为疫情微博数据集,其中的微博数据均与本次疫情相关。
微博情绪分类任务旨在识别微博中蕴含的情绪,输入是一条微博,输出是该微博所蕴含的情绪类别。在本次评测中,我们将微博按照其蕴含的情绪分为以下六个类别之一:积极、愤怒、悲伤、恐惧、惊奇和无情绪。
两个数据集的各类情绪微博举例如下表所示:
| 情绪 | 通用微博数据集 | 疫情微博数据集 |
|---|---|---|
| 积极 | 哥,你猜猜看和喜欢的人一起做公益是什么感觉呢。我们的项目已经进入一个新阶段了,现在特别有成就感。加油加油。 | 愿大家平安、健康[心]#致敬疫情前线医护人员# 愿大家都健康平安 |
| 愤怒 | 每个月都有特别气愤的时候。,多少个瞬间想甩手不干了,杂七杂八,当我是什么。 | 整天歌颂医护人员伟大的自我牺牲精神,人家原本不用牺牲好吧!吃野味和隐瞒疫情的估计是同一波人,真的要死自己去死,别拉上无辜的人。 |
| 悲伤 | 回忆起老爸的点点滴滴,心痛...为什么.接受不了 | 救救武汉吧,受不了了泪奔,一群孩子穿上大人衣服学着救人 请官方不要瞒报谎报耽误病情,求求武汉zf了[泪][泪][泪][泪] |
| 恐惧 | 明明是一篇言情小说,看完之后为什么会恐怖的睡不着呢,越想越害怕[吃驚] | 对着这个症状,没病的都害怕[允悲][允悲] |
| 惊奇 | 我竟然不知道kkw是丑女无敌里的那个 | 我特别震惊就是真的很多人上了厕所是不会洗手的。。。。 |
| 无情绪 | 我们做不到选择缘分,却可以珍惜缘分。 | 辟谣,盐水漱口没用。 |
数据集说明
本次技术评测使用的标注数据集由哈尔滨工业大学社会计算与信息检索研究中心提供,原始数据源于新浪微博,由微热点大数据研究院提供,数据集分为两部分。
第一部分为通用微博数据集,该数据集内的微博内容是随机获取到微博内容,不针对特定的话题,覆盖的范围较广。
第二部分为疫情微博数据集,该数据集内的微博内容是在疫情期间使用相关关键字筛选获得的疫情微博,其内容与新冠疫情相关。
因此,本次评测训练集包含上述两类数据:通用微博训练数据和疫情微博训练数据,相对应的,测试集也分为通用微博测试集和疫情微博测试集。参赛成员可以同时使用两种训练数据集来训练模型。
每条微博被标注为以下六个类别之一:neutral(无情绪)、happy(积极)、angry(愤怒)、sad(悲伤)、fear(恐惧)、surprise(惊奇)。
-
通用微博训练数据集包括27,768条微博,验证集包含2,000条微博,测试数据集包含5,000条微博。
-
疫情微博训练数据集包括8,606条微博,验证集包含2,000条微博,测试数据集包含3,000条微博。
注意:实际发布的测试集中会包含混淆数据,混淆数据不作为测点,在最终结果评测时会预先去除。
训练数据集以xlsx格式发布,包含三列:数据编号,文本,情绪标签。示例如下:
| 数据编号 | 文本 | 情绪标签 |
|---|---|---|
| 1 | 每个月都有特别气愤的时候。,多少个瞬间想甩手不干了,杂七杂八,当我是什么。 | angry |
测试数据集以xlsx格式发布,包含两列:数据编号,文本。示例如下:
| 数据编号 | 文本 |
|---|---|
| 1 | #全国已确诊新型肺炎病例319例#中国加油!一定会过去的,相信医生,相信国家,相信医护人员!!! ?? |
1.2 评价指标
本次评测以宏平均F1值作为评测指标,最终,我们会对通用微博测试集的测试结果和疫情微博的测试结果进行平均,作为最终的测试结果,即:
02 赛后分享
-
一等奖 -
Tencent -
二等奖 -
清博大数据 -
拿第一导师请吃肯德基 -
三等奖 -
BERT 4EVER -
sys1874 -
炬火
2.1 Tencent
我们从网上收集了大量的开源中文预训练模型。这些预训练模型来自于CLUE(https://github.com/CLUEbenchmark/CLUEPretrainedModels)、哈工大讯飞(https://github.com/ymcui/Chinese-BERT-wwm)、追一科技 (https://github.com/ZhuiyiTechnology/pretrained-models)、华为(https://github.com/huawei-noah/Pretrained-Language-Model),腾讯(https://github.com/dbiir/UER-py)等。我们可以直接使用这些预训练模型,也可以在上面进行增量的预训练。
数据分析
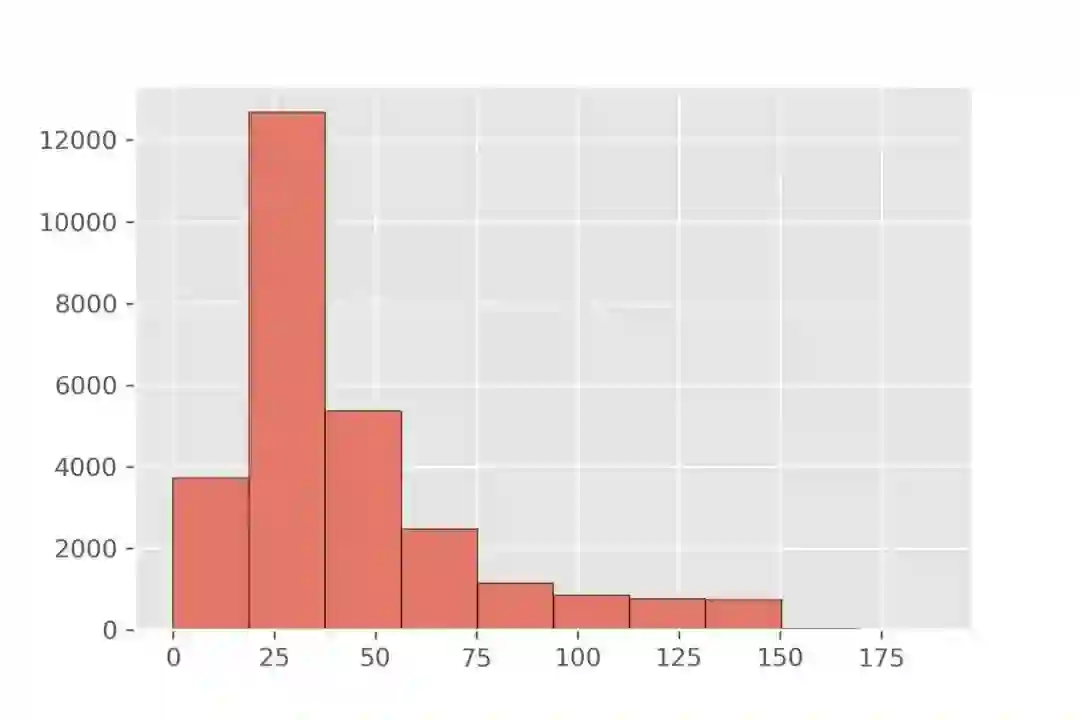
首先分析文本的长度,如图所示,大部分数据长度在 200 字符以内,95%的样本长度在 128 字符以内,99%的样本长度在 192 字符,其中有少量的样本长度达到 1000 以上,我们对多余部分使用截断处理。
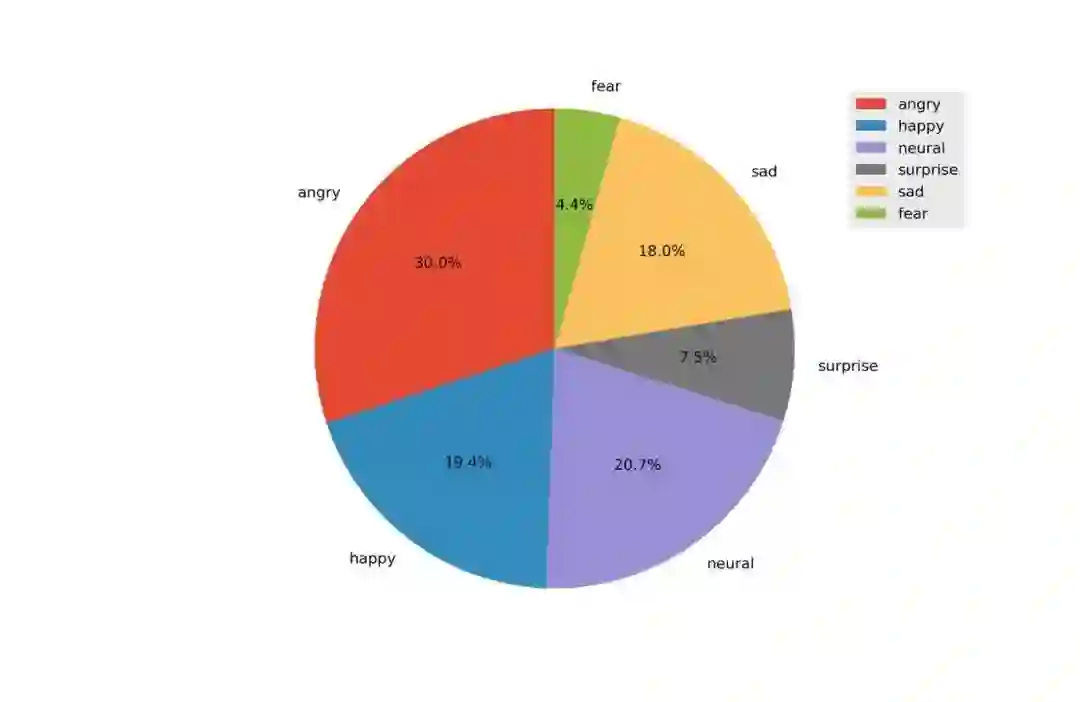
数据分为 6 个类别,如图 2、图 4 所示,其中 natural、angry、happy 占数据 的主要部分(分别占 usual 70.1%,virus 83.8%),由于评估指标使用的是 macro F1,准确区分数据量少的类将是提升得分的关键。
数据预处理
原始数据中带有大量的标记,对分析文本的情感倾向没有帮助(例如用户 ID, 转发标记、URL 等),我们利用正则表达式过滤了以上标记,并且将 emoji 表情 翻译成中文释义。例如:


在后续的训练中,我们同时使用了经过预处理和不经过预处理的数据作为模 型输入。
预训练
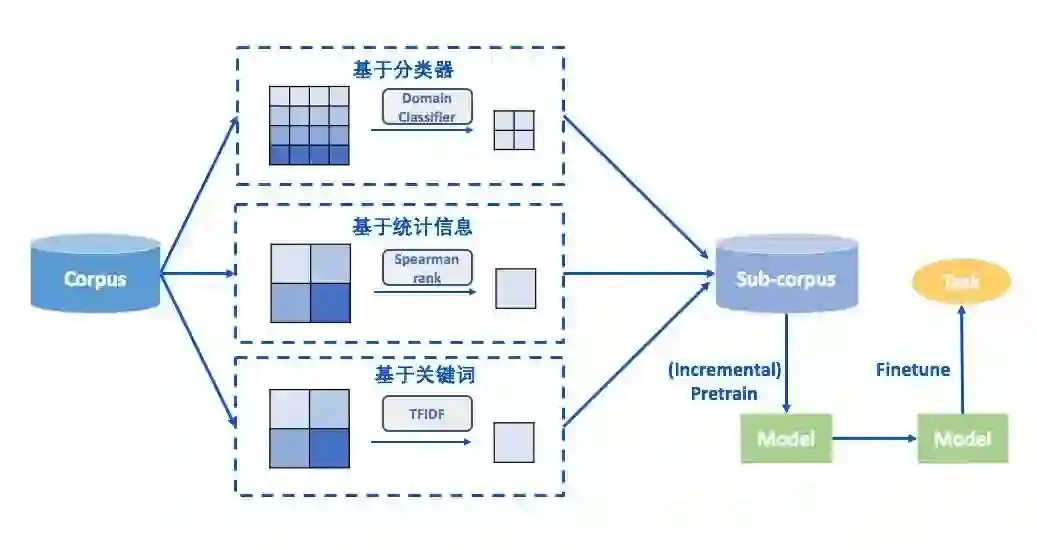
我们使用的外部语料有:网络上收集的 4000 万条微博语料、OpenKG疫情相关知识图谱中提取的语料、爬取的疫情相关微博以及从开放数据集中提 取的情感相关语料,结合这些语料和动态遮罩、区域遮罩、数据选择(使用统计信息、关键词和分类器来选择数据)等训练 策略得到增量训练模型。
数据增强
-
通过对样本进行随机删除、随机调换单词位置、同义词替换来扩充数据集; -
利用 BERT 模型的掩码语言模型特性,依次单独 mask 句子中的每个 token可能的候选字,生成了一个增强样本。 -
回译数据增强 & 对抗训练;
模型介绍
腾讯队伍的比赛代码是基于UER-py预训练框架的(https://github.com/dbiir/UER-py)。UER支持各种不同的预训练模型(编码器和预训练目标的任意组合)以及丰富的下游微调策略,并提供了大量的预训练好的中文预训练权重以及模型集成的代码。用户可以通过随机组合预训练权重、预训练策略和微调策略、快速的得到一系列的高质量的分类模型并对其进行集成。比如随机选择某一个开源的预训练权重、然后随机使用某一个或者多个预训练策略进行增量预训练,然后随机使用某一个或者多个策略进行微调。UER能帮助用户在比赛中以较少的人工成本,快速的得到有竞争力的结果。
我们训练了数百个分类模型,得到了超过 3000 亿(1TB)参数的系统。由于我们的技术主要围绕着 BERT展开,因此我们把这个系统叫做 BERT forest。据我们所知,目前很少有工作会针对一个具体的任务,使用超过千亿级 别参数量。我们的实验证明了在已有的工作上持续的增加参数量,仍然能取得可观的收益。
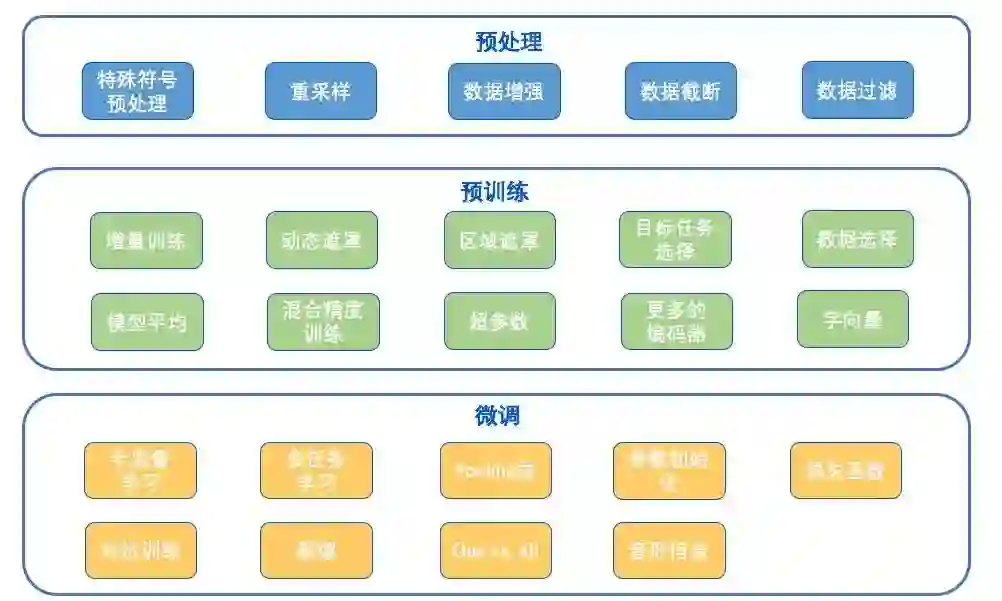
我们使用了大量中文预训练模型,通过不同的训练策略进行微调,从而得到 大量的具有低偏差-高方差的基础模型特征,并在这些特征上进行 stacking。我们从 model zoo 中选取模型进行微调和增量训练,此外还使用了 LSTM、 GPT、Gated CNN等模型,基于这些模型,随机组合了使用的数据集、文本 长度、损失函数、对抗训练等训练策略,为 usual 和 virus 分别提取超过 300 个 基模型特征用于 stacking 融合学习。
模型融合
我们的框架使用 4 层模型,3 次融合的方案,在第一层使用大量预训练模型 作为基模型特征,第二层使用 LightGBM 作为次模型特征,第三层使用 Linear Regression 之后平均作为最终结果。其步骤为
-
基模型:对训练集进行 k 折训练。由于比赛采 用 AB 测试集,需要保留训练的 checkpoint 用来预测 B 测试集,因此只保留 30%的模型 checkpoint 用于平均作 为测试集结果。
-
LightGBM 次模型:使用 LightGBM 进行第一次融合,将基模型特征通过 有放回抽样分为 5 组,每组以 Stacking 步骤单独训练一个 LightGBM 模型作为第 二层特征,LightGBM 通过贝叶斯优化确定超参数。
-
Linear Regression 次模型:利用线性回归模型对 LightGBM 模型进行第二 次融合,使用十折每次取 90%的数据用于训练,留出 10%数据用于验证,最后 提交的结果是对验证集/测试集预测的平均结果。
-
Averaging:对十折线性回归模型的结果平均作为最终结果。
2.2 清博大数据
了解决不同数据集上的分类问题,考虑到数据集的分类标准差异,所以针 对不同的数据,本组分开训练了两个模型。除了数据上的差异,两个模型的结构 上并没有太大差异,主要差异体现在训练过程和参数调整上。两个模型都采用了 三个相同的预训练模型,分别是 Roberta、XLNet、XLM-Roberta,构建了六个 fineturn 结构相同的模型,调参和调整模型输入来获得最好的单模型效果。
预训练模型
本组采用了疫情期间网民情绪文本 (https://www.datafountain.cn/competitions/423),共 1820606 条,对 Roberta 模型进行了动态掩码(dynamic Masking)任务的训练。得到了针对疫情 数据的预训练模型。用我们训练的有针对性的预训练模型在不改变任何参数的情 况下,疫情数据验证集的结果有一定提升。
迁移学习
两个数据集合在标签上有一致性,对于通用的情感词例如‘哈哈哈’,无论在 那个数据集中,都更倾向于分类到 happy 标签,基于这样的客观事实,我们可以 在训练好的适用范围更广的通用模型的基础上,加入疫情标注数据对模型进行适 应性训练,相比于在不足一万的疫情数据集上训练得到的模型,这种方式大大增 加了模型的泛化能力。
数据增强
本组采用的数据增强的方式类似同义词替换的思路,只是获取同义词的方式不同 于以往的词典或者 Word2vec 模型的方式,而是采用 BERT 模型对文本中的 Token 随机进行遮挡预测,并选取可能性最大的两个预测结果 替换原文中的 Token,最终从一个文本中获得多个生成文本,并控制总体的数据 比例,减少数据不均衡带来的影响。
但从实验结果来看,这样的技巧没有为我们 带来提升,分析增强的数据可以看到,BERT 预测出来的字不是很符号语言规律, 融合在原文本中使原来的句子变得晦涩难懂。
2.3 拿第一导师请吃肯德基
本文模型结构主要对 RoBERTa 以及 BERT 模型进行改进,使用迁移学习将通 用微博中获取的信息迁移到疫情微博中,将多个模型利用 Stacking 进行集成, 在疫情微博上取得了较好的结果。
通用微博模型
本文在 RoBERTa 以及 BERT 模型基础上进行改造,构建大量模型架构,最终 根据实验效果,选取了其中部分模型架构,预训练权重选择 robert-wwm-ext-large 以及 bert-wwm-ext,下面对这几种模型架构简要介绍。
-
Last_3embedding_concat:取预训练模型的最后三层 embedding 向量与 cls 向 量进行拼接,传入 linear 层得到预测结果; -
Last_3embedding_meanmax:取预训练模型的最后三层 embedding 向量分别进 行 mean-pooling 和 max-pooling,将 pooling 的结果拼接传入 linear 进行分类; -
LSTM_MaxPool:取预训练模型的最后一层 embedding 向量传入双向 LSTM 中,叠加 max-pooling 层和 linear 层进行分类; -
LSTM_RCNN:取预训练模型的最后一层 embedding 向量输入双向 LSTM, 叠加 CNN 和 linear 层进行分类预测; -
Last_2embedding_concat:取预训练模型的最后两层 embedding 向量与 cls 向量进行拼接,传如 linear 层进行分类;
疫情微博模型
最终疫情微博模型训练流程如图所示。首先使用通用微博数据集在预训练模 型 RoBERTa 上进行后训练,将获得的预训练模型参数作为疫情模型的初始权重, 然后通过相同方式在不同的模型结构上进行训练,最终选取线下结果较优的多个 单模型进行 Stacking 集成,获得了较好的效果。
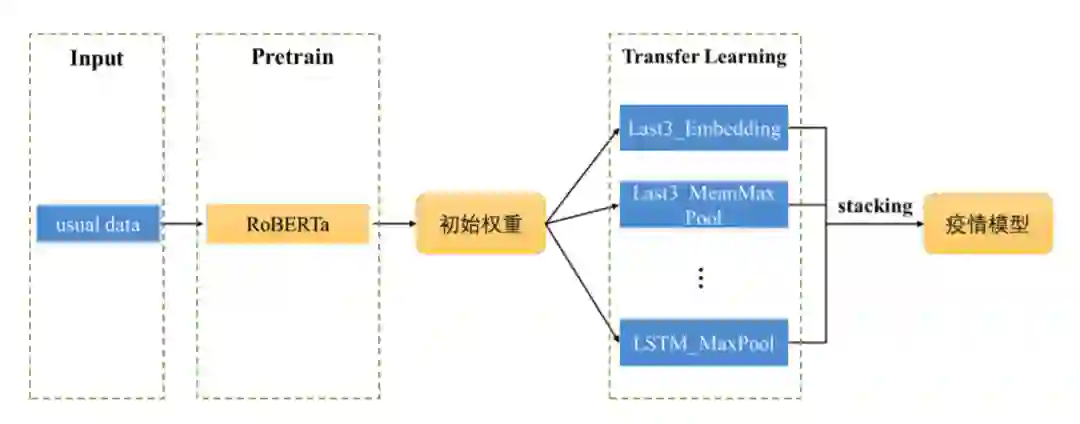
结果融合
对于通用微博 usual 数据集,将多个模型进行融合后效果均没有单模型结果 好,所以最终提交时仅选取最优单模型提交。单模型本身复杂度较低,过拟合风 险较小。最终结果也表明在 usual 数据集上验证集 F1 值和最终测试集 F1 值波动。
对于疫情微博 virus 数据集,使用投票融合、概率平均融合和加权融合的集 成策略均没有得到有效的提升,当使用 stacking 集成后,线上结果有较大的提升, 故本文最终提交方案选取了 Stacking+GBDT 方法对多模型进行集成融合。
2.4 BERT 4EVER
伪数据生成
在正式进入训练阶段前,我们分别采用了
第一种方式以一定的概率将输入句子中的词语替换成用于补齐 BERT 预训练模型句子的
多模型融合
我们分别训练了五个基于不同数据的 RoBERTa_WWM_Ext 模型,再分别对 每个模型进行通用领域信息/疫情领域信息增强后,将增强后的五个通用领域的模型进行软投票融合预测通用领域的数据,增强后的五个疫情领域的模型进行软 投票融合预测疫情领域的数据。
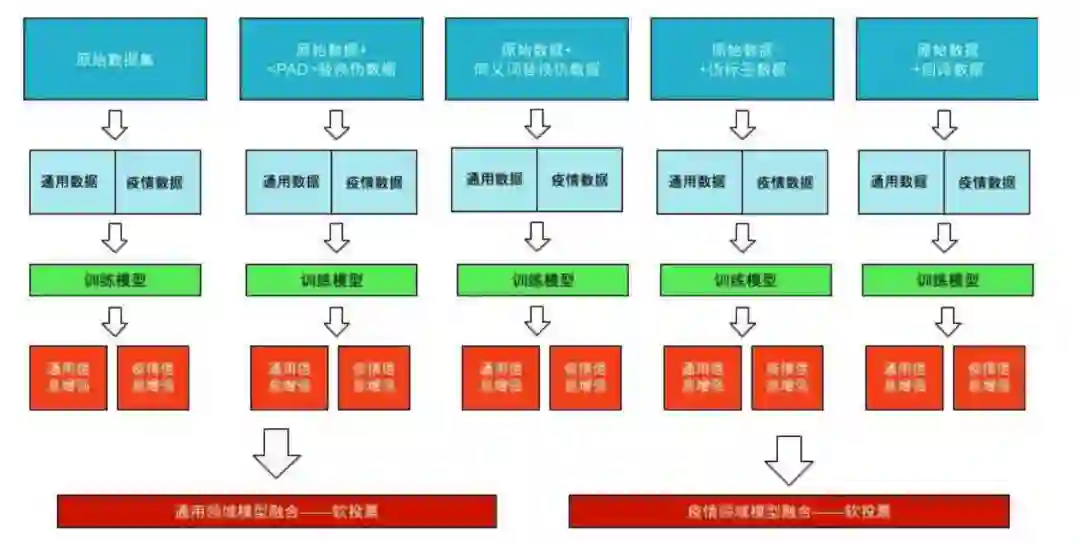
2.5 sys1874
所用模型以 RoBERTa 模型(RoBERTa-Large)为基础。文本特征被送入 24 层的编码器中特征隐藏层,最后将编码器所提取特征送入分类器中预测最终结果。考虑到情感分析问题本身的难度,我们融合了 RoBERTa-Large 中的浅层特征与 深层特征,用于最终预测。
基础模型
我们使用了 RoBERTa-Large 作为基础模型。RoBERTa-Large 包含 24 个隐藏 层。每一个隐藏层都包含相应的 self-attention 结构,用于利用不同位置的特征来 改良文本特征。最终,我们将所得的编码器特征送入包含两层全连接层的分类器中预测最终结果。
特征融合
考虑到情感的表现方式的多样性,即同时存在与情感紧密相关的特定词汇或 文字在原始文本中直接出现的情况(比如在愤怒、悲伤等较为极端的情况),以及存在情感较为内敛,需要从文本具体内容中提取情感信息的情况,我们在基础 模型中同时提取了浅层特征和深层特征用于最终的预测,即把解码器隐藏层中 10、15、20 以及最终的输出(24)层的特征取出。
2.6 炬火
模型集成
们在 Transformers 库中提供的 BertForSequenceClassification 的基础 上,对结构进行了调整,主要分为三部分,分别是对 CLS pool 方法的调整、对 H1-Hn pool 方法的调整以及对 output layer 的调整。
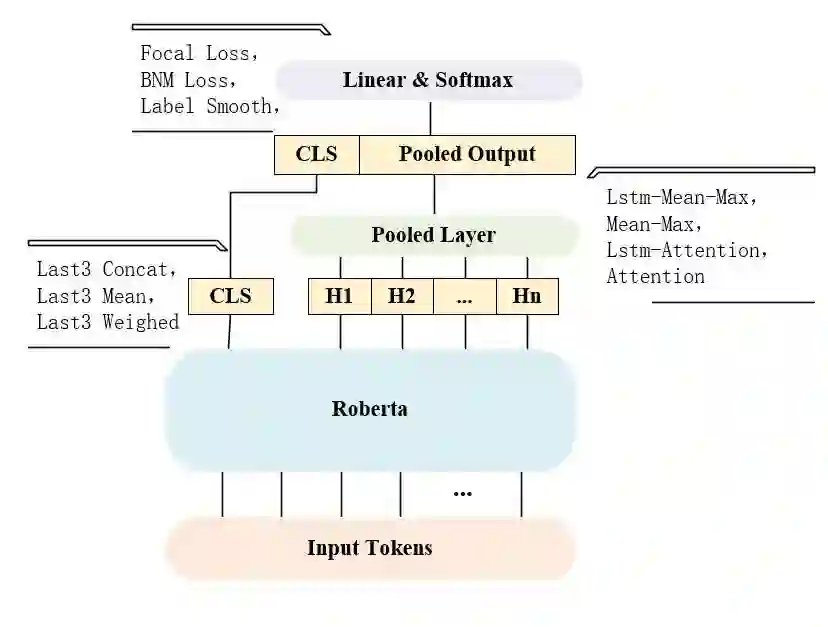
Roberta 最终输出的 CLS,我们尝试过将其替换为最后三层网络 CLS 的 concat、mean 以及 weighted,而在最后的 linear & softmax 层,我们也尝 试过 focal loss、bnm loss 以及 label smooth,但模型性能均未提升,所以在 这两部分我们最终采用了默认的 CLS,以及基础的 cross-entropy 损失函数。
此外我们尝试过四种池化策略处理 H1~Hn,分别是 mean max、LSTM mean max、 attention 以及 LSTM attention,实验表明后两种池化策略较为有效。
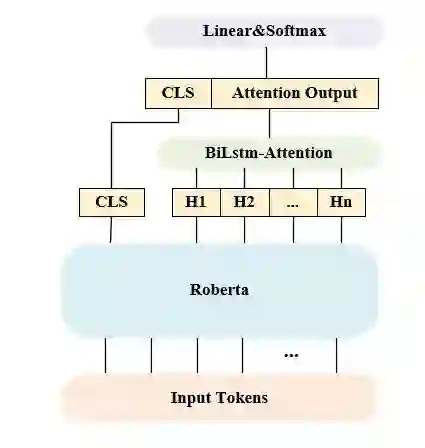
LSTM-Attention
我们尝试在原始 Roberta 模型后添加 BiLstm-Attention,然 后将其输出结果与原 CLS 拼接后输入一个线性层进行 softmax 分类,在 usual 数据集中效果较好,在 virus 上效果欠佳。
由于微信平台算法改版,公号内容将不再以时间排序展示,如果大家想第一时间看到我们的推送,强烈建议星标我们和给我们多点点【在看】。星标具体步骤为:
(1)点击页面最上方"AINLP",进入公众号主页。
(2)点击右上角的小点点,在弹出页面点击“设为星标”,就可以啦。
感谢支持,比心

推荐阅读
征稿启示| 200元稿费+5000DBC(价值20个小时GPU算力)
完结撒花!李宏毅老师深度学习与人类语言处理课程视频及课件(附下载)
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,分享、点赞、在看三选一吧🙏




